Автор: Денис Аветисян
В статье представлена структурированная классификация интеллектуальных систем, работающих с данными, и описаны этапы их развития от простых задач до полной автоматизации.
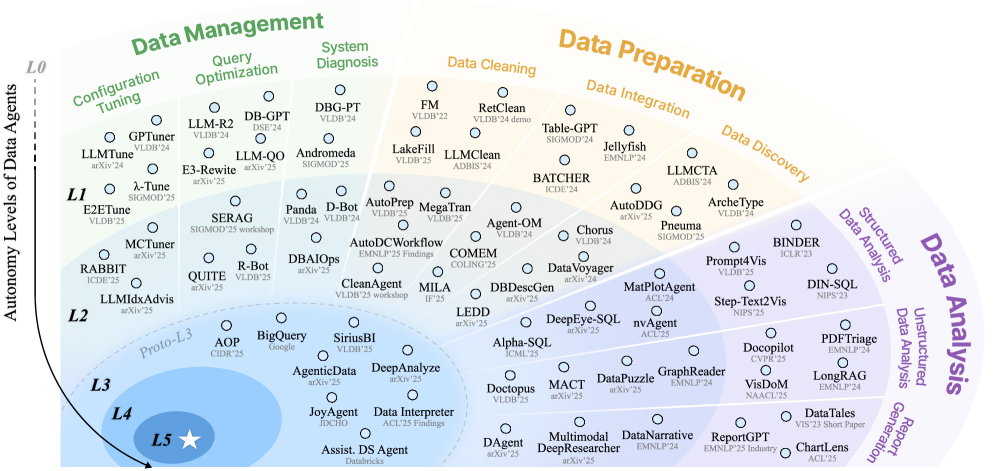
Предлагается иерархическая таксономия (L0-L5) для классификации агентов, работающих с данными, и анализ текущего состояния и нерешенных проблем в этой области.
Несмотря на растущий интерес к автоматизации задач управления данными, терминология и понимание возможностей систем, основанных на больших языковых моделях (LLM), остаются размытыми. В работе ‘Data Agents: Levels, State of the Art, and Open Problems’ предложена иерархическая таксономия “агентов данных” — от уровня 0 (L0, без автономии) до уровня 5 (L5, полная автономия) — для систематизации и оценки их возможностей на протяжении всего жизненного цикла данных. Эта классификация позволяет четко разграничить простые вспомогательные системы от по-настоящему автономных агентов, способных к комплексному анализу и управлению данными. Какие ключевые шаги необходимы для перехода от прототипов L3 к проактивным (L4) и генеративным (L5) агентам данных, способным самостоятельно решать сложные задачи в области анализа и управления данными?
От ручного труда к автономии: эволюция работы с данными
Исторически, работа с данными требовала значительных усилий и вмешательства человека на каждом этапе жизненного цикла данных. От сбора и очистки информации до её анализа и интерпретации, практически все операции выполнялись вручную. Это означало, что специалисты тратили огромное количество времени на рутинные задачи, что замедляло процесс принятия решений и ограничивало возможности масштабирования. Например, для подготовки отчетов требовалось вручную извлекать данные из различных источников, форматировать их и проверять на ошибки. Такой подход, хоть и обеспечивал контроль над качеством, был крайне неэффективным и требовал значительных трудовых ресурсов, что и послужило основой для поиска более автоматизированных решений в области обработки данных.
Исторически сложилось так, что обработка данных требовала значительных ручных усилий на каждом этапе жизненного цикла. Такой подход, представленный концепцией “агента L0”, характеризуется низкой эффективностью и неспособностью масштабироваться при увеличении объемов данных. По мере роста объемов информации и сложности задач, ручная обработка становится узким местом, приводя к задержкам, ошибкам и увеличению затрат. Необходимость автоматизации и уменьшения человеческого вмешательства становится критически важной для поддержания конкурентоспособности и извлечения максимальной пользы из данных, что и обуславливает развитие более совершенных агентов, способных к автономной работе.
