Автор: Денис Аветисян
Новый подход к генеративным рекомендациям позволяет более эффективно исследовать варианты и выбирать наиболее ценные предложения для пользователя.
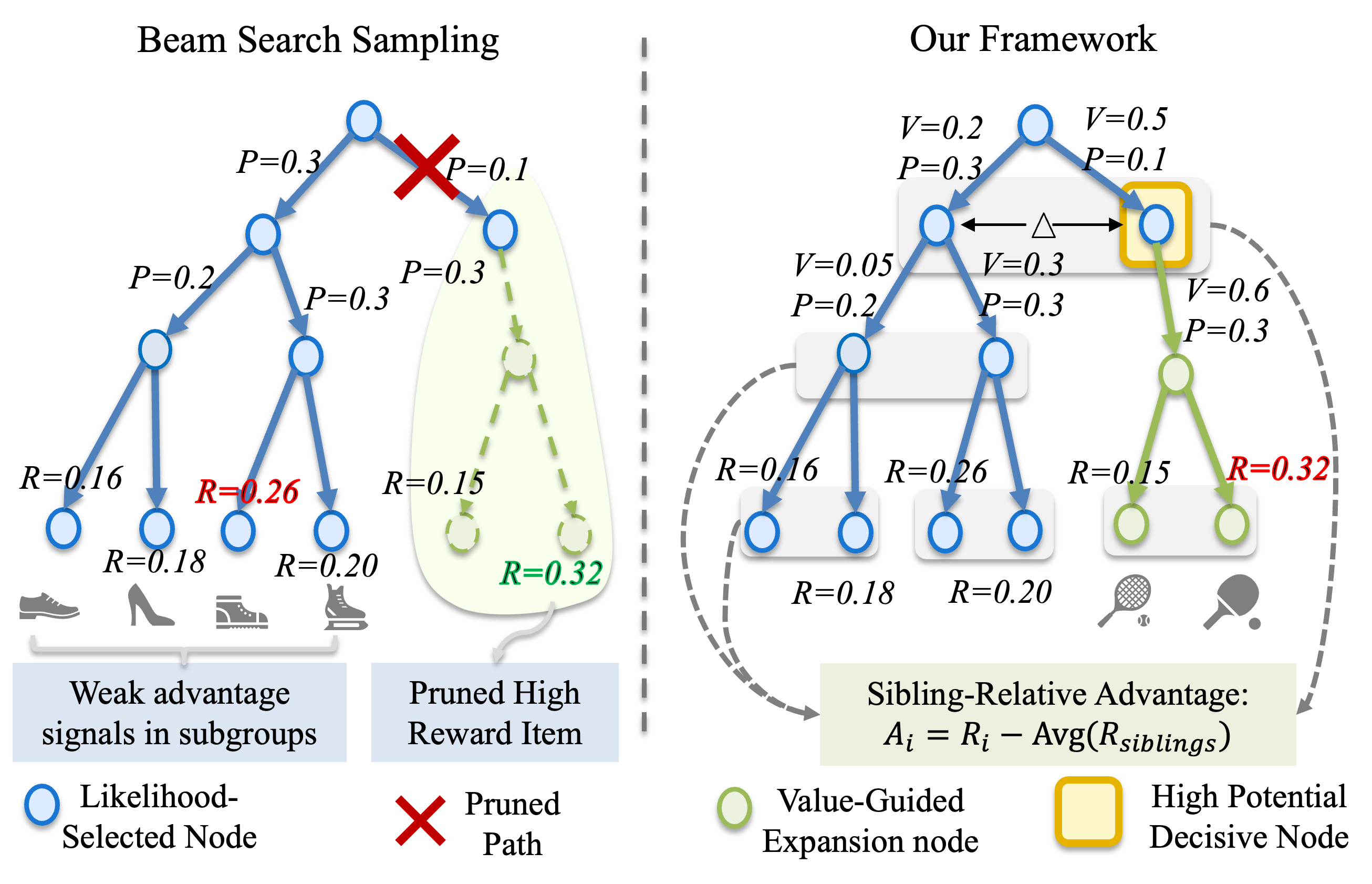
Представлен фреймворк V-STAR, использующий управляемое ценностью декодирование и групповое обучение с подкреплением для повышения производительности и эффективности рекомендаций.
