Автор: Денис Аветисян
Новое исследование показывает, что большие нейронные сети обретают внутреннюю организацию в процессе обучения, позволяющую упростить их структуру без потери производительности.
В ходе обучения формируются устойчивые зависимости между нейронами, которые можно выявить и использовать для повышения масштабируемости и эффективности больших искусственных интеллектов.
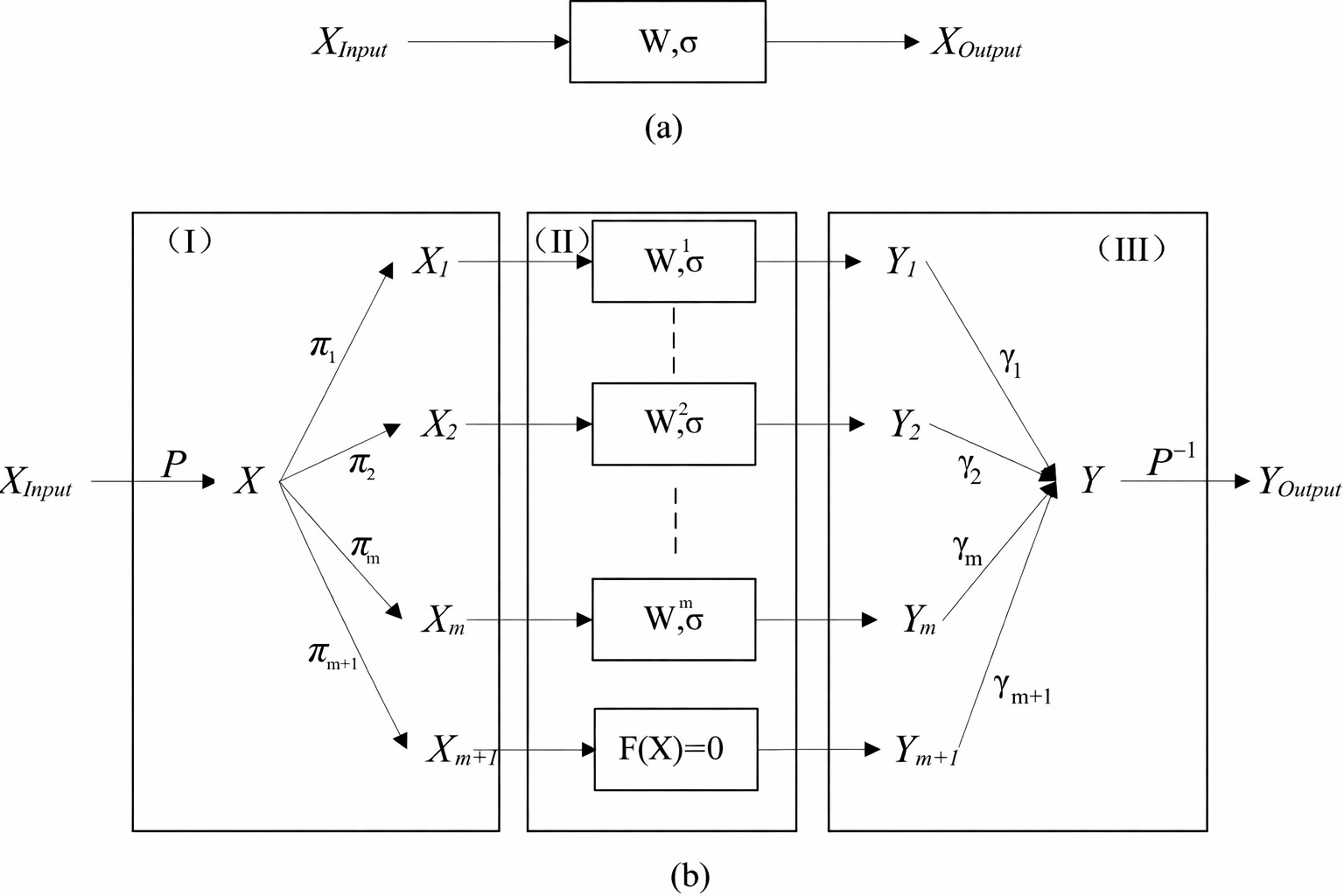
Несмотря на впечатляющую производительность современных больших моделей, их развертывание осложняется растущими вычислительными затратами на этапе инференса. В статье ‘Why Inference in Large Models Becomes Decomposable After Training’ показано, что причиной этого является не недостаток ёмкости моделей, а игнорирование внутренней структуры, формирующейся в процессе обучения. Авторы обнаружили, что градиентные обновления в больших сетях носят локальный характер, что позволяет выделить статистически независимые подструктуры после обучения. Открывает ли это путь к созданию более эффективных и масштабируемых систем инференса, основанных на структурном разрежении и параллельных вычислениях без изменения функциональности моделей?
