Автор: Денис Аветисян
В статье рассматривается концепция интеграции интеллектуальных агентов в процесс разработки материалов для ускорения открытия инновационных и полезных веществ.

Ключевым подходом является создание сквозных конвейеров, объединяющих искусственный интеллект, курирование данных и экспериментальную обратную связь для автономного материаловедения.
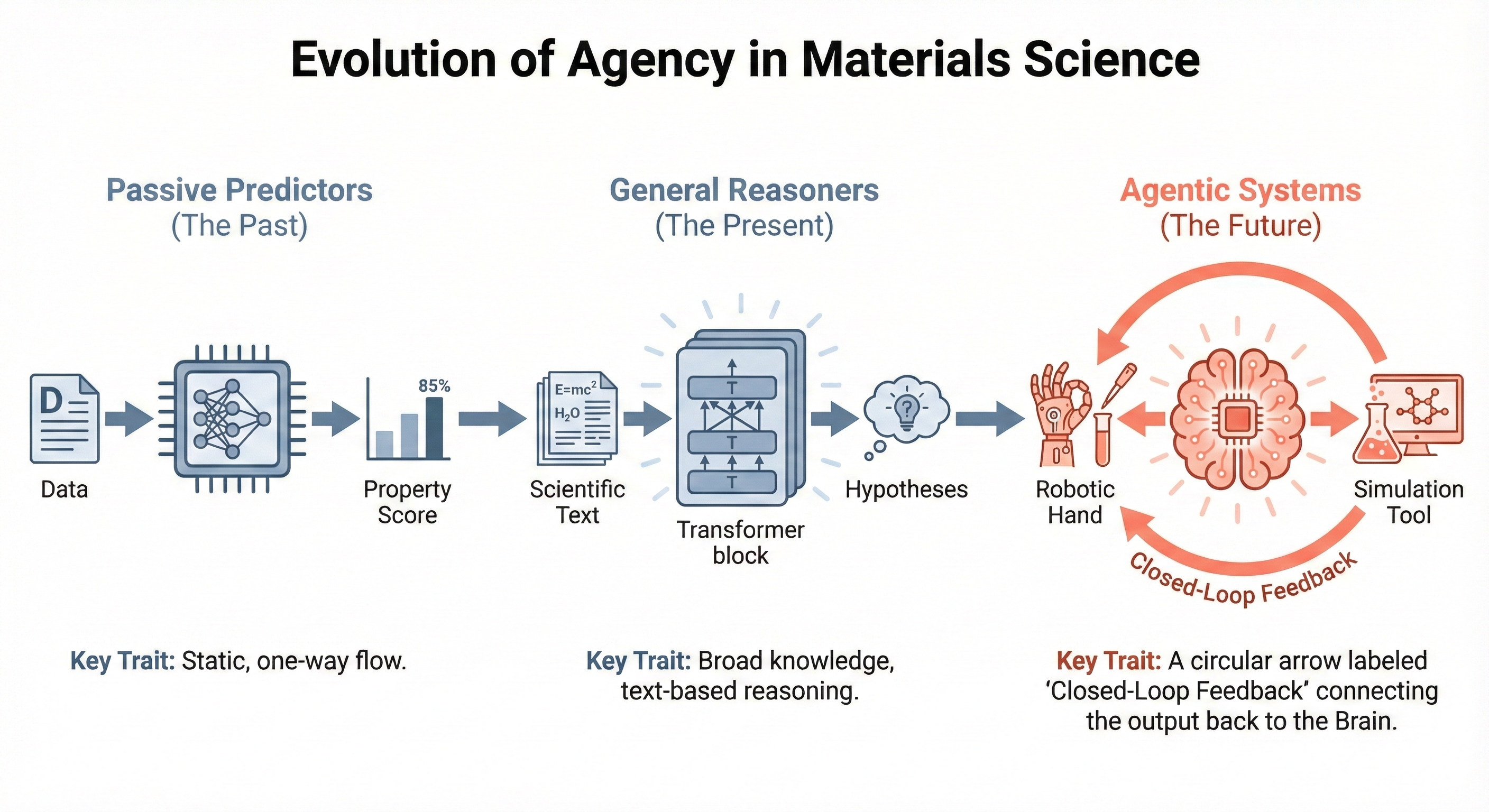
Несмотря на значительный прогресс в области искусственного интеллекта и материаловедения, ускорение открытия новых материалов требует перехода от изолированных задач к автономным системам. В настоящем обзоре, ‘Towards Agentic Intelligence for Materials Science’, предложена целостная концепция, рассматривающая весь цикл открытия материалов — от создания и предобработки данных до обучения и применения агентов, взаимодействующих с экспериментальными платформами. Ключевым результатом является акцент на создании сквозного конвейера, где выбор стратегии сбора данных и целей обучения напрямую влияет на успех экспериментов. Возможно ли создание действительно автономных интеллектуальных агентов, способных самостоятельно проектировать, синтезировать и характеризовать материалы с заданными свойствами, тем самым совершая революцию в материаловедении?
