Автор: Денис Аветисян
Представлена LingBot-VLA — модель, объединяющая зрение, язык и действия, обученная на огромном массиве реальных данных и демонстрирующая впечатляющую обобщающую способность.
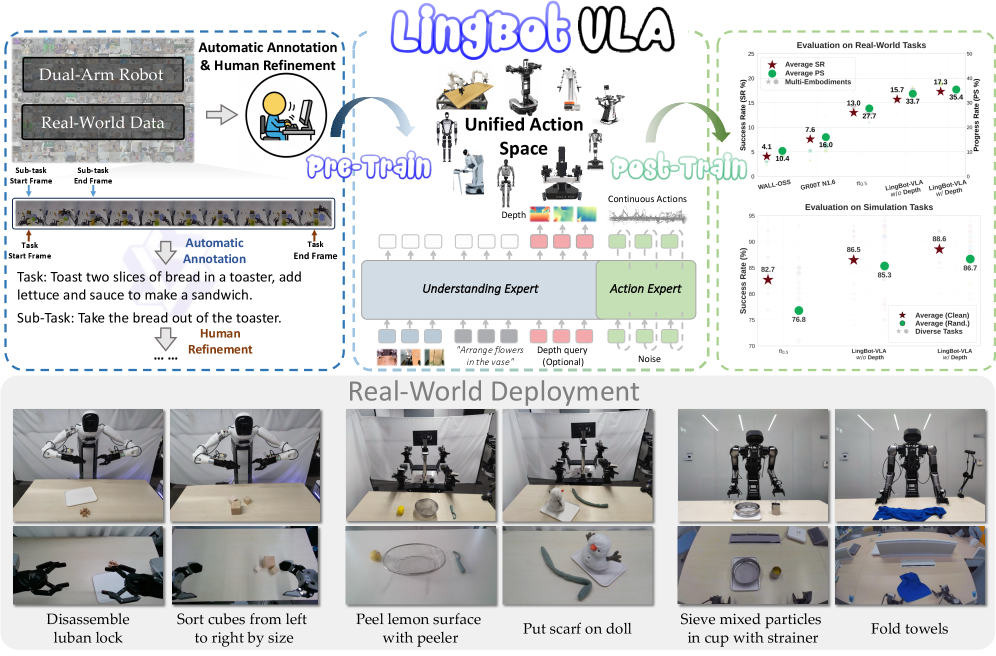
Исследователи разработали фундаментную модель Vision-Language-Action, обученную на 20 000 часах данных, полученных от робота в реальном мире, что позволило значительно улучшить эффективность и масштабируемость.
Несмотря на значительный потенциал робототехники в автоматизации сложных задач, создание универсальных моделей, способных к эффективной адаптации к различным платформам и сценариям, остается сложной задачей. В данной работе, посвященной разработке ‘A Pragmatic VLA Foundation Model’, представлена LingBot-VLA — новая модель «Зрение-Язык-Действие», обученная на приблизительно 20 000 часах реальных данных, полученных от девяти конфигураций двуруких роботов. Эксперименты на трех роботизированных платформах продемонстрировали превосходство разработанной модели над существующими аналогами в плане обобщающей способности и эффективности, обеспечивая пропускную способность в 261 образец в секунду на GPU. Сможет ли открытый доступ к коду, базовой модели и данным способствовать дальнейшему развитию области обучения роботов и созданию более сложных и надежных систем?
Преодолевая Ограничения: От Статических Моделей к Воплощенному ИИ
Традиционные системы управления роботами зачастую опираются на заранее запрограммированные последовательности действий или неудобное дистанционное управление, что существенно ограничивает их способность адаптироваться к меняющимся условиям и новым задачам. Вместо самостоятельного принятия решений и гибкой реакции на окружающую среду, роботы, управляемые подобным образом, требуют детальной предварительной настройки для каждого конкретного сценария. Это делает их неэффективными в динамичных и непредсказуемых ситуациях, где требуется немедленная корректировка действий и импровизация. Ограниченная адаптивность не только снижает производительность, но и препятствует широкому внедрению робототехники в разнообразные сферы деятельности, требующие высокой степени автономности и универсальности.