Эффективность Параметров: За гранью Оптимизации
Несмотря на впечатляющую производительность моделей глубокого обучения, эффективность использования параметров остаётся ключевой проблемой, особенно по мере увеличения их масштаба. Современные нейронные сети часто содержат миллиарды параметров, однако значительная их часть может быть избыточной или вносить незначительный вклад в процесс обучения. Это приводит к увеличению вычислительных затрат, потребления памяти и сложности развертывания, что затрудняет применение моделей на устройствах с ограниченными ресурсами. Повышение эффективности параметров — это не просто оптимизация существующих моделей, но и поиск принципиально новых архитектур и алгоритмов обучения, способных достигать высокой точности, используя значительно меньше ресурсов. Исследования в этой области направлены на выявление и использование внутренней структуры данных и моделей, чтобы обеспечить более компактное и эффективное представление знаний. \text{Эффективность} = \frac{\text{Точность}}{\text{Количество параметров}}
Исследования показывают, что в процессе обучения глубоких нейронных сетей не все параметры вносят одинаковый вклад в конечный результат. Это явление, известное как эффективная разреженность, указывает на то, что внутренняя структура модели может быть значительно проще, чем кажется на первый взгляд. Наблюдается, что лишь небольшая часть параметров действительно необходима для достижения высокой точности, в то время как остальные могут быть удалены или игнорированы без существенной потери производительности. Этот факт позволяет предположить, что обучение моделей может быть оптимизировано путем выявления и усиления наиболее важных связей, а также снижения значимости менее полезных, что потенциально приведет к созданию более эффективных и интерпретируемых систем искусственного интеллекта. Понимание принципов, лежащих в основе этой разреженности, открывает новые возможности для разработки алгоритмов обучения, способных автоматически обнаруживать и использовать внутреннюю структуру данных и моделей.
Механизм обновления градиента, несмотря на свою эффективность в обучении глубоких нейронных сетей, часто приводит к диффузным изменениям параметров. Вместо того, чтобы целенаправленно усиливать наиболее важные связи и подавлять избыточные, градиентный спуск равномерно влияет на множество параметров, что снижает эффективность обучения и увеличивает вычислительные затраты. Это происходит потому, что градиент усредняет влияние каждого отдельного примера на все параметры, игнорируя потенциальную внутреннюю структуру данных и модели. В результате, модель может переобучаться на шумовых данных или тратить ресурсы на неважные параметры, не раскрывая весь свой потенциал. Исследования показывают, что использование методов, направленных на повышение разреженности и структурирование параметров, позволяет более эффективно использовать возможности градиентного спуска и достигать лучших результатов с меньшими вычислительными затратами.
Локальные Взаимодействия: Основа Эффективного Обучения
Отношение совместной встречаемости (Co-occurrence Relation) определяет одновременную активацию состояний в нейронной сети и служит основой для выявления локально значимых взаимодействий. Принцип заключается в том, что если два элемента (например, нейрона или признака) активируются одновременно в контексте определенной задачи, это указывает на статистическую зависимость между ними. Использование этого отношения позволяет идентифицировать, какие компоненты сети наиболее часто работают вместе, что, в свою очередь, дает возможность сосредоточиться на усилении или ослаблении связей между этими компонентами. Такой подход позволяет сети эффективно обучаться, опираясь на закономерности в данных и избегая ненужных изменений в неактивных областях.
