Автор: Денис Аветисян
Исследователи разработали метод тонкой настройки больших видеомоделей, позволяющий роботам эффективно планировать и выполнять сложные манипуляции в реальном мире.
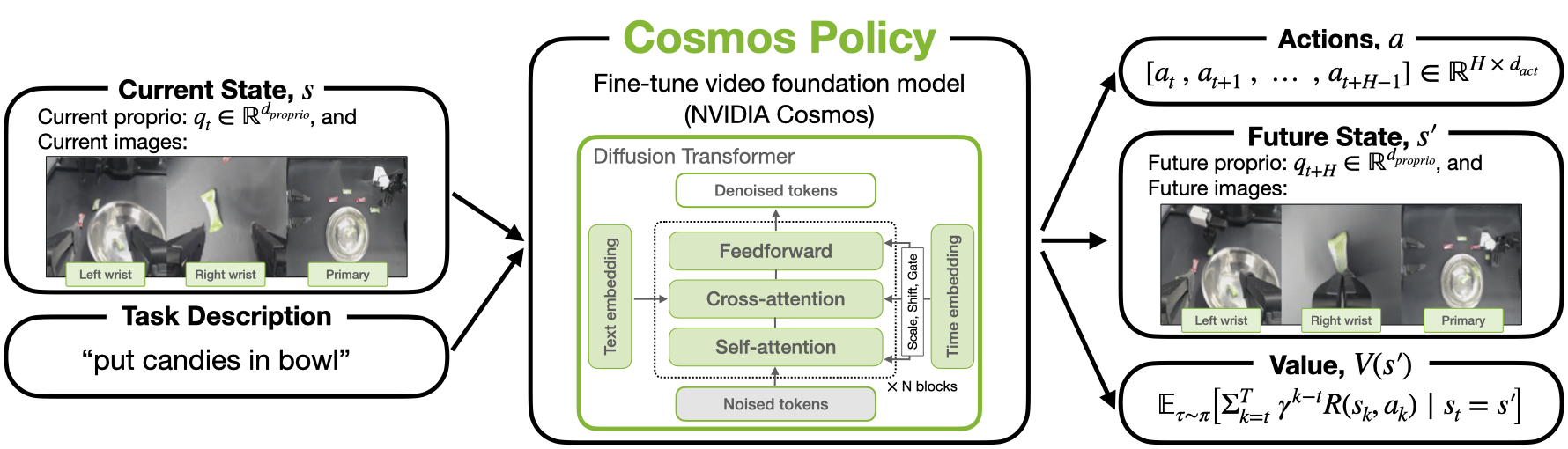
Представлена Cosmos Policy — передовая стратегия управления роботами, основанная на имитационном обучении и использовании мировых моделей, демонстрирующая высокую производительность как в симуляции, так и в реальных условиях.
Несмотря на впечатляющие успехи в генерации видео, адаптация этих моделей для управления роботами традиционно требует сложных архитектурных модификаций и многоэтапного обучения. В данной работе, представленной под названием ‘Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning’, предлагается упрощенный подход, позволяющий эффективно использовать предварительно обученную модель видео \mathcal{Cosmos-Predict2} в качестве основы для робототехнической политики, требующий лишь одноэтапного обучения на демонстрационных данных. Cosmos Policy напрямую генерирует действия робота, кодируя их в латентном пространстве видеомодели, и, что важно, предсказывает будущие состояния и ожидаемые награды для планирования траекторий. Достигнув передовых результатов в симуляциях и реальных задачах манипулирования, может ли этот подход открыть новые горизонты в создании более гибких и адаптивных робототехнических систем?
Преодолевая Имитацию: Необходимость Прогностической Политики
Традиционно, обучение роботов часто опирается на обширное имитационное обучение, когда робот копирует действия человека-оператора. Однако, такой подход имеет существенное ограничение: робот, обученный исключительно на конкретных примерах, испытывает трудности при столкновении с ситуациями, не встречавшимися ранее в процессе обучения. Это связано с тем, что имитационное обучение, по сути, является запоминанием паттернов, а не пониманием лежащих в их основе принципов. В результате, робот, прекрасно справляющийся с задачей в знакомой обстановке, может оказаться беспомощным в незнакомой или динамично меняющейся среде, что существенно ограничивает его автономность и адаптивность. Необходимость преодоления этого ограничения является ключевой задачей в развитии современной робототехники.
