Автор: Денис Аветисян
Представлен RIR-Mega-Speech — масштабный корпус речевых данных, записанных в различных реверберирующих помещениях, призванный улучшить устойчивость систем распознавания речи.
Корпус содержит детальные акустические метаданные и обеспечивает воспроизводимость научных исследований в области обработки речи.
Несмотря на десятилетия исследований в области распознавания речи в условиях реверберации, сравнение различных методов затруднено из-за отсутствия стандартизированных корпусов с полными акустическими аннотациями и воспроизводимой документацией. В настоящей работе представлен корпус RIR-Mega-Speech, состоящий примерно из 117.5 часов речи, полученной путем свертки данных LibriSpeech с около 5000 смоделированных импульсных характеристик помещений из коллекции RIR-Mega, с указанием RT60, отношения прямого к реверберирующему сигналу (DRR) и индекса ясности C_{50}. Корпус позволяет стандартизировать оценку устойчивости систем распознавания речи к реверберации и обеспечить воспроизводимость результатов исследований. Какие новые возможности для разработки и оценки алгоритмов распознавания речи в сложных акустических условиях открывает данный ресурс?
Зеркало Реальности: Проблема Распознавания Речи в Эхе
Современные системы распознавания речи демонстрируют значительное снижение эффективности в реалистичных реверберирующих средах, что существенно ограничивает их применение в повседневных ситуациях. Присутствие отражений звука от стен, мебели и других поверхностей искажает речевой сигнал, затрудняя для алгоритмов выделение и интерпретацию ключевых акустических признаков. В отличие от контролируемых лабораторных условий, реальные помещения характеризуются сложной геометрией, разнообразными материалами, поглощающими и отражающими звук, и постоянным изменением акустической обстановки, что делает задачу распознавания речи в таких условиях крайне сложной. Данное ограничение особенно критично для приложений, предназначенных для использования в общественных местах, таких как аэропорты, вокзалы, торговые центры или многолюдные офисы, где реверберация является неизбежным фактором, снижающим надежность и точность работы систем.
Существующие базы данных речевых данных с эффектом реверберации часто сталкиваются с ограничениями по объему, разнообразию и реалистичности, что негативно сказывается на способности автоматических систем распознавания речи (ASR) к обобщению. Недостаточный масштаб таких баз данных не позволяет моделям эффективно обучаться на широком спектре акустических условий, а ограниченное разнообразие помещений и источников звука снижает их устойчивость к различным реальным сценариям. Кроме того, упрощенные модели реверберации, используемые при создании синтетических данных, не всегда точно отражают сложность акустических процессов в реальных помещениях, что приводит к снижению производительности ASR-систем при работе с реальной речью в реверберирующих средах. Таким образом, необходимость в более крупных, разнообразных и реалистичных базах данных речевых данных с эффектом реверберации становится ключевым фактором для дальнейшего развития и повышения надежности систем распознавания речи.
Для достижения значительного прогресса в области автоматического распознавания речи (ASR) в реальных условиях, остро нуждаются в масштабных и качественных корпусах речевых данных, точно отражающих сложность акустических пространств. Существующие наборы данных часто ограничены по размеру, разнообразию акустических сред и степени реалистичности имитации реверберации. Это препятствует созданию ASR-моделей, способных эффективно работать в повседневных сценариях, таких как шумные общественные места или комнаты с различной геометрией. Разработка корпусов, охватывающих широкий спектр акустических условий, включая различные размеры помещений, типы поверхностей и уровни шума, является критически важной задачей для повышения надежности и точности систем распознавания речи в реальном мире. Создание таких ресурсов требует применения передовых методов имитации реверберации и тщательной проверки качества полученных данных.