В стремлении к оптимизации работы с данными и снижению влияния человеческого фактора, наблюдается активное развитие автономных агентов обработки информации. Данное исследование представляет собой иерархическую таксономию, охватывающую уровни от L0 до L5, предназначенную для оценки степени автономности этих агентов. Эта классификация позволяет систематизировать и анализировать возможности агентов в выполнении различных этапов жизненного цикла данных — от сбора и очистки до анализа и принятия решений. Разработка более совершенных агентов, способных самостоятельно решать сложные задачи, является ключевым направлением в современной обработке данных и открывает возможности для значительного повышения эффективности и масштабируемости систем.
Помощники и надзор: рождение агентов L1 и L2
Агент первого уровня (L1 Data Agent) представляет собой систему помощи, реализуемую посредством фреймворков, таких как “Prompt-Response”. Данные агенты функционируют, предоставляя пользователю предложения и рекомендации, основанные на анализе входных данных, однако не осуществляют непосредственного взаимодействия с внешней средой или выполнения каких-либо действий в ней. Основной принцип работы заключается в обработке запросов (prompts) и генерации соответствующих ответов (responses), что позволяет автоматизировать процесс поиска информации и формирования предложений, не требуя от системы физического воздействия на окружение. Таким образом, L1 агенты выступают в роли интеллектуальных помощников, облегчающих принятие решений и повышающих эффективность работы пользователя.
Агент L2, в отличие от L1, обладает способностью воспринимать окружающую среду и выполнять задачи, однако функционирует под постоянным контролем человека. Это означает, что L2 не только предоставляет предложения, как L1, но и активно взаимодействует с внешней средой, выполняя определенные действия. Важно отметить, что принятие решений и финальное подтверждение действий остаются за человеком, что обеспечивает контроль над процессом и предотвращает нежелательные последствия. Таким образом, L2 представляет собой шаг к большей автоматизации, сохраняя при этом человеческий надзор и ответственность.
Ранние поколения интеллектуальных агентов, такие как L1 и L2, представляют собой важный этап в развитии систем помощи, позволяя переложить выполнение рутинных задач и предоставить ценную информацию для анализа. Несмотря на способность L2 агентов к восприятию окружения и выполнению действий под контролем человека, оба типа агентов сохраняют зависимость от внешнего управления и не демонстрируют полной автономности в принятии решений или самостоятельном определении целей. В настоящий момент они функционируют как инструменты расширения возможностей человека, а не как полностью независимые системы.
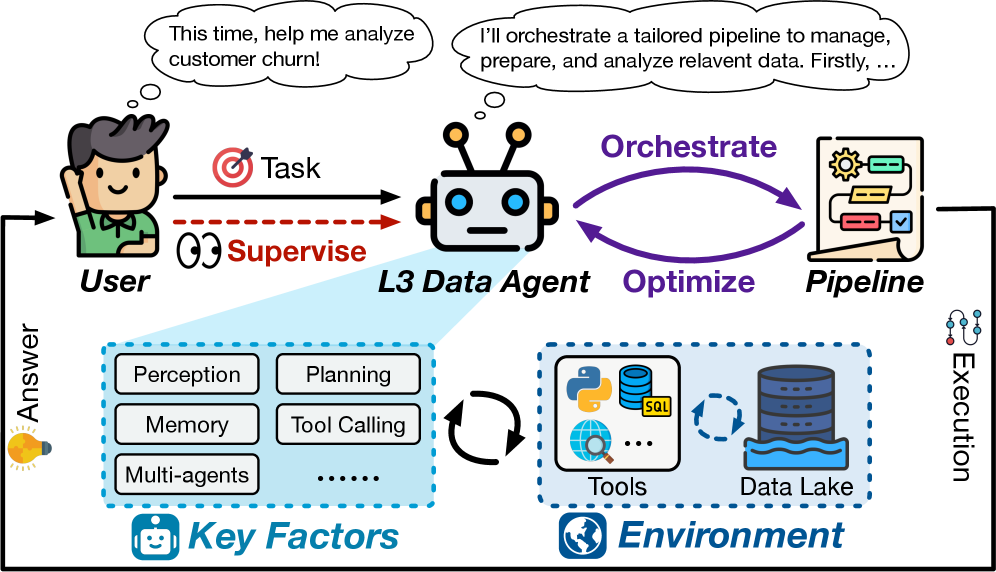
Оркестровка и автоматизация: агенты уровня 3 в действии
Агент данных уровня 3 (L3) представляет собой существенный шаг вперед в автоматизации обработки данных, обеспечивая автономное управление оркестровкой конвейеров данных (Pipeline Orchestration). В отличие от предыдущих уровней, L3 способен самостоятельно планировать и выполнять последовательность задач, необходимых для извлечения, преобразования и загрузки данных (ETL), при этом функционируя под контролем человека. Эта возможность позволяет существенно снизить операционные затраты и повысить скорость обработки данных, однако требует постоянного мониторинга со стороны специалиста для проверки корректности результатов и обработки непредвиденных ситуаций, возникающих в процессе работы конвейера.
