Автор: Денис Аветисян
Исследователи предлагают инновационный метод, позволяющий роботам планировать действия, основываясь на последовательном рассуждении в пространстве действий.
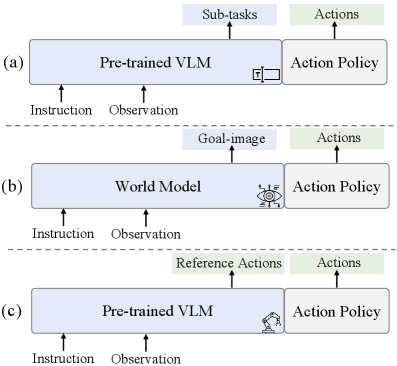
В статье представлена методика Action Chain-of-Thought (ACoT) для улучшения обобщающей способности и производительности моделей, объединяющих зрение, язык и управление действиями робота, за счет преодоления разрыва между семантикой и кинематикой.
Несмотря на успехи моделей «Vision-Language-Action» (VLA) в обучении роботов манипуляциям, перевод многомодальных данных непосредственно в действия часто оказывается недостаточно точным. В данной работе, представленной под названием ‘ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models’, предлагается новый подход, фокусирующийся на рассуждениях непосредственно в пространстве действий, — парадигма «Action Chain-of-Thought» (ACoT). Разработанная архитектура ACoT-VLA, включающая компоненты явного и неявного рассуждения об действиях, позволяет преодолеть семантический и кинематический разрыв, значительно повышая обобщающую способность и эффективность обучения роботов. Сможет ли подобный подход стать основой для создания действительно универсальных и надежных систем управления роботами в реальном мире?
Семантико-Кинематический Разрыв: Суть Проблемы
В робототехнике существует фундаментальное противоречие — так называемый «семантико-кинематический разрыв», который разделяет абстрактные цели и конкретные команды для моторов. Роботы часто сталкиваются с трудностями при переводе высокоуровневых инструкций, таких как «подай чашку», в последовательность точных движений суставов и моторов. Это происходит из-за того, что системы управления традиционно оперируют низкоуровневыми данными о положении и скорости, не учитывая смысл задачи. Неспособность преодолеть этот разрыв ограничивает возможности роботов в выполнении сложных, требующих понимания контекста операций, и является серьезным препятствием на пути к созданию действительно автономных и интеллектуальных машин. Разработка методов, позволяющих эффективно соотносить намерения с физическими действиями, представляет собой ключевую задачу современной робототехники.
Традиционные методы управления роботами часто сталкиваются с трудностями при преобразовании высокоуровневых инструкций в точные, исполняемые действия. Например, при команде “подай чашку кофе”, робот должен не только распознать объект и понять цель, но и спланировать сложную последовательность движений — захват, перемещение, избежание препятствий — учитывая хрупкость объекта и особенности окружающей среды. Неспособность эффективно решать эту задачу приводит к неточностям, ошибкам и, в конечном итоге, к невозможности выполнения сложных манипуляций, ограничивая возможности роботов в реальных условиях и требуя постоянного вмешательства человека. Проблема заключается в том, что существующие алгоритмы часто полагаются на заранее запрограммированные сценарии или требуют детального описания каждого шага, что делает их негибкими и неспособными адаптироваться к меняющимся обстоятельствам.
Существующий разрыв между пониманием намерения и выполнением действий требует принципиально нового подхода к управлению роботами. Традиционные методы, основанные на прямой трансляции команд, часто оказываются неэффективными при решении сложных задач, поскольку не учитывают контекст и не позволяют роботу адаптироваться к изменяющимся условиям. Необходим переход к системам, способным интерпретировать высокоуровневые инструкции, планировать последовательность действий и преобразовывать их в точные моторные команды, учитывая физические ограничения и особенности окружающей среды. Разработка таких систем предполагает интеграцию методов искусственного интеллекта, таких как машинное обучение и обработка естественного языка, с алгоритмами управления движением, что позволит роботам не просто выполнять заданные команды, а понимать их смысл и действовать автономно, приближаясь к уровню человеческого интеллекта и ловкости.

