Автор: Денис Аветисян
Исследователи представили систему, способную самостоятельно разрабатывать и совершенствовать программный код для графических процессоров, значительно повышая их производительность.
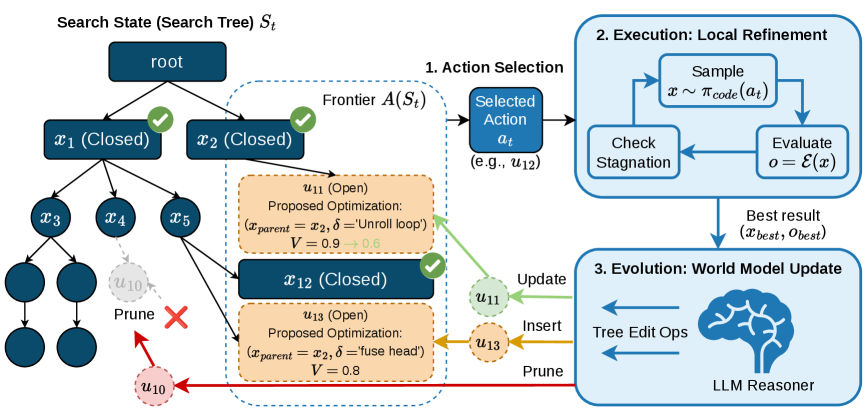
K-Search — фреймворк, использующий совместно развивающуюся внутреннюю модель мира и LLM-управляемый поиск для автономного планирования и оптимизации GPU-ядер.
Оптимизация GPU-ядер является критически важной задачей для современных систем машинного обучения, но традиционные подходы часто сталкиваются с ограничениями из-за сложности проектирования и быстрого развития аппаратного обеспечения. В данной работе, представленной под названием ‘K-Search: LLM Kernel Generation via Co-Evolving Intrinsic World Model’, предлагается новый фреймворк K-Search, использующий совместно развивающуюся внутреннюю модель мира на основе больших языковых моделей (LLM) для автономного планирования и оптимизации GPU-ядер. Эксперименты показали, что K-Search значительно превосходит существующие эволюционные методы поиска, достигая в среднем 2.10x прироста производительности, а для сложных MoE-ядер — до 14.3x. Сможет ли предложенный подход стать основой для автоматического создания высокопроизводительного кода для будущих поколений графических ускорителей?
Традиционные Ограничения: Почему Оптимизация Ядер Заходит в Тупик
Традиционная оптимизация ядер GPU, как правило, опирается на ручную настройку параметров или метод перебора по сетке, что требует значительных вычислительных ресурсов и времени. Этот подход становится особенно неэффективным при работе со сложными пространствами параметров, где количество возможных конфигураций экспоненциально возрастает. Ручная настройка требует глубоких знаний архитектуры GPU и специфики конкретного ядра, а перебор по сетке, даже при использовании параллельных вычислений, не может эффективно исследовать все возможные комбинации, особенно когда параметры взаимодействуют нелинейно. В результате, достижение оптимальной производительности становится сложной и трудоемкой задачей, ограничивающей потенциал современных графических ускорителей.
Традиционные методы оптимизации ядра графического процессора зачастую оказываются неэффективными при внедрении нового аппаратного обеспечения или появлении передовых алгоритмов. Это связано с тем, что ручная настройка или даже систематический перебор вариантов не способны оперативно адаптироваться к изменяющимся условиям. По мере усложнения архитектуры GPU и развития вычислительных техник, ограничения этих подходов становятся все более заметными, что препятствует достижению максимальной производительности. Новые аппаратные решения и алгоритмические инновации требуют более гибкого и интеллектуального подхода к оптимизации, который способен быстро реагировать на изменения и эффективно использовать потенциал современных технологий. В результате, существующие методы часто не позволяют в полной мере реализовать преимущества новых разработок, создавая своего рода «узкое место» в процессе повышения производительности.
