Автор: Денис Аветисян
Исследователи предлагают инновационную систему кодирования речи, которая адаптируется к естественному ритму языка для повышения эффективности и качества звучания.
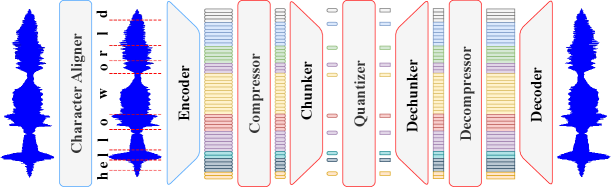
Представлен DyCAST — фреймворк для кодирования речи с переменной частотой кадров и выравниванием по символам, улучшающий лингвистическую согласованность.
Современные системы кодирования речи, лежащие в основе диалоговых технологий, зачастую страдают от неэффективности, обусловленной использованием фиксированной частоты кадров и, как следствие, избыточностью последовательностей токенов. В данной работе, представленной под названием ‘Beyond Fixed Frames: Dynamic Character-Aligned Speech Tokenization’, предлагается инновационный подход — DyCAST, динамический токенизатор речи, сопоставляющий токены с лингвистическими единицами на уровне символов и моделирующий их длительность. Благодаря этому, DyCAST обеспечивает эффективное и высококачественное представление речи, снижая количество необходимых токенов без потери качества реконструкции. Сможет ли подобный подход открыть новые горизонты в разработке более компактных и выразительных систем кодирования речи для широкого спектра приложений?
За пределами фиксированных рамок: Ограничения традиционного кодирования речи
Традиционные методы кодирования речи в значительной степени опираются на токенизацию с фиксированной частотой кадров, что представляет собой жёсткий подход, зачастую приводящий к потере тонких временных характеристик. Вместо того чтобы адаптироваться к естественному ритму речи, где информационная плотность постоянно меняется, этот метод разделяет сигнал на сегменты равной длительности, независимо от содержания. В результате, важные детали, такие как микропаузы, изменения в темпе и интонации, необходимые для передачи эмоций и акцентов, могут быть искажены или утеряны. Эта неспособность учитывать динамическую природу речи ограничивает качество синтезированного звука и может приводить к неестественному звучанию, особенно в сложных речевых ситуациях, где важна выразительность.
Жесткая привязка к фиксированной частоте кадров в традиционном кодировании речи приводит к появлению заметных артефактов и снижает естественность синтезированной речи, особенно когда речь идет об эмоционально окрашенных или динамично меняющихся высказываниях. Искусственная сегментация звукового потока на равновеликие отрезки не позволяет адекватно передать тонкие временные характеристики, присущие человеческой речи — паузы, акценты, изменения темпа и интонации. В результате, синтезированная речь часто звучит роботизированно и неестественно, лишаясь той выразительности, которая является ключевым элементом живого общения и восприятия информации. Эта проблема особенно остро проявляется при попытке воссоздать речь, содержащую сложные эмоциональные оттенки или требующую передачи динамики повествования.
Современные методы кодирования речи часто сталкиваются с проблемой неэффективного представления неравномерной информативности речевого сигнала. Речь характеризуется динамическими изменениями: некоторые моменты содержат критически важную информацию для понимания, в то время как другие несут меньшую нагрузку. Традиционные алгоритмы, стремясь к унификации, обрабатывают все сегменты сигнала с одинаковой тщательностью, что приводит к избыточности и ненужному расходу пропускной способности. В результате, даже при относительно небольшом сжатии, возникают потери качества, особенно заметные при передаче эмоционально окрашенной речи или сигналов с высокой степенью динамики. Разработка адаптивных методов, способных выделять и эффективно кодировать наиболее информативные участки речи, является ключевой задачей для повышения эффективности сжатия и улучшения качества синтезируемой речи.