Несмотря на успехи генеративных рекомендательных систем, обучение с подкреплением часто сталкивается с проблемой несоответствия между вероятностью и вознаграждением. В работе ‘Spend Search Where It Pays: Value-Guided Structured Sampling and Optimization for Generative Recommendation’ предложен фреймворк V-STAR, направленный на решение этой проблемы путем интеллектуального исследования пространства кандидатов и стабилизации обучения с помощью нового подхода к вычислению преимуществ. V-STAR использует декодирование с учетом ценности и групповое обучение с подкреплением, что позволяет значительно повысить точность и разнообразие рекомендаций при жестких ограничениях по времени отклика. Сможет ли предложенный подход стать основой для создания более эффективных и персонализированных рекомендательных систем нового поколения?
Преодолевая Ограничения Последовательного Моделирования: Эра Генеративных Рекомендаций
Традиционные методы последовательной рекомендации, такие как GRU4Rec, Caser и SASRec, часто испытывают трудности при анализе длительных цепочек взаимодействия пользователя с системой. Эти модели, хоть и эффективны в краткосрочном прогнозировании, не всегда способны уловить сложные взаимосвязи между прошлыми действиями и будущими предпочтениями. В частности, они сталкиваются с проблемой удержания информации о более ранних взаимодействиях, что ограничивает их способность учитывать долгосрочные интересы пользователя. Кроме того, существующие алгоритмы часто упрощают представление о разнообразии вкусов, предлагая рекомендации, которые могут быть слишком однообразными и не учитывать широкий спектр предпочтений, формирующихся со временем. Это приводит к снижению релевантности предложений и, как следствие, к неудовлетворенности пользователей.
Рекомендательные системы претерпевают фундаментальный сдвиг, переходя от традиционного последовательного моделирования к генеративному подходу. Вместо предсказания следующего элемента в последовательности действий пользователя, генеративные модели рассматривают задачу рекомендации как задачу генерации последовательности, подобно тому, как современные большие языковые модели генерируют текст. Этот подход позволяет использовать мощь и гибкость архитектур, разработанных для обработки естественного языка, для построения более точных и разнообразных рекомендаций. Вместо простого запоминания прошлых взаимодействий, система способна генерировать рекомендации, основываясь на более глубоком понимании предпочтений пользователя и контекста, что открывает возможности для персонализации на качественно новом уровне и предвосхищения будущих потребностей.
Непосредственное применение больших языковых моделей в задачах рекомендаций сталкивается с определенными трудностями, обусловленными необходимостью преодоления разрыва между представлением товаров и их семантическим пониманием. Традиционные методы кодирования товаров зачастую ограничиваются числовыми идентификаторами или простыми векторными представлениями, не отражающими их характеристики и взаимосвязи. Для эффективного использования генеративных моделей требуется обогащение этих представлений, позволяющее модели не просто предсказывать следующий товар в последовательности, но и понимать его суть, категорию и потенциальную привлекательность для пользователя. Разработка методов, способных извлекать и кодировать семантическую информацию о товарах, становится ключевым направлением исследований в области генеративных рекомендательных систем, открывая возможности для более персонализированных и релевантных предложений.
Семантическая Основа: Связывая Товары и Язык
Семантические идентификаторы (Semantic IDs) представляют собой иерархическую структуру, позволяющую кодировать характеристики товаров в формат, пригодный для использования в языковых моделях. Данная иерархия организует информацию о товарах по уровням абстракции, от общих категорий к конкретным атрибутам, что обеспечивает детальное представление каждого товара. Преобразование характеристик товара в семантические идентификаторы позволяет модели воспринимать товары не как изолированные единицы, а как элементы, связанные между собой в семантическом пространстве, что необходимо для эффективного моделирования предпочтений пользователей и генерации релевантных рекомендаций. Такое представление данных облегчает применение методов обработки естественного языка к задачам рекомендаций.