Для достижения подлинной автономности роботам необходимо не просто реагировать на текущую ситуацию, но и предвидеть её развитие в динамически меняющейся среде. В отличие от чисто реактивных подходов, которые оперируют исключительно с непосредственными сенсорными данными, способность прогнозировать будущие состояния позволяет роботу принимать проактивные решения и адаптироваться к неожиданным изменениям. Такое предвидение требует построения внутренних моделей мира и использования их для планирования действий, направленных на достижение цели даже при наличии неопределенности. Эффективное прогнозирование позволяет избежать столкновений, оптимизировать траекторию движения и, в конечном итоге, повысить надёжность и гибкость робота в реальных условиях эксплуатации.

Политика Cosmos: Основа для Видео-Обусловленного Действия
Политика Cosmos представляет собой новый подход к управлению роботами, основанный на тонкой настройке большой видео-фундаментальной модели Cosmos-Predict2-2B. Данная модель, состоящая из 2 миллиардов параметров, предварительно обучена на обширном наборе видеоданных, что позволяет ей эффективно моделировать динамику визуальных сцен. В отличие от традиционных методов, требующих обучения с нуля для каждой конкретной задачи, Cosmos-Predict2-2B предоставляет уже существующие пространственно-временные представления, которые служат отправной точкой для адаптации к новым сценариям управления роботом. Этот подход значительно сокращает время обучения и повышает обобщающую способность системы, позволяя роботу успешно выполнять задачи в различных и ранее не встречавшихся условиях.
Базовая модель Cosmos-Predict2-2B обеспечивает надежную основу для планирования действий благодаря наличию встроенных пространственно-временных априорных знаний. Эти априорные знания, полученные в процессе обучения на обширном наборе видеоданных, позволяют модели формировать правдоподобные прогнозы о будущих состояниях среды. Способность модели предсказывать развитие событий во времени и пространстве значительно повышает эффективность и устойчивость систем управления роботами, позволяя им более эффективно адаптироваться к изменяющимся условиям и планировать последовательности действий, направленные на достижение заданных целей. Встроенные априорные знания уменьшают потребность в большом количестве данных для обучения конкретным задачам, что делает подход более практичным и масштабируемым.
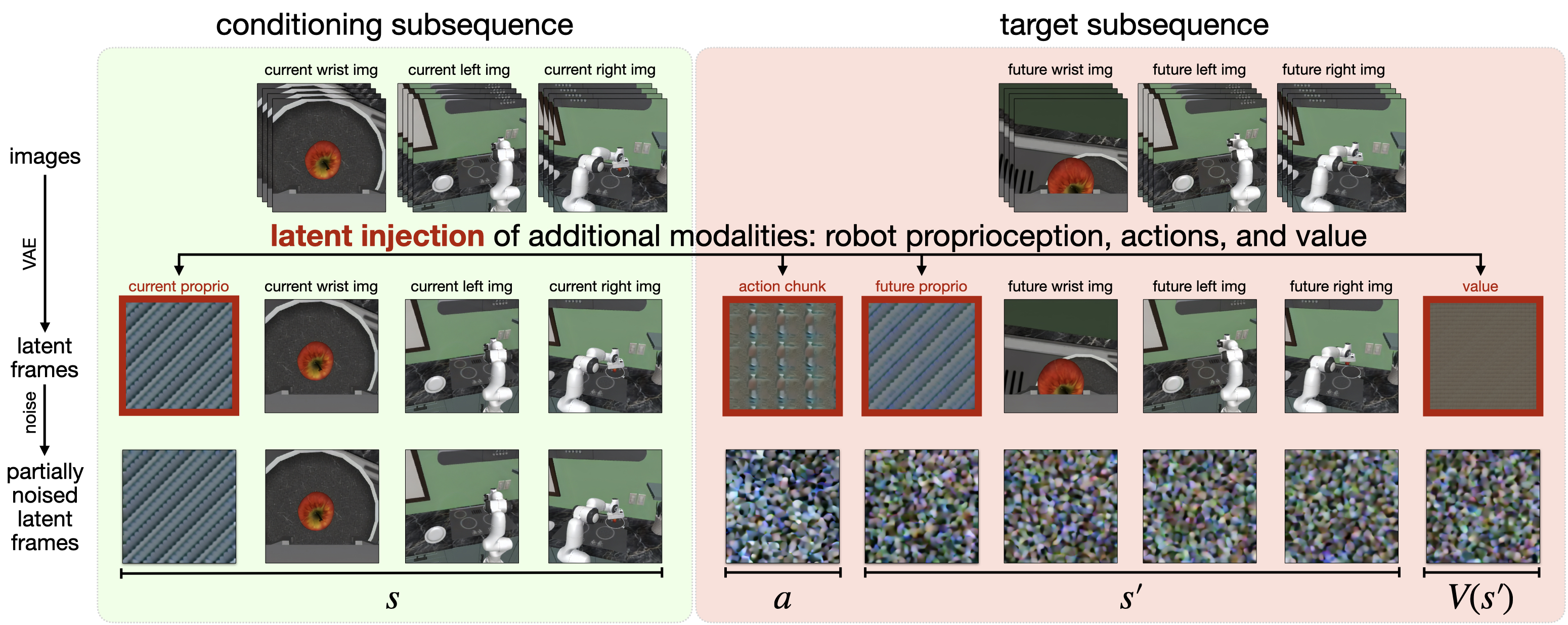