Преодоление Узких Мест Материаловедения: Необходимость Автономных Агентов
Традиционный поиск новых материалов характеризуется значительной медлительностью и высокими финансовыми затратами. Этот процесс в значительной степени опирается на интуицию и опыт исследователей, что делает его субъективным и ограничивает возможности для систематического исследования обширного химического пространства. Поиск оптимальных материалов часто напоминает иголку в стоге сена, требуя множества дорогостоящих экспериментов и длительных периодов анализа. Такой подход не позволяет в полной мере использовать потенциал материаловедения и замедляет темпы инноваций, поскольку большая часть перспективных соединений может оставаться неисследованной из-за ограниченности ресурсов и человеческих возможностей.
Огромное химическое пространство, включающее бесчисленное множество потенциальных материалов, представляет собой непреодолимую проблему для традиционных методов исследования. Ручной перебор комбинаций элементов и соединений, даже с использованием передовых вычислительных инструментов для предварительного отбора, ограничивает скорость открытия новых материалов с желаемыми свойствами. По сути, существующие подходы способны исследовать лишь ничтожную часть этого пространства, оставляя за пределами внимания бесчисленное количество перспективных соединений, которые могли бы привести к прорывам в различных областях науки и техники. Это связано не только с огромным количеством возможных комбинаций, но и с необходимостью проведения трудоемких и дорогостоящих экспериментов для подтверждения теоретических предсказаний, что делает систематическое исследование всего химического пространства практически невозможным.
Необходим принципиальный сдвиг в материаловедении: от исследований, основанных на предположениях, к автономным экспериментам и анализу данных. Традиционный подход, где ученые выдвигают гипотезы и затем проверяют их в лабораторных условиях, существенно ограничивает скорость открытия новых материалов. Автономные системы, способные самостоятельно планировать эксперименты, собирать и анализировать данные, открывают возможность исследовать в разы большее химическое пространство. Потенциальное увеличение объема экспериментального поиска до десятикратного, по сравнению с традиционными методами, позволяет надеяться на ускорение инноваций и создание материалов с уникальными свойствами, что особенно важно для развития передовых технологий.
