Автор: Денис Аветисян
Разработчики представили Xiaomi-Robotics-0 — систему, позволяющую роботам выполнять задачи, основываясь на визуальном восприятии и текстовых инструкциях.

Модель Xiaomi-Robotics-0, основанная на архитектуре Vision-Language-Action и использующая методы предварительного обучения и асинхронного исполнения, демонстрирует передовые результаты в задачах манипулирования роботами в реальном времени.
Несмотря на значительный прогресс в области робототехники, создание систем, способных к быстрому и точному выполнению сложных манипуляций в реальном времени, остается сложной задачей. В настоящей работе представлен ‘Xiaomi-Robotics-0: An Open-Sourced Vision-Language-Action Model with Real-Time Execution’ — модель, объединяющая возможности компьютерного зрения, обработки естественного языка и управления роботом, оптимизированная для высокой производительности и оперативной работы. Ключевым достижением является разработка эффективной стратегии предварительного обучения и асинхронного выполнения, позволяющей добиться передовых результатов в симуляции и на реальных роботах, демонстрируя высокую скорость и точность выполнения биманипуляций. Какие перспективы открывает данная открытая платформа для дальнейших исследований в области интеллектуальной робототехники и адаптивных систем?
От иллюзий к реальности: вызовы объединения восприятия и действия
Современная робототехника сталкивается с необходимостью создания надежных алгоритмов управления, способных объединить обработку визуальной информации, понимание естественного языка и выполнение действий в реальном времени. Традиционные методы, как правило, испытывают трудности в обеспечении бесшовной интеграции этих трех ключевых компонентов. Сложность заключается в том, что робот должен не просто «видеть» объекты, но и интерпретировать инструкции, выраженные человеческим языком, а затем точно и безопасно выполнить соответствующие действия в динамично меняющейся среде. Такое объединение требует разработки принципиально новых подходов к обучению роботов, способных к адаптации и обобщению, что представляет собой серьезный вызов для исследователей и инженеров.
Современные методы управления роботами зачастую демонстрируют ограниченную эффективность в условиях реального мира, отличающегося высокой степенью неопределенности и изменчивости. Сложность заключается в том, что роботы, обученные в контролируемой среде, испытывают трудности при столкновении с непредсказуемыми объектами, меняющимся освещением или неожиданными препятствиями. Эта неспособность к адаптации серьезно замедляет внедрение действительно интеллектуальных роботов в различные сферы — от автоматизации производства до оказания помощи в повседневной жизни. Для преодоления этой проблемы необходимы принципиально новые подходы к обучению, позволяющие роботам не просто распознавать объекты, но и гибко реагировать на любые изменения окружающей среды, проявляя находчивость и умение решать задачи в нестандартных ситуациях.
Для эффективного обучения роботов необходимы модели, способные не только воспринимать окружающую среду, но и понимать сложные инструкции, а затем претворять их в действия. Такие модели должны выходить за рамки простого распознавания объектов или сцен; они должны уметь интерпретировать лингвистические команды, связывать их с соответствующими манипуляциями и адаптироваться к изменяющимся условиям. Исследования в этой области направлены на создание систем, способных к семантическому пониманию языка и его трансляции в последовательности действий, что требует интеграции методов компьютерного зрения, обработки естественного языка и обучения с подкреплением. Успех в этой области позволит роботам выполнять сложные задачи, основанные на человеческих инструкциях, открывая новые возможности для автоматизации и взаимодействия человека с машиной.
Одной из ключевых проблем в обучении роботов-манипуляторов является перенос навыков, приобретенных в виртуальной среде, в реальный мир. Несмотря на кажущуюся простоту моделирования, различия в физических свойствах, освещении и сенсорных данных между симуляцией и реальностью приводят к значительным ошибкам в работе робота. Робот, успешно выполняющий задачу в симуляции, может столкнуться с трудностями при выполнении той же задачи в реальной обстановке из-за несоответствия между ожидаемыми и фактическими ощущениями. Разработка методов, позволяющих преодолеть этот разрыв и обеспечить надежную генерализацию, остается важной задачей для исследователей в области робототехники, поскольку именно это определяет возможность создания действительно автономных и адаптивных роботов, способных эффективно действовать в сложных и непредсказуемых условиях.