Локальные обновления градиента, основанные на информации о совместной активации (co-occurrence), позволяют уточнять параметры сети, ограничивая изменения только теми компонентами, которые непосредственно участвуют в текущей обработке. Вместо глобальной корректировки весов, применяется точечное изменение параметров, что способствует более эффективному обучению и снижению вычислительных затрат. Принцип заключается в том, что только активные связи, продемонстрировавшие совместную активацию, подвергаются модификации, усиливая релевантные соединения и ослабляя неактивные. Такой подход позволяет сети адаптироваться к конкретным входным данным и задачам, минимизируя влияние нерелевантной информации на процесс обучения.
Процесс локальной оптимизации основан на предположении, что обучение происходит за счет усиления связей, формирующихся в ходе взаимодействия, релевантного решаемой задаче. Это означает, что изменения параметров сети происходят преимущественно в тех компонентах, которые были активны во время выполнения конкретных действий или обработки определенных входных данных. Укрепление этих связей способствует более эффективной обработке аналогичных входных данных в будущем, позволяя модели адаптироваться к специфическим требованиям задачи и улучшать свою производительность. Данный подход позволяет избежать глобальных изменений параметров, которые могут нарушить уже сформированные полезные связи и привести к ухудшению результатов.
Выявление Блочно-Диагональной Структуры: Ключ к Устойчивости
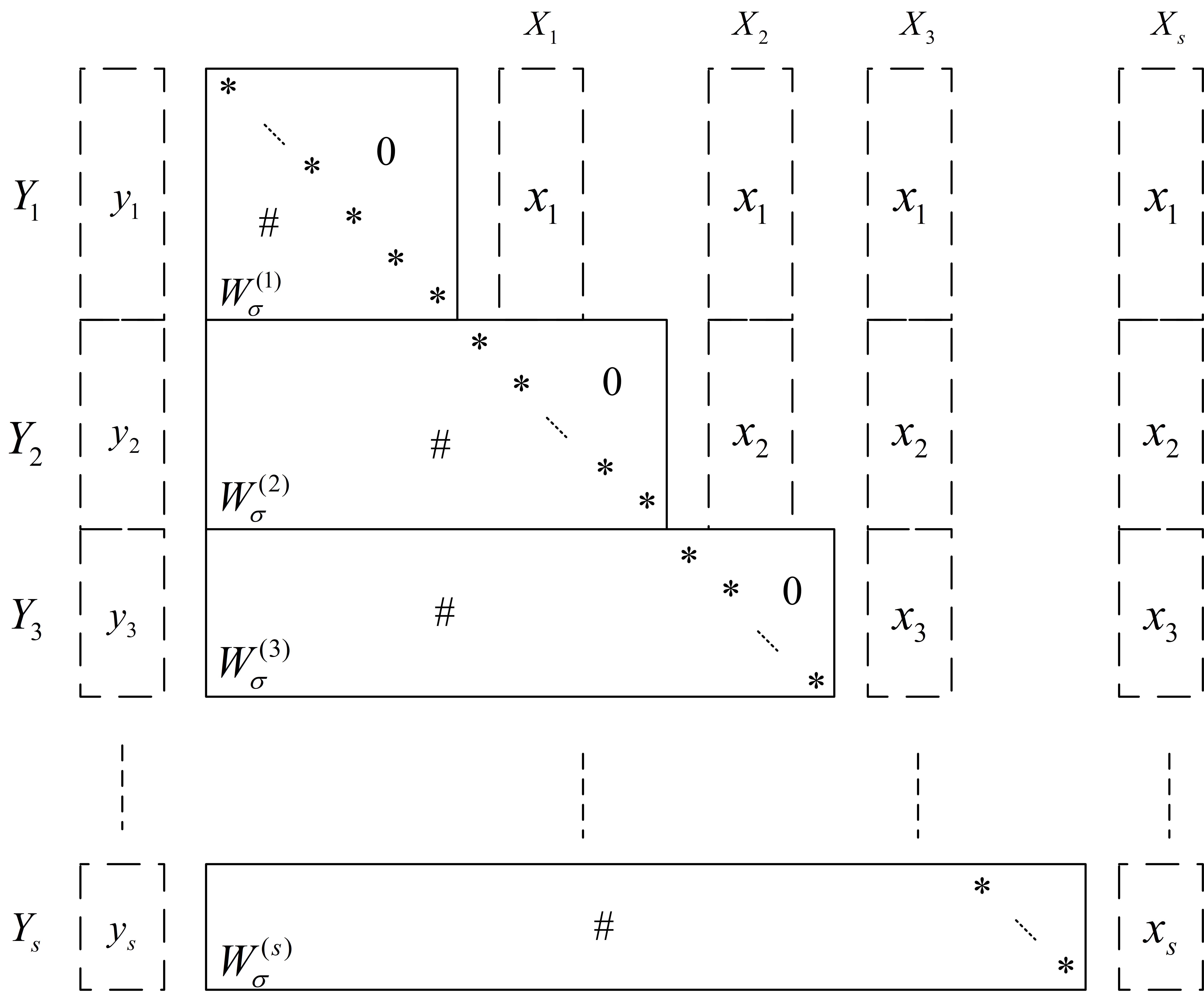
Отношение совместной встречаемости (Co-occurrence Coupling Relation), выведенное из отношения совместной встречаемости и основанное на принципах отношений эквивалентности, позволяет выявлять группы состояний, указывающие на функциональные модули. Данное отношение определяет связи между состояниями, основанные на частоте их совместного появления в данных. Применение принципов отношений эквивалентности