Автор: Денис Аветисян
Новое исследование систематически изучает возможности создания моделей, объединяющих зрение, язык и управление, для повышения эффективности и обобщающей способности роботов.
В статье представлен анализ пространства архитектур Vision-Language-Action моделей и стратегий обучения для улучшения управления роботами и прогнозирования действий.
Несмотря на стремительное развитие моделей Vision-Language-Action (VLA), систематического анализа ключевых факторов, определяющих их эффективность, до сих пор не проводилось. В работе ‘VLANeXt: Recipes for Building Strong VLA Models’ представлено комплексное исследование архитектурного пространства VLA, направленное на выявление оптимальных решений для обучения роботов. Систематически анализируя различные компоненты, от базовых моделей до методов обработки проприоцептивных данных, авторы сформулировали 12 ключевых рекомендаций для создания надежных и обобщающих VLA-моделей, воплощенных в предложенной архитектуре VLANeXt. Сможем ли мы, опираясь на эти практические рецепты, значительно ускорить прогресс в области обучения роботов сложным манипуляциям и принятию решений?
Традиционные подходы и их ограничения
Традиционные методы робототехники зачастую полагаются на заранее определенные, вручную настроенные характеристики объектов и окружения, что существенно ограничивает способность роботов адаптироваться к новым, незнакомым условиям. Эта зависимость от жестко заданных параметров делает роботов уязвимыми к изменениям в окружающей среде — будь то изменение освещения, появление новых препятствий или даже незначительное смещение объектов. В результате, робот, успешно функционирующий в одной среде, может столкнуться с серьезными трудностями при переходе в другую, требуя повторной ручной настройки и, как следствие, значительных затрат времени и ресурсов. Эта проблема особенно актуальна в динамичных средах, таких как домашние интерьеры или производственные цеха, где условия постоянно меняются.
Основная сложность в управлении роботами заключается в преобразовании абстрактных языковых команд в точные и непрерывные действия. Роботу необходимо не просто понять, что нужно сделать, но и как это выполнить, учитывая множество нюансов окружающей среды и собственных возможностей. Этот процесс требует сложного сопоставления семантического значения языка с конкретными параметрами управления моторами и другими исполнительными механизмами. Существующие подходы часто сталкиваются с проблемой «разрыва» между высокоуровневым описанием задачи и низкоуровневым управлением, что приводит к неточностям и неэффективности движений. Поэтому, разработка эффективных методов для перевода языковых инструкций в плавные и скоординированные действия является ключевой задачей в современной робототехнике и открывает путь к созданию более интеллектуальных и адаптивных роботов.
Недавние достижения в области визуально-языковых моделей (VLM) открывают многообещающие перспективы для управления роботами, однако непосредственное применение этих моделей сталкивается с трудностями, связанными со сложностью пространства действий. VLM демонстрируют впечатляющую способность понимать и связывать визуальную информацию с текстовыми инструкциями, но преобразование этих инструкций в непрерывные, точные движения робота требует преодоления существенных ограничений. Пространство действий робота, включающее в себя бесконечное число возможных положений и траекторий, значительно превосходит возможности стандартных методов дискретизации, используемых в VLM. Это приводит к неточностям и неэффективности управления, поскольку модели вынуждены выбирать из ограниченного набора предустановленных действий вместо генерации плавных и адаптивных движений. Исследователи активно работают над разработкой новых архитектур и алгоритмов, позволяющих VLM эффективно работать с непрерывными пространствами действий, используя такие подходы как иерархическое управление и обучение с подкреплением, чтобы преодолеть эти ограничения и реализовать потенциал VLM в робототехнике.
