Автор: Денис Аветисян
Исследователи представили систему FAMOSE, которая автоматически находит и улучшает признаки для табличных данных, используя возможности больших языковых моделей.
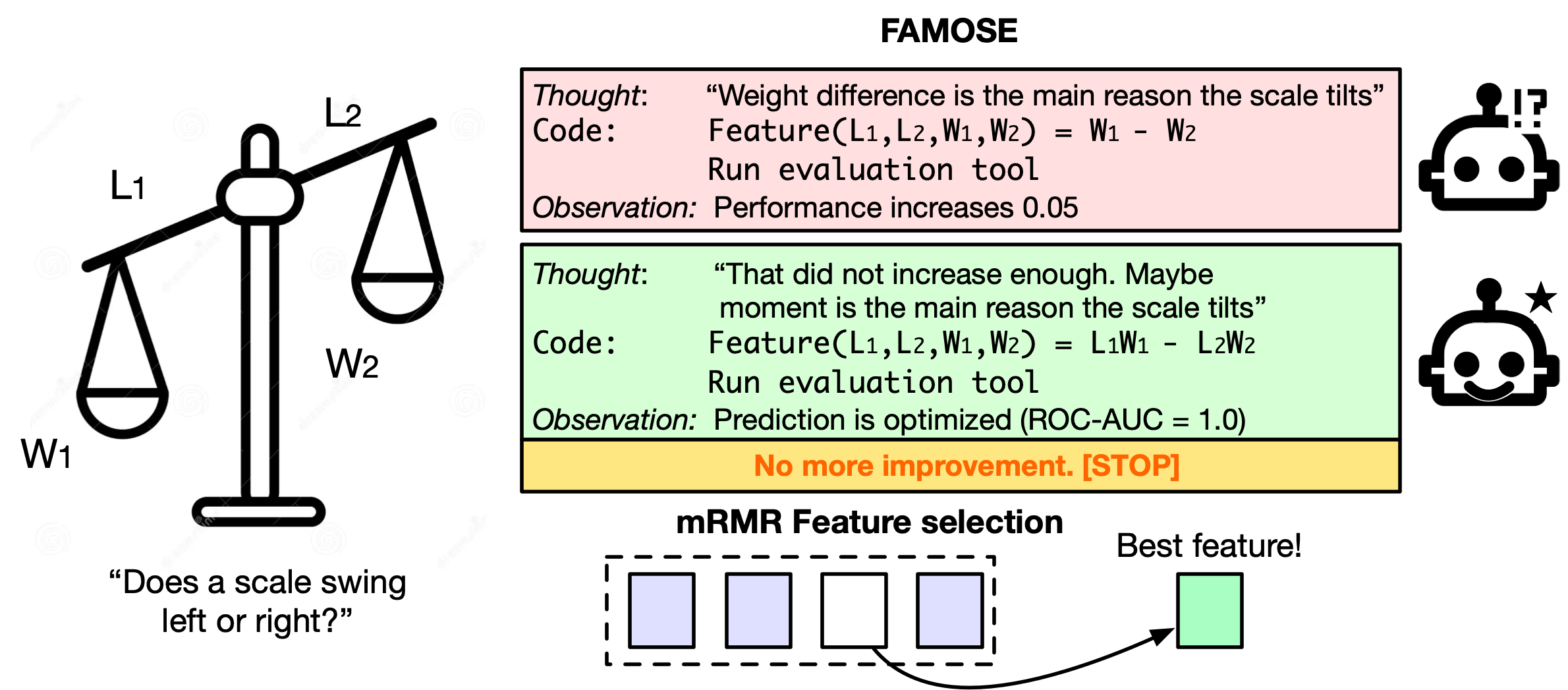
Предлагается ReAct-агент, позволяющий автономно открывать и оптимизировать признаки для повышения производительности и интерпретируемости моделей машинного обучения на табличных данных.