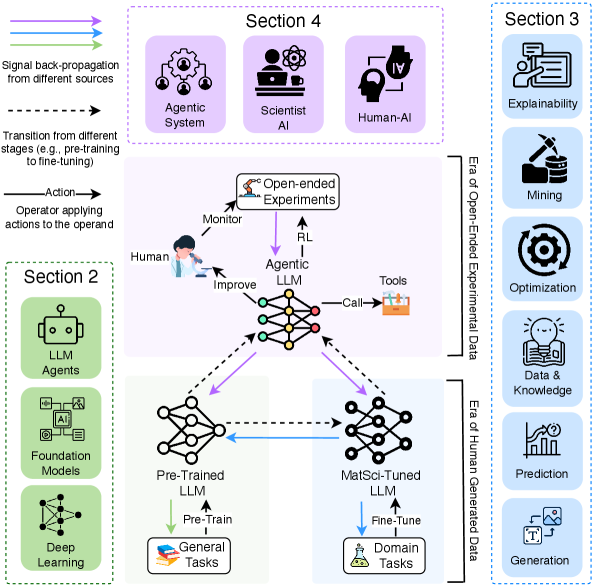
Агентные Большие Языковые Модели: Основа Автономной Материаловедческой Работы
Агентные большие языковые модели (LLM) представляют собой систему, способную самостоятельно планировать и проводить эксперименты в области материаловедения, имитируя деятельность ученого-исследователя. Они используют возможности LLM для анализа существующих данных, формулирования гипотез, разработки экспериментальных процедур, интерпретации результатов и итеративного улучшения стратегии исследования. В отличие от традиционных автоматизированных систем, агентные LLM обладают способностью к абстрактному мышлению и адаптации, позволяя им решать сложные задачи и находить новые решения без непосредственного вмешательства человека. Эта автономность достигается за счет интеграции LLM с инструментами для моделирования, симуляции и управления лабораторным оборудованием.
Для эффективного обучения агентов, использующих большие языковые модели (LLM) в материаловедении, необходимо адаптировать предварительно обученные модели посредством Domain Adaptation и последующей тонкой настройки с использованием Instruction Tuning. Domain Adaptation позволяет LLM освоить специфическую терминологию, форматы данных и принципы, характерные для материаловедения, что повышает релевантность генерируемых ответов и предложений. Instruction Tuning, в свою очередь, предполагает обучение модели на размеченных данных, состоящих из инструкций и соответствующих действий, необходимых для выполнения конкретных задач, таких как планирование экспериментов или анализ результатов. Комбинация этих двух подходов позволяет значительно улучшить производительность LLM в контексте материаловедения, обеспечивая более точные и надежные результаты.
Обучение с подкреплением (Reinforcement Learning) играет ключевую роль в управлении действиями агента, основанного на больших языковых моделях, в контексте материаловедения. Эффективное применение требует разработки структуры вознаграждений, стимулирующей успешное выполнение экспериментальных задач, таких как синтез материалов с заданными свойствами или оптимизация параметров процесса. Структура вознаграждений должна учитывать не только конечный результат эксперимента, но и промежуточные шаги, способствуя более эффективному поиску оптимальных решений. Использование обучения с подкреплением также необходимо для улучшения согласованности (alignment) моделей ИИ с реальными результатами экспериментов, учитывая неизбежные погрешности и неопределенности, присущие физическим процессам и измерительным приборам.
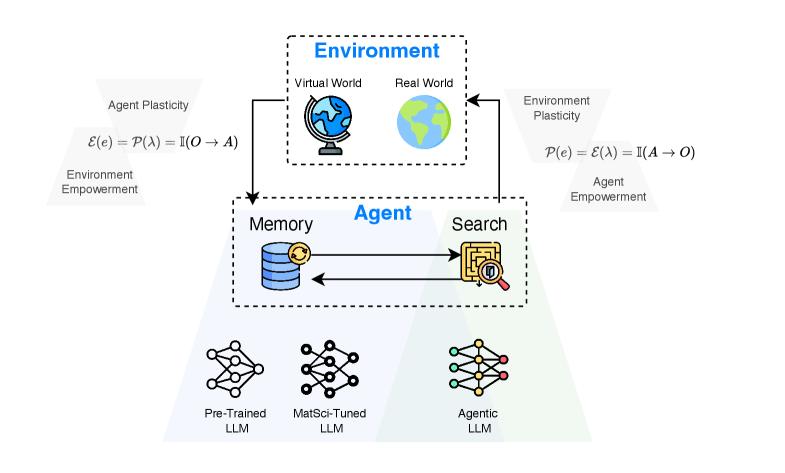
Виртуальная Валидация и Реальное Развертывание: Двухсторонний Подход
Виртуальная среда (VirtualEnvironment), при потенциальном усилении технологией DigitalTwin, предоставляет безопасную и экономически эффективную платформу для первоначального обучения и тестирования агентов. Использование симуляций позволяет проводить большое количество итераций обучения без риска повреждения оборудования или возникновения опасных ситуаций, характерных для реальных экспериментов. DigitalTwin, являясь цифровой репликой физической системы, обеспечивает повышенную точность симуляций, что способствует более эффективной передаче знаний из виртуальной среды в реальный мир. Это снижает потребность в дорогостоящих физических прототипах и позволяет сократить время разработки и внедрения.