DyCAST: Динамическая и контекстно-зависимая токенизация
В основе DyCAST лежит токенизация с переменной частотой кадров, что позволяет адаптировать длительность каждого токена к особенностям содержимого аудио. В отличие от традиционных методов, использующих фиксированную длительность кадров, DyCAST динамически регулирует временное разрешение, обеспечивая более точное представление быстро меняющихся звуковых событий и нюансов речи. Это достигается путем анализа аудиосигнала и определения оптимальной длительности токена для каждого сегмента, что позволяет улавливать тонкие временные зависимости и повышать эффективность модели в задачах, требующих учета динамики речи, таких как распознавание и синтез.
В основе DyCAST лежит механизм «мягкой» привязки к символам (soft character-level alignment), который позволяет более естественно и гибко представлять сегменты речи. В отличие от жесткой привязки, где каждый фонетический сегмент строго соответствует определенной последовательности символов, данный подход использует вероятностное соответствие. Это означает, что каждый звуковой фрагмент сопоставляется с набором символов с определенной степенью уверенности, что позволяет учитывать вариативность произношения, коартикуляцию и другие фонетические явления. Такая реализация обеспечивает более устойчивое и точное представление речи, особенно в случаях нечеткого или неоднозначного произношения, и снижает зависимость от точной транскрипции.
В основе DyCAST лежит использование предварительно обученной модели самообучения для кодирования речи — WavLM. WavLM извлекает устойчивые и информативные скрытые представления звуковых сигналов, что позволяет системе эффективно обрабатывать и анализировать речь. Предварительное обучение на больших объемах неразмеченных данных обеспечивает высокую обобщающую способность модели и позволяет ей извлекать релевантные признаки, необходимые для дальнейшей обработки и токенизации. Использование скрытых представлений, полученных WavLM, снижает потребность в ручной разработке признаков и повышает точность и надежность системы в целом.
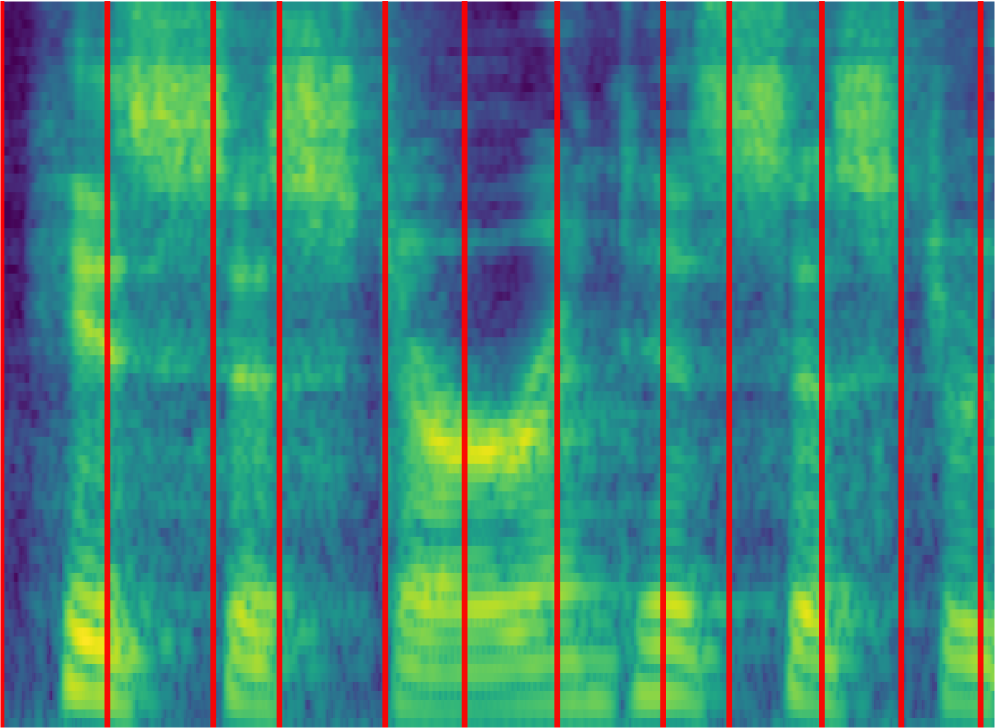
Декодирование фреймворка: Ключевые компоненты DyCAST
Прогнозирующая границы (Boundary Predictor) в DyCAST обеспечивает точную оценку границ фрагментов (chunks) при использовании переменной частоты кадров для токенизации. Это позволяет динамически разделять входной поток данных на сегменты, оптимальные для последующей обработки и синтеза речи. Алгоритм прогнозирует моменты, где изменение в аудиосигнале указывает на начало нового фрагмента, что критически важно для поддержания плавности и естественности реконструируемой речи, избегая резких переходов и артефактов, которые могут возникнуть при использовании фиксированных границ.