Action CoT: Руководство Действиями в Пространстве Возможностей
Action CoT — это новый подход к управлению роботами, который функционирует непосредственно в пространстве действий, обеспечивая единообразное (гомогенное) руководство. В отличие от традиционных методов, оперирующих в пространстве состояний или с использованием сложных иерархий, Action CoT позволяет напрямую генерировать и контролировать последовательность действий робота. Это обеспечивает более предсказуемое и стабильное управление, поскольку каждая команда соответствует конкретному действию в физическом мире, упрощая отладку и анализ поведения робота. Такой подход позволяет избежать неоднозначности, связанной с интерпретацией состояний, и обеспечивает более прямое соответствие между задачей и исполняемыми действиями.
Метод Action CoT использует принцип цепочки рассуждений (Chain-of-Thought) для разбиения сложных задач на последовательность промежуточных действий. Этот подход позволяет не просто генерировать финальное действие, а формировать логическую цепочку шагов, что повышает предсказуемость поведения робота. Разложение задачи на более мелкие, управляемые этапы упрощает отладку и анализ ошибок, а также повышает устойчивость системы к непредсказуемым ситуациям и шуму в данных, поскольку отдельные шаги более легко корректируются и контролируются. Такая декомпозиция задачи обеспечивает более надежное и последовательное выполнение, особенно в сложных и динамичных окружениях.
Ключевым аспектом Action CoT является концепция “Руководства в пространстве действий” (Action Space Guidance), обеспечивающая эффективную и интерпретируемую генерацию действий робота. Вместо прямого предсказания конечных состояний или траекторий, система генерирует последовательность промежуточных действий, каждое из которых соответствует конкретному элементу пространства возможных действий робота. Это позволяет более точно контролировать поведение робота и упрощает анализ причинно-следственных связей между действиями и результатами. Руководство в пространстве действий позволяет избежать непредсказуемых или нежелательных действий, повышая надежность и безопасность роботизированных систем, особенно в сложных и динамичных средах.
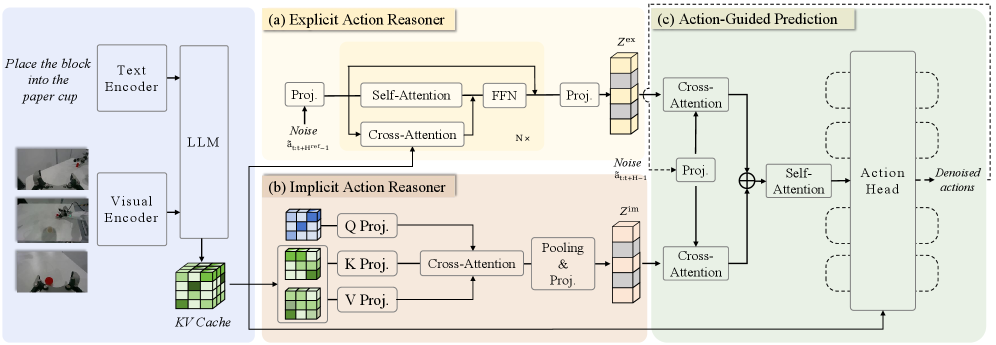
Явное и Неявное Рассуждение: Синергия в Действии
В рамках фреймворка Action CoT используется два основных модуля рассуждений: «Неявный Планировщик Действий» (Implicit Action Reasoner) и «Явный Планировщик Действий» (Explicit Action Reasoner). Неявный планировщик выводит скрытые априорные знания о возможных действиях, основываясь на контексте задачи и предыдущем опыте. Явный планировщик, в свою очередь, синтезирует грубые траектории движения, определяя последовательность действий для достижения цели. Взаимодействие этих модулей позволяет эффективно комбинировать интуитивные предположения о действиях с конкретными планами, повышая общую производительность системы.
