Автор: Денис Аветисян
Представлена инновационная система, позволяющая агентам самостоятельно адаптировать и оптимизировать свою память для достижения лучших результатов в меняющихся условиях.
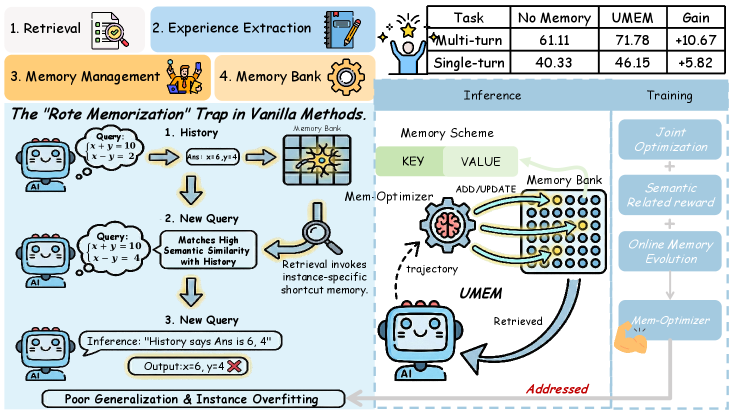
В статье описывается UMEM — фреймворк, совмещающий извлечение и управление памятью посредством семантического моделирования окрестностей и оптимизации на основе предельной полезности.
Существующие системы памяти для агентов на базе больших языковых моделей часто страдают от накопления специфических шумов, ограничивая их способность к обобщению. В данной работе представлена система ‘UMEM: Unified Memory Extraction and Management Framework for Generalizable Memory’ — новый подход, объединяющий извлечение и управление памятью в единый процесс оптимизации. Ключевым нововведением является моделирование семантического окружения и использование награды на основе предельной полезности для повышения обобщающей способности памяти. Позволит ли данная архитектура создать действительно самообучающихся агентов, способных эффективно адаптироваться к динамичным условиям и решать сложные задачи?
Ограничения Статической Памяти
Традиционные агенты, действующие в сложных средах, часто демонстрируют ограниченные возможности из-за негибкости их систем памяти. Вместо того, чтобы выделять и сохранять лишь значимую информацию, они, как правило, обрабатывают и сохраняют каждый опыт одинаково, вне зависимости от его важности для текущей или будущей задач. Этот подход приводит к перегрузке памяти нерелевантными деталями, затрудняя обобщение и адаптацию к новым ситуациям. Агент, перегруженный избыточной информацией, тратит ценные ресурсы на обработку незначительных деталей, что снижает его эффективность и способность к быстрому обучению. В результате, даже небольшие изменения в окружающей среде или входных данных могут вызвать значительные трудности в выполнении задач, требующих гибкости и способности к адаптации.
Неспособность к обобщению является существенным ограничением для традиционных интеллектуальных агентов, особенно при столкновении с новыми, ранее не встречавшимися ситуациями или незначительными изменениями входных данных. Вместо того чтобы выделять общие принципы и адаптировать накопленный опыт, такие системы склонны к запоминанию конкретных примеров, что приводит к их неэффективности при малейших отклонениях от заученного. Например, агент, обученный распознавать яблоки определенного сорта, может не идентифицировать яблоко другого сорта, несмотря на очевидное сходство. Это связано с тем, что он не способен экстраполировать знания и применять их к новым объектам или обстоятельствам, ограничивая его адаптивность и производительность в динамически меняющемся окружении.
Основная сложность в создании эффективных интеллектуальных систем заключается в умении отделить значимую, обобщаемую информацию от несущественных, контекстно-зависимых деталей. Подобно тому, как человеческий мозг фильтрует поступающие сигналы, выделяя ключевые аспекты опыта, искусственный интеллект должен научиться игнорировать “шум” — специфические особенности конкретной ситуации, не имеющие принципиального значения для решения более широкого круга задач. Неспособность к такой дифференциации приводит к перегрузке памяти бесполезными данными, снижает скорость обработки информации и, в конечном итоге, препятствует эффективной адаптации к новым условиям и обобщению полученного опыта. Разработка алгоритмов, способных динамически оценивать релевантность воспоминаний и отсеивать избыточную информацию, является ключевым шагом на пути к созданию действительно интеллектуальных систем.