обеспечивает кластеризацию состояний, объединяя те, которые статистически взаимосвязаны, и тем самым выделяя потенциальные функциональные блоки внутри системы. Анализ полученных групп позволяет идентифицировать относительно независимые подсистемы, что является ключевым шагом в понимании архитектуры и поведения сложной системы.
Группировки состояний, выявленные посредством отношения ко-встречаемости, проявляются в виде блочно-диагональной структуры в матрицах параметров. Данная структура указывает на наличие относительно независимых подсистем внутри модели. Блоки на диагонали соответствуют параметрам, связывающим состояния внутри определенной функциональной группы, в то время как внедиагональные элементы, соединяющие различные группы, незначительны или равны нулю. По сути, это означает, что изменения в одной подсистеме оказывают минимальное влияние на другие, что способствует повышению модульности и упрощению анализа и модификации модели. \mathbf{W} = \begin{bmatrix} \mathbf{W}_{11} & \mathbf{W}_{12} \\ \mathbf{W}_{21} & \mathbf{W}_{22} \end{bmatrix} , где \mathbf{W}_{11} и \mathbf{W}_{22} представляют собой блочные матрицы, а \mathbf{W}_{12} и \mathbf{W}_{21} содержат малые значения или равны нулю.
Структурная консолидация, осуществляемая посредством статического анализа после обучения модели, направлена на явную стабилизацию выявленных зависимостей между состояниями. Данный процесс включает в себя применение алгоритмов анализа к обученной модели с целью выявления и усиления связей, соответствующих функциональным модулям. Это достигается за счет оптимизации параметров модели таким образом, чтобы минимизировать влияние изменений в одном модуле на другие, что повышает модульность и, как следствие, устойчивость системы к возмущениям и ошибкам. Статический анализ позволяет идентифицировать критические зависимости без необходимости динамического выполнения модели, обеспечивая эффективность и предсказуемость процесса консолидации.