Эксперименты в реальном мире необходимы для подтверждения работоспособности агента в физической среде. Полученные в ходе этих экспериментов данные используются для дальнейшей оптимизации его способностей и позволяют существенно снизить затраты на проведение испытаний за счет интеграции с симуляционным окружением. Комбинирование реальных данных с результатами моделирования позволяет создать более точную и эффективную систему обучения, минимизируя необходимость в дорогостоящих и ресурсоемких физических испытаниях. Данный подход обеспечивает более быструю итерацию разработки и повышает надежность агента при развертывании в реальных условиях.
Функция вознаграждения (RewardFunction) является ключевым компонентом обучения агента, определяя количественную оценку успешности его действий в ходе экспериментов. Механизм кредитного назначения (CreditAssignment) позволяет установить связь между конкретными действиями агента и полученным вознаграждением, выявляя, какие действия привели к успешному результату. Этот процесс позволяет агенту итеративно улучшать свою стратегию, оптимизируя поведение для максимизации вознаграждения. Эффективное кредитное назначение существенно повышает эффективность использования данных, сокращая количество необходимых экспериментов для достижения требуемого уровня производительности агента.
Обучение на Данных: Активное Обучение и Курирование для Оптимальной Производительности
Активное обучение (ActiveLearning) представляет собой метод, при котором алгоритм самостоятельно выбирает наиболее информативные данные для ручной разметки. Вместо случайного выбора или разметки всего объема данных, система анализирует неразмеченные данные и определяет те образцы, которые при разметке наиболее эффективно улучшат производительность модели. Это позволяет значительно снизить затраты на ручную аннотацию, поскольку требуется разметить лишь небольшую часть данных для достижения необходимого уровня точности. Эффективность активного обучения обусловлена тем, что алгоритм фокусируется на данных, которые вносят наибольший вклад в снижение неопределенности модели и улучшение ее обобщающей способности.
Надёжная политика курирования данных (DataCurationPolicy) является критически важной для обеспечения качества и согласованности данных, используемых в процессе обучения агента. Эта политика включает в себя процедуры проверки данных на наличие ошибок, пропусков и противоречий, а также стандартизацию форматов и единиц измерения. Особое внимание уделяется выявлению и устранению систематических искажений (bias), которые могут возникнуть из-за нерепрезентативной выборки данных, ошибок измерения или предвзятости при аннотации. Внедрение DataCurationPolicy позволяет минимизировать влияние некачественных данных на процесс обучения, повышая точность, надёжность и обобщающую способность модели.
Использование многомодальных данных, включающих текстовую информацию, изображения и числовые данные, существенно улучшает процесс RepresentationLearning — обучение представлений. Это позволяет агенту извлекать более глубокие и полные знания из сложных наборов данных о материалах. Комбинирование различных типов данных обеспечивает более полное описание свойств материала, чем использование только одного типа информации. Например, текстовые описания химического состава могут быть дополнены изображениями микроструктуры и числовыми данными о механических свойствах, что позволяет агенту установить более сложные корреляции и улучшить точность прогнозирования.
Безопасная и Прозрачная Автоматизация: Будущее Материаловедческих Инноваций
Принципы SafeAI обеспечивают функционирование агентных больших языковых моделей (LLM) в четко определенных границах, предотвращая нежелательные последствия. Данный подход подразумевает создание системы ограничений и проверок, которые не позволяют модели выходить за рамки установленных протоколов и безопасных действий. В частности, используются механизмы, отслеживающие и ограничивающие доступ модели к критически важным ресурсам и данным, а также контролирующие ее выходные данные на предмет соответствия заданным критериям безопасности. Это позволяет избежать ситуаций, когда модель, действуя автономно, может совершить действия, противоречащие поставленным задачам или несущие потенциальный риск. В результате, разработчики получают возможность эффективно управлять автономностью LLM, обеспечивая ее надежную и предсказуемую работу в различных областях применения.
