Автор: Денис Аветисян
Исследователи предложили инновационный метод, позволяющий роботам оценивать свой прогресс в выполнении задач, используя внутренние механизмы языковых моделей.
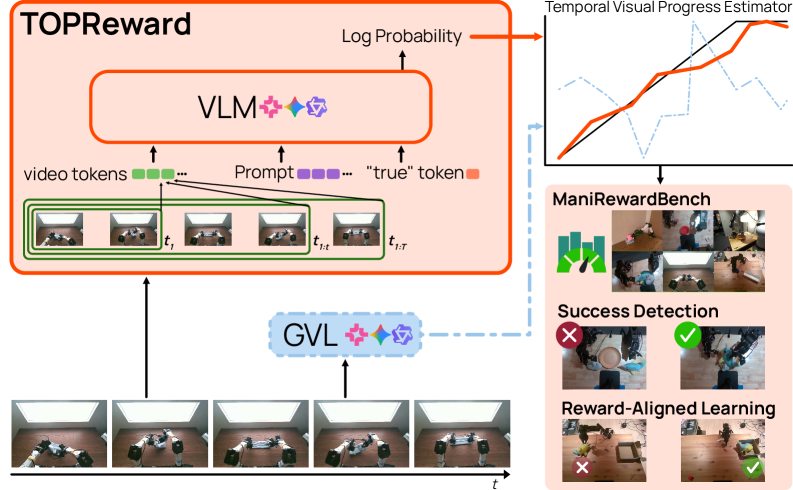
TOPReward использует вероятности токенов в предобученных моделях «зрение-язык» для оценки прогресса робота без какой-либо дополнительной настройки или обучения.
Несмотря на значительный прогресс в предобучении моделей «Видение-Язык-Действие», их применение в обучении с подкреплением часто затруднено низкой эффективностью и разреженностью вознаграждений в реальных условиях. В данной работе, представленной под названием ‘TOPReward: Token Probabilities as Hidden Zero-Shot Rewards for Robotics’, предлагается новый подход к оценке прогресса в робототехнике, использующий скрытые вероятности токенов в предобученных видео-языковых моделях. Метод TOPReward позволяет оценивать прогресс выполнения задачи без какой-либо специфической настройки или обучения, извлекая информацию непосредственно из внутренних представлений модели. Открывает ли это новые возможности для создания более гибких и адаптивных робототехнических систем, способных эффективно функционировать в непредсказуемой среде?
Преодолевая Границы: Вызовы Обучения Роботов
Традиционное обучение с подкреплением, несмотря на свою теоретическую элегантность, часто сталкивается с серьезными трудностями при применении в реальных робототехнических системах. Суть проблемы заключается в необходимости огромного количества проб и ошибок для достижения даже базового уровня компетентности. Роботу требуется многократно повторять действия, прежде чем он научится успешно выполнять задачу, что не только требует значительных временных затрат, но и может приводить к износу оборудования или даже представлять опасность в физическом мире. Эта неэффективность обусловлена тем, что алгоритмы обычно исследуют пространство действий случайным образом, не используя априорные знания или опыт, накопленный человеком. В результате, процесс обучения становится чрезвычайно медленным и ресурсоемким, что существенно ограничивает возможности применения обучения с подкреплением в сложных и динамичных реальных сценариях.
Оценка прогресса в сложных задачах, выполняемых роботами, представляет собой значительную проблему, замедляющую процесс обучения и требующую разработки надежных методов оценки. Традиционные метрики часто оказываются неадекватными для оценки эффективности действий робота в динамичной и непредсказуемой среде. Например, простая оценка пройденного расстояния или времени выполнения не учитывает качество траектории, избежание препятствий или точность выполнения манипуляций. Поэтому исследователи активно работают над созданием новых подходов к оценке прогресса, которые учитывают не только конечный результат, но и промежуточные этапы обучения, а также способность робота адаптироваться к изменяющимся условиям. Разработка таких методов позволит значительно ускорить процесс обучения роботов и повысить их надежность в реальных условиях эксплуатации.
