Автор: Денис Аветисян
Исследователи представили систему, позволяющую роботам более эффективно планировать и выполнять сложные задачи, такие как сборка конструктора, благодаря использованию больших языковых моделей и многоагентных систем.
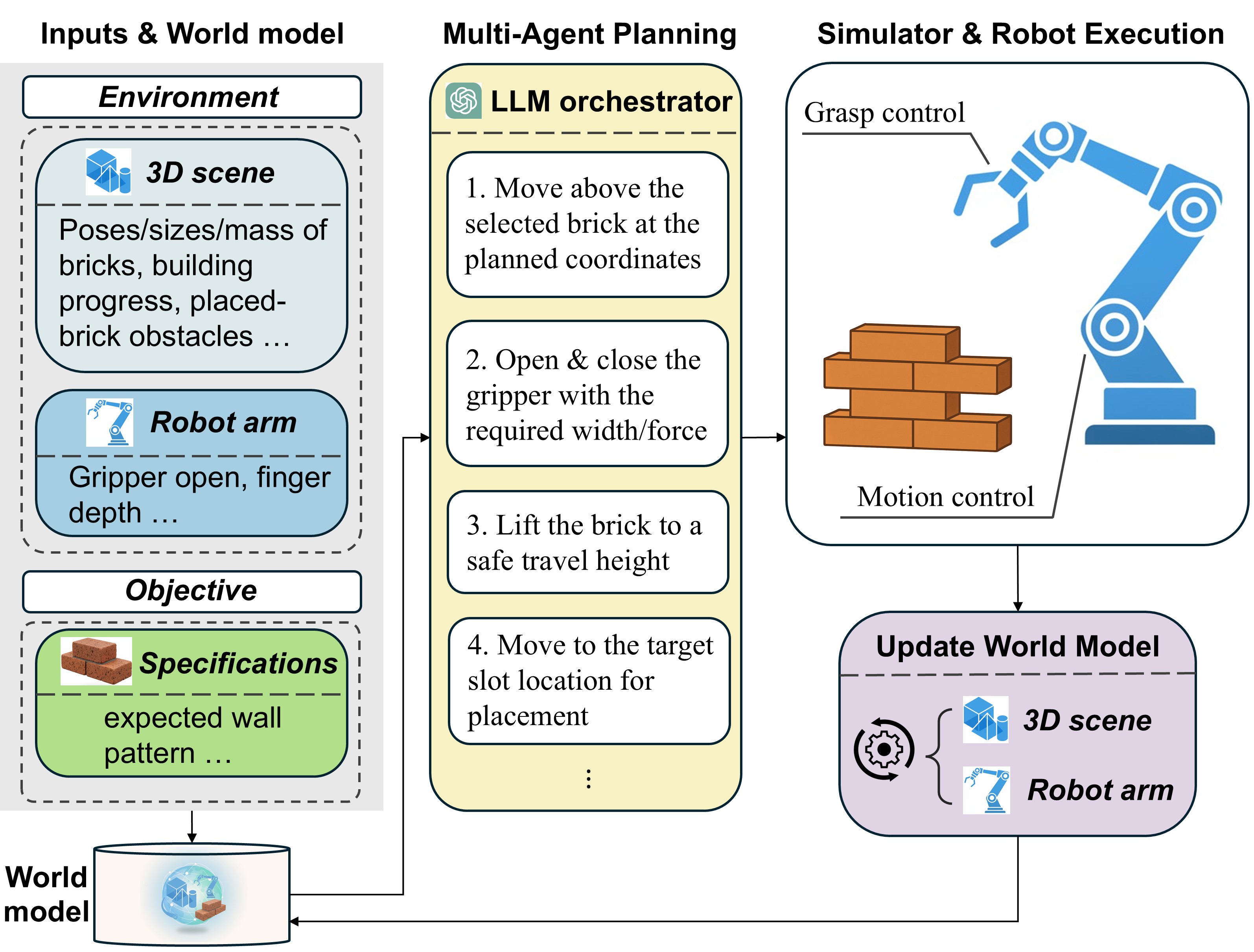
Предложен фреймворк ActionReasoning, использующий LLM для 3D-рассуждений о действиях и обеспечивающий более надежное и адаптивное управление роботами в сложных условиях.
