Автор: Денис Аветисян
Исследователи представили Green-VLA — модель, объединяющую зрение, язык и действия, позволяющую роботам эффективно выполнять разнообразные задачи в различных условиях.
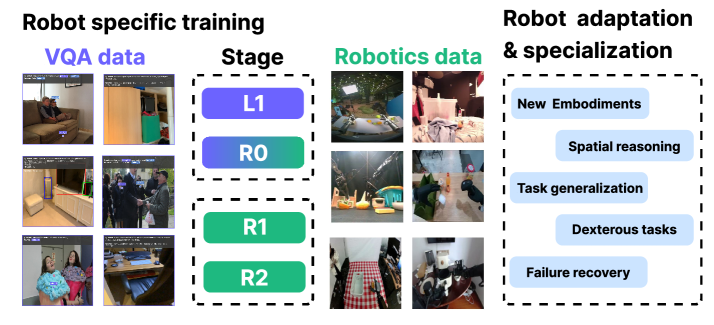
Предлагаемый фреймворк Green-VLA использует обучение с подкреплением, унифицированное пространство действий и акцент на качество данных для достижения передовых результатов в робототехнике.
Несмотря на значительный прогресс в области робототехники, создание универсальных роботов, способных к эффективному выполнению разнообразных задач в реальном мире, остается сложной задачей. В данной работе представлена модель Green-VLA: Staged Vision-Language-Action Model for Generalist Robots — многоступенчатый фреймворк, объединяющий обработку визуальной информации, языка и действий, предназначенный для развертывания на гуманоидном роботе Green и обеспечивающий обобщение для различных воплощений. Ключевым результатом является демонстрация, что акцент на качестве данных, унифицированном пространстве действий и обучении с подкреплением позволяет добиться существенного повышения эффективности и надежности робота в сложных сценариях. Сможет ли предложенный подход стать основой для создания действительно универсальных робототехнических систем, способных к адаптации и обучению в динамичной среде?
Разрыв шаблонов: Необходимость унифицированных робототехнических фреймворков
Традиционно, робототехника часто опирается на программирование, ориентированное на выполнение конкретных задач, что существенно ограничивает возможности адаптации и масштабируемости роботов. Вместо создания универсальных алгоритмов, способных к обучению и применению в различных ситуациях, разработчики вынуждены создавать уникальный программный код для каждой отдельной операции. Это приводит к громоздким и неэффективным системам, требующим значительных усилий для модификации или расширения функционала. В результате, роботы, созданные для выполнения одной узкоспециализированной задачи, оказываются бесполезными при изменении внешних условий или необходимости выполнения новых, даже незначительно отличающихся операций, что замедляет прогресс в области автоматизации и ограничивает потенциал робототехники в реальном мире.
Несогласованность в способах представления действий является существенным препятствием для эффективной передачи навыков между роботами и усложняет их совместную работу. Разные робототехнические системы зачастую используют отличные друг от друга форматы для описания одного и того же действия — например, перемещения, захвата или манипуляции с объектом. Это приводит к тому, что навык, успешно освоенный одним роботом, не может быть напрямую использован другим, требуя дорогостоящей и трудоемкой переработки. Такая фрагментация препятствует созданию действительно гибких и масштабируемых робототехнических систем, способных к эффективному сотрудничеству в сложных и динамичных условиях, и подчеркивает необходимость унифицированного подхода к кодированию и обмену опытом между роботами.
Современные роботизированные системы часто сталкиваются с трудностями при работе в реальных условиях, характеризующихся непредсказуемостью и изменчивостью. Существующие методы, как правило, разрабатываются для конкретных, упрощенных сценариев, что ограничивает их способность адаптироваться к новым, сложным ситуациям. Неспособность эффективно обрабатывать шумные данные, неполную информацию и непредвиденные препятствия приводит к снижению надежности и эффективности роботов в реальном мире. В связи с этим, возникает острая необходимость в разработке более устойчивых и обобщенных подходов, способных обеспечить надежную работу роботов в динамичных и неструктурированных средах, что требует интеграции продвинутых алгоритмов восприятия, планирования и управления, а также использования методов машинного обучения для повышения адаптивности и обучаемости систем.
Зелёный ВЛА: Многоэтапный фреймворк «Зрение-Язык-Действие»
Green-VLA использует возможности моделей «зрение-язык» (VLM) для восприятия и понимания сложных окружений. Эти модели, предварительно обученные на больших наборах данных изображений и текста, позволяют системе интерпретировать визуальную информацию и соотносить ее с языковыми инструкциями. В частности, VLM позволяют Green-VLA идентифицировать объекты, понимать их взаимосвязи и предсказывать последствия действий в окружении, что критически важно для успешного выполнения задач роботами в реальных условиях. Использование VLM позволяет системе обобщать знания, полученные в процессе обучения, и применять их к новым, ранее не встречавшимся ситуациям.