Политика Cosmos использует метод инъекции латентных кадров для объединения предсказаний действий, проприоцепции и ценности непосредственно в процесс видеодиффузии. Этот подход позволяет модели Cosmos-Predict2-2B эффективно интегрировать информацию о планируемых действиях робота, его текущем состоянии и оценке желаемых результатов в процесс генерации видеопоследовательности. Инъекция латентных кадров осуществляется в скрытом пространстве модели, что позволяет избежать прямого вмешательства в процесс генерации пикселей и сохраняет когерентность и реалистичность генерируемого видео. Таким образом, модель способна предсказывать не только визуальное развитие сцены, но и наиболее вероятные действия робота в этой сцене, учитывая его внутреннее состояние и цели.
Прогностическое Планирование с Использованием Выборки Best-of-N
В Cosmos Policy используется метод выборки best-of-N, который предполагает генерацию нескольких потенциальных последовательностей действий на основе прогнозов будущих состояний и оценок их ценности. Вместо выбора единственного, наиболее вероятного действия, система формирует N различных вариантов развития событий, каждый из которых представляет собой возможную последовательность действий. Эти последовательности формируются на основе предсказаний о том, как текущее действие повлияет на будущее состояние среды, и оценки, насколько это будущее состояние соответствует желаемым целям. Затем, на основе этих прогнозов и оценок, выбирается наиболее перспективная последовательность действий для выполнения, что позволяет повысить устойчивость и эффективность системы в динамичной среде.
Прогнозируемые состояния будущего, полученные из видео-фундаментальной модели, являются ключевым фактором оценки качества каждого кандидата на действие. Модель, анализируя текущий кадр и историю, генерирует вероятные сценарии развития событий после выполнения конкретного действия. Эти предсказанные состояния затем используются для оценки, насколько данное действие приближает систему к желаемой цели или избегает нежелательных исходов. Точность прогнозирования будущих состояний напрямую влияет на эффективность выбора оптимального действия, поскольку позволяет системе различать перспективные и бесперспективные варианты, максимизируя долгосрочную производительность и накопление вознаграждения. Отсутствие точных прогнозов приводит к принятию субоптимальных решений и снижению общей эффективности системы.
Прогнозирование ценности (Value Prediction) в системе Cosmos Policy позволяет оценивать потенциальные исходы различных действий, направляя процесс планирования к выбору стратегий, максимизирующих долгосрочное вознаграждение. Система, используя предсказанные состояния и модели вознаграждения, присваивает каждому возможному действию оценку, отражающую ожидаемую выгоду. Это позволяет отбирать не только действия, приводящие к немедленному результату, но и те, которые создают условия для более значительных вознаграждений в будущем, оптимизируя тем самым общую производительность и кумулятивную награду системы. Выбор действий осуществляется на основе ранжирования по прогнозируемой ценности, что обеспечивает эффективное достижение поставленных целей.