RQ-VAE (Variational Autoencoder с Рациональными Ограничениями) играет ключевую роль в процессе кодирования элементов в Семантические ID. Данная архитектура нейронной сети обучается отображать характеристики каждого элемента в компактное, векторное представление — Семантический ID. Обучение происходит путем минимизации ошибки реконструкции, то есть способности сети восстановить исходные характеристики элемента из его Семантического ID. Использование рациональных ограничений в процессе обучения позволяет формировать более структурированные и интерпретируемые Семантические ID, что способствует повышению точности и эффективности рекомендательной системы. Фактически, RQ-VAE преобразует сложное описание элемента в унифицированный код, пригодный для обработки в рамках языковой модели.
Основываясь на семантическом значении, модель способна более точно интерпретировать намерения пользователя и генерировать более релевантные рекомендации. Вместо анализа только поверхностных характеристик предметов или истории взаимодействия, система учитывает глубинное семантическое представление, что позволяет предлагать товары или контент, соответствующие интересам пользователя даже в случае отсутствия прямой истории взаимодействия. Повышение релевантности достигается за счет использования семантических идентификаторов, которые отражают не только атрибуты предмета, но и его роль в более широком контексте.
Оптимизация Генерации: Обучение с Подкреплением и Эффективное Декодирование
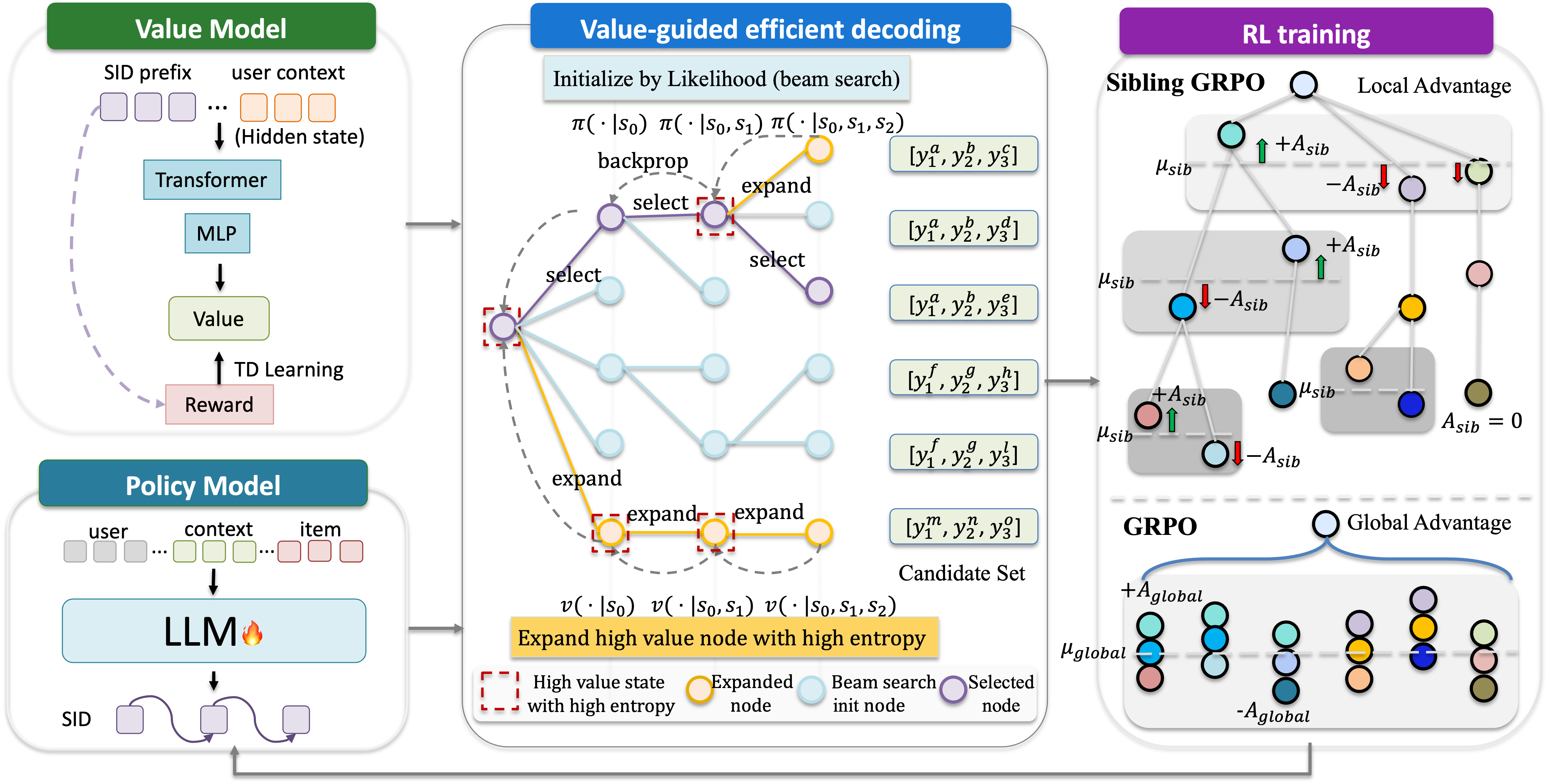
Обучение с подкреплением (RL) предоставляет эффективный механизм для оптимизации политики генерации рекомендаций, напрямую максимизируя получаемое пользователем вознаграждение. В отличие от традиционных методов, которые оптимизируют вероятность генерации токенов, RL позволяет оптимизировать непосредственно целевую функцию, отражающую ценность рекомендации для пользователя, например, вероятность клика или покупки. Это достигается путем моделирования взаимодействия пользователя с рекомендательной системой как процесса принятия решений Маркова, где агент (рекомендательная система) принимает действия (генерацию токенов), а пользователь предоставляет обратную связь в виде вознаграждения. Использование алгоритмов RL, таких как Q-learning или Policy Gradients, позволяет агенту научиться генерировать последовательности, которые максимизируют ожидаемое суммарное вознаграждение за весь сеанс взаимодействия.