Автоматизированное извлечение и отбор признаков в машинном обучении, особенно для табличных данных, остается сложной задачей, требующей значительной экспертной подготовки. В данной работе представлена система ‘FAMOSE: A ReAct Approach to Automated Feature Discovery’, новый фреймворк, использующий парадигму ReAct для автономного исследования, генерации и улучшения признаков, объединяя отбор признаков и оценку в рамках агентской архитектуры. Эксперименты демонстрируют, что FAMOSE достигает передовых результатов в задачах классификации и регрессии, снижая среднеквадратичную ошибку (RMSE) на 2.0% в задачах регрессии, и превосходит существующие алгоритмы по устойчивости к ошибкам. Может ли агентский подход на основе ReAct стать ключом к созданию более интеллектуальных и адаптивных систем машинного обучения, способных самостоятельно решать сложные задачи инженерии признаков?
Ограничения ручного конструирования признаков
Традиционное машинное обучение с учителем в значительной степени зависит от качественной разработки признаков, процесса, требующего не только значительных временных затрат, но и глубоких знаний в предметной области. Эффективное извлечение и преобразование исходных данных в полезные признаки — критически важный этап, определяющий производительность и точность модели. Специалисты тратят большую часть своего времени на ручной отбор, масштабирование и комбинирование признаков, стремясь выявить наиболее релевантные сигналы в данных. Однако, этот процесс часто субъективен и подвержен ошибкам, что ограничивает возможности автоматического обучения и требует постоянной корректировки со стороны экспертов. Недостаточное внимание к разработке признаков может привести к снижению обобщающей способности модели и ухудшению её работы на новых, ранее не встречавшихся данных.
Ручное создание признаков, несмотря на свою распространенность, часто оказывается недостаточным для выявления сложных взаимосвязей, скрытых в данных. В результате, модели машинного обучения, построенные на таких признаках, демонстрируют ограниченную производительность и низкую способность к обобщению на новые, ранее не встречавшиеся данные. Это связано с тем, что