Традиционные системы робототехники, как правило, полагаются на специализированные планировщики, эффективные лишь в ограниченных средах. В работе ‘ActionReasoning: Robot Action Reasoning in 3D Space with LLM for Robotic Brick Stacking’ предложен фреймворк ActionReasoning, использующий большие языковые модели (LLM) и многоагентную архитектуру для выполнения пространственного рассуждения о действиях робота. Это позволяет создавать более устойчивые и адаптивные системы управления, демонстрируемые на примере задачи укладки кирпичей. Способны ли подобные подходы, объединяющие физическое рассуждение и LLM, существенно расширить возможности роботов в решении сложных манипулятивных задач и приблизиться к созданию действительно универсального искусственного интеллекта?
Пределы Ручного Управления: Когда Логика Бессильна
Традиционное управление роботами основывается на тщательно разработанных, закодированных вручную алгоритмах поведения, что создает существенное ограничение в плане адаптивности. Каждое движение, каждая реакция на внешние раздражители заранее программируется инженерами, что требует огромных усилий и времени при внесении даже незначительных изменений. В результате, робот, созданный таким образом, демонстрирует высокую надежность в строго определенных условиях, но испытывает трудности при столкновении с непредсказуемыми ситуациями или в незнакомой обстановке. Эта зависимость от жестко заданных инструкций существенно ограничивает потенциал роботов в решении сложных задач, требующих гибкости и способности к самостоятельному принятию решений, и, как следствие, замедляет развитие автономных систем.
Классические системы управления роботами, несмотря на свою надёжность в заранее определенных условиях, испытывают значительные трудности при работе в сложных и неструктурированных средах. При столкновении с непредвиденными обстоятельствами, такими как неожиданные препятствия или изменения в окружающей обстановке, заранее запрограммированные алгоритмы оказываются неэффективными. Робот, функционирующий на основе жестко заданных инструкций, не способен адаптироваться к новым ситуациям, что приводит к ошибкам или полной остановке работы. Это особенно актуально в динамичных условиях, где требуется оперативное реагирование и принятие решений на основе текущей обстановки, что выходит за рамки возможностей традиционных контроллеров, ориентированных на предсказуемость и повторяемость действий.
По мере усложнения задач, стоящих перед робототехническими системами, становится очевидной необходимость перехода от жесткой, заранее запрограммированной логики к более гибким подходам, основанным на рассуждениях. Традиционные контроллеры, полагающиеся на четко определенные правила, демонстрируют ограниченную эффективность в неструктурированных и динамично меняющихся средах. Вместо этого, современные исследования направлены на создание систем, способных самостоятельно анализировать ситуацию, делать выводы и адаптировать свои действия, подобно человеческому мышлению. Такой подход позволяет роботам не просто выполнять заданные команды, но и решать новые, непредвиденные задачи, значительно расширяя область их применения и повышая автономность. Вместо кодирования каждого возможного сценария, создаются алгоритмы, позволяющие машине учиться и принимать решения на основе полученного опыта и анализа данных.

Управление на Основе LLM: Мост к Интеллектуальной Робототехнике
Использование больших языковых моделей (LLM) в управлении роботами открывает возможности для создания более адаптивных и интеллектуальных роботизированных систем благодаря интеграции высокоуровневого рассуждения. Традиционные системы управления роботами часто полагаются на жестко запрограммированные реакции на конкретные ситуации. В отличие от них, LLM способны анализировать сложные сценарии, понимать намерения и генерировать последовательности действий, основанные на контексте и планируемых траекториях робота. Это позволяет роботам действовать в динамически меняющихся условиях и выполнять задачи, требующие гибкости и способности к решению проблем, что существенно расширяет их функциональные возможности и области применения.
В основе управления роботами с использованием больших языковых моделей (LLM) лежит генерация действий на основе текущего состояния окружающей среды (‘Environment State’) и запланированных точек маршрута робота (‘Robot Waypoints’). LLM, получая эти данные в качестве входных параметров, формирует последовательность команд, необходимых для выполнения поставленной задачи. Фактически, LLM выступает в роли интерпретатора намерений, преобразуя высокоуровневые инструкции в конкретные действия, необходимые для перемещения и манипулирования объектами в заданном окружении. Этот процесс позволяет роботу адаптироваться к изменяющимся условиям и выполнять сложные задачи, требующие планирования и принятия решений в реальном времени.
