Автор: Денис Аветисян
Исследователи представили AgentEvolver – систему, способную самостоятельно генерировать задачи и совершенствовать процесс обучения, открывая путь к более эффективному и адаптивному искусственному интеллекту.

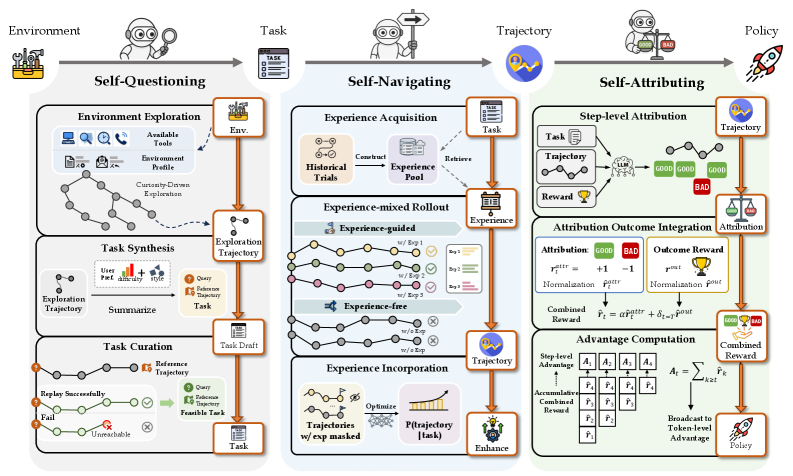
Представленная система AgentEvolver использует большие языковые модели для автономной генерации задач, самонаправления и улучшения обучения посредством механизмов самооценки и атрибуции.
Несмотря на огромный потенциал автономных агентов, основанных на больших языковых моделях, их разработка часто требует значительных затрат и неэффективных процедур обучения с подкреплением. В данной работе представлена система AgentEvolver: Towards Efficient Self-Evolving Agent System, предлагающая принципиально новый подход к самообучению агентов за счет использования возможностей LLM для генерации задач, оптимизации исследования среды и дифференцированного вознаграждения действий. Интегрируя механизмы само-вопрошания, само-навигации и само-оценивания, AgentEvolver обеспечивает масштабируемость, экономичность и непрерывное улучшение способностей агентов. Сможет ли подобный подход радикально упростить разработку и применение автономных агентов в различных областях?
За пределами Статических Моделей: Необходимость Адаптивных Агентов
Традиционные агенты испытывают трудности в решении сложных задач из-за жесткости и ограниченного понимания контекста. Ограниченное поддержание последовательности диалога снижает эффективность в интерактивных средах и препятствует долгосрочному планированию.
Эффективное рассуждение требует системы, способной поддерживать и развивать понимание текущего диалога – динамичную «временную шкалу контекста». Такой механизм позволяет агенту отслеживать историю взаимодействия, учитывать предыдущие действия и адаптировать стратегию в соответствии с ситуацией.
Без этого агенты склонны к повторениям или не используют накопленные знания. Отсутствие целостного представления о контексте приводит к ошибкам и неспособности эффективно взаимодействовать с окружающей средой.

Память – не просто хранилище, а компас, направляющий разум сквозь лабиринты взаимодействия.
AgentEvolver: Платформа для Динамического Управления Контекстом
Представлен AgentEvolver – саморазвивающаяся платформа, предназначенная для достижения автономной эволюции способностей посредством взаимодействия со средой. Архитектура позволяет агенту адаптировать поведение, основываясь на текущем диалоге и предыдущем опыте, обеспечивая устойчивость и согласованность взаимодействий.
Ключевым компонентом AgentEvolver является ‘Менеджер Контекста’, использующий ‘Живую Временную Шкалу Контекста’ и ‘Регистратор Снимков Временной Шкалы’ для динамического отслеживания и воспроизведения релевантной информации. Это позволяет агенту сохранять и использовать информацию о предыдущих взаимодействиях, улучшая качество решений и обеспечивая осмысленные ответы.
Предложенная архитектура обеспечивает гибкость и масштабируемость, позволяя AgentEvolver эффективно решать широкий спектр задач, требующих адаптации и обучения на опыте.
Оптимизация Поведения Агента Через Самосовершенствование
AgentEvolver реализует механизмы самосовершенствования, включая ‘Self-Navigating’ для эффективного исследования среды и ‘Self-Attributing’ для распределения вознаграждений на основе качества траектории. Это позволяет агенту автономно развивать возможности и повышать производительность.
Механизм ‘Self-Attributing’ использует ‘LLM Judge’ для предоставления нюансированной обратной связи, позволяя уточнять процесс принятия решений. Оптимизация политики осуществляется посредством ‘GRPO’, способствуя автономной эволюции и повышению эффективности агента.