Xiaomi-Robotics-0: решая задачу «зрение-язык-действие»
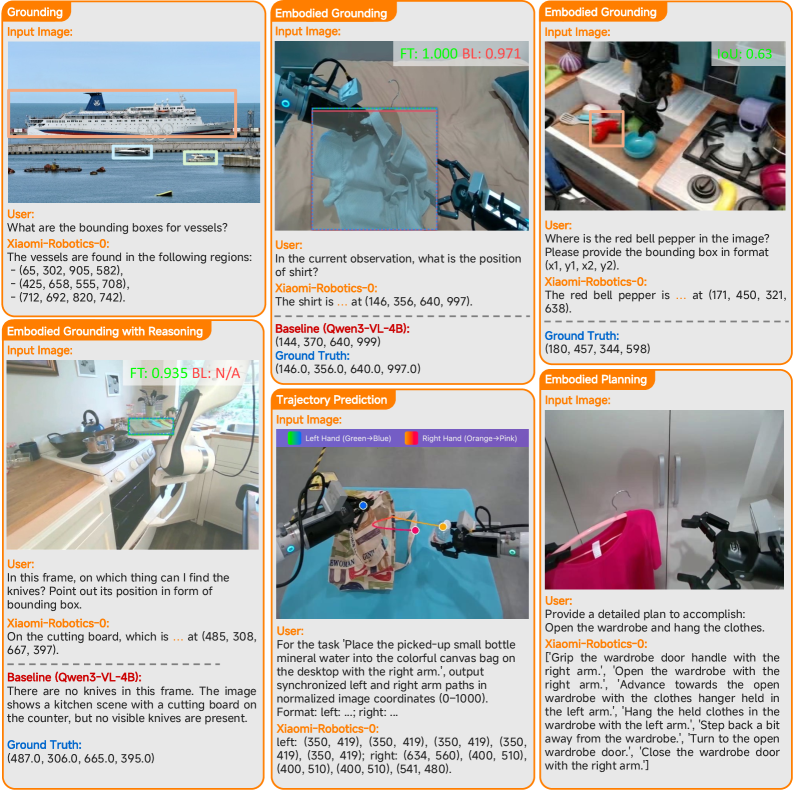
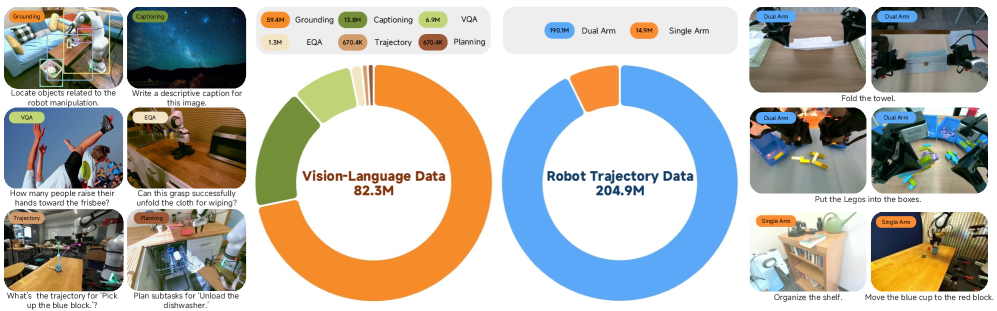
Система Xiaomi-Robotics-0 реализует новый подход к управлению роботами, используя предварительно обученную модель, сочетающую обработку изображений и естественного языка. Это позволяет роботу не просто распознавать визуальные объекты, но и понимать семантическое значение сцены и команд, что значительно расширяет возможности восприятия и взаимодействия с окружающей средой. Предварительное обучение модели на большом объеме данных позволяет ей эффективно обобщать знания и адаптироваться к новым, ранее не встречавшимся ситуациям, повышая надежность и гибкость управления роботом.
Модель Xiaomi-Robotics-0 использует архитектуру Diffusion Transformer, что позволяет генерировать разнообразные и контекстуально релевантные действия. В основе лежит принцип диффузионных моделей, которые последовательно преобразуют случайный шум в осмысленные действия, управляемые входными данными. Transformer обеспечивает эффективную обработку последовательностей и улавливание зависимостей между различными элементами входных данных, такими как визуальные данные и текстовые инструкции. Комбинация этих двух подходов позволяет модели создавать не только корректные, но и разнообразные действия, адаптированные к конкретной ситуации и поставленной задаче. Это обеспечивает гибкость и приспособляемость робота к различным условиям эксплуатации и типам задач.