Прогнозирование длительности токенов в DyCAST осуществляется с целью оптимизации информационной плотности и естественности синтезируемой речи. Модель Duration Predictor анализирует входные данные и определяет оптимальную длительность каждого токена, что позволяет избежать неестественных пауз или слишком быстрого произношения. Точность прогнозирования длительности критически важна для обеспечения плавности и разборчивости речи, особенно в задачах преобразования текста в речь (TTS). Алгоритм учитывает контекст и характеристики каждого токена для формирования наиболее подходящей временной структуры, что способствует повышению субъективной оценки качества синтезированной речи слушателями.
Скалярная сферическая квантизация (Scalar Spherical Quantization) представляет собой метод дискретизации латентных представлений, направленный на снижение вычислительной сложности без существенной потери качества. В отличие от традиционных методов квантизации, использующих линейные или тензорные представления, данный подход использует сферическую координатную систему для кодирования векторов. Это позволяет более эффективно представлять данные с высокой размерностью, снижая потребность в вычислительных ресурсах для их обработки и хранения. Метод заключается в отображении каждого вектора латентного пространства на ближайшую точку на гиперсфере, что приводит к уменьшению битовой глубины представления без значительного ухудшения перцептивного качества реконструируемого сигнала. Эффективность достигается за счет уменьшения числа параметров, необходимых для представления данных, что особенно важно для моделей с большим количеством параметров и ограниченными вычислительными ресурсами.
Фокальная модуляция повышает качество реконструированной речи путем селективной амплификации важных признаков. Данный механизм анализирует латентное пространство представления и идентифицирует наиболее значимые элементы, такие как форманты и тональные характеристики. Затем, используя обучаемые веса, происходит усиление этих признаков при декодировании, что позволяет более точно восстановить исходный сигнал и улучшить его разборчивость и естественность. В процессе обучения модель оптимизирует веса для достижения максимального улучшения качества реконструированной речи, фокусируясь на наиболее информативных участках спектра и временной области.
Расширяя горизонты: Применение и влияние DyCAST
Разработка DyCAST демонстрирует существенное повышение эффективности в различных задачах обработки речи, включая автоматическое распознавание, синтез речи и идентификацию говорящего. Данная система, благодаря инновационному подходу к кодированию, позволяет добиться более точного распознавания речи даже в условиях шума и искажений, что критически важно для голосовых помощников и систем диктовки. В области синтеза речи DyCAST обеспечивает более естественное и разборчивое звучание, приближая искусственную речь к человеческой. Кроме того, система значительно повышает точность идентификации говорящего, что находит применение в системах безопасности и биометрической аутентификации. В целом, DyCAST представляет собой универсальное решение, способное значительно улучшить качество и надежность широкого спектра приложений, связанных с обработкой и анализом речи.
Способность DyCAST обрабатывать переменные частоты кадров, варьирующиеся от 6 до 17 Гц, открывает новые горизонты в области преобразования голоса. Традиционные кодеки часто ограничены фиксированной частотой, что приводит к неестественным и роботизированным результатам при изменении тембра или скорости речи. DyCAST, напротив, позволяет более точно моделировать динамику голоса, сохраняя нюансы интонации и эмоциональной окраски. Это особенно важно для создания реалистичных и выразительных голосовых аватаров, а также для приложений, требующих адаптации речи к различным контекстам и стилям общения. Благодаря гибкости в отношении частоты кадров, преобразования голоса становятся более плавными, естественными и лишенными артефактов, что значительно повышает качество и восприятие синтезированной речи.