Эксперименты в эталонных средах, таких как ‘AppWorld’ и ‘BFCL-v3’, показали улучшение на 29.4% в avg@8 и 36.1% в best@8 для модели 7B, а также 27.8% и 30.3% для модели 14B. Зафиксировано увеличение на 29.4% в выполнении целевых задач и на 36.1% в выполнении сценарных целевых задач для модели 7B.
Масштабируемая Инфраструктура и Перспективы Развития
Для поддержки высоких требований AgentEvolver используется масштабируемая ‘Environment Service’, построенная на основе ‘Ray’, обеспечивающая параллельное выполнение сред. Эта инфраструктура позволяет эффективно обучать и оценивать агента в разнообразных и сложных сценариях, значительно сокращая время, необходимое для достижения оптимальной производительности.
В основе системы лежит большая языковая модель ‘Qwen2.5’, предоставляющая надежную основу для рассуждений и понимания естественного языка. Это позволяет AgentEvolver эффективно взаимодействовать со средой, понимать цели и задачи, а также адаптироваться к новым ситуациям.

В дальнейшем планируется сосредоточиться на изучении более продвинутых техник самозадавания вопросов для дальнейшего повышения любознательности и обучаемости агента. Углубление этой способности позволит AgentEvolver не просто решать задачи, но и активно искать новые знания и оптимизировать стратегии.
Любопытство, как и свет, рассеивает тьму неведения, и только в постоянном стремлении к познанию рождается истинное понимание.
Представленная работа демонстрирует стремление к созданию автономных систем, способных к самосовершенствованию. В основе AgentEvolver лежит принцип генерации задач и оценки прогресса посредством больших языковых моделей. Это созвучно мысли Анри Пуанкаре: «Наука не состоит из цепи логических выводов, которые неизбежно ведут к новым открытиям; она состоит из предположений и обобщений, которые постоянно проверяются и пересматриваются». Самоэволюция, реализованная в AgentEvolver через механизмы само-вопрошания и само-оценки, является воплощением этого процесса непрерывной проверки и адаптации, что способствует повышению эффективности обучения и производительности агента. Акцент на эффективном обучении с меньшим количеством данных подчеркивает стремление к лаконичности и ясности, что соответствует философии упрощения сложных систем.
Что дальше?
Представленная работа, стремясь к саморазвитию агентов, неизбежно сталкивается с фундаментальной сложностью: оценкой собственной ценности. Механизмы само-генерации задач и само-оценки, хотя и демонстрируют улучшения, остаются подверженными цикличности и возможности застревания в локальных оптимумах. Простое увеличение масштаба языковой модели не решит эту проблему; необходимо более глубокое понимание метакогнитивных процессов и их формализация.
Истинный прогресс, вероятно, кроется не в усложнении архитектуры, а в её очищении. Настоящая эффективность не в способности агента выполнять больше задач, а в умении выбирать те, которые действительно имеют значение. Ключевым направлением представляется разработка принципов минимализма в обучении – выявление минимального набора операций и данных, необходимых для достижения конкретной цели. Сложность — это тщеславие; ясность — милосердие.
Перспективы включают в себя исследование методов, позволяющих агенту критически оценивать собственные результаты, отбрасывать бесполезные знания и адаптироваться к меняющимся условиям не только посредством обучения, но и посредством осознанного само-ограничения. Совершенство достигается не когда нечего добавить, а когда нечего убрать.
Оригинал статьи: https://arxiv.org/pdf/2511.10395.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовая обработка данных: новый подход к повышению точности моделей
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые прорывы: Хорошее, плохое и смешное
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
2025-11-15 01:16