Ключевым фактором эффективности Xiaomi-Robotics-0 является использование методов разбиения действий на фрагменты (Action Chunking) и асинхронного выполнения (Asynchronous Execution). Разбиение сложных задач на более мелкие, управляемые фрагменты позволяет оптимизировать планирование и снизить вычислительную нагрузку. Асинхронное выполнение этих фрагментов, то есть их параллельная обработка, значительно повышает скорость реакции робота и обеспечивает управление в режиме реального времени. Такой подход позволяет избежать последовательного выполнения всех этапов задачи, что критически важно для динамичных сред и сложных манипуляций.
Архитектура системы использует маскировку внимания для оптимизации механизма фокусировки. Каузальная маска внимания (Causal Attention Mask) предотвращает использование информации из будущего, обеспечивая последовательную обработку данных и предотвращая «утечку» информации во время обучения. Лямбда-образная маска внимания (Lambda-Shape Attention Mask) применяется для формирования внимания, ограничивая его определенными участками входной последовательности, что повышает эффективность и точность модели при обработке длинных последовательностей данных и позволяет более эффективно выделять релевантную информацию.
Тщательная валидация и сравнительные тесты
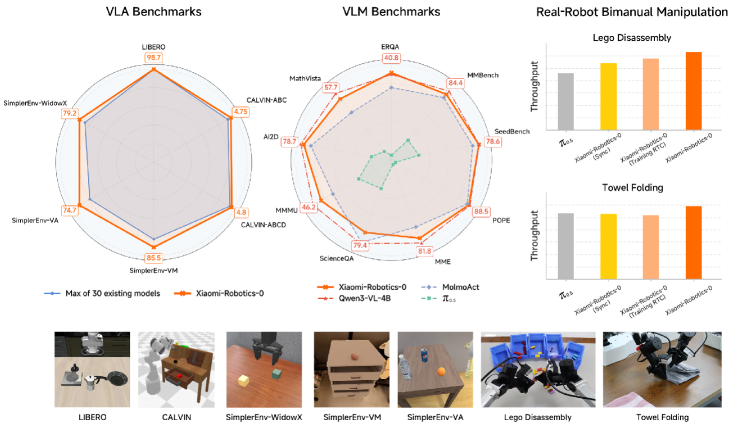
Производительность Xiaomi-Robotics-0 была всесторонне оценена на ряде сложных бенчмарков, включающих LIBERO, CALVIN и SimplerEnv. Эти бенчмарки представляют собой стандартизированные наборы задач, предназначенные для оценки способности робота к планированию действий, визуальному восприятию и решению проблем в различных средах. Использование этих бенчмарков позволяет объективно сравнить производительность Xiaomi-Robotics-0 с существующими методами и продемонстрировать его возможности в сложных сценариях, включающих манипуляции с объектами и навигацию в динамических условиях.
На тестовом наборе LIBERO, модель Xiaomi-Robotics-0 демонстрирует средний процент успешного выполнения задач на уровне 98.7%. Этот показатель подтверждает, что производительность модели соответствует современному уровню, и превосходит результаты, полученные ранее на аналогичных бенчмарках. Высокий процент успешности указывает на надежность и эффективность алгоритмов, используемых для решения задач манипулирования и навигации в сложных условиях, предоставляемых LIBERO.
В ходе тестирования на бенчмарке CALVIN (ABCD→D) модель Xiaomi-Robotics-0 продемонстрировала среднюю длину выполнения задач в 4.80 шага. Данный показатель превосходит результаты, достигнутые предыдущими методами, что свидетельствует о повышении эффективности планирования и выполнения последовательностей действий в условиях данного бенчмарка. Эффективность была измерена путем анализа среднего количества шагов, необходимых для успешного завершения задач, определенных в CALVIN.
Модель Xiaomi-Robotics-0 продемонстрировала передовые результаты на бенчмарке SimplerEnv (Google Robot — Visual Matching), достигнув средней успешности выполнения задач в 85.5%. Данный показатель свидетельствует о высокой точности системы в задачах визуального сопоставления и манипулирования объектами, что подтверждает её эффективность в сложных роботизированных сценариях. Бенчмарк SimplerEnv включает в себя широкий спектр задач, требующих от робота способности к распознаванию объектов и выполнению соответствующих действий, что делает полученный результат значимым для оценки общей производительности системы.