В рамках Action CoT, взаимодействие между ‘Неявным Рассудителем Действий’ и ‘Явным Рассудителем Действий’ осуществляется посредством механизма ‘Прогнозирование, управляемое действиями’. Этот механизм объединяет выходы обоих модулей, используя информацию, полученную от каждого из них, для уточнения и оптимизации конечной последовательности действий. В частности, ‘Прогнозирование, управляемое действиями’ использует неявные априорные знания о возможных действиях, полученные от ‘Неявного Рассудителя’, и комбинирует их с более грубыми траекториями движения, сгенерированными ‘Явным Рассудителем’, для создания более точной и согласованной последовательности действий.
Явный планировщик действий обучается с использованием метода “Flow Matching”, представляющего собой генеративный подход к моделированию траекторий. Данный метод позволяет эффективно отображать шум в целевые траектории, обеспечивая высокую точность и скорость генерации движений. В отличие от традиционных методов, Flow Matching напрямую моделирует векторное поле, связывающее шум и траектории, что снижает вычислительные затраты и повышает стабильность обучения. Применение Flow Matching гарантирует, что сгенерированные траектории соответствуют желаемым целям и ограничениям, что критически важно для реалистичного и управляемого поведения агента.
Проверка Надежности: Устойчивость в Реальных Условиях
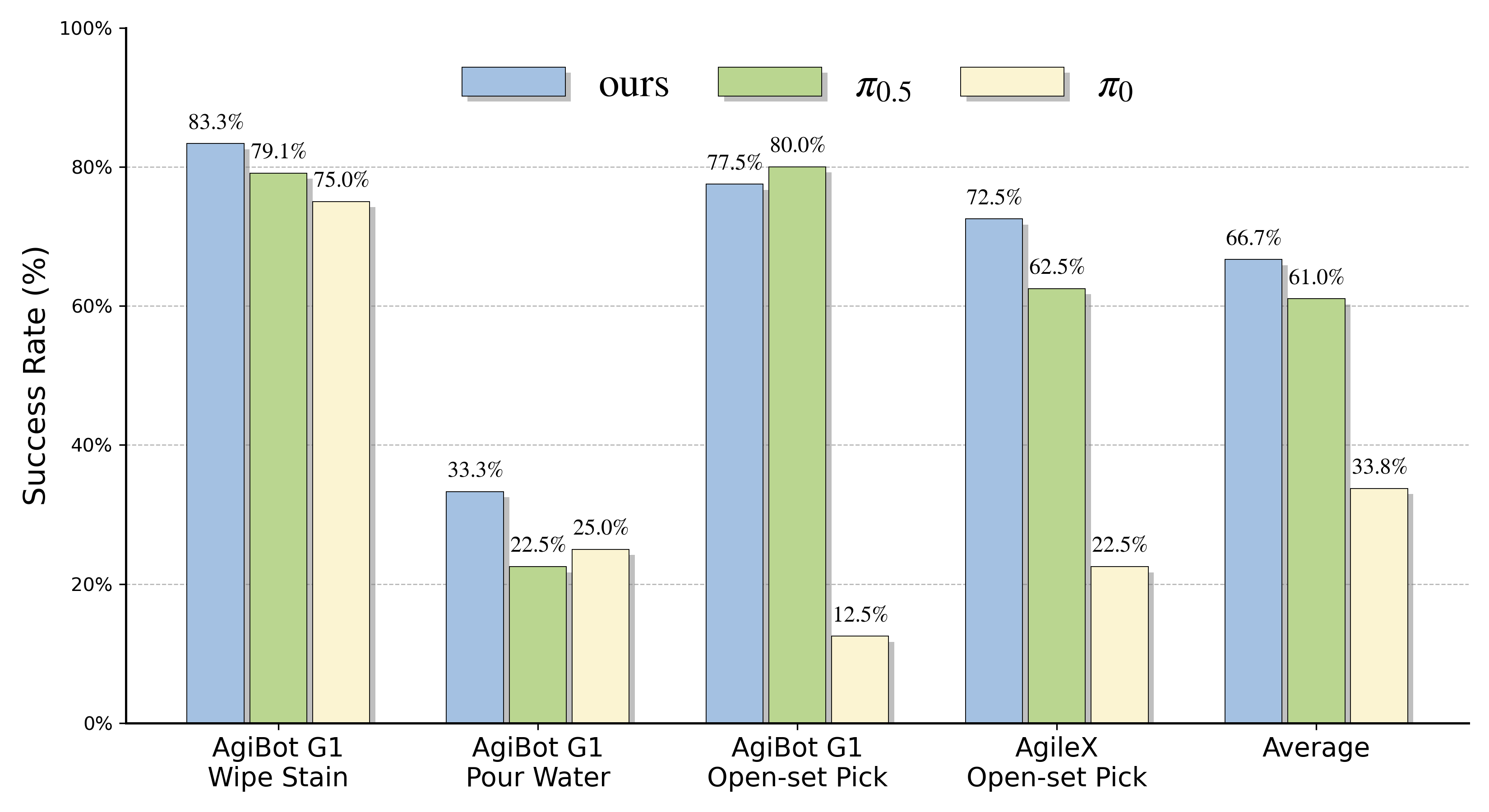
Оценка разработанного подхода проводилась на бенчмарках VLABench и LIBERO, что позволило продемонстрировать его способность к обобщению на широкий спектр задач робототехники. VLABench представляет собой набор симуляций, охватывающих манипуляции с различными объектами и в различных условиях, в то время как LIBERO специализируется на задачах сборки, требующих высокой точности и координации. Успешное прохождение этих бенчмарков подтверждает, что предложенный метод не ограничен конкретным типом задач или специфическими условиями, а способен адаптироваться к новым, ранее не встречавшимся сценариям, что критически важно для практического применения в реальных робототехнических системах.