Создавая Основание: Корпус RIR-Mega
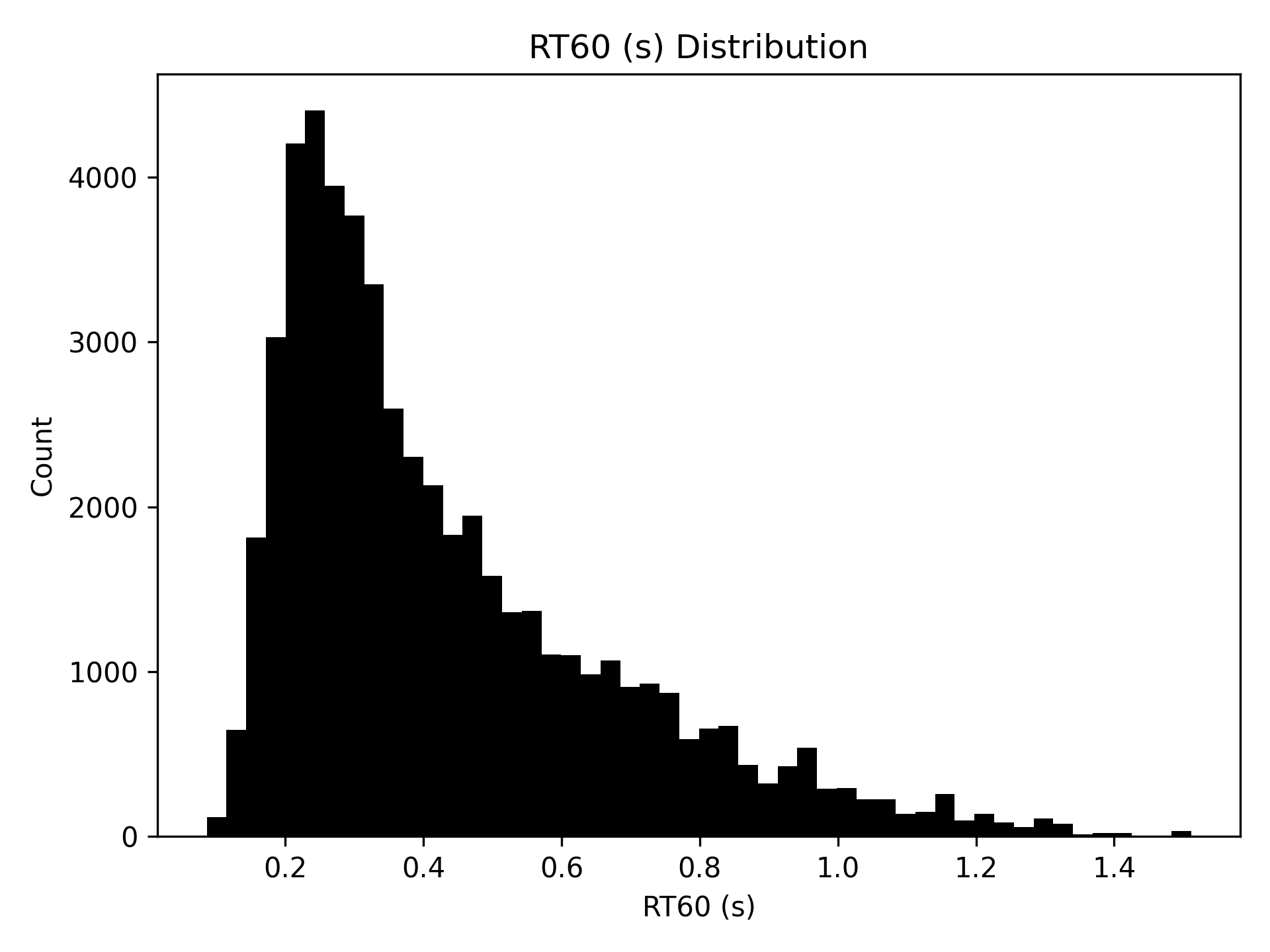
Корпус RIR-Mega представляет собой масштабную коллекцию имитированных импульсных характеристик помещений (Room Impulse Responses, RIR), предназначенную для широкого спектра исследований в области реверберации. В состав корпуса входят тысячи RIR, охватывающих разнообразные геометрические параметры помещений, размеры, материалы отделки и источники звука. Объем данных позволяет проводить статистически значимые исследования, а также тестировать и валидировать алгоритмы обработки звука, моделирующие реверберацию в различных акустических условиях. Доступность и масштабируемость RIR-Mega делают его ценным ресурсом для исследователей и разработчиков в области аудиоинженерии, виртуальной реальности и акустического моделирования.