По мере усложнения архитектур графических процессоров и алгоритмов, ручная настройка ядра становится непосильной задачей, требующей огромных вычислительных ресурсов и времени. Автоматизированные и интеллектуальные стратегии поиска конфигураций, способные адаптироваться к новым аппаратным решениям и оптимизировать производительность в реальном времени, становятся не просто желательными, а критически необходимыми для достижения максимальной эффективности GPU. Такие методы позволяют исследовать гораздо более широкое пространство параметров, выявляя оптимальные настройки, которые остаются недоступными при традиционных подходах, и открывают путь к значительному увеличению скорости вычислений и энергоэффективности.

Эволюция Оптимизации: Новый Взгляд на Проектирование Ядер
FunSearch представил принципиально новый подход к генерации кода, объединив большую языковую модель (LLM) с функцией оценки (evaluator). Этот тандем формирует итеративный цикл улучшения: LLM генерирует фрагменты кода, evaluator оценивает их производительность или соответствие заданным критериям, а результаты оценки используются для корректировки процесса генерации. В отличие от традиционных методов, FunSearch не требует предварительно заданных шаблонов или экспертных знаний для создания эффективного кода, что позволяет автоматизировать процесс оптимизации и находить нетривиальные решения, которые сложно получить иными способами. Этот метод доказал свою эффективность в поиске новых алгоритмов и оптимизации существующих.
AlphaEvolve расширяет концепцию, представленную в FunSearch, позволяя использовать большие языковые модели (LLM) для внесения изменений непосредственно в существующие кодовые базы. В отличие от генерации кода с нуля, AlphaEvolve фокусируется на эволюционном подходе, где LLM выступает в роли агента, модифицирующего и улучшающего существующий код. Этот подход обеспечивает более существенные и целенаправленные изменения, поскольку LLM работает в контексте уже функционирующего решения, что позволяет ему оптимизировать и расширять функциональность, а не создавать её с нуля. Такой метод позволяет применять LLM к более сложным задачам, требующим глубокого понимания существующей кодовой базы и её взаимодействий.
OpenEvolve представляет собой реализацию с открытым исходным кодом, позволяющую применять эволюционные стратегии к кодовым базам. В основе OpenEvolve лежит принцип архивной эволюции, при котором популяция потенциальных решений (вариантов кода) сохраняется в архиве. Это обеспечивает надежное исследование пространства решений, позволяя возвращаться к ранее успешным вариантам и избегать преждевременной сходимости к локальным оптимумам. Архив используется для сохранения разнообразия и поддержания стабильности процесса эволюции, особенно при работе со сложными и крупномасштабными проектами. Реализация OpenEvolve включает в себя инструменты для автоматической оценки производительности и функциональности кода, что позволяет проводить итеративное улучшение с использованием алгоритмов эволюции.