человек, при создании признаков, неизбежно опирается на свои собственные представления и опыт, что может привести к упущению важных закономерностей или к созданию признаков, не отражающих истинную сложность исследуемого явления. Использование автоматизированных методов извлечения признаков и обучения представлений позволяет обойти эти ограничения, обнаруживая более тонкие и неявные зависимости в данных, что в свою очередь способствует повышению точности и надежности моделей.
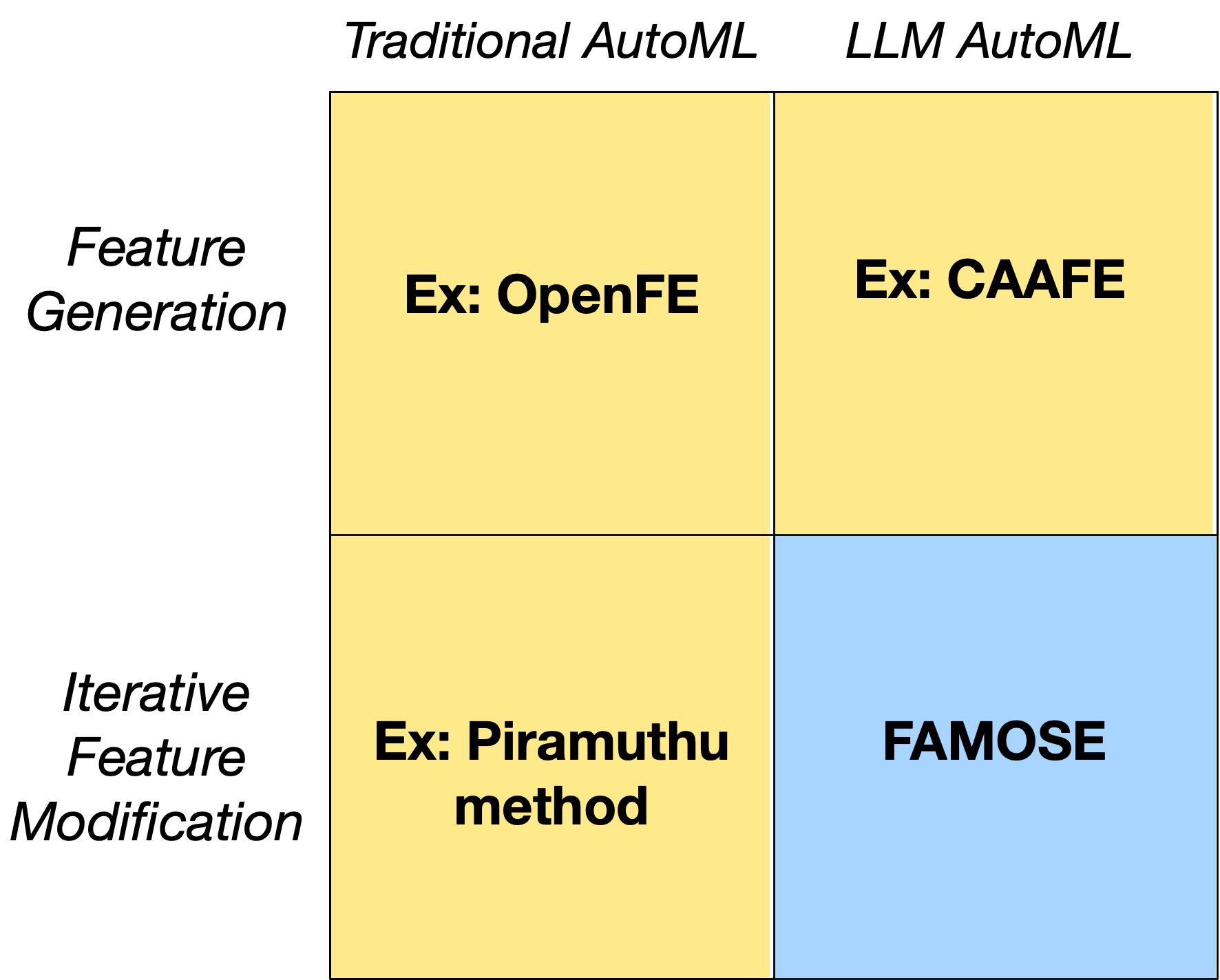
Автоматизация процесса конструирования признаков
Автоматизированное конструирование признаков (feature engineering) направлено на снижение нагрузки на специалистов по данным за счет систематического исследования и генерации потенциальных признаков для моделей машинного обучения. Этот процесс включает в себя автоматическое создание новых признаков из существующих данных, что позволяет расширить пространство поиска оптимальных признаков без необходимости ручного труда. Автоматизация позволяет быстро перебирать различные комбинации и преобразования данных, выявляя признаки, которые могут улучшить производительность моделей. В рамках автоматизированного конструирования признаков применяются различные методы, включая математические преобразования, агрегацию данных и создание взаимодействий между признаками, с целью повышения точности и эффективности моделей машинного обучения.
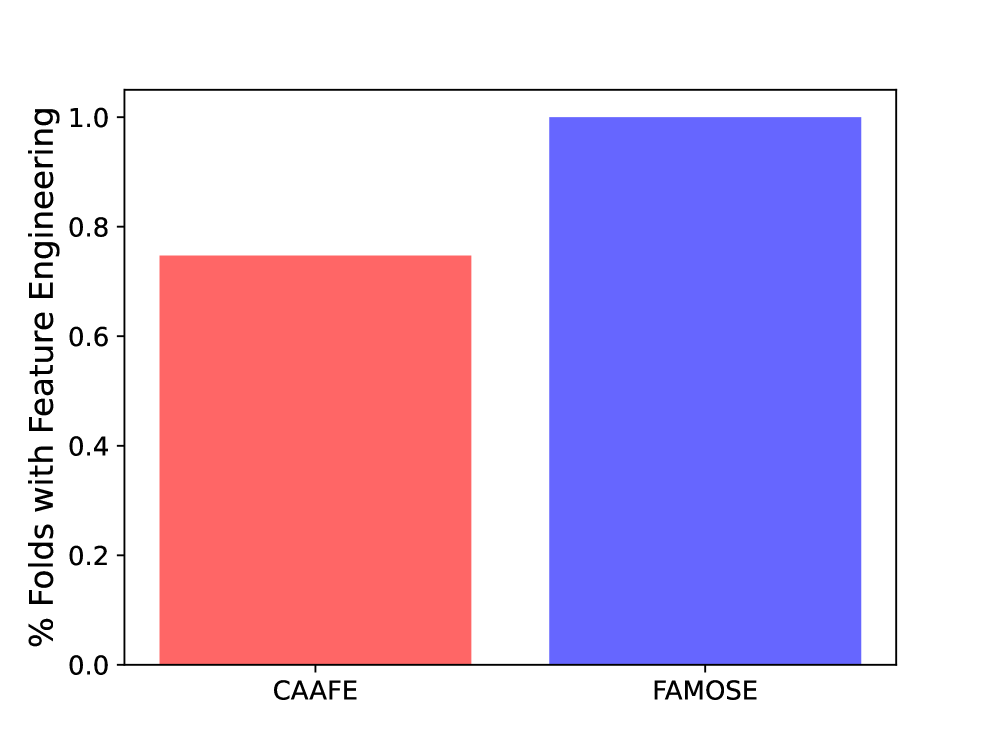
Существующие методы автоматизированного создания признаков, такие как OpenFE и CAAFE, используют алгоритмические подходы для систематического исследования и генерации потенциальных признаков. В последнее время наблюдается тенденция к интеграции больших языковых моделей (LLM) в эти системы. OpenFE, например, использует комбинацию алгоритмов трансформации признаков и поиска, в то время как CAAFE фокусируется на построении композитных признаков на основе заданных базовых признаков. LLM применяются для генерации новых признаков на основе семантического анализа данных и понимания контекста, что позволяет создавать более сложные и релевантные признаки, чем это возможно при использовании только традиционных алгоритмов.