Импульсные характеристики помещений (IR) в RIR-Mega генерируются посредством акустического моделирования, что обеспечивает точный контроль над характеристиками виртуальных пространств и акустическими параметрами. Этот подход позволяет задавать такие параметры, как размеры помещения, форму, материалы отделки и положение источника и приемника звука, с высокой степенью детализации. В частности, контролируются время реверберации RT_{60}, прямой звук, ранние отражения и плотность поздних отражений, что позволяет создавать IR с заданными акустическими свойствами и исследовать влияние различных параметров на восприятие звука. Метод моделирования позволяет генерировать IR для широкого спектра помещений, которые сложно или невозможно получить в реальных условиях.
Корпус RIR-Mega включает в себя как смоделированные, так и реальные записи импульсных характеристик помещений, что обеспечивает разнообразие данных и возможность проведения исследований в различных условиях. Использование как синтетических, так и эмпирических данных позволяет объединить преимущества контролируемых экспериментов, обеспечиваемых моделированием, с реалистичностью и сложностью, присущей реальным акустическим средам. Такое сочетание позволяет исследователям валидировать результаты моделирования на основе реальных измерений и применять модели, обученные на синтетических данных, к реальным сценариям, тем самым преодолевая разрыв между теоретическими исследованиями и практическими приложениями.
Воссоздавая Реальность: Генерация Реверберирующей Речи
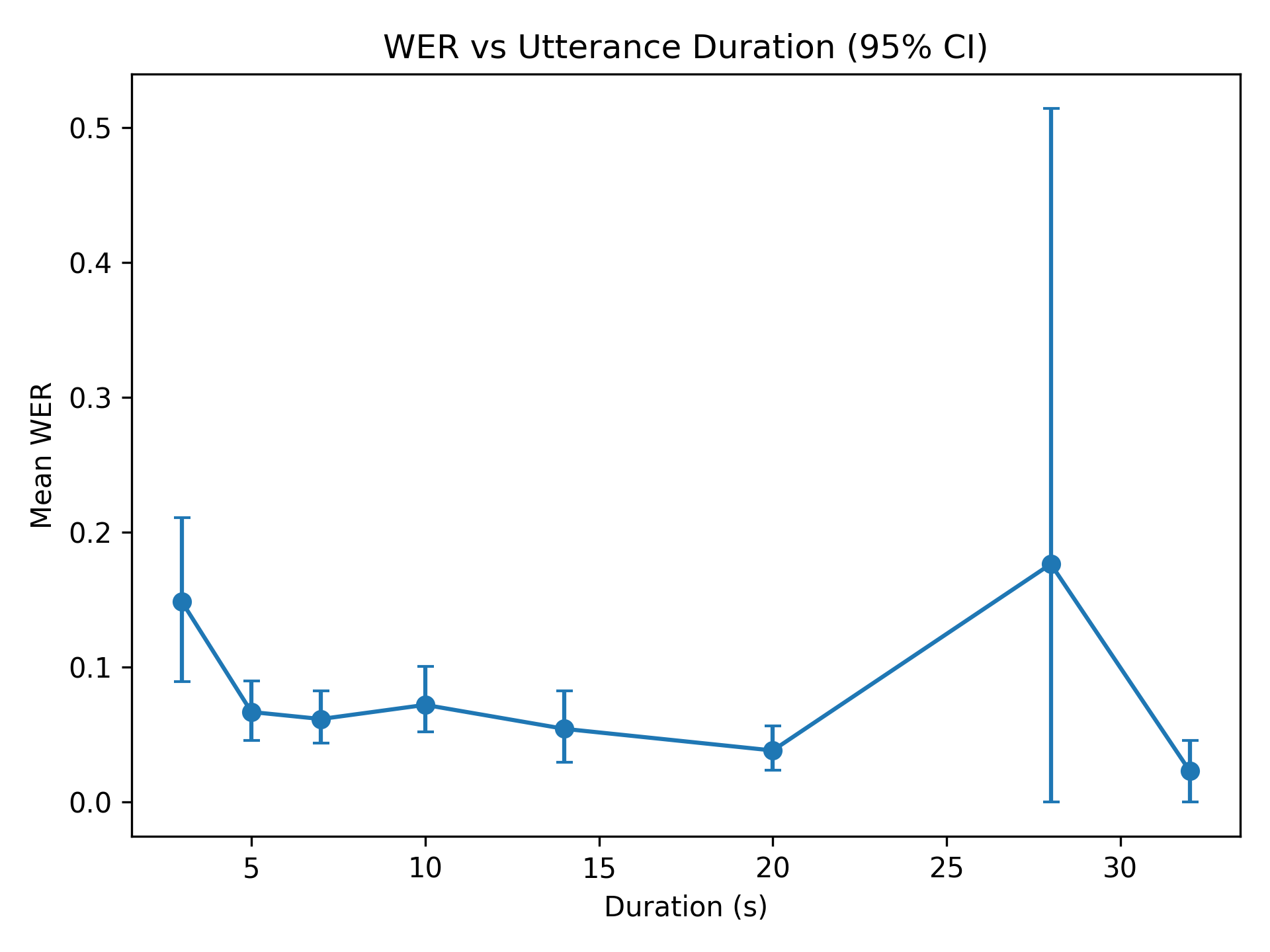
Для создания реалистичных речевых образцов с реверберацией чистая речь из корпуса LibriSpeech подвергалась свертке с импульсными характеристиками RIR-Mega. Этот процесс, известный как свертка, позволяет моделировать распространение звука в различных акустических средах, добавляя к чистой речи эффекты отражений и затухания, характерные для реверберации. Использование RIR-Mega обеспечивает разнообразие акустических условий, поскольку этот корпус содержит импульсные характеристики, измеренные в различных помещениях и с разными параметрами.
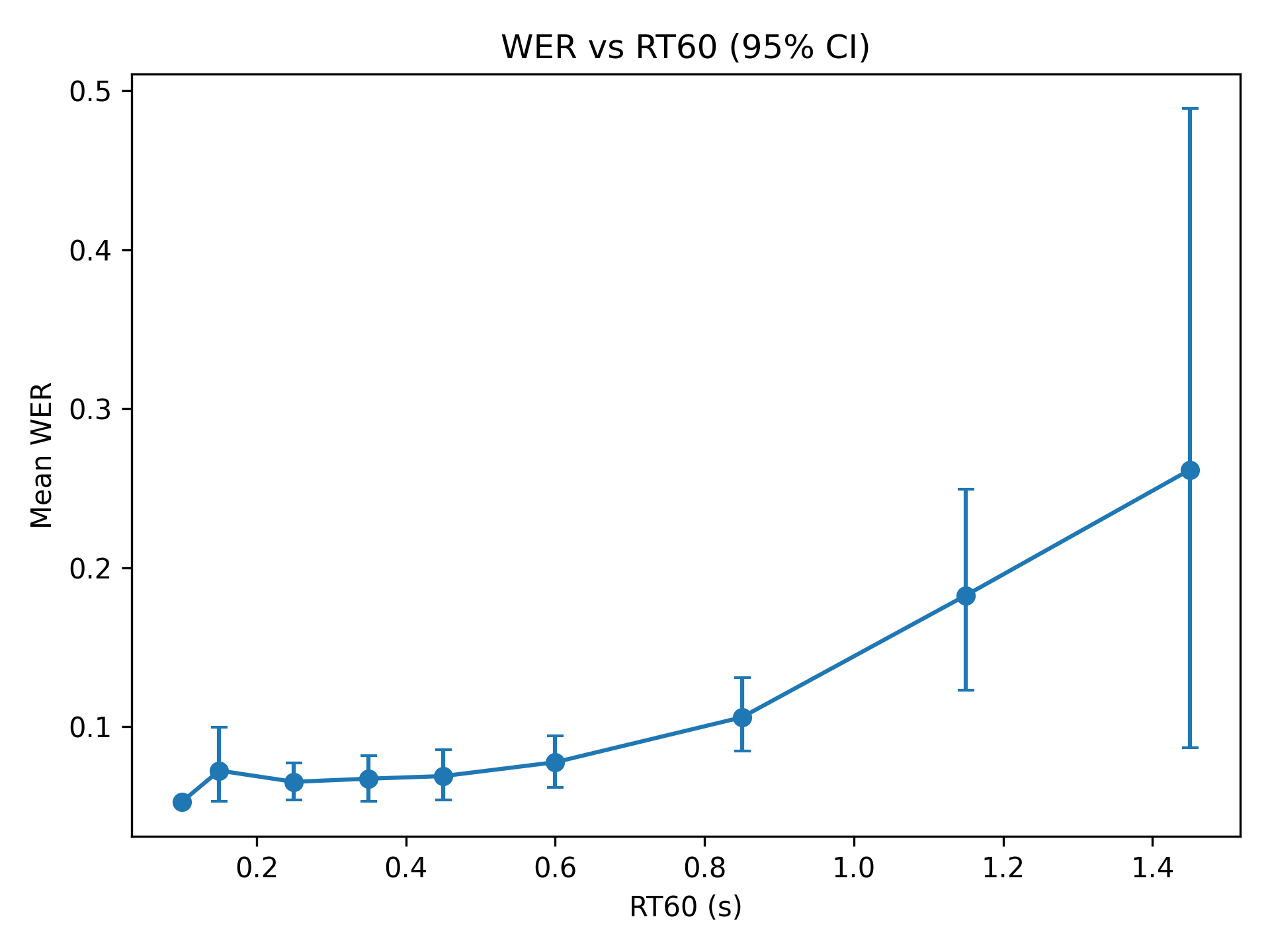