В основе Green-VLA лежит поэтапный подход к обучению, включающий предварительное обучение и последующую тонкую настройку. Предварительное обучение позволяет модели приобрести общие знания о визуальном восприятии, языке и действиях, что обеспечивает высокую обобщающую способность и устойчивость к новым условиям. На этапе предварительного обучения достигается уровень успешности, сопоставимый с результатами моделей, прошедших только тонкую настройку на целевых данных, что свидетельствует об эффективности данного подхода к передаче знаний и снижению потребности в большом количестве размеченных данных для конкретных задач.
Ключевым элементом Green-VLA является унификация пространств действий, обеспечивающая бесшовную передачу навыков между различными роботизированными платформами. Это достигается путем представления всех возможных действий в стандартизированном формате, что позволяет обученной модели эффективно управлять разнообразным оборудованием без необходимости повторного обучения для каждой конкретной платформы. Унифицированное пространство действий включает в себя как низкоуровневые команды управления моторами и сервоприводами, так и высокоуровневые инструкции, такие как «захватить объект» или «переместиться в точку». Такой подход значительно упрощает процесс развертывания обученных моделей на новых роботах и повышает их общую применимость.
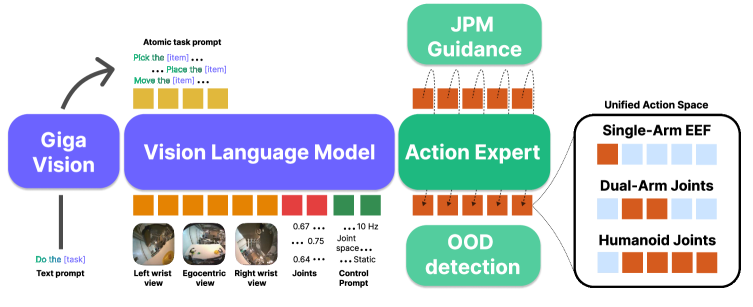
Качество данных и уточнение действий
Конвейер DataQA выполняет фильтрацию, сглаживание и выравнивание роботизированных наборов данных, что позволяет снизить уровень шума и устранить несоответствия. Процесс фильтрации включает в себя удаление аномальных или ошибочных данных, полученных в результате неисправностей сенсоров или других факторов. Сглаживание применяется для уменьшения высокочастотных колебаний в данных, повышая их стабильность и упрощая дальнейшую обработку. Выравнивание данных необходимо для синхронизации информации, поступающей от различных сенсоров и в разные моменты времени, обеспечивая целостность и согласованность набора данных. Эффективность конвейера DataQA напрямую влияет на точность и надежность последующих этапов обработки, таких как анализ оптического потока и обучение эксперта по действиям.
Анализ оптического потока применяется для выравнивания временной динамики в наборах данных, что повышает точность прогнозирования действий робота. Этот метод отслеживает смещение пикселей между последовательными кадрами видео, позволяя определить вектор движения каждого пикселя и, следовательно, оценить движение объектов в сцене. Полученные данные о движении используются для компенсации временных расхождений и обеспечения согласованности данных, что критически важно для обучения моделей предсказания действий. Применение оптического потока позволяет более эффективно использовать временные зависимости в данных и снизить влияние шума и неточностей, возникающих при сборе данных с сенсоров.
Модуль совместного предсказания (Joint Prediction Module) повышает эффективность механизма управления за счет точного предсказания целевых точек для манипуляций. Этот модуль функционирует путем анализа текущего состояния системы и прогнозирования оптимальных координат, к которым должны стремиться манипуляторы. Точность предсказания достигается за счет использования алгоритмов машинного обучения, обученных на больших объемах данных о движении и взаимодействии с объектами. Предсказанные целевые точки используются для формирования траекторий движения манипуляторов, что позволяет снизить погрешность и повысить скорость выполнения задач. Использование модуля совместного предсказания особенно эффективно в динамичных средах и при выполнении сложных манипуляций, требующих высокой точности позиционирования.
Метод Flow Matching обучает эксперта по действиям (action expert) генерировать соответствующие действия на основе наблюдаемых состояний. Этот подход использует вероятностную модель для сопоставления наблюдаемых состояний с распределением возможных действий, что позволяет эксперту выбирать наиболее вероятное и подходящее действие в каждой конкретной ситуации. Обучение происходит путем минимизации расхождения между предсказанным распределением действий и фактическим распределением, наблюдаемым в обучающих данных. Это позволяет эксперту адаптироваться к различным условиям и обеспечивать стабильную и точную работу системы манипулирования.