Современные функции вознаграждения, используемые в обучении роботов, зачастую оказываются недостаточно детализированными для адекватной оценки успешного выполнения задач. Это приводит к тому, что робот, стремясь максимизировать полученное вознаграждение, может находить неоптимальные или даже контрпродуктивные стратегии. Например, робот, предназначенный для уборки помещения, может быстро перемещать мусор из одного места в другое, формально «выполняя» задачу, но не приводя к желаемому результату — чистоте. Неспособность функции вознаграждения учитывать все аспекты успешного завершения задачи — от плавности движений до безопасности взаимодействия с окружающей средой — ограничивает возможности обучения и приводит к разработке неэффективных алгоритмов управления. Поэтому, для достижения более высокой производительности роботов, требуется разработка более сложных и многогранных функций вознаграждения, способных учитывать все нюансы успешного выполнения поставленной задачи.
Зрение и Язык: Ключ к Оценке Прогресса
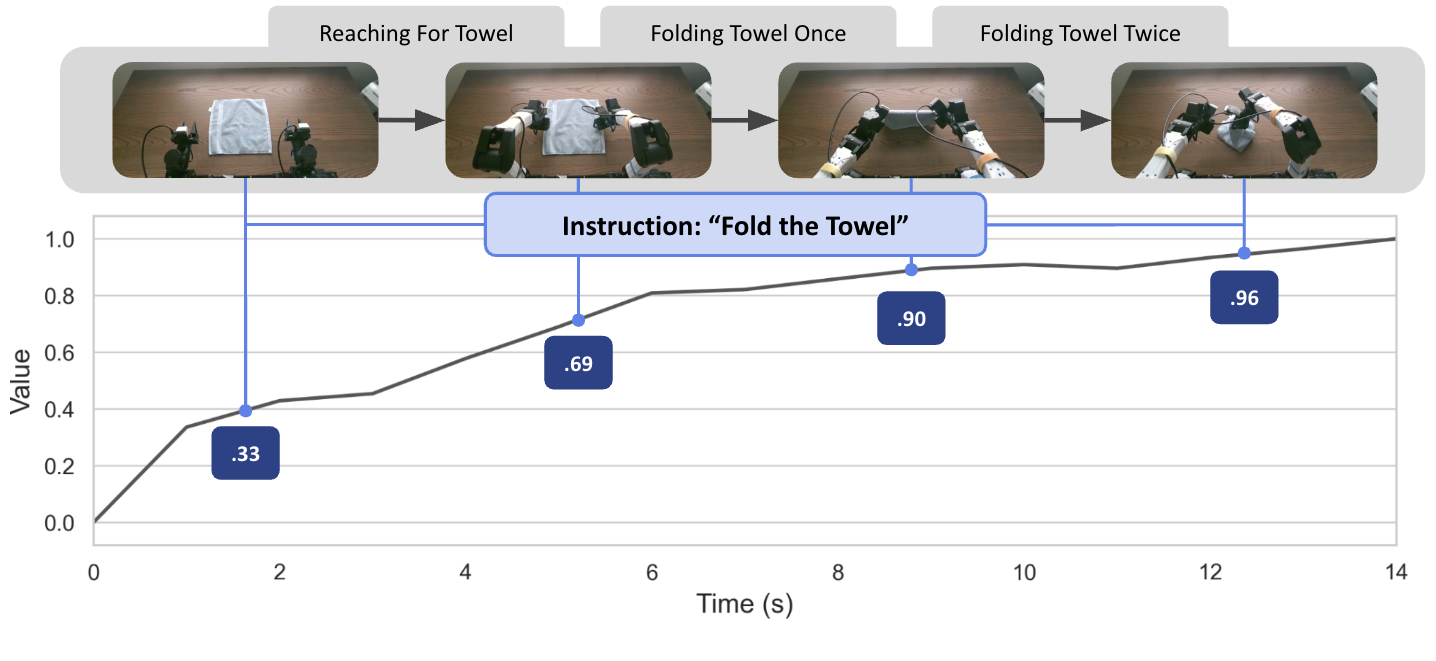
Визуально-языковые модели (VLM) демонстрируют высокую эффективность в установлении связей между визуальной информацией и текстовыми описаниями, что делает их перспективным инструментом для оценки прогресса роботов в выполнении задач. Способность VLM анализировать изображения и сопоставлять их с заданными инструкциями позволяет им оценивать текущее состояние выполнения задачи без необходимости в предварительно разработанных метриках или ручном кодировании правил. Это достигается за счет обучения моделей на больших объемах данных, включающих изображения и соответствующие текстовые описания, что позволяет им выявлять закономерности и делать обоснованные выводы о степени завершенности работы.