Эффективное декодирование с использованием функции ценности (Value Function) направляет процесс поиска, динамически распределяя вычислительные ресурсы в пользу перспективных префиксов генерируемой последовательности. Вместо равномерного исследования всех возможных вариантов, алгоритм оценивает потенциальную ценность каждого префикса, определяемую функцией ценности, и сосредотачивает вычисления на тех префиксах, которые, вероятно, приведут к более высокой награде. Это позволяет значительно ускорить процесс генерации, сокращая время, необходимое для создания рекомендуемой последовательности, и повышая общую эффективность системы рекомендаций. Приоритезация перспективных префиксов достигается за счет использования функции ценности как критерия для отбора и ранжирования вариантов на каждом шаге генерации.
Стандартные методы декодирования, такие как жадное декодирование или выборка, оптимизированы для максимизации вероятности генерируемой последовательности, что не всегда соответствует максимизации целевой функции рекомендации (например, долгосрочному вознаграждению от взаимодействия с пользователем). Это несоответствие между вероятностью и вознаграждением (Probability-Reward Misalignment) приводит к генерации последовательностей, которые статистически вероятны, но не оптимальны с точки зрения рекомендаций. Предложенный подход решает эту проблему, напрямую оптимизируя генерацию последовательностей для максимизации ожидаемого вознаграждения, а не просто вероятности, обеспечивая соответствие генерируемых рекомендаций поставленной задаче.
Устранение Ограничений Оптимизации: Sibling-GRPO и Сжатие Преимуществ
Sibling-GRPO, развиваясь на основе метода Group-Relative Optimization, решает проблему сжатия преимуществ (Advantage Compression) путем нормализации оценок преимущества внутри групп “соседних” кандидатов. Этот подход предполагает, что при обучении с подкреплением, оценка преимущества конкретного кандидата нормализуется относительно оценок преимуществ других кандидатов, находящихся в той же группе. Нормализация позволяет снизить дисперсию оценок и стабилизировать процесс обучения, поскольку абсолютная величина преимущества становится менее значимой, а важным становится лишь относительное сравнение с другими кандидатами в группе. Фактически, Sibling-GRPO использует информацию о взаимосвязи между кандидатами для более эффективной оценки их ценности.