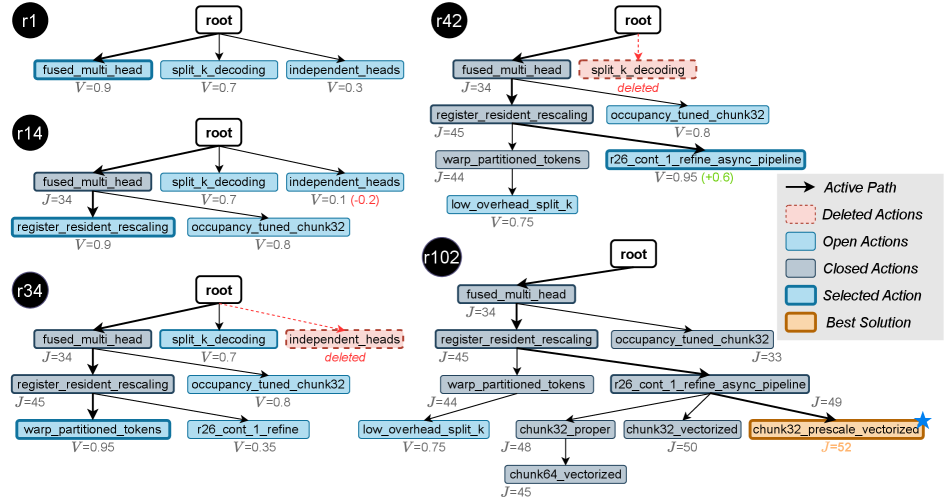
K-Search: Самообучающаяся Модель Мира для Оптимизированного Поиска
В K-Search используется совместно развивающаяся мировая модель, основанная на больших языковых моделях (LLM) GPT-5.2 и Gemini-3-Pro, для прогнозирования производительности потенциальных ядер (kernels). Эта модель не просто оценивает существующие варианты, но и предсказывает, как изменения в коде ядра повлияют на его эффективность. Прогнозирование осуществляется на основе анализа кода и данных о производительности, что позволяет K-Search эффективно ориентироваться в пространстве поиска и выбирать наиболее перспективные кандидаты для дальнейшей оптимизации. Использование LLM позволяет модели учитывать сложные взаимосвязи между структурой кода и его производительностью, что повышает точность прогнозирования и ускоряет процесс поиска оптимального ядра.
Процесс поиска в K-Search управляется миром моделей посредством трех ключевых этапов: выбора действий (Action Selection), локальной оптимизации (Local Refinement) и обновления модели мира (World Model Update). Выбор действий определяет, какие изменения в ядре будут предприняты на текущем этапе, основываясь на прогнозах производительности, сделанных моделью мира. Локальная оптимизация позволяет уточнить выбранные изменения, стремясь к повышению производительности ядра. Наконец, обновление модели мира включает в себя интеграцию результатов оценки новых версий ядра, что позволяет модели мира более точно прогнозировать производительность будущих кандидатов и, следовательно, фокусировать поиск на наиболее перспективных областях пространства проектирования.
В ходе тестирования на ядрах FlashInfer, K-Search продемонстрировал среднее увеличение производительности в 2.10 раза по сравнению с OpenEvolve и в 2.21 раза по сравнению с ShinkaEvolve. Данный результат подтверждает эффективность предложенного подхода к оптимизации, основанного на совместной эволюции модели мира и поискового алгоритма. Улучшение производительности было зафиксировано при оценке времени выполнения критически важных операций на целевом оборудовании, что свидетельствует о практической значимости полученных результатов.
В основе K-Search лежит концепция “Состояния поиска” (Search State), представляющая собой структурированное хранилище данных о ходе оптимизации. Данное состояние включает в себя информацию о протестированных ядрах, их производительности, параметрах и предсказаниях, полученных от мировой модели. Сохранение истории поиска позволяет K-Search избегать повторного исследования неперспективных областей пространства проектирования, эффективно использовать информацию, полученную на предыдущих этапах, и принимать обоснованные решения при выборе следующих кандидатов для оценки. Это значительно ускоряет процесс оптимизации и повышает вероятность обнаружения высокопроизводительных решений, особенно в сложных пространствах поиска, характерных для задач, таких как FlashInfer kernels.
Высокопроизводительное Обслуживание с FlashInfer и Paged KV Cache
Разработанные механизмы FlashInfer и FlashAttention обеспечивают существенное ускорение процесса обслуживания больших языковых моделей (LLM) благодаря оптимизации паттернов доступа к памяти и повышению эффективности вычислений механизма внимания. Вместо традиционного подхода, при котором данные последовательно считываются из памяти, эти технологии используют более эффективные стратегии, такие как упорядоченное чтение и переупорядочивание данных, что значительно снижает задержки и повышает пропускную способность. Ключевым аспектом является минимизация перемещений данных между памятью и вычислительными блоками, что позволяет более эффективно использовать ресурсы GPU и снижает энергопотребление. Благодаря этим инновациям, обслуживание LLM становится более быстрым, экономичным и масштабируемым, открывая новые возможности для развертывания сложных моделей в реальных приложениях.