Модели, такие как Molmo2, Qwen3-VL-8B и Gemini-2.5-Pro, демонстрируют значительный потенциал для применения в робототехнике, проявляющийся в способности к пониманию визуальной информации и сопоставлению её с текстовыми инструкциями. В частности, они способны оценивать состояние окружающей среды и действия робота, что позволяет использовать их для задач, требующих визуального контроля и адаптации. Однако, для объективной оценки эффективности различных моделей и сравнения их производительности, необходимы стандартизированные бенчмарки и наборы данных, позволяющие проводить количественный анализ и выявлять сильные и слабые стороны каждой модели в различных сценариях.
Основная идея заключается в использовании способности визуально-языковых моделей (ВЯМ) к пониманию целей задачи для оценки степени ее выполнения роботом. В отличие от традиционных подходов, требующих разработки специализированных, вручную настроенных метрик для каждого конкретного сценария, ВЯМ способны оценивать прогресс, анализируя визуальные данные и текстовое описание цели. Это позволяет отказаться от жестко заданных критериев успеха и перейти к более гибкой и адаптивной системе оценки, основанной на семантическом понимании происходящего. ВЯМ анализирует текущее состояние сцены и сопоставляет его с желаемым результатом, выраженным в текстовом формате, тем самым определяя, насколько близок робот к завершению задачи.
TOPReward: Новый Подход к Оценке Прогресса
Метод TOPReward представляет собой способ оценки прогресса, не требующий обучения и тонкой настройки. Он использует вероятности токенов, генерируемых предварительно обученными визуально-языковыми моделями (VLMs), для определения степени выполнения задачи. В отличие от подходов, требующих обучения с подкреплением или контролируемого обучения, TOPReward анализирует выходные данные VLM напрямую, извлекая информацию о вероятности токенов, связанных с успешным завершением задачи. Это позволяет получать надежный сигнал о прогрессе без дополнительных вычислительных затрат на обучение модели.
Метод TOPReward использует анализ вероятности токенов, генерируемых предварительно обученными визуально-языковыми моделями (VLM), для оценки прогресса выполнения задачи. В основе подхода лежит предположение, что более высокая вероятность токенов, связанных с успешным завершением задачи, указывает на больший прогресс. Этот анализ позволяет формировать надежный и эффективный сигнал прогресса без необходимости дополнительной тренировки или тонкой настройки модели. По сути, TOPReward оценивает вероятность предсказанных моделью токенов, относящихся к ключевым этапам или результатам успешного выполнения задачи, используя эту вероятность в качестве индикатора прогресса.