Функциональность L3 Data Agent обеспечивается компонентами оркестратора на основе больших языковых моделей (LLM). Эти модели позволяют автономно планировать и выполнять последовательности операций с данными. Для реализации различных задач, таких как извлечение данных, преобразование и загрузка, используются готовые библиотеки инструментов (Tool Libraries), что значительно упрощает и ускоряет процесс оркестрации. Компоненты оркестратора используют LLM для динамического выбора и применения наиболее подходящих инструментов из этих библиотек в соответствии с конкретными требованиями задачи.
Агент данных уровня 3 (L3) требует постоянного контроля со стороны человека для проверки корректности полученных результатов и обработки непредвиденных ситуаций. Автоматизация, реализованная в L3, не исключает необходимости валидации данных и логики выполнения конвейера обработки. Человеческий надзор необходим для выявления ошибок, которые могут возникнуть из-за неполноты или неточности используемых инструментов, а также для адаптации к новым или изменяющимся требованиям к данным и бизнес-логике. Особенно важно вмешательство человека при обработке аномальных данных или в случаях, когда LLM-based Orchestrator сталкивается с задачами, выходящими за рамки его обученных возможностей.
Проактивный интеллект: уровни 4 и 5 и горизонты будущего
Агент уровня 4 выходит за рамки простой оркестровки данных, используя возможности обнаружения задач и долгосрочного планирования для проактивного мониторинга данных. Вместо пассивного реагирования на запросы, он самостоятельно выявляет потенциальные проблемы и возможности в динамично меняющихся экосистемах данных. Этот процесс включает в себя не только поиск известных аномалий, но и предвидение будущих потребностей, что достигается благодаря способности агента строить и оценивать планы на длительный период. По сути, агент L4 способен самостоятельно определить, какие данные нуждаются в анализе, какие задачи требуют решения и какие ресурсы необходимы для достижения оптимальных результатов, что значительно повышает эффективность и оперативность обработки информации.
Агент пятого уровня, или L5 Data Agent, представляет собой полностью автономного генеративного специалиста по данным, способного не просто анализировать существующую информацию, но и изобретать принципиально новые решения. В его основе лежат два ключевых механизма: причинно-следственное мышление и мета-рассуждения. Причинно-следственное мышление позволяет агенту не просто выявлять корреляции, а понимать истинные причины и следствия явлений, что необходимо для разработки эффективных стратегий. Мета-рассуждения, в свою очередь, позволяют агенту оценивать собственные процессы мышления, оптимизировать подходы к решению задач и даже разрабатывать новые алгоритмы анализа данных, превосходящие существующие. Такая способность к самообучению и генерации инноваций открывает перспективы для решения сложных проблем, требующих не только обработки больших объемов информации, но и творческого подхода.
Переход к агентам продвинутого уровня знаменует собой фундаментальный сдвиг парадигмы в области науки о данных. Если ранее автоматизация ограничивалась реакцией на существующие запросы и заранее определенные задачи, то теперь появляется возможность проактивного анализа и самостоятельного формирования решений. Эти агенты не просто выполняют инструкции, а способны самостоятельно выявлять закономерности, предвидеть будущие потребности и генерировать инновационные подходы к решению сложных проблем. Такой переход от реактивной автоматизации к проактивному интеллекту открывает принципиально новые горизонты для извлечения ценности из данных и позволяет перейти от пассивного наблюдения к активному формированию будущего.