Технологии Объяснимого Искусственного Интеллекта (ExplainableAI) предоставляют возможность детального анализа логики, лежащей в основе решений, принимаемых автономными агентами. Вместо «черного ящика», исследователи и инженеры получают доступ к информации о том, какие факторы и данные повлияли на конкретный выбор, что критически важно для установления доверия к системе. Такой подход позволяет не только верифицировать корректность работы агента, но и выявлять потенциальные предубеждения или ошибки в его рассуждениях. Более того, прозрачность процесса принятия решений обеспечивает возможность своевременного вмешательства человека, позволяя корректировать действия агента в сложных или неопределенных ситуациях, и, таким образом, гарантировать соответствие результатов поставленным целям и этическим нормам.
Сочетание автономности, безопасности и прозрачности открывает новую эру в ускоренном открытии материалов, стимулируя инновации в различных областях науки и техники. Интеграция интеллектуальных агентов, функционирующих в рамках четко определенных границ, позволяет значительно расширить пространство экспериментальных исследований. По предварительным оценкам, внедрение данной методологии может увеличить потенциальное пространство поиска новых материалов до десяти раз, что дает возможность исследовать комбинации и составы, ранее недоступные из-за ограничений времени и ресурсов. Это, в свою очередь, ведет к более быстрому созданию материалов с заданными свойствами, необходимых для прогресса в энергетике, медицине, и других критически важных сферах.
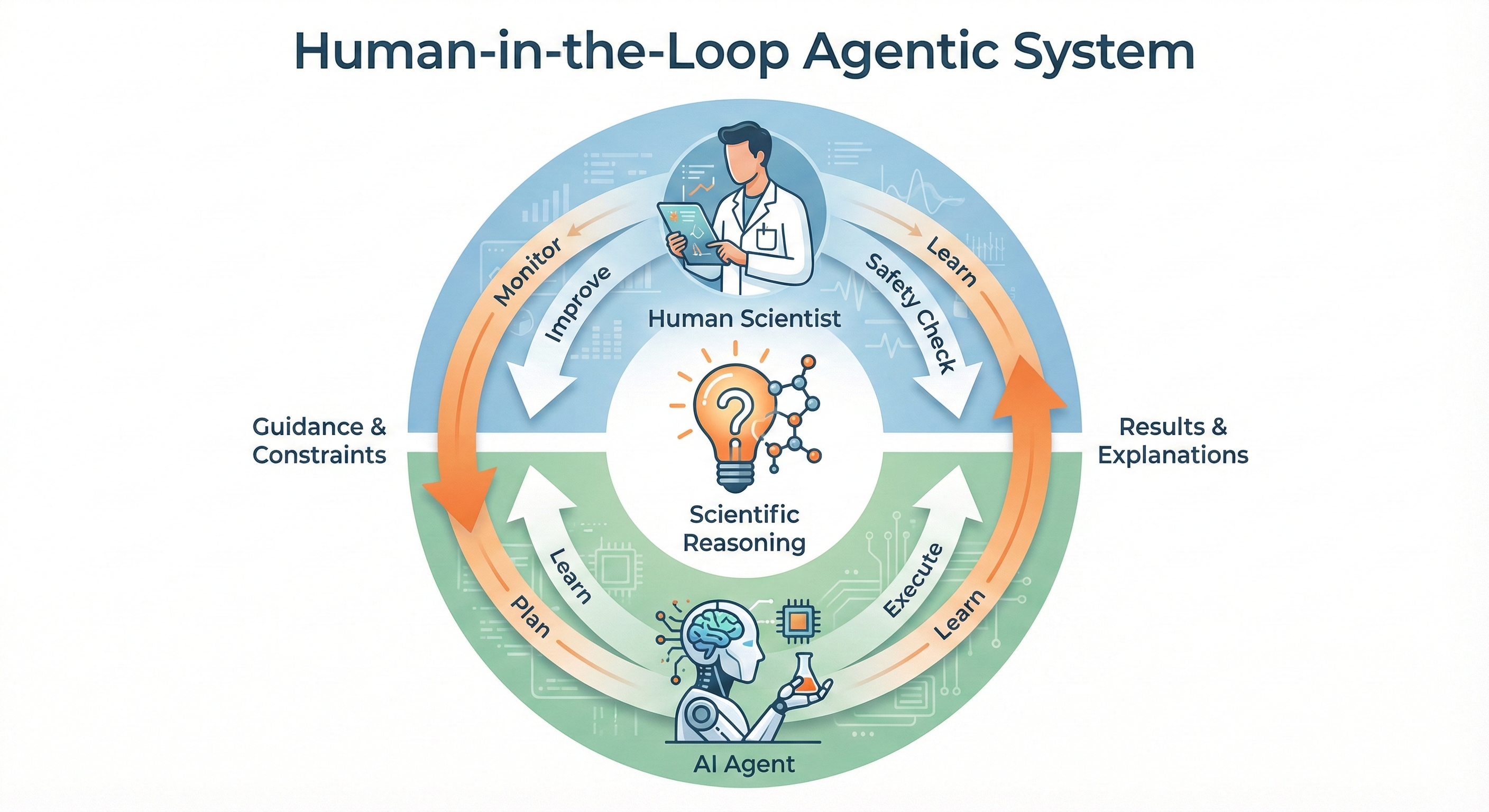
Без точного определения задачи любое решение — шум. Данная работа подчеркивает необходимость перехода к конвейерному подходу в материаловедении, где агенты искусственного интеллекта последовательно выполняют задачи, начиная от курации данных и заканчивая экспериментальной проверкой. В этом контексте особенно актуальна мысль Карла Сагана: «Мы — звездная пыль, осознающая себя». Эта фраза напоминает о фундаментальной связи между наблюдением, анализом и стремлением к пониманию, что является ключевым для успешного применения агентов ИИ в материаловедении и, в конечном счете, для открытия новых материалов с заданными свойствами. Точность определения целей и логическая последовательность действий — залог достоверных результатов.