Несмотря на развитие автоматизированных систем для создания признаков, они часто уступают опытным специалистам по данным в плане итеративной доработки и стратегического мышления. Автоматические системы, как правило, генерируют признаки на основе заданных алгоритмов или моделей, не обладая способностью к анализу результатов, выявлению нерелевантных признаков и целенаправленной модификации существующих для повышения эффективности модели. В отличие от специалиста, который может оценить влияние каждого признака на общую производительность и адаптировать процесс создания признаков в соответствии с полученными данными, автоматизированные системы ограничены заранее определенными правилами и параметрами, что снижает их гибкость и способность к оптимизации.
FAMOSE: Агент искусственного интеллекта для итеративного улучшения
FAMOSE использует архитектуру ReAct (Reason + Act), имитирующую процесс работы специалиста по машинному обучению при разработке признаков. В рамках этой архитектуры, агент попеременно выполняет этапы рассуждения (reasoning), где LLM (Large Language Model) анализирует текущее состояние данных и определяет необходимые действия, и действия (action), где агент выполняет эти действия, например, генерирует новые признаки или отбирает существующие. Этот цикл «рассуждение-действие» позволяет системе не только создавать новые признаки, но и адаптироваться к особенностям данных, а также корректировать стратегию генерации признаков на основе полученных результатов, что приближает процесс к человеческому подходу к feature engineering.
Система FAMOSE обеспечивает значительное повышение производительности в задачах классификации благодаря итеративной процедуре улучшения признаков. Данный процесс включает в себя генерацию новых признаков с использованием больших языковых моделей (LLM) и последующий отбор наиболее релевантных с помощью алгоритма mRMR (mutual information maximization with redundancy minimization). На тестовых наборах данных, содержащих более 10,000 экземпляров, FAMOSE демонстрирует среднее увеличение показателя ROC-AUC на 0.23% по сравнению с другими методами формирования признаков. Итеративный характер алгоритма позволяет последовательно улучшать качество признаков и, как следствие, повышать точность модели.
Для обеспечения качества и релевантности генерируемых признаков, в FAMOSE интегрированы механизмы коррекции галлюцинаций. Эти механизмы включают в себя проверку сгенерированных признаков на соответствие исходным данным и заданным ограничениям, а также фильтрацию нерелевантных или логически некорректных признаков. Процесс коррекции включает в себя использование LLM для переоценки и исправления признаков, которые демонстрируют признаки галлюцинаций — то есть, содержат информацию, не основанную на исходных данных. Кроме того, применяется оценка правдоподобия сгенерированных признаков, что позволяет отсеивать признаки с низкой степенью достоверности и минимизировать влияние галлюцинаций на итоговую модель.
Система FAMOSE улучшает имитацию процесса разработки признаков, свойственного специалистам по данным, за счет непрерывного итеративного уточнения. Этот процесс включает в себя последовательное генерирование новых признаков с использованием больших языковых моделей (LLM), последующий отбор наиболее релевантных признаков с помощью метода mRMR (mutual information maximization with redundancy reduction), и повторение этих шагов. Каждая итерация позволяет системе улучшать качество и информативность набора признаков, что приводит к повышению производительности модели на задачах классификации. Механизмы коррекции галлюцинаций, встроенные в систему, обеспечивают релевантность генерируемых признаков и предотвращают включение неинформативных или ошибочных данных в финальный набор.