Существующие подходы к организации памяти в интеллектуальных агентах зачастую не способны адаптироваться к изменяющимся требованиям задачи, что негативно сказывается на их эффективности в динамических средах. Традиционные системы рассматривают все полученные данные как равноценные, не выделяя критически важные элементы, необходимые для решения текущей задачи. Это приводит к перегрузке памяти избыточной информацией, затрудняет обобщение опыта и снижает способность агента к эффективному обучению и принятию решений в новых, незнакомых ситуациях. Отсутствие механизма динамической фильтрации и приоритизации данных приводит к тому, что агент тратит ресурсы на обработку нерелевантной информации, что особенно критично в условиях ограниченных вычислительных мощностей и необходимости быстрого реагирования на изменения окружающей среды.
UMEM: Архитектура Саморазвивающегося Агента
UMEM представляет собой новую архитектуру, основанную на концепции “Саморазвивающегося Агента”, способного к обучению и адаптации поведения во времени. В отличие от традиционных агентов с фиксированными параметрами, UMEM динамически изменяет свою стратегию действий, используя накопленный опыт для улучшения производительности. Это достигается за счет непрерывного процесса обучения и модификации внутренних параметров агента, что позволяет ему эффективно функционировать в меняющихся условиях и решать широкий спектр задач без необходимости ручного перепрограммирования. Ключевым аспектом является способность агента не только запоминать информацию, но и извлекать из нее полезные знания для оптимизации своего поведения.
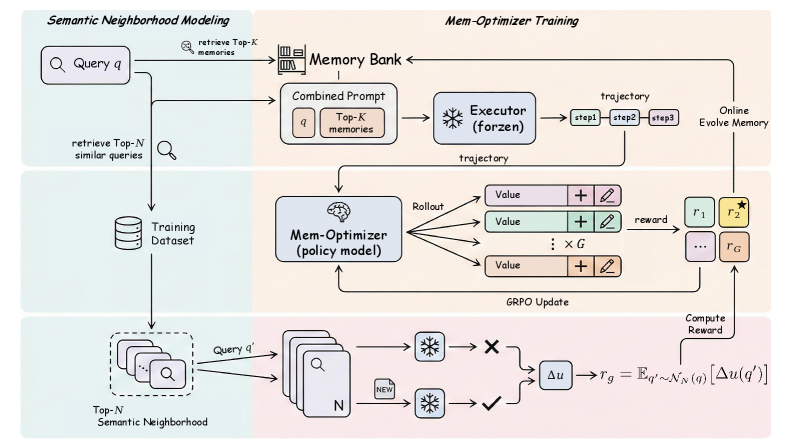
В основе архитектуры UMEM лежит “Банк Памяти” — набор обучаемых параметров, функционирующий как ассоциативная база данных. Этот банк хранит информацию в виде пар “запрос-воспоминание”, где “запрос” представляет собой входные данные или условия, а “воспоминание” — соответствующий ответ или действие. Обучаемые параметры позволяют системе изменять и уточнять связи между запросами и воспоминаниями в процессе обучения, обеспечивая адаптацию к новым задачам и данным. Каждая пара “запрос-воспоминание” представлена в виде векторов, что позволяет системе эффективно обрабатывать и сопоставлять различные типы данных, а также обобщать знания на основе схожих запросов.
Оптимизатор памяти (Mem-Optimizer) является ключевым компонентом архитектуры UMEM, обеспечивающим динамическую эволюцию банка памяти. Этот процесс включает два основных этапа: извлечение памяти (Memory Extraction) и управление памятью (Memory Management). Извлечение памяти подразумевает выявление и сохранение наиболее релевантных эпизодов опыта, формируя новые записи в банке памяти. Управление памятью, в свою очередь, включает в себя процессы отбора, обновления и удаления устаревших или неэффективных записей, оптимизируя банк памяти для повышения производительности и эффективности агента. Данные процессы осуществляются на основе критериев релевантности и полезности, определяемых в процессе обучения агента.
Исполнитель “Замороженного Агента” (Frozen Agent Executor) использует сформированную и структурированную базу памяти, созданную процессами извлечения и управления памятью. Этот компонент отвечает за непосредственное выполнение задач, опираясь на отобранные и оптимизированные данные из Memory Bank. В отличие от традиционных подходов, Executor не выполняет обучение или модификацию параметров в процессе работы — его задача заключается в эффективном извлечении релевантной информации из статической базы данных для достижения поставленной цели. Такая архитектура позволяет достичь высокой скорости и предсказуемости выполнения задач, поскольку Executor функционирует как детерминированная система, использующая предварительно сформированные знания.