VLANeXt: Новый подход к Видение-Язык-Действие
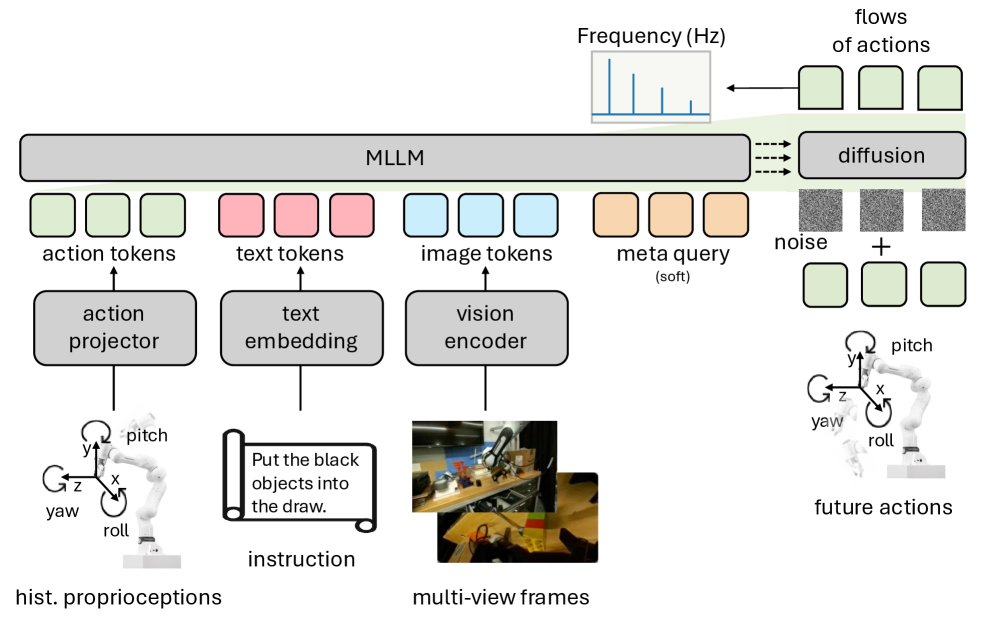
VLANeXt представляет собой передовую модель Видение-Язык-Действие, разработанную для повышения эффективности выполнения роботами сложных задач. Данная архитектура объединяет обработку визуальной информации, понимание естественного языка и планирование действий в единую нейронную сеть. В отличие от традиционных подходов, VLANeXt оптимизирована для обработки многоступенчатых задач, требующих координации действий и адаптации к изменяющейся обстановке. Модель демонстрирует улучшенные показатели в задачах, требующих понимания инструкций на естественном языке и преобразования их в последовательность действий, выполняемых роботом в физическом мире.
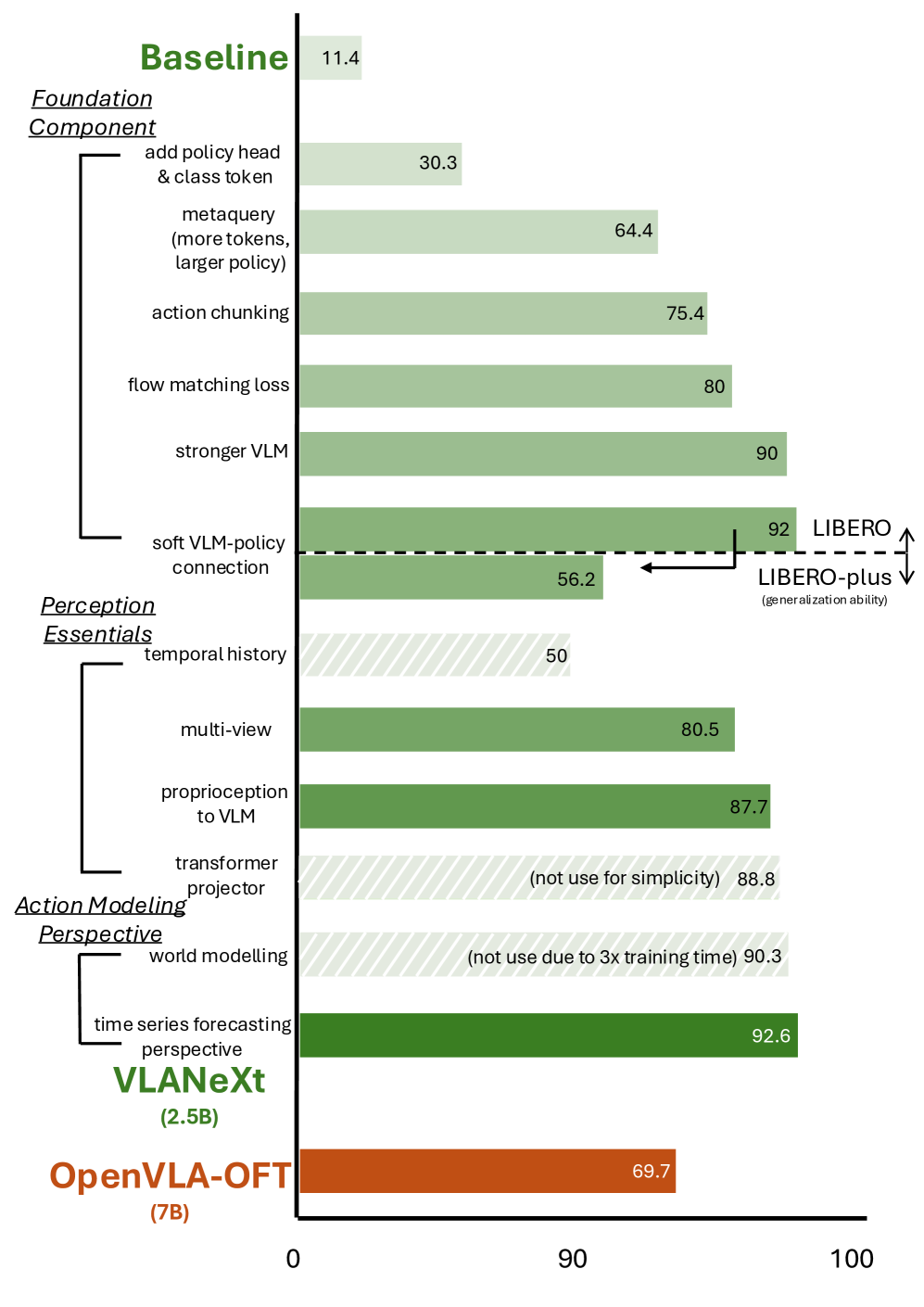
Ключевой особенностью архитектуры VLANeXt является механизм ‘Soft VLM-Policy Connection’, обеспечивающий эффективную передачу информации между языковой моделью зрения (VLM) и системой управления роботом. Вместо прямой передачи данных, используется буфер в виде обучаемых запросов (learnable queries), выступающих в роли латентного посредника. Этот подход позволяет VLM формулировать запросы, специфичные для текущей задачи и контекста, а системе управления — интерпретировать их и генерировать соответствующие действия. Использование обучаемых запросов позволяет динамически адаптировать процесс передачи информации, оптимизируя его для различных сценариев и снижая вычислительную нагрузку по сравнению с традиционными методами, требующими обработки больших объемов данных напрямую между VLM и контроллером робота.
В отличие от традиционных методов, VLANeXt позволяет избежать вычислительных ограничений, связанных с обработкой больших объемов информации и сложными вычислениями при предсказании действий робота. Это достигается за счет оптимизации передачи данных между языковой моделью (VLM) и политикой управления роботом, что снижает задержки и повышает скорость обработки. В результате, система способна генерировать более точные прогнозы действий в реальном времени, что критически важно для выполнения сложных роботизированных задач и обеспечивает более эффективное взаимодействие с окружающей средой.
В архитектуре VLANeXt для повышения когерентности действий используется метод “Action Chunking”, предполагающий одновременное предсказание нескольких последующих действий. Вместо последовательного формирования каждого действия, модель прогнозирует сразу несколько шагов, что позволяет учитывать долгосрочные зависимости и контекст задачи. Такой подход снижает вероятность возникновения нелогичных или разрозненных действий, обеспечивая более плавное и связное выполнение роботом сложных манипуляций. Предсказание “чанков” действий также позволяет модели эффективнее планировать и оптимизировать траекторию движения, улучшая общую производительность и точность выполнения задач.