Критически важным элементом данной инфраструктуры является кэш KV с постраничной организацией памяти. Эта технология позволяет динамически объединять запросы в пакеты, что существенно повышает эффективность использования ресурсов GPU и снижает задержки. В отличие от традиционных методов, когда память выделяется статически и может фрагментироваться, постраничная организация обеспечивает гибкое управление памятью. Это означает, что память выделяется и освобождается по страницам, что минимизирует фрагментацию и позволяет более эффективно использовать доступный объем памяти. В результате, система способна обрабатывать больше запросов одновременно, обеспечивая высокую пропускную способность и стабильную производительность даже при высокой нагрузке.
В ходе тестирования на задаче GPUMODE TriMul, алгоритм K-Search продемонстрировал задержку в 1030 микросекунд. Данный показатель свидетельствует о значительном повышении эффективности обработки данных по сравнению с существующими решениями. Достигнутая скорость позволяет более оперативно выполнять сложные вычисления, что особенно важно в задачах, требующих обработки больших объемов информации в режиме реального времени. Эффективность K-Search обусловлена оптимизацией алгоритма поиска и использованием современных методов параллельной обработки, что открывает новые возможности для создания высокопроизводительных систем искусственного интеллекта.
Исследования показали, что K-Search продемонстрировал впечатляющее ускорение в 14.3 раза при работе с ядрами Mixture-of-Experts (MoE) по сравнению с OpenEvolve. Этот значительный прирост производительности достигается благодаря оптимизированному поиску и обработке данных в MoE-моделях, что позволяет существенно сократить время вычислений и повысить эффективность работы сложных нейронных сетей. Такое ускорение имеет решающее значение для приложений, требующих высокой скорости обработки, таких как обработка естественного языка и машинный перевод, где MoE-модели часто используются для повышения точности и масштабируемости.
Достижения в области оптимизации ядра, такие как представленные в FlashInfer и Paged KV Cache, имеют решающее значение для внедрения больших языковых моделей в реальные приложения. Максимизация пропускной способности и минимизация задержки — ключевые факторы для обеспечения отзывчивости и масштабируемости сервисов, работающих с ИИ. Повышенная эффективность обработки данных позволяет значительно сократить время ответа на запросы, что критически важно для интерактивных приложений и сервисов, обрабатывающих большой объем данных в режиме реального времени. В результате, оптимизированные ядра открывают возможности для более широкого применения передовых моделей искусственного интеллекта в различных отраслях, от обработки естественного языка до компьютерного зрения и автоматизированного принятия решений.
Будущее Оптимизации: Полностью Автоматизированный Конвейер
Сочетание таких фреймворков, как OpenEvolve, ShinkaEvolve и MAP-Elites, открывает новые возможности для повышения разнообразия и устойчивости процесса поиска оптимальных решений. Каждый из этих инструментов обладает своими сильными сторонами: OpenEvolve обеспечивает гибкость в определении алгоритмов эволюции, ShinkaEvolve специализируется на оптимизации сложных многопараметрических систем, а MAP-Elites эффективно исследует пространство решений, поддерживая разнообразие и избегая преждевременной сходимости к локальным оптимумам. Интегрируя эти подходы, исследователи стремятся создать гибридные системы, способные адаптироваться к различным задачам и обеспечивать более надежные и эффективные результаты, особенно в контексте автоматизированного машинного обучения и оптимизации вычислительных ядер. Такой синергетический эффект позволяет преодолеть ограничения каждого отдельного фреймворка и добиться значительного прогресса в области автоматического поиска оптимальных параметров и алгоритмов.