Для подтверждения устойчивости разработанного метода к возмущениям и шуму, проведена валидация на более сложной тестовой среде ‘LIBERO-Plus’. Данный бенчмарк характеризуется повышенным уровнем неопределенности и случайных помех, имитирующих реальные условия эксплуатации робототехнических систем. Результаты тестирования на ‘LIBERO-Plus’ показали, что предложенный подход сохраняет работоспособность и обеспечивает высокую точность выполнения задач даже при наличии значительных возмущений, подтверждая его надежность и применимость в сложных сценариях.
В ходе сравнительного анализа производительности предложенного метода на эталонных наборах данных ‘VLABench’, ‘LIBERO’ и ‘LIBERO-Plus’ были достигнуты следующие результаты: 98.5% успешных выполнений на ‘LIBERO’, 84.1% на ‘LIBERO-Plus’ и 47.4% на ‘VLABench’. Данный показатель на ‘LIBERO’ демонстрирует улучшение на 1.6% по сравнению с предыдущими передовыми решениями, подтверждая эффективность разработанного подхода в задачах роботизированного управления.
Для повышения точности выполнения действий и обеспечения надежности системы используются методы управления, включающие контроль перемещения концевого эффектора (Delta End-Effector Control) и абсолютный контроль суставов (Absolute Joint Control). Контроль перемещения концевого эффектора позволяет напрямую управлять положением и ориентацией инструмента, что особенно важно для задач, требующих высокой точности позиционирования. Абсолютный контроль суставов обеспечивает точное управление каждым суставом робота, что необходимо для выполнения сложных траекторий и поддержания стабильности системы. Интеграция этих методов позволяет компенсировать погрешности и обеспечить плавное и точное выполнение задач даже в условиях неопределенности.
Адаптивные Роботы: Будущее Интеллектуальных Действий
Интеграция моделей «Зрение-Язык-Действие» с подходом «Chain of Thought» для действий (Action CoT) открывает впечатляющие перспективы в создании роботов, способных понимать и выполнять сложные инструкции, сформулированные на естественном языке. Данный подход позволяет роботу не просто распознавать слова, но и последовательно рассуждать о задаче, разбивая ее на логические этапы и планируя действия для достижения цели. Вместо прямого сопоставления команды и движения, робот анализирует запрос, визуально оценивает окружающую среду и, подобно человеку, формирует план действий, объясняя каждый шаг. Такой способ обработки информации значительно повышает надежность и гибкость робота, позволяя ему адаптироваться к новым ситуациям и эффективно взаимодействовать с окружающим миром, даже если инструкции не являются абсолютно четкими или полными.