Оптимизация Эволюции Памяти с GRPO
В качестве основного алгоритма обучения Mem-Optimizer используется ‘Group Relative Policy Optimization’ (GRPO). GRPO представляет собой алгоритм обучения с подкреплением, который оптимизирует политику агента путем оценки относительных преимуществ действий в контексте групп состояний. В отличие от традиционных методов, GRPO позволяет эффективно исследовать пространство параметров памяти, учитывая взаимосвязь между различными конфигурациями памяти и их влиянием на производительность. Это достигается за счет группировки схожих состояний и вычисления градиентов политики относительно этих групп, что снижает дисперсию и ускоряет процесс обучения. Применение GRPO обеспечивает стабильную сходимость и позволяет Mem-Optimizer адаптироваться к сложным задачам и динамически меняющимся условиям.
Алгоритм GRPO (Group Relative Policy Optimization) обеспечивает эффективное исследование пространства памяти и выявление оптимальных конфигураций за счет использования групповой относительной оптимизации политики. Вместо исследования всего пространства параметров памяти, GRPO фокусируется на относительном улучшении производительности в пределах определенных групп параметров, что значительно снижает вычислительные затраты и ускоряет процесс обучения. Алгоритм итеративно корректирует конфигурацию памяти, оценивая изменения в производительности на основе относительных улучшений внутри групп, что позволяет быстро находить конфигурации, обеспечивающие наилучшие результаты для поставленной задачи. Это особенно важно при работе с большими объемами памяти и сложными задачами, где полный перебор всех возможных конфигураций практически невозможен.
В процессе оптимизации используется награда на основе предельной полезности (Marginal Utility Reward), которая количественно оценивает прирост производительности в пределах семантического окружения. Это окружение представляет собой набор входных данных, близких по смыслу, для которых вычисляется изменение метрик производительности при модификации памяти. Награда рассчитывается как разница в производительности между текущей конфигурацией памяти и базовой, усредненная по этому семантическому окружению. Использование предельной полезности позволяет агенту фокусироваться на изменениях памяти, которые приносят наибольшую пользу в широком диапазоне семантически связанных входных данных, обеспечивая обобщающую способность и устойчивость к вариациям во входных данных.
Процесс “Онлайн-эволюции памяти” подразумевает, что агент обучается использовать динамически изменяющуюся систему памяти в процессе тренировки. В отличие от подходов, предполагающих предварительное определение и фиксированную структуру памяти, GRPO непрерывно адаптирует конфигурацию памяти на основе получаемых результатов. Это позволяет агенту не просто запоминать информацию, но и оптимизировать способ ее хранения и извлечения, что приводит к улучшению производительности по мере обучения и более эффективному использованию ресурсов памяти. Постоянная адаптация структуры памяти происходит параллельно с обучением основной задаче, формируя взаимосвязь между эффективностью памяти и общими результатами агента.
За Пределами Текущих Ограничений: Путь к Надежному ИИ
Динамическое управление памятью в системе UMEM значительно повышает способность к обобщению знаний между различными задачами, эффективно отсеивая специфический для конкретной ситуации «шум». В отличие от традиционных систем, которые хранят всю информацию, UMEM активно фильтрует данные, сохраняя только наиболее релевантные и общие паттерны. Этот подход позволяет агенту успешно адаптироваться к новым, ранее не встречавшимся задачам, поскольку он не перегружен избыточной информацией, характерной для конкретных ситуаций. Благодаря этому, система способна извлекать полезные знания из разнообразного опыта и применять их в новых контекстах, что критически важно для создания действительно интеллектуальных систем искусственного интеллекта, способных к гибкому и эффективному решению широкого круга задач.
Разработанный агент, использующий динамическое управление памятью, продемонстрировал впечатляющую способность к обучению и адаптации, достигнув 82.84% успешности на бенчмарке ALFWorld. Этот показатель сопоставим с результатами, демонстрируемыми передовой языковой моделью GPT-5.1, что свидетельствует о значительном прогрессе в области создания интеллектуальных систем. Способность агента эффективно отбирать и сохранять релевантную информацию позволяет ему успешно справляться со сложными задачами, требующими понимания контекста и планирования действий, что делает его перспективным решением для широкого спектра применений, включая автоматизацию бытовых задач и разработку виртуальных помощников.