Подтвержденные результаты и повышение производительности
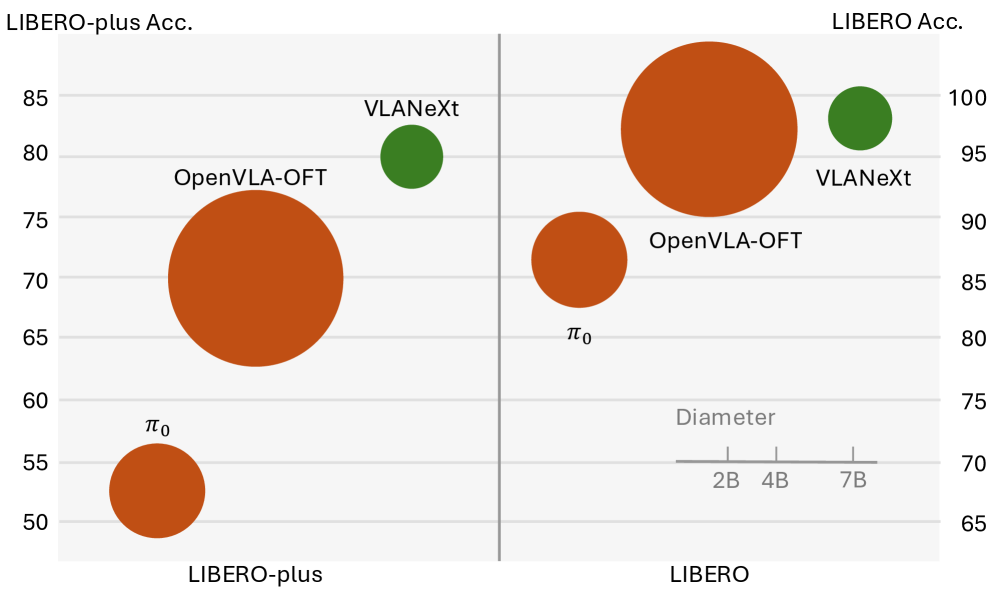
VLANeXt демонстрирует передовые результаты на эталонных наборах данных LIBERO и LIBERO-plus, что подтверждает его способность к обобщению и эффективной работе в условиях возмущений. Достигнутые показатели свидетельствуют о превосходстве модели в прогнозировании траекторий и планировании действий в сложных, динамически меняющихся средах. Успешное выполнение тестов на данных LIBERO и LIBERO-plus подтверждает надежность и устойчивость VLANeXt к различным типам помех и неточностей, что критически важно для практического применения в робототехнике.
В ходе тестирования на бенчмарке LIBERO-plus, модель VLANeXt показала на 10% более высокий процент успешных выполнений заданий по сравнению с предыдущим лидером, OpenVLA-OFT. Данный результат был получен при использовании стандартного протокола оценки и идентичных параметров среды, что позволяет напрямую сравнить эффективность двух моделей в решении задач манипулирования объектами. Увеличение процента успешных выполнений демонстрирует значительное улучшение способности VLANeXt к планированию и выполнению сложных действий в условиях, приближенных к реальным.
Интеграция частотно-доменного моделирования позволила повысить точность предсказания сложных последовательностей действий. Данный подход учитывает спектральные характеристики временных рядов, что позволяет модели VLANeXt более эффективно экстраполировать траектории и предсказывать будущие состояния робота. В отличие от традиционных методов, оперирующих непосредственно с временными данными, частотно-доменное моделирование позволяет выделить ключевые частотные компоненты, определяющие динамику движения, и использовать их для более точного прогнозирования. Это особенно важно при выполнении сложных манипуляций, требующих учета множества факторов и предсказания долгосрочных последствий действий.