Автономная экосистема: будущее науки о данных
Последовательное развитие от агента данных уровня L0 к L5 демонстрирует чёткую траекторию к созданию полностью автономных данных-экосистем. Изначально, агент L0 требует значительного ручного вмешательства для выполнения базовых задач, таких как сбор и первичная обработка информации. С каждым последующим уровнем — L1, L2, L3, L4 — агент приобретает всё большую способность к самообучению, автоматизации и генерации новых решений, минимизируя потребность в участии человека. В конечном итоге, агент данных уровня L5 способен самостоятельно определять цели, собирать релевантные данные, анализировать их, формулировать выводы и даже генерировать новые гипотезы, создавая замкнутый цикл интеллектуальной деятельности и обеспечивая непрерывное улучшение данных-экосистемы без внешнего контроля. Такая эволюция открывает перспективы для радикального ускорения научных открытий, оптимизации бизнес-процессов и создания принципиально новых сервисов, основанных на интеллектуальном анализе данных.
Архитектура данных агента выходит за рамки традиционных задач управления, подготовки и анализа данных, эволюционируя в самообучающийся и генеративный интеллект. В отличие от статических систем, новый подход предполагает способность агента не только обрабатывать информацию, но и самостоятельно выявлять закономерности, формулировать гипотезы и генерировать новые данные, расширяя возможности для исследований и инноваций. Такой агент способен адаптироваться к изменяющимся условиям, оптимизировать собственные алгоритмы и даже создавать собственные модели данных, что открывает перспективы для автоматизации сложных задач и получения глубоких, ранее недоступных знаний. Это не просто инструмент для обработки данных, а активный участник процесса познания, способный к самостоятельному обучению и генерации новых идей.
В данной работе представлена иерархическая таксономия агентов данных, охватывающая уровни от L0 до L5, что позволяет оценить и сопоставить степень автономности различных систем обработки информации. Данная классификация не просто структурирует существующие подходы, но и выявляет ключевые исследовательские задачи, необходимые для дальнейшего развития интеллектуальных агентов данных. Подобный подход открывает перспективы для получения принципиально новых знаний, ускорения инновационных процессов и коренной трансформации всей области науки о данных, позволяя системам самостоятельно адаптироваться, обучаться и генерировать ценные выводы без непосредственного вмешательства человека.
Изучение уровней автономности, предложенное в статье, неизбежно приводит к мысли о сложности контроля над системами, которые, по сути, пытаются самостоятельно управлять данными. Это напоминает попытки приручить хаос. Блез Паскаль однажды заметил: «Все великие проблемы заключаются в том, что для их решения требуется простота». Однако, в контексте Data Agents, простота ускользает. Каждый новый уровень автономности (L0-L5) добавляет слой абстракции, увеличивая вероятность непредсказуемых последствий. В итоге, система, стремящаяся к полной автономии, рискует стать сложнее, чем те данные, которыми она управляет. И это, как правило, закономерность.
Что дальше?
Предложенная иерархия агентов данных, от простого инструментария (L0) до полностью автономных систем (L5), выглядит элегантно на бумаге. Однако, как показывает опыт, любая абстракция умирает от продакшена. Заманчиво мечтать об агентах L5, самостоятельно управляющих полным жизненным циклом данных, но реальность, вероятно, окажется куда прозаичнее: бесконечной борьбой с краевыми случаями, неожиданными корреляциями и неизбежными ошибками в коде. Все, что можно задеплоить — однажды упадёт, и агенты данных не станут исключением.
Наиболее острыми остаются вопросы, связанные с верификацией и контролем. Как обеспечить, чтобы автономный агент, оптимизирующий процессы, не нарушил принципы конфиденциальности или не принял неверное решение, основанное на неполных данных? В контексте AI4DB особенно важно понимать, как эти агенты будут взаимодействовать с существующими системами управления базами данных, и не превратятся ли в очередной слой сложности, который будет тяжело поддерживать.
Вероятно, ближайшее будущее за гибридными подходами, где человек остается в цикле принятия решений, а агенты данных выступают в роли продвинутых ассистентов. Иронично, но самая революционная технология часто оказывается просто новым способом делегировать рутинные задачи. И это, пожалуй, неплохо. Даже идеальные диаграммы умирают, но умирают красиво.
Оригинал статьи: https://arxiv.org/pdf/2602.04261.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Охота на уязвимости: как большие языковые модели учатся на ошибках прошлого
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Многокритериальная оптимизация: взгляд на народные методы
- Ожившие скелеты: Редактируемая 4D-генерация объектов
2026-02-05 20:09