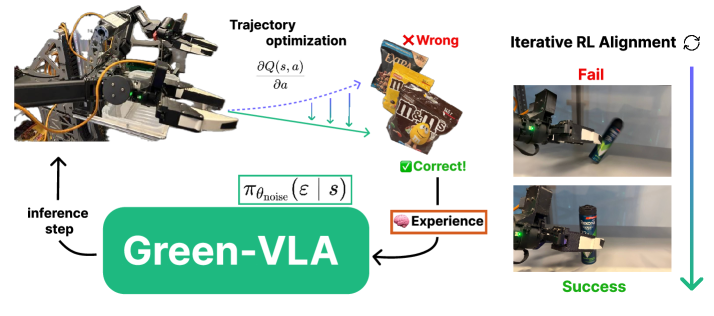
Обучение с подкреплением для надёжности и адаптации
Обучение с подкреплением (RL) используется для тонкой настройки политики управления, что позволяет улучшить производительность на длинных временных горизонтах и повысить устойчивость системы. В процессе RL агент взаимодействует со средой, получая вознаграждение за действия, приближающие его к целевому состоянию. Эта обратная связь используется для итеративного улучшения политики, позволяя агенту адаптироваться к различным условиям и достигать более надежных результатов в сложных сценариях. Применение RL позволяет преодолеть ограничения традиционных методов управления, которые могут испытывать трудности при работе с неопределенностью и изменяющимися условиями окружающей среды.
Оптимизация траекторий и неявное Q-обучение применяются для решения проблем, возникающих в обучении с подкреплением, таких как разреженность вознаграждения и переоценка Q-значений. Разреженность вознаграждения возникает, когда агент получает редкие сигналы вознаграждения, что затрудняет обучение оптимальной стратегии. Оптимизация траекторий позволяет находить последовательности действий, максимизирующие кумулятивное вознаграждение, даже при редких сигналах. Переоценка Q-значений, напротив, приводит к неоптимальному поведению агента. Неявное Q-обучение, используя методы, такие как обучение на основе ценности, позволяет смягчить эту проблему, обеспечивая более стабильные и точные оценки Q-значений и, следовательно, улучшая общую производительность агента.
Исследования показали, что разработанная платформа демонстрирует способность к обобщению на различных задачах и в разных средах. Применение алгоритма R2 RL привело к улучшению показателя успешности на 24% на бенчмарке Simpler BRIDGE WidowX. Это свидетельствует о способности системы адаптироваться к новым условиям и эффективно выполнять задачи, несмотря на изменения в окружающей среде или постановке цели. Полученные результаты подтверждают эффективность подхода, основанного на обучении с подкреплением, для повышения устойчивости и адаптивности роботизированных систем.
Применение R2 RL выравнивания позволило улучшить показатели на бенчмарке CALVIN ABC→D, демонстрируя повышение эффективности при выполнении задач, требующих планирования на длительный горизонт. В ходе тестирования было зафиксировано улучшение успешности завершения задач, что свидетельствует о способности алгоритма эффективно решать сложные, многоступенчатые задачи, требующие последовательного принятия решений и учета долгосрочных последствий. Результаты подтверждают, что R2 RL выравнивание способствует более надежному и успешному выполнению задач, требующих долгосрочного планирования и адаптации к изменяющимся условиям.

К всеобщему робототехническому интеллекту
Унифицированная архитектура Green-VLA и её устойчивые возможности обучения открывают принципиально новые горизонты для применения робототехники. В отличие от традиционных систем, где восприятие, планирование и управление действуют изолированно, Green-VLA объединяет эти процессы в единый, самообучающийся контур. Это позволяет роботам не только адаптироваться к изменяющимся условиям, но и самостоятельно осваивать новые навыки, используя минимальный объем данных. Благодаря этому, системы, построенные на базе Green-VLA, демонстрируют повышенную надежность и эффективность в различных сферах — от автоматизации производства и логистики до помощи в чрезвычайных ситуациях и проведения научных исследований. Разработчики подчеркивают, что подобный подход позволяет создавать более гибких и универсальных роботов, способных решать широкий спектр задач без необходимости перепрограммирования для каждого конкретного случая.