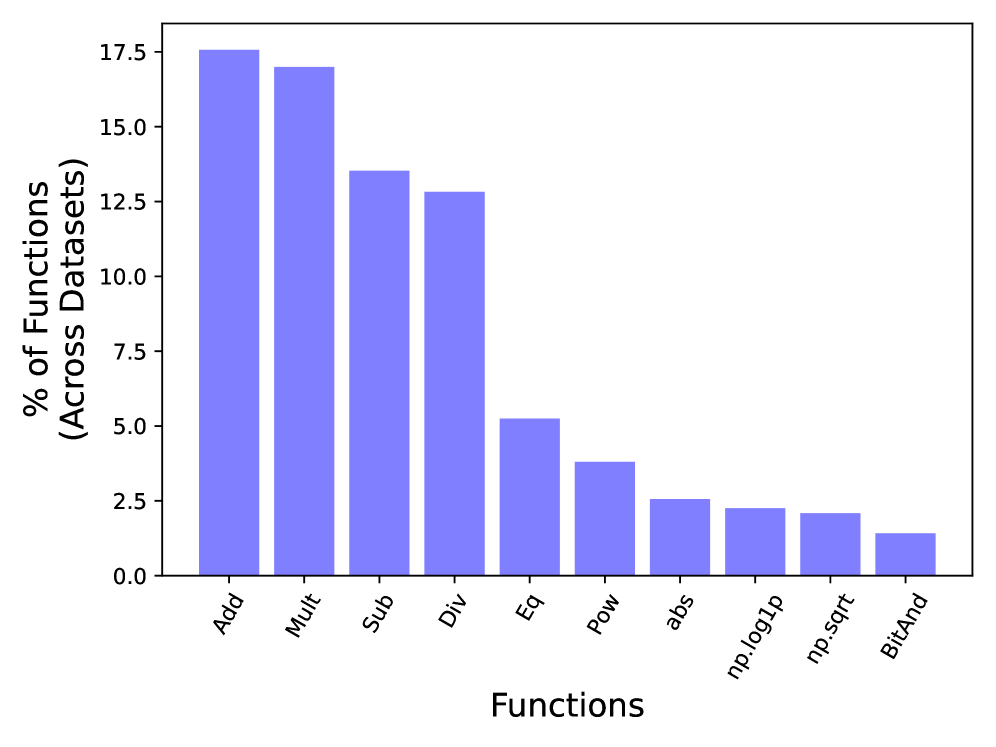
Превосходная производительность и широкая применимость
Эмпирические исследования демонстрируют, что FAMOSE превосходит существующие автоматизированные методы в задачах разработки признаков, достигая передового уровня производительности. В ходе экспериментов, система последовательно показывала лучшие результаты по сравнению с аналогичными инструментами, обеспечивая значительное улучшение качества моделей машинного обучения. Это превосходство обусловлено инновационным подходом к поиску и комбинированию признаков, позволяющим выявлять наиболее релевантные и информативные характеристики данных. Достигнутые показатели свидетельствуют о том, что FAMOSE может стать ключевым инструментом для автоматизации и оптимизации процесса разработки признаков, существенно повышая эффективность и точность моделей в различных областях применения.
Исследования показали, что разработанная система демонстрирует исключительную устойчивость к изменениям в данных и алгоритмах. В ходе экспериментов, фреймворк стабильно выдавал высокие результаты на разнообразных наборах данных, охватывающих различные области применения, от финансовых прогнозов до медицинских исследований. При этом, сохранялась высокая производительность вне зависимости от выбранного типа модели машинного обучения — будь то линейные регрессии, деревья решений или нейронные сети. Такая универсальность и надежность позволяют использовать систему в широком спектре задач, минимизируя необходимость в тонкой настройке и адаптации к конкретным условиям, что значительно упрощает процесс внедрения и обеспечивает предсказуемые результаты.
В ходе экспериментов, система FAMOSE продемонстрировала значительное улучшение точности прогнозирования в задачах регрессии. В частности, было зафиксировано снижение среднеквадратичной ошибки (RMSE) на 2,0% по сравнению с существующими методами автоматизированного конструирования признаков. Этот результат указывает на способность FAMOSE создавать более эффективные и релевантные признаки, что напрямую влияет на качество моделей, используемых для прогнозирования непрерывных значений. Уменьшение RMSE свидетельствует о более точных предсказаниях и, как следствие, о повышении надежности и полезности моделей, построенных с использованием FAMOSE.