Практическая Валидация и Сравнение с Современными Методами
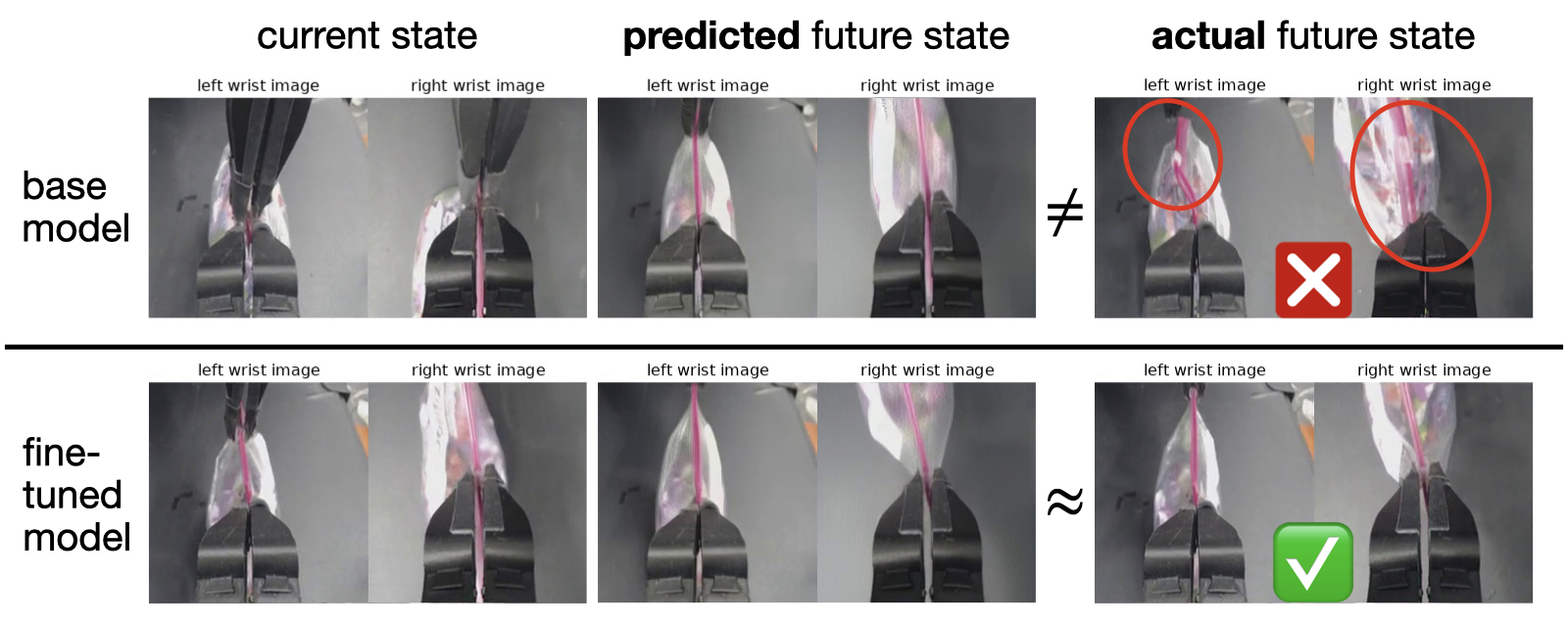
Политика Cosmos была успешно развернута и протестирована на роботе ALOHA, что подтверждает её применимость в реальных условиях. В ходе испытаний робот ALOHA успешно выполнял различные задачи, демонстрируя способность политики адаптироваться к сложным и непредсказуемым ситуациям, возникающим в реальном мире. Этот этап позволил оценить не только теоретическую эффективность подхода, но и его практическую реализуемость, выявив потенциальные проблемы и возможности для дальнейшей оптимизации. Полученные результаты являются важным шагом на пути к созданию более автономных и надежных робототехнических систем, способных эффективно функционировать в повседневной жизни.