Появление моделей «зрение-язык» (Vision-Language Models, VLMs) открывает новые перспективы в управлении роботами, позволяя перейти от жестко запрограммированных действий и неуклюжего дистанционного управления к более интуитивному взаимодействию на естественном языке. Эти модели способны понимать и интерпретировать как визуальную информацию, получаемую с камер робота, так и текстовые команды, что дает возможность человеку давать роботу указания в привычной форме. Вместо сложного программирования отдельных движений, робот, оснащенный VLM, может выполнить задачу, основываясь на простом словесном описании, например, «положи красный кубик на синий». Такой подход значительно упрощает процесс обучения и адаптации робота к новым задачам и условиям, приближая его к более гибкому и человекоподобному поведению.
Для полноценной реализации потенциала управления роботами на основе языковых моделей необходимы обширные объемы данных, полученных в реальных условиях, что представляет собой значительную проблему с точки зрения сбора и масштабируемости. Решение этой проблемы демонстрирует LingBot-VLA, модель, обученная на приблизительно 20 000 часах видеозаписей манипуляций роботом в реальном мире. Такой масштаб обучения позволяет модели не только понимать сложные языковые инструкции, но и успешно применять их в разнообразных и непредсказуемых ситуациях, приближая эру интуитивного и гибкого управления робототехникой.

LingBot-VLA: Фундаментальный Подход к Моделированию
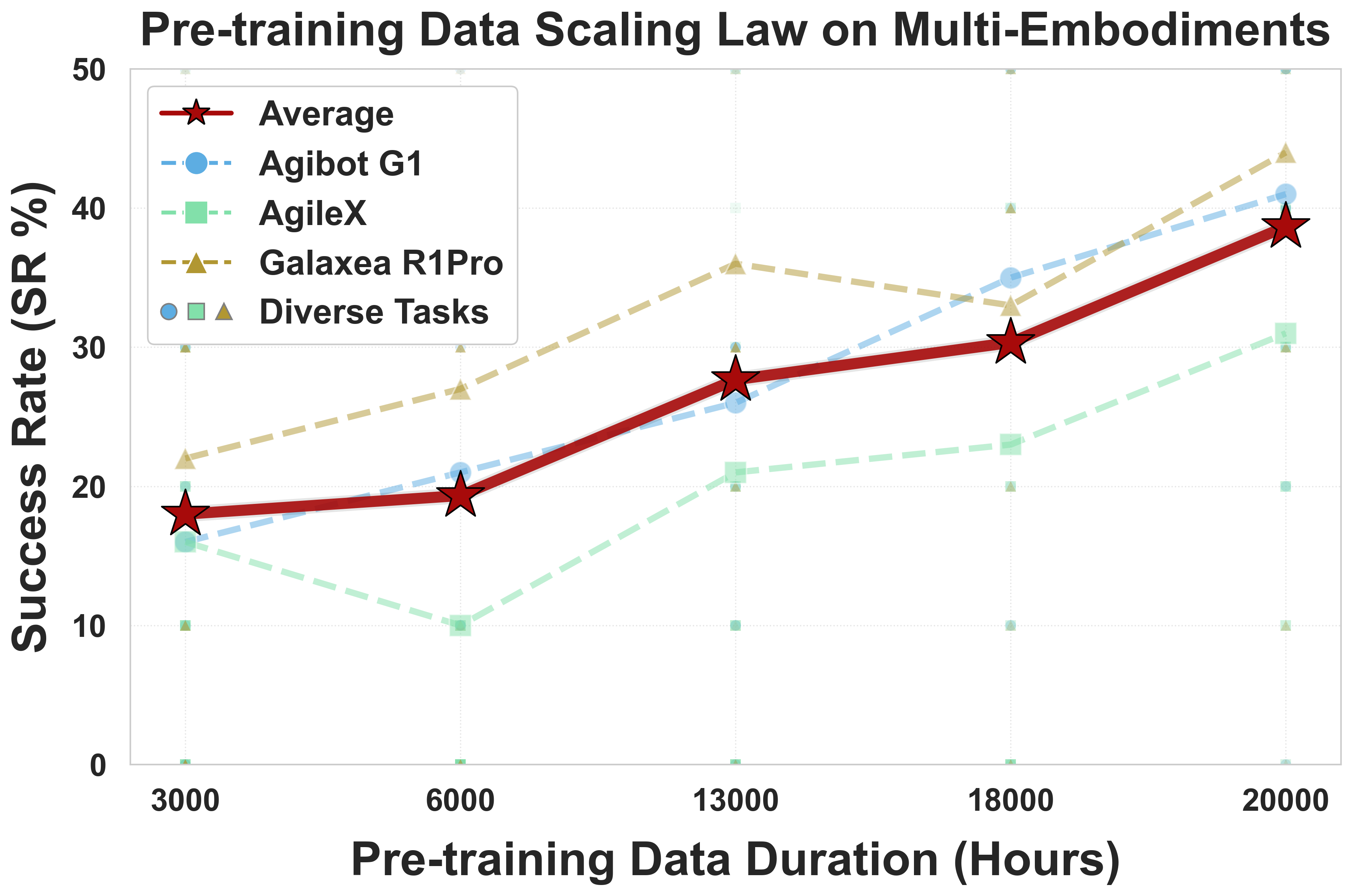
LingBot-VLA представляет собой новую базовую модель VLA (Vision-Language-Action), обученную на приблизительно 20 000 часах данных, полученных в результате реальных манипуляций роботом. Этот объем данных необходим для эффективного обучения моделей, способных понимать и выполнять сложные задачи в