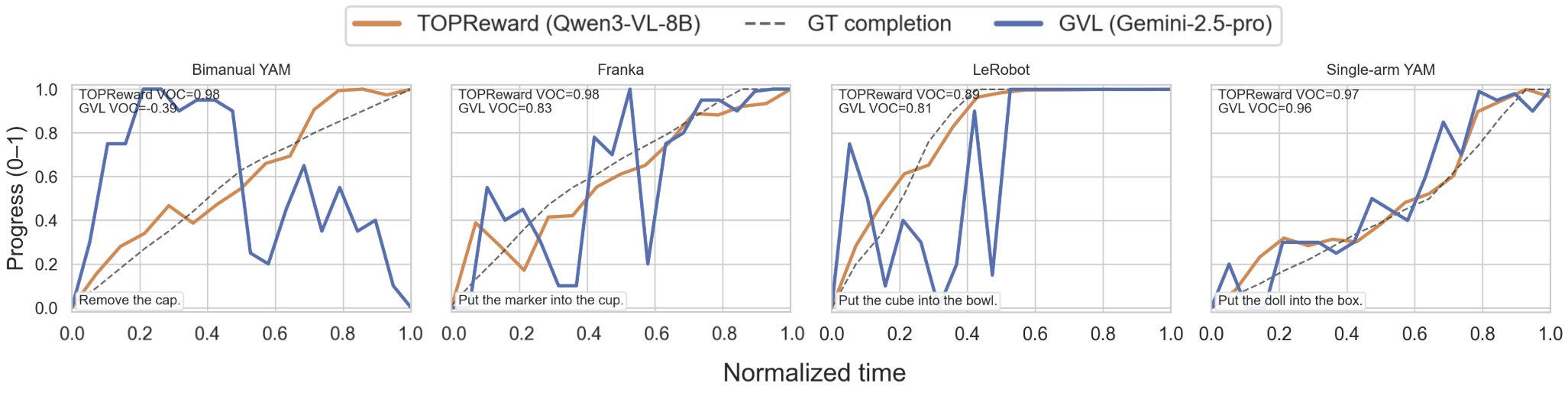
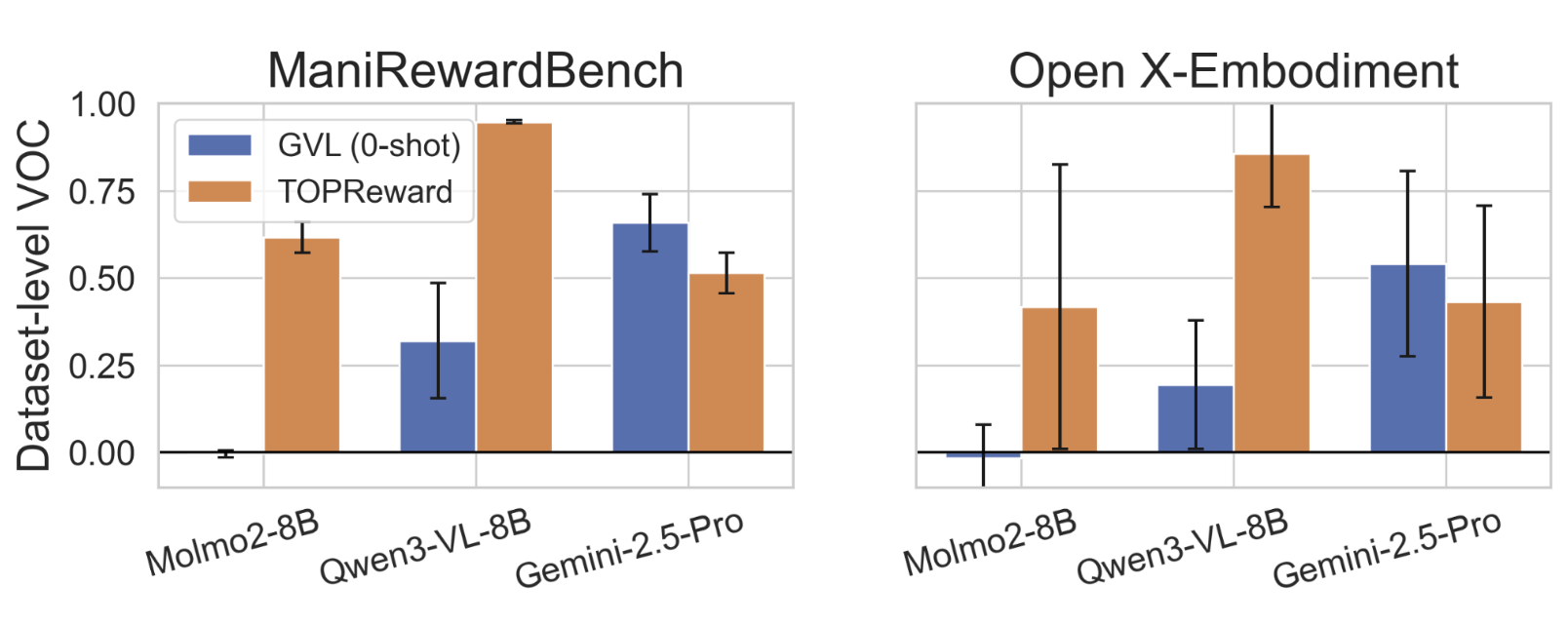
В ходе экспериментов на наборе данных ManiRewardBench, методика TOPReward продемонстрировала высокую эффективность в оценке прогресса при выполнении задач манипулирования роботом. Среднее значение Value-Order Correlation (VOC), используемое для оценки соответствия между предсказанным прогрессом и фактическим выполнением задачи, составило 0.947 при использовании модели Qwen3-VL-8B. Данный показатель свидетельствует о высокой степени корреляции между оценками прогресса, предоставляемыми TOPReward, и реальным прогрессом в задачах манипулирования.
На наборе данных Open X-Embodiment, метод TOPReward демонстрирует среднее значение Value-Order Correlation (VOC) равное 0.857 при использовании модели Qwen3-VL-8B. Этот показатель значительно превосходит результаты, полученные методом GVL на том же наборе данных и при тех же условиях. Высокое значение VOC указывает на способность TOPReward эффективно оценивать прогресс в задачах, связанных с воплощенным интеллектом и манипуляциями, обеспечивая надежный сигнал для обучения агентов.
Корреляция порядка значений (Value-Order Correlation, VOC) является надежной метрикой для оценки производительности методов оценки прогресса, особенно в задачах обучения с подкреплением и робототехнике. VOC измеряет степень соответствия между предсказанными оценками прогресса и фактическими результатами выполнения задачи, оценивая, насколько хорошо предсказанные