Устойчивость модели VLANeXt к возмущениям и изменениям в окружающей среде повышается за счет использования проприоцептивной обусловленности. Этот метод предполагает включение в процесс предсказания информации о внутреннем состоянии робота — его текущей позе, скорости и ускорении суставов. Интеграция данных проприоцепции позволяет модели более точно оценивать и компенсировать неточности в восприятии окружающей среды, а также предсказывать последствия действий робота, учитывая его физические характеристики и текущее состояние. Это особенно важно в динамичных и непредсказуемых сценариях, где точное отслеживание внутреннего состояния робота критически необходимо для обеспечения надежной и безопасной работы.
Использование многоканального визуального ввода, объединяющего данные с камеры от третьего лица и камеры, установленной на манипуляторе робота, позволяет получать дополнительные геометрические подсказки, что положительно сказывается на производительности и надежности системы. Камера от третьего лица обеспечивает глобальное представление об окружающей среде и позволяет отслеживать положение объектов на больших расстояниях. В то время как камера на манипуляторе предоставляет детальную информацию о непосредственной близости, включая ориентацию и расстояние до объекта, что критически важно для точного выполнения манипуляций. Комбинирование этих двух источников визуальной информации позволяет модели более эффективно оценивать геометрию сцены и планировать оптимальные траектории движения.

Перспективы развития и значимость для отрасли
Разработка VLANeXt опирается на уже существующие модели VLA, такие как RT-2 и OpenVLA, что обеспечивает плавный переход к новым достижениям в области робототехники и искусственного интеллекта. Используя проверенную архитектуру и накопленный опыт, исследователи смогли создать систему, способную к более эффективному обучению и адаптации. Этот подход не только ускоряет процесс разработки, но и позволяет строить на существующей базе, избегая необходимости начинать с нуля. В результате, VLANeXt представляет собой не просто новую модель, а логическое продолжение и развитие предшествующих разработок, открывающее широкие перспективы для дальнейших исследований и практического применения в различных областях, от автоматизации бытовых задач до создания сложных промышленных роботов.
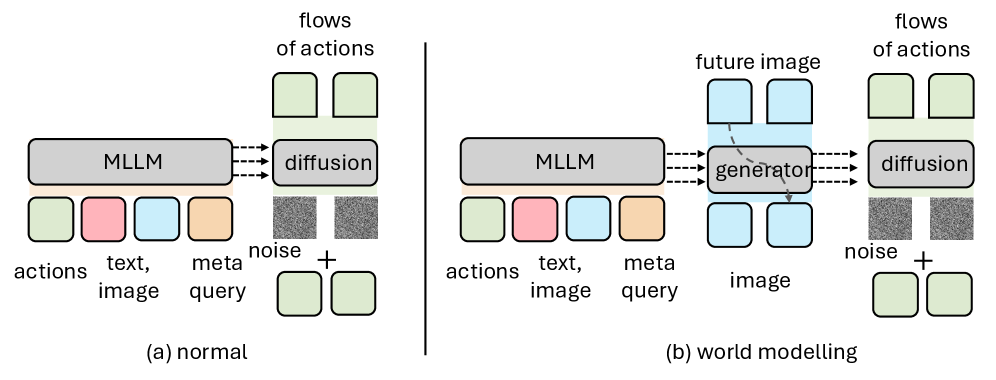
Интеграция методов моделирования мира позволяет VLANeXt значительно расширить понимание окружающей среды, выходя за рамки простого распознавания объектов. Вместо пассивного восприятия, модель способна создавать внутреннее представление о пространстве, предсказывать изменения и планировать действия на основе этой информации. Этот подход позволяет роботу не только реагировать на текущую ситуацию, но и проявлять проактивность, адаптируясь к новым условиям и выполняя задачи более эффективно. В результате, появляется возможность создания роботов, способных самостоятельно ориентироваться в сложных средах, взаимодействовать с объектами и предвидеть последствия своих действий, что является ключевым шагом к созданию действительно автономных и интеллектуальных систем.