реальном мире. В отличие от моделей, обученных на синтетических данных или ограниченных наборах данных, LingBot-VLA демонстрирует повышенную обобщающую способность и надежность при взаимодействии с различными объектами и в различных условиях, благодаря широкому спектру сценариев, представленных в процессе обучения. Использование обширного датасета является ключевым фактором в достижении высокого уровня производительности и адаптивности модели.
В основе LingBot-VLA лежит архитектура Qwen2.5-VL, использующая подход Mixture-of-Transformers (MoT) для эффективной обработки мультимодальных данных. MoT позволяет модели распределять вычисления между несколькими «экспертами» — небольшими трансформерами — активируемыми в зависимости от входных данных. Это значительно снижает вычислительные затраты и повышает пропускную способность по сравнению с использованием одной большой модели. Qwen2.5-VL обеспечивает надежную основу для обработки визуальной и языковой информации, а MoT оптимизирует процесс, позволяя LingBot-VLA эффективно интегрировать и анализировать данные из различных сенсоров и инструкций.
Моделирование непрерывных действий в LingBot-VLA реализовано посредством алгоритма Flow Matching, что позволяет роботу выполнять плавные и точные движения на основе инструкций, заданных на естественном языке. Flow Matching представляет собой вероятностный подход, преобразующий задачу управления роботом в задачу поиска траектории в пространстве состояний. В отличие от дискретных методов управления, Flow Matching обеспечивает непрерывное изменение параметров движения, что критически важно для выполнения сложных манипуляций и достижения высокой точности. Алгоритм позволяет модели эффективно обучаться на данных, полученных от реальных роботов, и обобщать полученные знания для выполнения новых задач.