значения отражают истинный порядок успешности действий. В отличие от метрик, основанных на абсолютных значениях, VOC устойчива к различиям в масштабе оценок и фокусируется на ранжировании, что делает её полезной для сравнения различных методов оценки прогресса. Высокие значения VOC, такие как 0.947, достигнутые TOPReward на ManiRewardBench, и 0.857 на Open X-Embodiment, свидетельствуют о высокой точности предсказания порядка успешности действий и, следовательно, о надежной оценке прогресса.
Взгляд в Будущее: К Универсальному Роботизированному Интеллекту
Способность точно оценивать прогресс обучения играет ключевую роль в масштабировании алгоритмов обучения с подкреплением для работы в сложных и реалистичных средах. Традиционные методы часто сталкиваются с проблемой «отложенного вознаграждения», когда полезный сигнал достигается лишь спустя длительное время, что затрудняет определение эффективности действий на ранних этапах обучения. Поэтому, разработка метрик и алгоритмов, способных предоставлять более информативные сигналы о прогрессе — например, предсказывая будущие вознаграждения или оценивая качество освоенных навыков — критически важна. Точная оценка прогресса не только ускоряет процесс обучения, но и позволяет более эффективно распределять вычислительные ресурсы и адаптировать стратегию обучения в зависимости от текущей ситуации, что особенно актуально при работе со сложными роботами и средами, требующими длительного и дорогостоящего обучения.