Нормализация преимуществ внутри групп «сиблингов» способствует повышению стабильности обучения за счет уменьшения дисперсии градиентов и предотвращения эффекта «затухания» сигналов. Это позволяет модели более эффективно различать схожие кандидаты, поскольку уменьшает влияние избыточных наград и акцентирует внимание на реальных различиях в ожидаемых результатах. Улучшенная дифференциация кандидатов приводит к более точному построению ранжирования и, как следствие, к повышению эффективности процесса обучения с подкреплением.
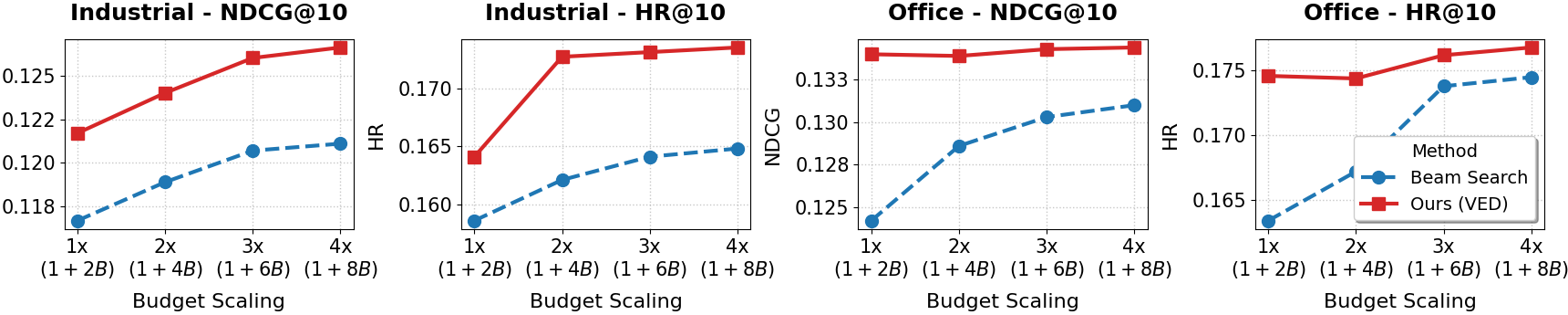
Метод Sibling-GRPO повышает эффективность обучения с подкреплением за счет снижения потерь сигнала, возникающих из-за избыточных наград. В ходе экспериментов на наборе данных Office было зафиксировано относительное улучшение метрики HR@3 до 10.4% по сравнению со стандартными подходами. Это улучшение обусловлено более точной оценкой преимуществ различных кандидатов, что позволяет модели быстрее сходиться к оптимальному решению и более эффективно использовать данные для обучения.
Взгляд в Будущее: К Интеллектуальным и Адаптивным Рекомендациям
Сочетание генеративных моделей, семантического понимания и обучения с подкреплением открывает путь к созданию принципиально новых рекомендательных систем. Традиционные подходы, основанные на анализе коллаборативных фильтров или контент-базированных методах, зачастую ограничены в способности генерировать действительно релевантные и неожиданные предложения. Интеграция генеративных моделей позволяет создавать рекомендации «с нуля», учитывая сложные взаимосвязи между элементами и предпочтениями пользователя. Семантическое понимание, в свою очередь, обеспечивает глубокий анализ не только явных характеристик объектов, но и скрытых смыслов, позволяя предлагать товары или контент, соответствующие интересам пользователя даже в случае отсутствия прямой истории взаимодействия. Обучение с подкреплением позволяет системе непрерывно адаптироваться к меняющимся предпочтениям, оптимизируя стратегии генерации рекомендаций и максимизируя долгосрочную ценность для пользователя. Такой симбиоз технологий обещает революционизировать сферу персонализированных рекомендаций, переходя от простого предсказания к настоящему интеллектуальному взаимодействию.