Строгая Валидация и Многозадачная Обобщающая Способность
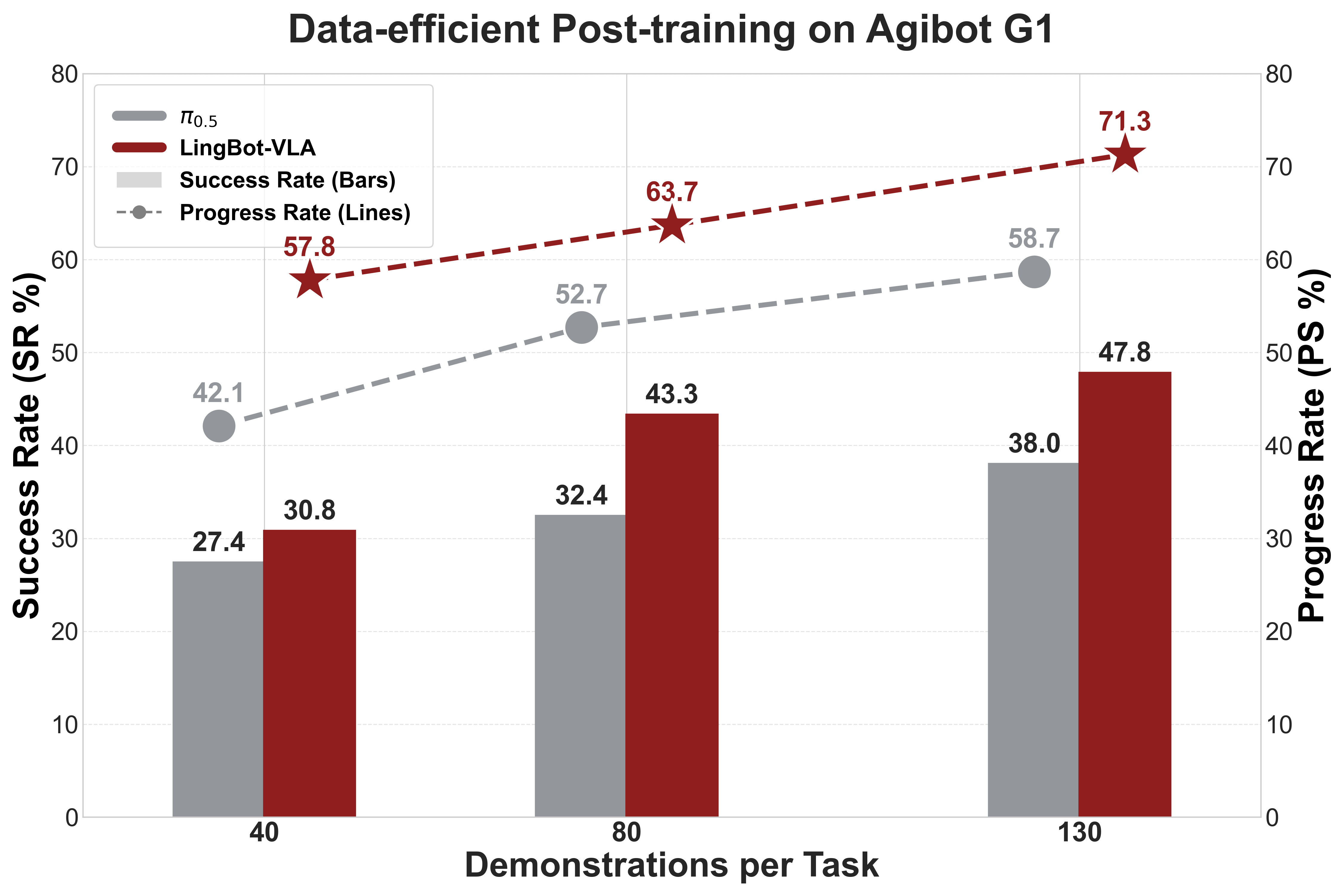
Эффективность LingBot-VLA подвергается строгой оценке с использованием эталонного набора GM-100 Benchmark, представляющего собой комплексную коллекцию из 100 разнообразных задач манипулирования. Этот набор включает в себя широкий спектр сценариев, предназначенных для всесторонней проверки возможностей модели в различных условиях и с различными объектами. Использование GM-100 Benchmark обеспечивает объективную и воспроизводимую оценку производительности LingBot-VLA в задачах, требующих точного манипулирования и адаптации к новым ситуациям.