Развитие систем адаптивных роботов неразрывно связано с углублением их способности к рассуждению и планированию. Внедрение методов «Визуального Цепочки Рассуждений» (Visual CoT) и «Языковой Цепочки Рассуждений» (Language CoT) позволяет роботам не просто понимать инструкции на естественном языке, но и визуально анализировать окружающую среду, выстраивая логическую цепочку действий для достижения поставленной цели. Визуальный CoT, анализируя изображения, помогает роботу определить объекты и их взаимосвязь, а языковой CoT — интерпретировать словесные указания и преобразовывать их в последовательность команд. Сочетание этих подходов значительно расширяет возможности робота в решении сложных задач, требующих понимания контекста и адаптации к изменяющимся условиям, что приближает нас к созданию действительно интеллектуальных машин, способных эффективно взаимодействовать с миром.
Преодоление разрыва между семантическим пониманием и кинематическим выполнением действий является ключевым шагом к созданию действительно адаптивных роботов. Исторически, роботы испытывали трудности с преобразованием словесных инструкций в последовательность физических движений, что ограничивало их способность к гибкому взаимодействию с окружающим миром. Современные исследования направлены на разработку систем, способных не просто распознавать команды, но и интерпретировать их смысл, планировать необходимые действия и точно выполнять их, учитывая особенности окружающей среды и поставленной задачи. Успешное решение этой проблемы позволит роботам не только автоматизировать рутинные операции, но и оказывать существенную помощь людям в самых разнообразных сферах — от домашнего хозяйства и медицины до производства и освоения новых территорий, открывая новую эру в области робототехники и человеко-машинного взаимодействия.
Исследование представляет собой попытку преодолеть разрыв между семантическим пониманием задачи и ее кинематической реализацией. Авторы предлагают парадигму Action Chain-of-Thought (ACoT), фокусирующуюся на рассуждениях непосредственно в пространстве действий. Этот подход, направленный на повышение обобщающей способности и производительности робота, находит отклик в словах Блеза Паскаля: «Все великие вещи требуют времени». Именно последовательное, шаг за шагом, продумывание цепочки действий, как это и предполагает ACoT, позволяет достичь более эффективного и надежного выполнения задач, преодолевая сложность, присущую робототехнике. По сути, ACoT демонстрирует, что простота и ясность в планировании действий являются ключом к успеху.
Что Дальше?
Предложенный подход, фокусирующийся на рассуждениях непосредственно в пространстве действий, выявляет фундаментальную сложность: преодоление семантико-кинематического разрыва. Однако, ясность — это минимальная форма любви, и следует признать, что адекватное представление кинематической когерентности остаётся проблемой. Успех зависит не от количества параметров, а от их осмысленного взаимодействия. Необходимо сместить акцент с обучения выполнению действий на обучение пониманию последствий этих действий.
Очевидно, что обобщение, достигнутое в контролируемых условиях, требует дальнейшей проверки в более хаотичных, непредсказуемых средах. Настоящая проверка — не в демонстрации успехов, а в честном признании ограничений. Будущие исследования должны сосредоточиться на разработке механизмов самокоррекции и адаптации, позволяющих агенту извлекать уроки из собственных ошибок, а не просто повторять успешные образцы.
В конечном счете, ценность подхода определяется не его новизной, а его способностью упростить сложное. Задача не в создании «умных» роботов, а в создании роботов, способных к осмысленному взаимодействию с миром. И это требует не больше вычислений, а больше ясности.
Оригинал статьи: https://arxiv.org/pdf/2601.11404.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2026-01-19 20:43