Ключевым элементом данной парадигмы управления является метод “Цепочки рассуждений” (Chain-of-Thought Reasoning), позволяющий большой языковой модели (LLM) не только генерировать действия, но и артикулировать последовательность логических шагов, приведших к этому решению. Данный подход значительно повышает надежность системы, поскольку позволяет проводить анализ процесса принятия решений LLM, выявлять потенциальные ошибки и корректировать логику. В отличие от прямого сопоставления входных данных и действий, “Цепочка рассуждений” предоставляет промежуточные выводы, которые можно отслеживать и верифицировать, что особенно важно для критически важных приложений, где требуется объяснимость и предсказуемость поведения робота.
Эффективное управление большими языковыми моделями (LLM) в робототехнике требует применения структурированного подхода к формированию запросов (Structured Prompting). Этот подход заключается в предоставлении LLM четко определенных входных данных, включающих текущее состояние окружающей среды, запланированные точки маршрута робота и конкретные инструкции по выполнению задачи. Структурирование запросов позволяет LLM более точно интерпретировать намерения пользователя и генерировать последовательности действий, соответствующие поставленной цели. Ключевые элементы структурированного запроса включают определение формата входных данных, использование ключевых слов и фраз, а также явное указание желаемого формата выходных данных, что обеспечивает предсказуемость и надежность работы системы.

ActionReasoning: Физическое Рассуждение в 3D Пространстве
Фреймворк ActionReasoning расширяет возможности больших языковых моделей (LLM) за счет интеграции физических ограничений и законов, действующих в среде робота. В отличие от LLM, работающих исключительно с текстовыми данными, ActionReasoning обеспечивает привязку логических заключений к реальным физическим взаимодействиям. Это достигается путем моделирования окружения робота и его способности манипулировать объектами в трехмерном пространстве, что позволяет LLM генерировать планы действий, учитывающие физическую реализуемость и избегающие невозможных или опасных ситуаций. По сути, ActionReasoning предоставляет LLM «чувство физики», необходимое для успешного управления роботом в реальном мире.
В основе системы лежит логика SE(3), представляющая собой математический формализм для описания положений и ориентаций объектов в трехмерном пространстве. Использование SE(3) позволяет роботу осуществлять физическое рассуждение, необходимое для планирования и выполнения сложных манипуляций. В частности, SE(3) позволяет точно моделировать трансформации, включая вращения и перемещения, что критически важно для оценки досягаемости, захвата объектов и координации движений манипулятора. Такой подход обеспечивает возможность предсказывать результаты действий робота в трехмерной среде и избегать столкновений, повышая надежность и точность выполнения задач.
Основой функционирования системы является физическое моделирование, имитирующее взаимодействие робота с объектами и окружающей средой. В качестве физического исполнительного устройства используется манипулятор Robot Arm, чьи движения и воздействие на окружение просчитываются в симуляции. Это позволяет предсказывать результаты манипуляций, оптимизировать траектории и избегать столкновений до их фактического выполнения в реальном мире. Моделирование учитывает физические свойства объектов, такие как масса, трение и упругость, обеспечивая реалистичное представление взаимодействия.
Для обеспечения безопасной и надежной работы робота ключевыми являются методы обнаружения контакта и предотвращения столкновений. Разработанная система продемонстрировала среднее значение 3D IoU (Intersection over Union) равное 0.8803 при выполнении задачи кладки кирпича. Данный показатель подтверждает значительно улучшенную геометрическую точность при манипуляциях с объектами в трехмерном пространстве и свидетельствует об эффективности используемых алгоритмов для предсказания и предотвращения нежелательных контактов и столкновений.

От Декомпозиции к Исполнению: Многоагентный Подход
Для решения сложных задач, таких как построение башен из кирпичей, система “ActionReasoning” использует архитектуру, основанную на множестве взаимодействующих агентов. Такой подход позволяет разложить единую, комплексную задачу на более мелкие, управляемые подзадачи, каждая из которых решается отдельным агентом. Взаимодействие между этими агентами происходит посредством обмена информацией и координации действий, что значительно повышает эффективность и скорость выполнения всей задачи. Использование многоагентной системы позволяет не только решать сложные задачи, но и адаптироваться к изменяющимся условиям окружающей среды, обеспечивая большую гибкость и надежность в работе.