Для подтверждения способности модели обобщать полученные знания и применять их к новым, ранее не встречавшимся сценариям, использовался RoboTwin 2.0 — реалистичный симуляционный комплекс. RoboTwin 2.0 предоставляет широкий спектр виртуальных сред и условий, позволяющих оценить производительность модели в различных, но правдоподобных ситуациях, не ограничиваясь конкретным набором задач из обучающей выборки. Это позволяет более точно оценить способность модели к адаптации и надежности в реальных условиях эксплуатации, а также выявить потенциальные слабые места в алгоритмах обобщения.
Улучшение пространственного восприятия в LingBot-VLA достигается за счет использования метода Vision Distillation, который интегрирует информацию о глубине для повышения точности манипуляций с двухрукими роботами. В ходе тестирования было установлено, что использование информации о глубине приводит к увеличению показателя успешности (Success Rate, SR) на 4.28% при оценке на трех различных платформах. Дополнительно, в чистых симуляционных средах наблюдалось увеличение SR на 5.82%, а в рандомизированных симуляционных средах — на 9.92%. Данные результаты подтверждают эффективность применения Vision Distillation для повышения надежности и точности роботизированных манипуляций.
Масштабируемость и Эффективность: Путь к Широкому Внедрению
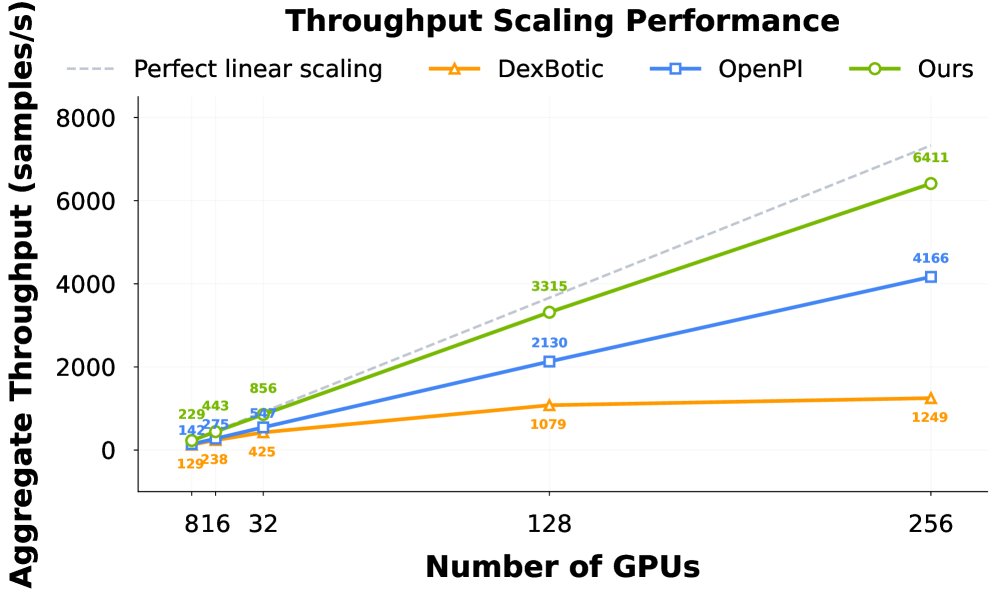
Для масштабирования больших языковых моделей, таких как LingBot-VLA, вычислительная эффективность имеет первостепенное значение. В данной работе активно применяются передовые стратегии параллелизации, в частности, Fully Sharded Data Parallel (FSDP) и Zero Redundancy Optimizer (ZeRO). FSDP позволяет распределять параметры модели между несколькими графическими процессорами, существенно снижая потребность в памяти каждого из них. ZeRO, в свою очередь, оптимизирует процесс обучения за счет устранения избыточности в градиентах и состояниях оптимизатора, что ведет к сокращению объема памяти и ускорению сходимости. Сочетание этих методов позволяет эффективно обучать модели с миллиардами параметров, открывая путь к созданию более мощных и интеллектуальных систем.