Для повышения точности предсказания действий в Xiaomi-Robotics-0 используется подход, основанный на Choice Policies. Данная методика позволяет модели выбирать из нескольких возможных действий, основываясь на текущем состоянии среды и поставленной задаче. В отличие от традиционных методов, где модель напрямую предсказывает единственное действие, Choice Policies оценивают вероятность каждого действия и выбирают наиболее вероятное, что приводит к снижению количества ошибок и повышению надежности выполнения задач в различных условиях. Использование Choice Policies является ключевым фактором, способствующим достижению высоких показателей производительности модели на эталонных бенчмарках, таких как LIBERO, CALVIN и SimplerEnv.
К адаптивной и интеллектуальной робототехнике: взгляд в будущее
Успех Xiaomi-Robotics-0 наглядно демонстрирует возможности моделей «зрение-язык-действие» в расширении функциональности робототехники. Данная разработка подтверждает, что объединение визуального восприятия, понимания естественного языка и способности к выполнению действий открывает принципиально новые горизонты для создания роботов, способных адаптироваться к сложным и непредсказуемым условиям реального мира. Модель позволяет роботу не просто выполнять заранее запрограммированные задачи, а интерпретировать инструкции на естественном языке и применять их к визуальной информации, что существенно расширяет спектр решаемых задач и приближает роботов к уровню автономности и интеллекта, необходимому для работы в различных сферах человеческой деятельности. Результаты, полученные с Xiaomi-Robotics-0, являются важным шагом на пути к созданию действительно интеллектуальных робототехнических систем.
В основе успешной интеграции модели Xiaomi-Robotics-0 с реальным роботизированным оборудованием лежит концепция “разделения на фрагменты в реальном времени” (Real-Time Chunking). Этот подход позволяет разбивать сложные задачи на последовательность небольших, управляемых действий, что значительно упрощает процесс переноса из симуляционной среды в практическое применение. Вместо обработки всей задачи целиком, модель анализирует текущий визуальный поток и, основываясь на этом, генерирует короткие последовательности команд для манипулятора. Такая декомпозиция не только ускоряет обработку и снижает вычислительную нагрузку, но и обеспечивает более гибкую и адаптивную работу робота в динамично меняющихся условиях реального мира, позволяя эффективно преодолевать разрыв между виртуальной средой и физическим воплощением.
В ходе тестирования модели Xiaomi-Robotics-0 была продемонстрирована выдающаяся скорость выполнения задачи по складыванию полотенец — 1,2 штуки в минуту. Этот показатель значительно превосходит результаты, демонстрируемые существующими роботизированными системами, что свидетельствует о существенном прогрессе в области адаптивной робототехники. Достижение высокой производительности в такой практической задаче, как складывание полотенец, подтверждает эффективность предложенного подхода и открывает перспективы для широкого применения подобных систем в бытовых и промышленных условиях, где требуется высокая скорость и точность выполнения повторяющихся операций.
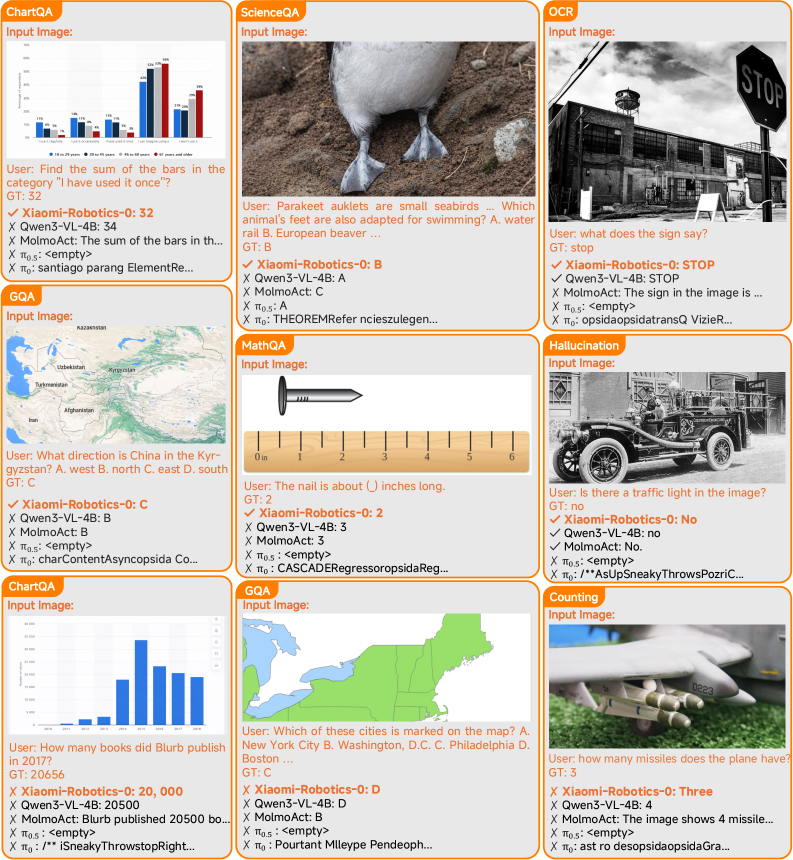