В основе адаптивной генерации рекомендаций лежит принцип, сочетающий в себе эффективное декодирование, ориентированное на ценность, и баланс между исследованием и использованием (exploration-exploitation tradeoff). Данный подход позволяет системе не просто предлагать наиболее популярные товары, но и учитывать индивидуальные предпочтения каждого пользователя. Эффективное декодирование, в свою очередь, оптимизирует процесс генерации рекомендаций, снижая вычислительные затраты и повышая скорость ответа. Баланс между исследованием и использованием позволяет системе предлагать как проверенные, хорошо зарекомендовавшие себя товары, так и новые, потенциально интересные позиции, расширяя горизонты выбора и повышая вероятность обнаружения пользователем действительно подходящего продукта. Именно такое сочетание факторов обеспечивает динамическую адаптацию рекомендаций к меняющимся потребностям и вкусам каждого конкретного пользователя, создавая персонализированный и эффективный опыт взаимодействия с системой.
Проведенное онлайн A/B тестирование продемонстрировало значительное повышение эффективности предложенного подхода к рекомендациям. В результате эксперимента зафиксировано увеличение объема валовой прибыли (GMV) на 1.23% относительно контрольной группы. При нормализации данных, учитывающей сезонные колебания и другие внешние факторы, прирост GMV достиг 1.87%. Эти результаты подтверждают, что разработанная система не только способна генерировать более релевантные рекомендации, но и оказывает ощутимое положительное влияние на ключевые бизнес-показатели, что свидетельствует о ее практической ценности и потенциале для широкого внедрения.
Исследование, представленное в данной работе, подчеркивает важность не просто достижения работоспособности алгоритма, но и его математической корректности. Авторы предлагают V-STAR, фреймворк, направленный на оптимизацию генеративных рекомендаций через структурированное исследование пространства кандидатов и стабилизацию обучения. Этот подход созвучен принципам, которыми руководствовался Давид Гильберт, утверждавший: «В математике нет «или-или», есть только «да» и «нет». Любое утверждение либо истинно, либо ложно, и его следует доказывать». Как и в математике, где необходима строгость доказательств, V-STAR стремится к надежным и предсказуемым результатам, обеспечивая тем самым более эффективные и обоснованные рекомендации, в особенности используя value-guided decoding для направленного исследования.
Куда Далее?
Представленная работа, хотя и демонстрирует улучшение в области генеративных рекомендаций, лишь подчёркивает фундаментальную сложность задачи. Эффективное исследование пространства кандидатов — это не просто вопрос оптимизации алгоритма поиска, но и глубокое понимание семантической структуры данных. Использование семантических идентификаторов — это шаг в верном направлении, однако, истинная элегантность заключается в создании системы, способной самостоятельно выводить эти идентификаторы, а не полагаться на предопределённые. Вопрос согласования награды, решаемый предложенным group-relative подходом, является необходимым, но не достаточным. Необходимо стремиться к созданию метрик, отражающих истинную ценность рекомендации для пользователя, а не просто кликабельность.
Очевидным направлением для дальнейших исследований является исследование обобщающей способности предложенного подхода. Достаточно ли улучшения, чтобы гарантировать стабильную работу в динамически меняющихся условиях? Проблема exploration-exploitation, хоть и смягчена, остаётся актуальной. Необходимо разработать методы, позволяющие алгоритму эффективно адаптироваться к новым данным, не теряя при этом накопленные знания. Простое увеличение размера обучающей выборки не является решением; необходимо стремиться к алгоритмической чистоте, к решению, которое доказуемо сходится к оптимальному.
В конечном счёте, истинный прогресс в области рекомендательных систем заключается не в увеличении точности на несколько процентов, а в создании систем, способных понимать потребности пользователя на глубинном уровне. Это требует не только усовершенствования алгоритмов, но и междисциплинарного подхода, объединяющего достижения в области машинного обучения, когнитивной науки и психологии. Иначе все эти ухищрения останутся лишь изящными, но бессмысленными упражнениями в математической оптимизации.
Оригинал статьи: https://arxiv.org/pdf/2602.10699.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Искусственный интеллект на службе физики высоких энергий
- Стратегия подцелей: Как научить ИИ долгосрочному планированию
- Квантовая неопределенность: новый взгляд на измерения
- Квантовые машины Больцмана для обучения с подкреплением: новый подход
- Квантовые Иллюзии и Практические Шаги
- Геном под контролем: Ускорение анализа данных для персонализированной медицины
- Вероятностный интеллект на скорости света: новые горизонты машинного обучения
2026-02-12 23:52