Для оценки эффективности разработанной модели LingBot-VLA были проведены сравнительные тесты с использованием общедоступных кодовых баз, таких как StarVLA, Dexbotic и OpenPI. Результаты демонстрируют, что LingBot-VLA превосходит эти решения по показателям производительности, а также демонстрирует близкое соответствие теоретической линейной зависимости пропускной способности при обучении. Это означает, что с увеличением вычислительных ресурсов, скорость обучения модели увеличивается пропорционально, что критически важно для масштабирования и практического применения больших языковых моделей. Достигнутая эффективность позволяет значительно сократить время и затраты на обучение, делая LingBot-VLA перспективным решением для широкого круга задач.
Для углубленного анализа пропускной способности и масштабируемости при обучении больших языковых моделей, использовался фреймворк PaliGemma. Этот инструмент позволил детально изучить, как производительность LingBot-VLA изменяется при увеличении вычислительных ресурсов и объема данных. В результате применения PaliGemma удалось выявить ключевые факторы, влияющие на эффективность обучения, и оптимизировать процесс для достижения максимальной пропускной способности. Полученные данные подтверждают, что LingBot-VLA демонстрирует превосходные показатели масштабируемости, что делает его перспективным решением для задач, требующих обработки больших объемов информации.
Исследование, представленное в данной работе, демонстрирует стремление к созданию фундаментальных моделей, способных к обобщению и масштабированию в реальных условиях робототехники. Этот подход, воплощенный в LingBot-VLA, акцентирует внимание на корректности и устойчивости алгоритмов при обработке огромных объемов данных. Как однажды заметил Кен Томпсон: «Простота — это высшая степень изысканности». Эта фраза резонирует с идеей создания элегантных и эффективных решений, способных выдерживать проверку временем и масштабом. Пусть N стремится к бесконечности — что останется устойчивым? LingBot-VLA стремится к тому, чтобы в этой бесконечности осталась надежная и предсказуемая система, способная к адаптации и обучению.
Что Дальше?
Представленная работа, демонстрируя эффективность модели LingBot-VLA на обширном наборе данных реальных робототехнических взаимодействий, лишь подчеркивает глубину нерешенных вопросов. Вместо слепого наращивания масштаба данных, необходимо сосредоточиться на разработке алгоритмов, способных к истинному обобщению, а не просто к запоминанию паттернов. Проблема, заключающаяся в достижении устойчивости к шуму и вариативности реального мира, остается открытой. Элегантность решения не измеряется количеством часов обучения, а строгостью математической формализации.
Очевидно, что текущий подход к обучению, основанный на статистической корреляции, далек от идеала. Необходимо исследовать методы, позволяющие модели не просто имитировать поведение, а понимать причинно-следственные связи. Попытки внедрения логических правил и символьных представлений, несмотря на кажущуюся сложность, представляются более перспективными, чем дальнейшее увеличение размера нейронных сетей. Иначе мы обречены на создание сложных, но хрупких систем, не способных к адаптации к непредвиденным обстоятельствам.
В конечном счете, истинный прогресс в области VLA-моделей будет достигнут не за счет увеличения вычислительных ресурсов, а за счет углубления понимания принципов обучения и представления знаний. Пока же, успехи, подобные продемонстрированному, остаются лишь шагами в направлении этой, возможно, недостижимой цели. Простота и доказательность алгоритма всегда превалируют над его практической реализацией.
Оригинал статьи: https://arxiv.org/pdf/2601.18692.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сердце музыки: открытые модели для создания композиций
- Эмоциональный отпечаток: Как мы научили ИИ читать душу (и почему рейтинги вам врут)
- Адаптация моделей к новым данным: квантильная коррекция для нейросетей
- Волны звука под контролем нейросети: моделирование и инверсия в вязкоупругой среде
- Динамическая теория поля в реальном времени: путь к квантовым вычислениям
- LLM: математика — предел возможностей.
2026-01-28 21:51