Для детальной акустической характеристики сгенерированных реверберирующих образцов речи вычисляются такие параметры, как RT60 (время реверберации), DRR (отношение прямого к реверберирующему звуку) и C50 (разница в уровне между прямым звуком и звуком, отраженным от ближайших поверхностей). Параметр RT60 измеряет время, необходимое для затухания сигнала на 60 децибел, DRR характеризует соотношение между мощностью прямого звука и мощностью поздних отражений, а C50 предоставляет информацию о различиях в уровне между ранними и поздними отражениями. Эти параметры позволяют количественно оценить акустические свойства помещений, смоделированных импульсными характеристиками, и обеспечить точную оценку реалистичности сгенерированных реверберирующих данных.
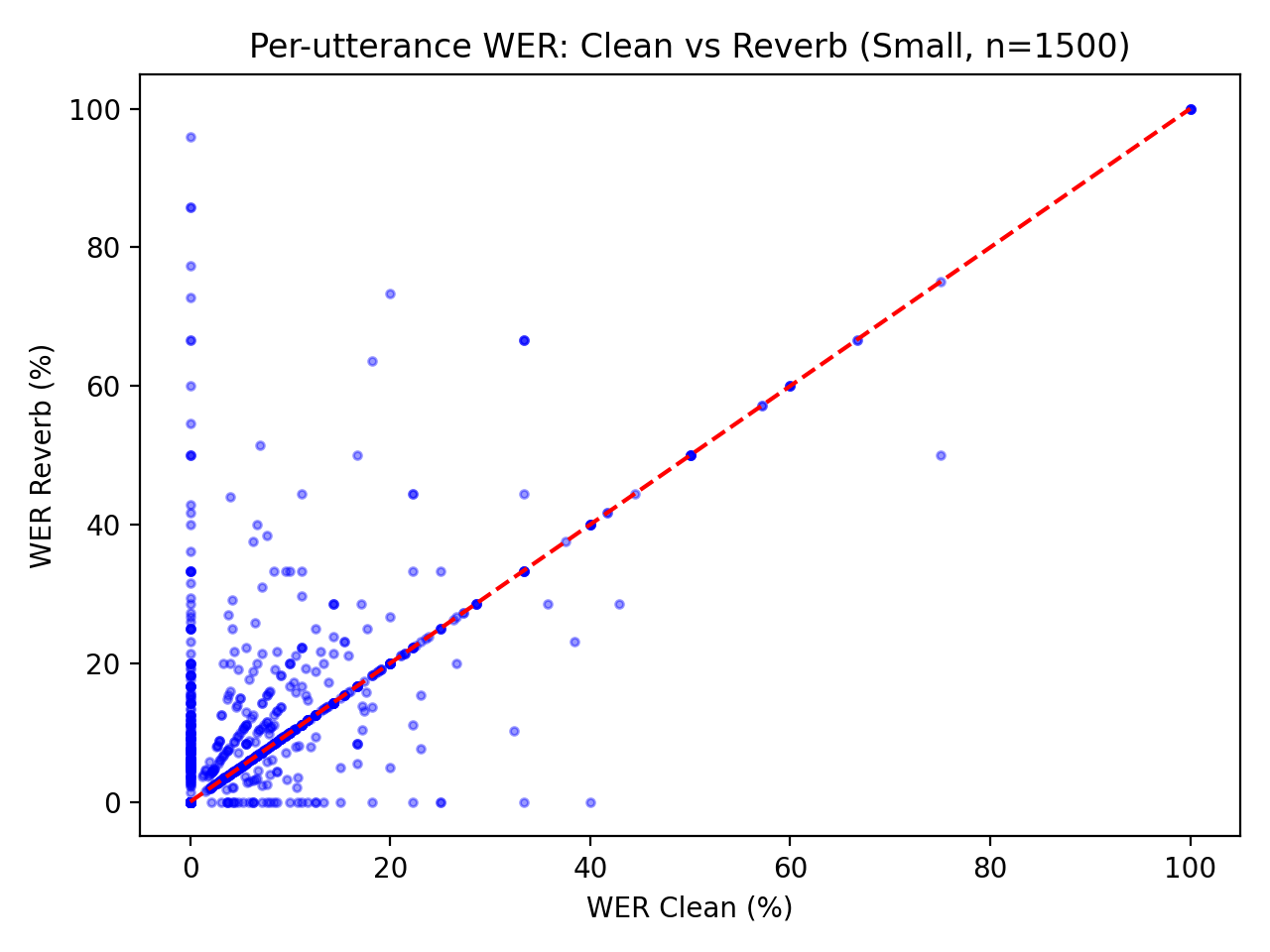
Корпус RIR-Mega-Speech показал увеличение относительной частоты ошибок распознавания речи (WER) на 48% при использовании модели Whisper small для распознавания реверберирующей речи по сравнению с чистой речью. Данный результат указывает на значительное снижение производительности автоматического распознавания речи в условиях реалистичной реверберации, что подтверждает необходимость разработки методов повышения робастности систем распознавания к акустическим искажениям, вызванным реверберацией. Оценка проводилась на основе стандартной метрики WER, отражающей процент неправильно распознанных слов относительно общего количества слов в тестовом наборе.
Проверяя Надежность: Валидация и Воспроизводимость
Для оценки эффективности автоматических систем распознавания речи использовался корпус RIR-Mega-Speech, а в качестве модели — Whisper. Показателем, определяющим точность распознавания, является частота ошибок слов (Word Error Rate, WER). Данный показатель позволяет количественно оценить количество неправильно распознанных слов в речевом сигнале относительно общего числа слов в исходном тексте. Применение корпуса RIR-Mega-Speech, включающего разнообразные речевые данные, в сочетании с метрикой WER, обеспечивает надежную и объективную оценку производительности моделей автоматического распознавания речи в различных акустических условиях, что критически важно для дальнейшего развития и совершенствования этих технологий.