Архитектура Green-VLA демонстрирует исключительную масштабируемость и адаптивность, что позволяет использовать роботов в условиях повышенной сложности и изменчивости. В отличие от традиционных систем, жестко привязанных к конкретным задачам и окружениям, данная платформа способна эффективно функционировать в разнообразных, непредсказуемых сценариях. Благодаря своей гибкой структуре, она легко приспосабливается к новым условиям, быстро обучаясь и оптимизируя свои действия. Это особенно важно для применения роботов в реальном мире, где окружение постоянно меняется, а задачи требуют немедленной реакции и способности к импровизации. Возможность развертывания в сложных и динамичных условиях открывает широкие перспективы для использования роботов в логистике, сельском хозяйстве, поисково-спасательных операциях и других областях, требующих автономной работы в неструктурированных средах.
Разработка Green-VLA представляет собой значительный шаг к созданию универсального искусственного интеллекта для робототехники, объединяя в единую систему восприятие окружающей среды, принятие решений и обучение. Традиционно, эти компоненты разрабатывались изолированно, что ограничивало способность роботов адаптироваться к новым, непредсказуемым ситуациям. Green-VLA, напротив, позволяет роботу не просто реагировать на текущие данные, но и активно учиться на опыте, совершенствуя свои навыки и стратегии действий. Благодаря такому интегрированному подходу, роботы получают возможность понимать контекст, предвидеть последствия своих действий и эффективно решать широкий спектр задач в различных условиях, приближая нас к созданию действительно интеллектуальных машин, способных к автономной деятельности и взаимодействию с миром.
Дальнейшие исследования сосредоточены на расширении возможностей разработанной структуры для решения более сложных задач и адаптации к разнообразным средам. Особое внимание уделяется повышению эффективности обучения на ограниченном объеме данных, что является ключевым фактором для практического применения робототехнических систем в реальном мире. Ученые стремятся к созданию алгоритмов, способных быстро адаптироваться к новым условиям и извлекать максимальную пользу из доступной информации, что позволит роботам действовать автономно и эффективно в непредсказуемых ситуациях. Развитие этих направлений позволит значительно расширить спектр решаемых роботами задач и приблизиться к созданию действительно универсального искусственного интеллекта для робототехники.

Исследование, представленное в данной работе, демонстрирует стремление к созданию универсальных роботизированных систем, способных оперировать в разнообразных условиях. Акцент на качественных данных и унифицированном пространстве действий позволяет Green-VLA достигать выдающихся результатов в обучении с подкреплением. Этот подход напоминает принцип, сформулированный Робертом Тарьяном: «Если вы не можете объяснить, как что-то работает, вы не понимаете, как оно работает.» Подобно тому, как Тарьян подчеркивал важность глубокого понимания алгоритмов, данная работа фокусируется на создании прозрачной и управляемой системы, где каждый компонент играет четко определенную роль, что обеспечивает надежность и масштабируемость модели.
Что дальше?
Представленная работа, безусловно, демонстрирует прогресс в создании универсальных робототехнических систем. Однако, возникает вопрос: а не является ли само стремление к «универсальности» искусственным ограничением? Система, способная выполнять широкий спектр задач, неизбежно компромиссна в каждой конкретной из них. Вместо погони за всеохватностью, возможно, стоит сосредоточиться на создании узкоспециализированных агентов, глубоко оптимизированных для конкретных ниш, и изучить принципы их взаимодействия. В конце концов, не баг ли это — потребность в едином решении для всех проблем?
Особое внимание заслуживает вопрос о качестве данных. Авторы справедливо подчеркивают его важность, но остается неясным, как эффективно масштабировать процесс курирования данных для ещё более сложных сценариев. Необходимо исследовать методы самообучения и активного обучения, позволяющие агенту самостоятельно выявлять и исправлять ошибки в данных, а также адаптироваться к новым, непредсказуемым ситуациям. Ведь идеальные данные — это миф, а способность к обучению на неполной и противоречивой информации — вот что действительно отличает разумную систему.
В перспективе, интересно будет наблюдать за интеграцией Green-VLA с другими подходами, такими как нейроэволюция и обучение с подкреплением на основе имитаций. Возможно, истинный прорыв произойдет не за счет улучшения существующих алгоритмов, а за счет создания принципиально новых архитектур, способных к самостоятельному исследованию окружающего мира и формированию собственных целей. И тогда вопрос о «универсальности» отпадет сам собой.
Оригинал статьи: https://arxiv.org/pdf/2602.00919.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Взлом языковых моделей: эволюция атак, а не подсказок
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Робот-манипулятор: обучение взаимодействию с миром с помощью зрения от первого лица
- Кванты в Финансах: Не Шутка!
- Квантовый оптимизатор: Новый подход к сложным задачам
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Обучение с подкреплением и причинность: как добиться надёжных выводов
- Эволюция инструментов мышления: новый подход к научным открытиям
- От принципов к практике: как сделать данные по-настоящему взаимосовместимыми
2026-02-03 12:37