Исследования демонстрируют, что разработанная система управления памятью UMEM значительно превосходит современные аналоги, такие как ReMem и Memp, по большинству ключевых бенчмарков. В ходе тестирования UMEM показала существенный прирост производительности, позволяя агентам эффективнее решать сложные задачи и адаптироваться к новым условиям. Преимущество системы заключается в её способности динамически оптимизировать использование памяти, отсеивая избыточную информацию и концентрируясь на наиболее релевантных данных, что приводит к более быстрому и точному выполнению заданий по сравнению с традиционными подходами к управлению памятью в системах искусственного интеллекта.
Исследования показали, что использование UMEM позволяет агентам демонстрировать значительно повышенную эффективность выполнения задач. В частности, агент, использующий UMEM, способен успешно завершить задачу в среднем за 13 шагов, в то время как базовый агент требует для этого 30 шагов. Данное сокращение вдвое необходимого количества действий подчеркивает существенное улучшение в оптимизации процесса принятия решений и более рациональное использование ресурсов. Такая эффективность не только ускоряет выполнение задачи, но и снижает вероятность ошибок, возникающих при большем количестве шагов, что делает UMEM перспективным решением для создания более надежных и продуктивных систем искусственного интеллекта.
Исследования демонстрируют, что система UMEM проявляет устойчивую самоэволюцию в процессе длительных взаимодействий, превосходя базовые методы по показателю суммарной успешности. В отличие от традиционных систем, которые со временем могут терять эффективность, UMEM способен адаптироваться и улучшать свои показатели в ходе работы, обеспечивая стабильно высокий уровень производительности. Данная способность к самообучению и оптимизации позволяет агенту не только успешно выполнять поставленные задачи, но и повышать свою эффективность с течением времени, что является ключевым фактором для создания действительно интеллектуальных и адаптивных систем искусственного интеллекта. Наблюдаемая устойчивость к деградации производительности на протяжении длительных взаимодействий подчеркивает потенциал UMEM для применения в сложных и динамичных средах, где требуется постоянная адаптация и оптимизация.
Представленный труд демонстрирует стремление к упрощению сложной задачи управления памятью в саморазвивающихся агентах. Разработанная система UMEM акцентирует внимание на совместной оптимизации извлечения и управления памятью, используя моделирование семантического соседства и награду на основе предельной полезности. Это позволяет агентам лучше адаптироваться к динамичным условиям и повышает их обобщающую способность. Как однажды заметил Дональд Дэвис: «Простота — это высшая степень изысканности». Данный подход к управлению памятью подтверждает эту мысль, поскольку стремится к элегантности и эффективности, избавляясь от ненужных усложнений в пользу ясности и функциональности.
Куда же дальше?
Представленная работа, как и любая попытка обуздать сложность, лишь обнажает новые грани нерешенных вопросов. Идея совместной оптимизации извлечения и управления памятью, безусловно, имеет элегантность, но её истинная ценность проявится в столкновении с действительно хаотичными, непредсказуемыми средами. Модель семантического соседства — полезный инструмент, но не панацея. Что, если “соседство” определяется не объективными характеристиками, а субъективными предпочтениями агента? Эта деталь требует дальнейшего осмысления.
Особенно важно преодолеть зависимость от метрики “предельной полезности”. Полезность — категория зыбкая, зависящая от контекста и времени. Попытки её формализации неизбежно приводят к упрощениям, искажающим реальность. Более того, вопрос о том, что вообще означает “успех” для саморазвивающегося агента, остается открытым. Нельзя ли разработать метрики, основанные не на достижении конкретных целей, а на способности к адаптации и самосохранению?
В конечном счете, настоящий прорыв потребует отказа от иллюзии контроля. Нельзя “управлять” эволюцией. Можно лишь создать условия, в которых она будет происходить наиболее эффективно. И, возможно, самое мудрое — это признать, что наша роль — не архитекторы разума, а лишь его скромные наблюдатели.
Оригинал статьи: https://arxiv.org/pdf/2602.10652.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Язык тела под присмотром ИИ: архитектура и гарантии
- Видео-Мыслитель: гармония разума и визуального потока.
- Квантовый Переворот: От Теории к Реальности
- Оптимизация квантовых схем: новый алгоритм для NISQ-устройств
- Плоские зоны: от теории к новым материалам
2026-02-12 22:11