Для обеспечения надёжной оценки производительности систем автоматического распознавания речи применялись методы бутстрэпа. Этот статистический подход позволяет оценить доверительные интервалы для показателя Word Error Rate (WER), что особенно важно при работе с данными, подверженными шумам и искажениям, таким как реверберация. Вместо однократного вычисления WER, бутстрэп многократно перевычисляет его на основе выборок с возвращением из исходного набора данных, позволяя получить распределение вероятностей для WER и, следовательно, более точную и обоснованную оценку производительности модели. Такой подход существенно повышает уверенность в полученных результатах и позволяет более корректно сравнивать различные модели и алгоритмы обработки речи.
Результаты автоматического распознавания речи показали, что базовая частота ошибок WER на чистой речи составила 5.20%. При добавлении эффекта реверберации и использовании модели Whisper small, WER увеличился до 7.70%, что соответствует увеличению на 2.50 процентных пункта. Данное увеличение демонстрирует влияние акустической среды на точность распознавания речи и подчеркивает необходимость разработки алгоритмов, устойчивых к реверберации, для обеспечения надежной работы систем автоматического распознавания в реальных условиях.
Для обеспечения прозрачности и возможности независимой проверки полученных результатов, весь программный код и используемые данные, включая корпус RIR-Mega-Speech, были опубликованы в открытом доступе. Этот шаг направлен на стимулирование воспроизводимости исследований в области реверберации и позволяет другим ученым самостоятельно верифицировать представленные выводы, а также использовать данные для дальнейших разработок и экспериментов. Открытый доступ к ресурсам способствует развитию научного сообщества и ускоряет прогресс в области автоматического распознавания речи в сложных акустических условиях.
Представленный корпус RIR-Mega-Speech, с его детальными данными об импульсных характеристиках помещений и тщательно задокументированными акустическими параметрами, словно пытается обуздать хаос отражений, чтобы сделать речь более понятной для машин. Это напоминает о словах Томаса Гоббса: «Человеческая природа — это война всех против всех». В данном контексте, это можно интерпретировать как постоянную борьбу между сигналом и шумом, между желанием передать информацию и неизбежными искажениями, возникающими в реальном акустическом окружении. Корпус, стремясь к воспроизводимости, как бы возводит барьер против этой анархии, предлагая стандартизированную площадку для оценки устойчивости систем распознавания речи. Каждое измерение, каждое задокументированное значение RT60 и DRR — это попытка примирить желание понять и реальность, которая не всегда желает быть понятой.
Что дальше?
Представленный корпус, стремясь к стандартизации оценки робастности систем распознавания речи, лишь обнажает глубину нерешённых проблем. Любая попытка зафиксировать акустическую реальность в наборе параметров, даже столь подробных, как RT60 и DRR, подобна попытке удержать бесконечность на листе бумаги. Корпус, безусловно, облегчает сравнение алгоритмов, но истинное понимание требует признания, что идеальной модели реверберации не существует.
Следующим шагом представляется не столько увеличение объёма данных, сколько углубление понимания механизмов взаимодействия звука и пространства. Необходимо исследовать, как субъективное восприятие реверберации влияет на эффективность систем распознавания, ведь даже самые точные метрики могут упустить нюансы, важные для человеческого слуха. Чёрные дыры учат терпению и скромности; они не принимают ни спешки, ни шумных объявлений.
В конечном счёте, задача состоит не в создании идеального корпуса, а в развитии методологии, позволяющей адаптироваться к неизбежной неопределённости. Любая гипотеза о сингулярности — в данном случае, об идеальной модели акустической среды — лишь приближение, которое всегда будет нуждаться в пересмотре и уточнении. Поиск робастных алгоритмов — это не покорение реверберации, а смирение перед её сложностью.
Оригинал статьи: https://arxiv.org/pdf/2601.19949.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Взлом языковых моделей: эволюция атак, а не подсказок
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Кванты в Финансах: Не Шутка!
- Квантовый оптимизатор: Новый подход к сложным задачам
- Разделяй и властвуй: Новый подход к классификации текстов
- Врачебные диагнозы и искусственный интеллект: как формируются убеждения?
- Обучение с подкреплением и причинность: как добиться надёжных выводов
- Глубокое обучение на службе обратных задач: новый взгляд на оптимизацию
2026-01-30 05:48