Система, разработанная для решения сложных задач, использует подход, основанный на декомпозиции задач — разделении сложного процесса на ряд более простых и управляемых подзадач. Такой метод позволяет агентам системы выполнять эти подзадачи параллельно, значительно повышая общую эффективность и скорость выполнения. Вместо последовательного выполнения всех этапов одной единицей, распределение работы между несколькими агентами обеспечивает более рациональное использование ресурсов и сокращает время, необходимое для достижения конечной цели. Данный принцип позволяет справляться с задачами, которые были бы слишком сложными или трудоемкими для выполнения одним агентом, открывая возможности для создания более гибких и производительных роботизированных систем.
В основе эффективной координации между агентами в многоагентной системе лежит общая модель мира — унифицированное представление об окружающей среде. Эта модель не просто фиксирует текущее состояние, но и позволяет прогнозировать последствия действий, что критически важно для планирования и принятия решений. Агенты, оперируя единой моделью мира, способны согласовывать свои действия, избегать конфликтов и совместно решать сложные задачи. Использование общей модели значительно повышает устойчивость системы к неопределенности и изменениям в окружающей среде, поскольку каждый агент имеет доступ к актуальной информации и может адаптироваться к новым условиям. Таким образом, модель мира выступает ключевым элементом, обеспечивающим когерентность и эффективность работы всей системы.
В ходе тестирования разработанной многоагентной системы, удалось добиться значительного улучшения точности выполнения задач по сравнению с традиционными контроллерами. Зафиксировано снижение средней ошибки вращения на 30.0% (до 0.703 см) и уменьшение средней ошибки смещения центра на 85.2% (до 0.637 см). Эти результаты демонстрируют, что предложенный подход к разложению задач и координации агентов позволяет создавать более гибкие и адаптивные роботизированные системы, способные выполнять сложные манипуляции с повышенной точностью и надежностью. Такой прогресс открывает новые возможности для автоматизации в различных областях, где требуется высокая точность и надежность робототехнических операций.
Исследование демонстрирует, что даже самые передовые системы, вроде ActionReasoning, оперирующие с большими языковыми моделями и трехмерным пространством, в конечном итоге сводятся к решению прикладных задач. Иллюзия автономности и интеллектуального планирования неизбежно сталкивается с необходимостью манипулировать физическим миром, где точность и надежность важнее изящной архитектуры. Как однажды заметил Джон фон Нейманн: «В науке нет места для предрассудков — только логика и расчет». Именно этот принцип должен лежать в основе любого подхода к робототехнике, где абстрактные модели неизбежно сталкиваются с жестокой реальностью физических ограничений и непредсказуемостью окружения. Разработчики стремятся к созданию сложных систем, но часто забывают о простоте и эффективности базовых принципов.
Что дальше?
Представленная работа, несомненно, продвигает границу между декларативным описанием задачи и её физическим воплощением. Однако, иллюзия элегантной архитектуры быстро рассеивается при столкновении с реальностью. Мир, в котором кирпичи всегда идеально прямоугольные, а освещение — предсказуемо, существует лишь в симуляциях. В реальности же, неизбежно возникнут отклонения, не учтённые даже самыми мощными языковыми моделями. И тогда, оптимизированный для идеального случая агент, столкнётся с необходимостью импровизации — то есть, возвращения к хаотичному перебору вариантов.
Попытки масштабировать подобный подход к более сложным задачам и многоагентным системам неизбежно выявляют новые узкие места. Увеличение количества агентов — это не просто линейное увеличение сложности. Это экспоненциальный рост вероятности коллизий, непредсказуемого поведения и, как следствие, необходимости в постоянной ручной корректировке. И, как показывает опыт, всё, что автоматизировано, рано или поздно требует ручного вмешательства.
В конечном итоге, задача сводится не к созданию идеального планировщика, а к разработке систем, способных к самодиагностике и самовосстановлению. Архитектура, которая не предполагает возможность сбоев — утопия. Настоящий прогресс заключается в создании систем, которые способны извлекать уроки из собственных ошибок, а не просто повторять их с большей скоростью. Ведь код не рефакторят — в нём реанимируют надежду.
Оригинал статьи: https://arxiv.org/pdf/2602.21161.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
2026-02-26 06:02