В ходе тестирования на задаче с балансировкой весов, использующей упрощенную модель, основанную лишь на одном признаке, система FAMOSE продемонстрировала абсолютную точность, достигнув значения ROC-AUC, равного 1.0. Этот результат свидетельствует о способности алгоритма эффективно выделять наиболее значимый признак даже в условиях крайне ограниченного набора данных и упрощенной модели, что подчеркивает его высокую эффективность и потенциал для применения в задачах, требующих максимальной точности и интерпретируемости.
В основе FAMOSE лежит не только автоматическое создание признаков, но и обеспечение их интерпретируемости для пользователей. В отличие от многих “черных ящиков” в машинном обучении, FAMOSE предоставляет возможность понять логику, лежащую в основе сгенерированных признаков. Это достигается за счет использования прозрачных алгоритмов и предоставления пользователям информации о том, как именно каждый признак влияет на предсказания модели. Такой подход способствует повышению доверия к системе, поскольку пользователи могут убедиться в обоснованности полученных результатов и лучше понять взаимосвязи в данных. Прозрачность FAMOSE также облегчает отладку и оптимизацию моделей, позволяя специалистам выявлять и устранять потенциальные проблемы, связанные с использованием неинтерпретируемых признаков.
Автоматизируя критически важный этап конвейера машинного обучения — разработку признаков — FAMOSE открывает новые горизонты для инноваций, основанных на данных. Традиционно, этот процесс требовал значительных усилий экспертов в предметной области и специалистов по машинному обучению, что замедляло внедрение и ограничивало масштабируемость проектов. FAMOSE, освобождая от рутинной работы по ручному конструированию признаков, позволяет исследователям и практикам сосредоточиться на более сложных задачах, таких как выбор оптимальной модели и интерпретация результатов. Это, в свою очередь, ускоряет процесс разработки, снижает затраты и повышает эффективность использования данных, способствуя более широкому внедрению машинного обучения в различных областях — от финансов и здравоохранения до маркетинга и научных исследований.
Исследование FAMOSE демонстрирует стремление к упрощению сложного процесса разработки признаков в машинном обучении. Автоматизация этого этапа, как показано в статье, направлена на повышение производительности и интерпретируемости моделей. Кен Томпсон однажды заметил: «Вся сложность — это результат неудачных решений». Данное наблюдение перекликается с основной идеей FAMOSE — стремлением к элегантности и эффективности путем автоматического поиска и усовершенствования признаков, что позволяет избежать излишней сложности и создать более понятные и надежные модели для анализа табличных данных. Система, по сути, пытается найти оптимальный баланс между выразительностью и простотой.
Что дальше?
Представленный подход, хотя и демонстрирует впечатляющие результаты в автоматизированном конструировании признаков, обнажает фундаментальную сложность задачи. Иллюзия автоматизации часто маскирует необходимость в четком определении целей. Что есть «хороший» признак? Эффективность, измеряемая метрикой, или понятность, способствующая доверию к модели? Поиск баланса между этими, казалось бы, несовместимыми требованиями — задача, требующая не только вычислительной мощи, но и философского осмысления.
Очевидным направлением дальнейших исследований является расширение области применения. Табличные данные — лишь верхушка айсберга. Возможно ли адаптировать данную архитектуру для работы с неструктурированными данными — текстом, изображениями, звуком? Или, что более вероятно, необходимо признать, что универсального решения не существует, и каждое представление данных требует индивидуального подхода, основанного на глубоком понимании предметной области?
В конечном итоге, ценность FAMOSE не в автоматизации рутинных операций, а в стимулировании критического мышления. Подобные системы должны служить не заменой эксперту, а инструментом для расширения его возможностей, позволяющим сосредоточиться на действительно важных вопросах — формулировке проблемы и интерпретации результатов. Помните: простота — высшая форма сложности.
Оригинал статьи: https://arxiv.org/pdf/2602.17641.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Сердце музыки: открытые модели для создания композиций
- Квантовый скачок: от лаборатории к рынку
2026-02-22 22:51