Использование специализированных языков программирования, таких как Triton и CuTe, открывает новые возможности для детального контроля над проектированием и оптимизацией вычислительных ядер. Эти языки позволяют разработчикам явно управлять аппаратными ресурсами и алгоритмами, что приводит к значительному повышению производительности и эффективности кода. В отличие от традиционных подходов, где оптимизация часто выполняется на более высоком уровне абстракции, Triton и CuTe предоставляют инструменты для тонкой настройки каждого аспекта ядра, включая использование памяти, параллелизм и векторные операции. Это особенно важно для современных архитектур, таких как графические процессоры, где эффективное использование аппаратных возможностей требует глубокого понимания низкоуровневых деталей. В результате, ядра, разработанные с использованием этих языков, способны достигать более высоких скоростей и снижать энергопотребление, что критически важно для широкого спектра приложений, от машинного обучения до научных вычислений.
Конечной целью исследований является создание полностью автоматизированного конвейера оптимизации, способного к непрерывной адаптации к новым аппаратным средствам и алгоритмическим решениям. Такой конвейер позволит преодолеть ограничения ручной настройки и добиться беспрецедентного уровня производительности в различных вычислительных задачах. Автоматизация охватит все этапы — от генерации и тестирования различных вариантов реализации алгоритмов до их развертывания на целевой платформе. Ключевым аспектом является разработка механизмов самообучения, позволяющих системе самостоятельно выявлять оптимальные стратегии оптимизации для конкретного аппаратного обеспечения и алгоритма, минимизируя время и ресурсы, затрачиваемые на ручную настройку и максимизируя эффективность вычислений. В перспективе подобный подход откроет возможности для создания самооптимизирующихся систем, способных динамически адаптироваться к изменяющимся условиям и требованиям.
В представленной работе K-Search демонстрирует изящный подход к оптимизации GPU-ядер, используя LLM для формирования и эволюции внутренней модели мира. Эта модель позволяет системе самостоятельно планировать и совершенствовать код, что приводит к значительному приросту производительности. Как заметил Марвин Минский: «Лучший способ понять — это создать». В контексте K-Search, создание коэволюционирующей модели мира и есть тот самый процесс понимания и оптимизации, позволяющий системе обходить сложные задачи, избегая необходимости в ручном вмешательстве и излишних инструкциях. Система, требующая минимального количества внешних указаний, действительно превосходит более громоздкие решения.
Куда же дальше?
Представленный подход, безусловно, демонстрирует любопытную способность к автоматизации оптимизации GPU-ядер. Однако, за внешней эффектностью «самообучающейся» модели скрывается старая проблема: сложность ради сложности. Они назвали это «фреймворком», чтобы скрыть панику перед реальной необходимостью глубокого понимания аппаратной архитектуры. Успех K-Search, вероятно, ограничен областью задач, в которых LLM способна адекватно моделировать пространство поиска — а это, как известно, не всегда так.
Настоящая зрелость в этой области будет заключаться не в создании все более изощренных алгоритмов поиска, а в разработке инструментов, позволяющих человеку быстро и интуитивно понимать узкие места в производительности. Необходимо сместить фокус с автоматической генерации кода на автоматическую диагностику проблем. Простой, понятный профилировщик, который укажет на проблемные участки, будет ценнее, чем сложный алгоритм, который «оптимизирует» что попало.
В конечном итоге, истинный прогресс заключается не в создании «умных» систем, а в усилении возможностей человека. И, возможно, стоит задуматься о том, чтобы потратить меньше времени на поиски «идеального» алгоритма и больше — на обучение инженеров, способных писать эффективный код с самого начала.
Оригинал статьи: https://arxiv.org/pdf/2602.19128.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
- Оживший аватар: Генерация видео в реальном времени по голосу
- Серебро и медь: новый взгляд на наноаллои
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Научные эксперименты с ИИ: новая платформа для проверки интеллекта
- Искусственный интеллект и квантовая физика: кто кого?
- Нейросети: проявление неклассической статистики?
- Пространственное мышление видео: новый подход к обучению ИИ
- Нейронные сети и астроциты: новый подход к обнаружению аномалий
2026-02-24 08:31