Куда Ведет Этот Путь?
Представленная работа, хотя и демонстрирует потенциал агентов, управляемых большими языковыми моделями, в материаловедении, лишь слегка приоткрывает дверь в область истинной автономности. Необходимо признать, что сама концепция «агента» требует более строгого математического определения. Достаточно ли текущих методов обучения с подкреплением для обеспечения не просто работоспособности, но и доказанной корректности алгоритмов поиска новых материалов? Настоящая сложность не в объеме кода, а в масштабируемости и асимптотической устойчивости предлагаемых решений.
Особое внимание следует уделить проблеме курации данных. Автоматическая фильтрация и валидация экспериментальных результатов — задача, требующая не просто статистических методов, но и глубокого понимания физических принципов. Иначе, мы рискуем построить элегантный алгоритм на фундаменте неверных данных, что равносильно математической ошибке.
Будущие исследования должны быть направлены на разработку формальных методов верификации агентов, а также на создание самообучающихся систем, способных самостоятельно выявлять и исправлять ошибки в своих знаниях. Истинный прогресс в области научного искусственного интеллекта будет достигнут не тогда, когда алгоритмы начнут «работать», а когда их корректность будет доказана математически.
Оригинал статьи: https://arxiv.org/pdf/2602.00169.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Кванты в Финансах: Не Шутка!
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Квантовый скачок из Андхра-Прадеш: что это значит?
- Квантовый алгоритм для оптимального размещения антенн
- Искусственный интеллект на допросе: как объяснить решения в цифровой криминалистике?
- Виртуальные миры под контролем: новая оценка реалистичности симуляций
2026-02-03 09:22