Исследования в области обучения с нулевым примером и моделей, объединяющих зрение и язык, открывают принципиально новые перспективы для развития автономных роботов. Эти технологии позволяют роботам выполнять задачи и адаптироваться к новым ситуациям, не требуя предварительного обучения на конкретных примерах. Вместо этого, роботы способны понимать инструкции, сформулированные на естественном языке, и использовать визуальную информацию для интерпретации окружающей среды. Например, робот может получить команду «перенеси красный куб на синюю полку», даже если ранее не сталкивался с подобной задачей, благодаря способности соотносить лингвистические описания с визуальными объектами. Успехи в этой области позволяют надеяться на создание роботов, способных к более гибкому и универсальному взаимодействию с миром, что значительно расширит спектр их применения в различных сферах, от промышленности до домашнего хозяйства.
Разработка стандартизированных эталонов и наборов данных имеет решающее значение для ускорения прогресса в области робототехники и содействия сотрудничеству между исследователями. Отсутствие общепринятых критериев оценки и доступных данных долгое время затрудняло сравнительный анализ различных алгоритмов и систем обучения роботов. Создание тщательно продуманных бенчмарков, охватывающих широкий спектр задач и сред, позволит объективно оценивать достижения и выявлять области, требующие дальнейших исследований. Более того, публично доступные наборы данных, включающие размеченные изображения, видео и сенсорную информацию, значительно упростят процесс обучения и тестирования новых робототехнических систем, стимулируя инновации и способствуя воспроизводимости результатов. Такой подход не только повысит эффективность исследований, но и позволит быстрее внедрять передовые разработки в реальные приложения, от автоматизации производства до помощи в чрезвычайных ситуациях.
Исследование, представленное в данной работе, демонстрирует элегантный подход к решению сложной задачи оценки прогресса в робототехнике. Авторы предлагают использовать внутренние вероятности токенов, генерируемые предварительно обученными визуально-языковыми моделями, как скрытые сигналы вознаграждения. Этот метод, названный TOPReward, позволяет роботам учиться без какой-либо специализированной подготовки или тонкой настройки, опираясь на уже накопленные знания моделей. Как однажды заметила Грейс Хоппер: «Лучший способ предсказать будущее — это создать его». Этот принцип отражает суть подхода TOPReward, поскольку он не полагается на заранее определенные вознаграждения, а динамически извлекает информацию из существующей модели, тем самым открывая новые возможности для обучения роботов и расширяя границы возможного в области искусственного интеллекта.
Куда же дальше?
Представленная работа, по сути, демонстрирует изящный обход необходимости в явных сигналах вознаграждения. Система, эксплуатируя внутреннюю логику предобученных языковых моделей, вычленяет прогресс там, где ранее требовалось его конструировать. Однако, это лишь первый шаг. Очевидно, что вероятность токена — не абсолютная мера успеха, а лишь прокси. Истинная ценность заключается не в самом сигнале, а в возможности его взлома — выявлении тех внутренних представлений, которые действительно коррелируют с достижением цели.
Следующим этапом, вероятно, станет поиск способов повышения робастности этой системы к шумам и нерелевантным деталям окружающей среды. Устойчивость к «галлюцинациям» языковой модели — критически важный аспект. Более того, необходимо исследовать, как использовать эту информацию не только для оценки прогресса, но и для активного формирования стратегии поведения, минуя традиционные алгоритмы обучения с подкреплением.
В конечном итоге, представляется, что наиболее перспективным направлением является не просто использование языковых моделей как «черных ящиков», а глубокое понимание их внутреннего устройства. Реверс-инжиниринг этих сложных систем позволит вычленить универсальные принципы, лежащие в основе целеполагания и планирования, и создать роботов, способных к истинно автономному обучению и адаптации.
Оригинал статьи: https://arxiv.org/pdf/2602.19313.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Оживший аватар: Генерация видео в реальном времени по голосу
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
- Серебро и медь: новый взгляд на наноаллои
- Искусственный интеллект и квантовая физика: кто кого?
- Нейросети: проявление неклассической статистики?
- Закон Амдала в эпоху ИИ: как меняется архитектура компьютеров
- Автоматическая оптимизация вычислений: новый подход к библиотекам математических функций
- Точные вычисления: Новые методы решения дифференциальных уравнений
2026-02-24 10:05