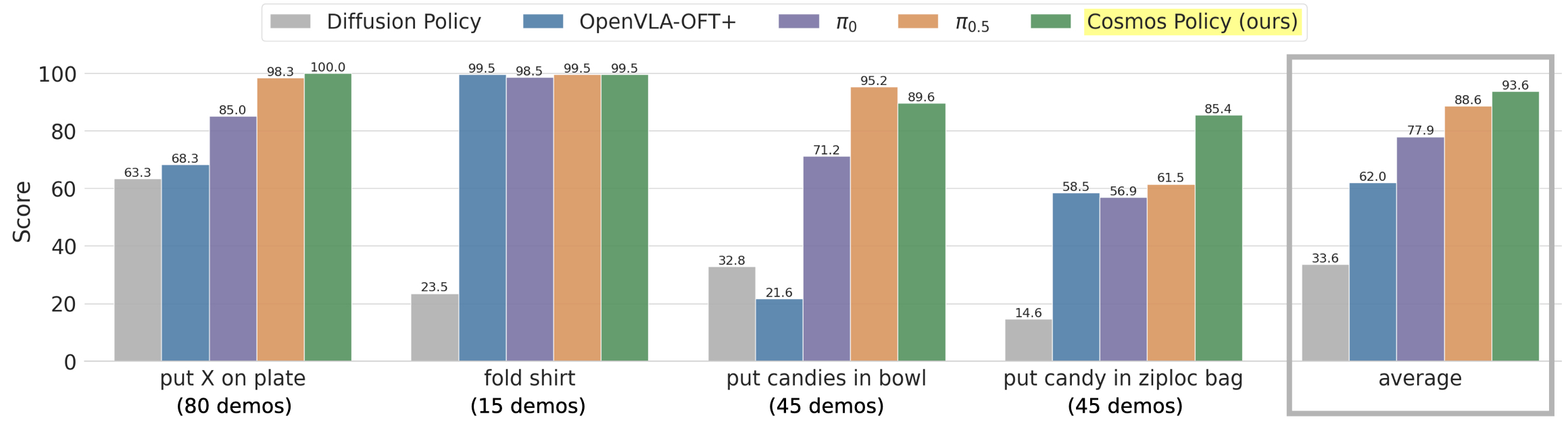
Для оценки эффективности новой системы управления роботами, была проведена серия сравнительных тестов на широко используемых наборах данных LIBERO и RoboCasa. В ходе экспериментов, разработанный подход был сопоставлен с результатами, полученными с помощью известных методов, таких как Diffusion Policy и OpenVLA-OFT. Использование этих стандартных наборов данных позволило объективно оценить способность системы к обобщению и адаптации к различным условиям, а также выявить ее преимущества перед существующими решениями в задачах, требующих от робота выполнения сложных манипуляций и навигации в реальных условиях.
Результаты тестирования демонстрируют значительный прогресс в обобщающей способности и устойчивости системы. На стандартных наборах данных LIBERO и RoboCasa достигнуты передовые показатели успешности, составившие 98.5% и 67.1% соответственно. Особенно примечательно, что использование модели, основанной на планировании, позволило увеличить процент успешного выполнения задач в реальных условиях на 12.5%. Данные показатели свидетельствуют о том, что разработанная система не только эффективно справляется с известными сценариями, но и демонстрирует повышенную надежность при столкновении с новыми, непредсказуемыми ситуациями, что крайне важно для практического применения робототехники.
Исследование, представленное в данной работе, демонстрирует элегантность подхода к управлению роботами, основанного на тонкой настройке больших видеомоделей. Авторы добились впечатляющих результатов, интегрируя мультимодальные данные и планирование на основе моделей, что позволяет роботам успешно выполнять манипуляции как в симуляции, так и в реальном мире. Этот метод, подобно строгой математической теореме, подтверждает, что корректность алгоритма важнее, чем просто его работа на тестовых примерах. Как однажды заметил Пол Эрдёш: «Математика — это алфавит, на котором написана книга природы». В данном случае, Cosmos Policy выступает в роли тщательно выверенного математического выражения, позволяющего «прочитать» и взаимодействовать с физическим миром.
Куда же дальше?
Без четкого определения задачи, любое усовершенствование — лишь шум, умноженный на вычислительные мощности. Представленная работа, безусловно, демонстрирует впечатляющую интеграцию видео-диффузионных моделей и робототехники, однако фундаментальный вопрос остается нерешенным: что именно мы пытаемся оптимизировать? Простое воспроизведение наблюдаемого поведения — это лишь имитация, а не истинный интеллект. Необходимо строгое математическое определение целевой функции, а не эмпирическая оценка «успешности» манипуляций.
Особое внимание следует уделить проблеме обобщения. Текущие модели, даже самые передовые, остаются хрупкими и чувствительными к незначительным изменениям в окружающей среде. Недостаточно продемонстрировать работоспособность в симуляции; алгоритм должен быть доказуемо устойчивым к шуму и неопределенности реального мира. Иначе, все усилия по обучению сводятся к построению сложных, но бесполезных декораций.
Будущие исследования должны сосредоточиться на разработке формальных методов верификации и валидации робототехнических систем. Достаточно ли нам «черного ящика», который выдает желаемый результат? Или необходимо понимать внутреннюю логику принятия решений? Истинная элегантность не в достижении результата, а в чистоте и доказуемости самого алгоритма.
Оригинал статьи: https://arxiv.org/pdf/2601.16163.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-23 22:20