В ходе тестирования на бенчмарке ERQA, модель Xiaomi-Robotics-0 продемонстрировала впечатляющий результат, достигнув 40.8% успешных выполнений заданий. Этот показатель незначительно превосходит аналогичный результат модели Qwen3-VL-4B-Instruct, составивший 40.0%. Такое превосходство, хоть и небольшое, подтверждает потенциал разработанной системы в области понимания и выполнения сложных инструкций, заданных на естественном языке, и подчеркивает ее способность к более эффективному взаимодействию с окружающим миром по сравнению с существующими аналогами.
Данная работа знаменует собой переход к робототехнике нового поколения, где машины перестают быть просто исполнителями заложенных программ. Вместо слепого следования инструкциям, демонстрируется способность к пониманию задач на основе визуальной и текстовой информации, а также к самостоятельному планированию действий для их выполнения. Такой подход позволяет роботам адаптироваться к изменяющимся условиям и решать более сложные, непредсказуемые задачи, что является ключевым шагом на пути к созданию поистине интеллектуальных машин, способных к обучению и автономной работе в реальном мире.
Представленная работа, словно очередной коммит в бесконечном репозитории технологического долга, демонстрирует, как элегантные теоретические построения неизбежно сталкиваются с суровой реальностью продакшена. Модель Xiaomi-Robotics-0, стремясь к state-of-the-art манипуляциям, в конечном итоге становится ещё одним слоем абстракции между человеком и машиной. Обещание быстродействия и плавности в реальном времени, безусловно, привлекательно, но опыт подсказывает, что асинхронное исполнение — это лишь временное решение, которое рано или поздно потребует отладки в самый неподходящий момент. Как метко заметил Давид Гильберт: «В математике нет трамплинов; нужно идти шаг за шагом». И в этой области, похоже, иной путь невозможен.
Что дальше?
Представленная работа, безусловно, демонстрирует возможности предварительного обучения и асинхронного исполнения в задачах манипулирования роботами. Однако, необходимо помнить, что каждая «революция» в области робототехники неизбежно порождает новый тип технического долга. Достижение «реального времени» — это лишь временная иллюзия, пока прод не решит, что нужна новая функция или оптимизация, которая сломает всю архитектуру.
Появление моделей вроде Xiaomi-Robotics-0 лишь усложняет проблему. Вместо того, чтобы стремиться к созданию все более сложных систем, возможно, стоит задуматься о минимизации иллюзий. Нам не нужно больше микросервисов — нам нужно меньше самообмана относительно того, насколько хорошо всё работает в реальных условиях эксплуатации. Устойчивость к «продакшену» — вот настоящий вызов, а не очередная публикация с «state-of-the-art» результатом.
В дальнейшем, вероятно, мы увидим всё большее внимание к адаптации моделей к изменяющейся среде и непредсказуемым запросам. Предварительное обучение — это хорошо, но способность быстро переучиваться и исправлять ошибки — вот что действительно ценно. В конечном итоге, каждая элегантная архитектура со временем превращается в анекдот, а реальная ценность заключается в способности поддерживать систему в рабочем состоянии, несмотря на все внешние факторы.
Оригинал статьи: https://arxiv.org/pdf/2602.12684.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Квантовая телепортация в новых измерениях: топологические изоляторы
- Квантовый скачок в обучении с учителем: новая архитектура для искусственного интеллекта
- Искусственный интеллект нового поколения: фокус на специализированные модели
- Цифровые улики под присмотром ИИ: новая эра криминалистики?
- Стратегия подцелей: Как научить ИИ долгосрочному планированию
2026-02-16 15:24