Разработка DyCAST открывает новые перспективы в области аудио, обеспечивая значительно более высокую степень сжатия данных без ущерба для воспринимаемого качества звука. Это достижение имеет ключевое значение для создания более эффективных и захватывающих аудио-опытов, поскольку позволяет снизить требования к пропускной способности и объему памяти при сохранении высокой детализации и реалистичности звучания. Подобное сжатие особенно важно для потоковой передачи аудио- и видеоконтента, облачных хранилищ и мобильных устройств, где оптимизация ресурсов играет решающую роль. В результате, пользователи смогут наслаждаться более качественным звуком при меньшем размере файлов и более плавной передаче данных, что значительно улучшает общее впечатление от использования аудио- и видеоприложений.
Исследования демонстрируют, что система DyCAST достигает наименьшего показателя ошибки распознавания речи (dWER) при использовании декодирования на основе «токенов + длительностей». При этом, сохраняется сопоставимое качество естественности (UTMOS) и схожесть голоса (Sim) с базовыми кодеками. Данный результат свидетельствует о благоприятном компромиссе между степенью сжатия аудиоданных и эффективностью их последующей обработки, что открывает перспективы для создания более качественных и компактных систем распознавания и синтеза речи.
Исследование, представленное в данной работе, демонстрирует стремление к разрушению устоявшихся рамок в области кодирования речи. Авторы, подобно исследователям, вскрывающим чёрный ящик, предлагают отказаться от фиксированной длительности фреймов в пользу динамического подхода. Этот метод, основанный на токенизации, выстроенной на основе символов, позволяет достичь более точного лингвистического выравнивания и, следовательно, более эффективного представления звука. Как однажды заметил Дональд Дэвис: «Любая достаточно продвинутая технология неотличима от магии». Именно подобное ощущение возникает при наблюдении за тем, как сложные алгоритмы позволяют превзойти ограничения традиционных подходов, создавая иллюзию магического преобразования звука в данные и обратно, с сохранением всех нюансов.
Куда Дальше?
Представленный подход, манипулируя скоростью передачи информации и привязывая её к фонетической структуре, лишь обнажает глубинные противоречия в самом понятии «кодирования» речи. Попытки сжать информацию всегда несут в себе риск потери — вопрос лишь в том, что именно будет отброшено. Вместо погони за идеальной компрессией, возможно, стоит переосмыслить задачу: не «сжать», а «реконструировать», создавая иллюзию речи, достаточную для восприятия, даже если эта иллюзия и не является точной копией оригинала. Это переход от инженерного решения к философскому эксперименту.
Очевидным ограничением текущих методов является зависимость от предварительно обученных моделей. По сути, система «запоминает» речь, а не «понимает» её. Будущие исследования должны быть направлены на создание систем, способных к генерации речи, основанной на принципах, а не на шаблонах. Переход к более абстрактным представлениям, независимым от конкретного говорящего или языка, представляется не просто желательным, но и необходимым шагом. Иначе мы обречены вечно улучшать лишь имитацию, а не создавать истинный искусственный интеллект.
В конечном счете, задача кодирования речи — это не только техническая проблема, но и метафизический вопрос о природе информации и её связи с реальностью. Попытки «разбить» речь на токены, как будто это дискретный объект, могут оказаться тупиковыми. Возможно, истинный прогресс лежит в признании того, что речь — это непрерывный поток, и задача состоит не в его «кодировании», а в его «перехвате» и «реинтерпретации». Правила существуют, чтобы их проверять.
Оригинал статьи: https://arxiv.org/pdf/2601.23174.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Графы и действия: новый подход к планированию для роботов
- Многокритериальная оптимизация: взгляд на народные методы
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Квантовые амбиции: Иран вступает в гонку
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Bibby AI: Новый помощник для исследователей в LaTeX
- Наука определений: Автоматическое извлечение знаний из научных текстов
- Генерация без рисков: как избежать нарушения авторских прав при работе с языковыми моделями
2026-02-08 22:02