Модель VLANeXt демонстрирует значительный прогресс в объединении понимания языка, визуальной информации и способности к действию, что открывает новые горизонты для разработки более интуитивно понятных и универсальных роботов-помощников. Вместо того, чтобы полагаться на заранее запрограммированные последовательности, система способна интерпретировать лингвистические инструкции в контексте визуально воспринимаемой среды, а затем преобразовывать это понимание в конкретные действия. Такое слияние модальностей позволяет роботам не просто выполнять команды, а адаптироваться к изменяющимся условиям и эффективно решать задачи в реальном времени, приближая их к способности взаимодействовать с людьми на качественно новом уровне и выполнять сложные манипуляции в динамичных ситуациях.
Представленная работа знаменует собой важный этап в создании роботов, способных к беспрепятственному взаимодействию с человеком и выполнению сложных задач в реальных условиях. В отличие от существующих систем, часто ограниченных узкой специализацией, данное исследование демонстрирует возможность объединения языкового понимания, визуального восприятия и способности к действию в единой архитектуре. Это позволяет создавать роботов, которые не просто выполняют запрограммированные команды, но и способны адаптироваться к изменяющейся обстановке, понимать намерения человека и самостоятельно принимать решения. Успешная реализация подобного подхода открывает перспективы для широкого применения роботов в различных сферах — от помощи по дому и ухода за пожилыми людьми до работы в промышленных условиях и участия в спасательных операциях, значительно повышая эффективность и безопасность выполняемых задач.
Исследование пространства архитектур моделей Vision-Language-Action (VLA), представленное в работе, неизбежно сталкивается с проблемой технического долга. Каждая элегантная теоретическая конструкция, направленная на улучшение обобщающей способности роботов, рано или поздно требует практической реализации, а значит, и компромиссов. Авторы стремятся систематизировать выбор архитектурных решений и стратегий обучения, но, как показывает опыт, «продакшен всегда найдёт способ сломать элегантную теорию». Особенно это касается обобщения — робот, обученный в симулированной среде, часто демонстрирует неожиданные результаты в реальном мире. Как метко заметил Ян ЛеКюн: «Машинное обучение — это математика плюс немного магии». И магия эта, как правило, требует постоянной поддержки и исправления багов, фиксируемых в багтрекерах — дневниках боли любого проекта.
Что дальше?
Работа, представленная в данной статье, методично разбирает конструктор LEGO под названием «Визуально-Языковые-Действия». Похвально, конечно, но не стоит обольщаться. Каждый «прорыв» в области робототехники, как правило, оказывается набором компромиссов, которые рано или поздно придётся расплачивать. Предсказание действий робота — задача сложная, и сейчас это, вероятно, назовут «AI» и получат инвестиции, но не стоит забывать, что в основе любой сложной системы когда-то лежал простой bash-скрипт.
Ключевым ограничением остаётся обобщение. Даже самые элегантные модели, обученные на тщательно подобранных данных, неизбежно спотыкаются о реальный мир, полный шума и непредсказуемости. Пока что мы просто перекладываем сложность с робота на человека, который должен создать эти «идеальные» данные. И документация, как обычно, врёт о возможности переноса обучения на совершенно новые сценарии.
В перспективе, вероятно, потребуется отойти от идеи универсальной модели и сосредоточиться на создании модульных, адаптивных систем. Каждая задача — свой набор инструментов, каждая среда — своя калибровка. Технический долг — это просто эмоциональный долг с коммитами, и рано или поздно придётся возвращать этот кредит, разбирая всё по винтикам и переписывая код заново. Начинаю подозревать, что они просто повторяют модные слова.
Оригинал статьи: https://arxiv.org/pdf/2602.18532.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
- Оживший аватар: Генерация видео в реальном времени по голосу
- Серебро и медь: новый взгляд на наноаллои
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Точные вычисления: Новые методы решения дифференциальных уравнений
- Саморедактирование научных статей: новый взгляд на качество и влияние
- Искусственный интеллект в действии: как оптимизировать сложные задачи
- Обход Больших KATов: Новые Методы Символьного Анализа
- Квантовая оптимизация: гибкий подход к разработке приложений
2026-02-24 15:12