Статистический Отжиг: Выявление Истинных Зависимостей
Статистический отжиг, основанный на гипотезе случайных блужданий (Random-Walk Noise Hypothesis), представляет собой метод постобработки, применяемый к обученной нейронной сети для выявления статистически значимых групп параметров. Данный подход предполагает, что незначительные параметры подвержены случайным флуктуациям, в то время как значимые параметры демонстрируют более устойчивые значения. Процесс отжига заключается в последовательном уменьшении «температуры», что позволяет отфильтровать шумовые зависимости и выделить параметры, которые вносят существенный вклад в функционирование сети. В результате, можно идентифицировать подмножество параметров, определяющих ключевые характеристики модели, что позволяет упростить структуру сети и улучшить её обобщающую способность.
Тест Неймана играет ключевую роль в фильтрации шумов и выявлении устойчивых зависимостей внутри нейронной сети. В рамках данного метода, каждый параметр оценивается на статистическую значимость, определяемую уровнем значимости p < 0.01. Параметры, для которых полученное значение p меньше установленного порога, считаются статистически значимыми и, следовательно, отражают реальные зависимости в данных, а не случайные флуктуации. Это позволяет исключить из рассмотрения незначимые параметры, снизить сложность модели и повысить ее обобщающую способность, сохраняя при этом точность.
Ограничение анализа и оптимизации модели статистически значимыми параметрами позволяет добиться сжатия модели без потери точности. Удаление незначимых связей снижает вычислительную сложность и уменьшает размер модели, что способствует улучшению обобщающей способности, особенно при работе с ограниченными объемами данных или при переносе модели на новые, незнакомые данные. Сохранение только параметров, прошедших статистическую проверку, снижает риск переобучения и повышает устойчивость модели к шуму в данных, что в конечном итоге приводит к более надежным прогнозам и улучшенной производительности в реальных условиях эксплуатации.
Последствия для Масштабируемого и Эффективного Глубокого Обучения
Исследования показали, что для функционирования крупномасштабных систем, таких как модели, основанные на фундаменте (Foundation-Scale Systems), необязательно использовать полностью заполненные матрицы параметров. Вместо этого, достаточной оказывается модульная реализация, управляемая обнаруженной внутренней структурой данных. Этот подход позволяет значительно снизить вычислительную нагрузку, поскольку операции выполняются лишь над релевантными блоками параметров, а не над всей матрицей целиком. Обнаружение и использование такой структуры открывает путь к созданию более эффективных и масштабируемых моделей глубокого обучения, способных обрабатывать огромные объемы информации при ограниченных ресурсах. По сути, системы учатся оптимизировать свою собственную архитектуру, выделяя и используя только наиболее важные связи между параметрами.
Исследования показали, что выявленная блочно-диагональная структура параметров нейронных сетей открывает новые возможности для существенного снижения вычислительных затрат. Методы обрезки (pruning) и сжатия, традиционно применяемые для оптимизации моделей, могут быть значительно улучшены, если учитывать эту структуру. Вместо случайного удаления или упрощения параметров, обрезка может быть направлена на удаление целых блоков, что позволяет сохранить ключевые связи и функциональность сети при минимальных потерях точности. Сжатие, в свою очередь, может использовать блочную структуру для более эффективного кодирования и хранения параметров, уменьшая объем памяти и ускоряя передачу данных. Такой подход не только повышает эффективность обучения и работы моделей, но и способствует созданию более компактных и энергоэффективных систем, особенно актуальных для мобильных устройств и облачных вычислений.
Исследования показывают, что переход к глубокому обучению, учитывающему внутреннюю структуру данных, открывает путь к созданию более эффективных, устойчивых и понятных моделей. Анализ последовательностей параметров длиной в 8 единиц позволяет выявить скрытые закономерности и упростить архитектуру сети, снижая вычислительные затраты и потребление памяти. Такой подход не требует использования полностью плотных матриц параметров; достаточно модульного исполнения, управляемого обнаруженной структурой. Это способствует повышению надежности моделей к различным возмущениям и упрощает интерпретацию их работы, что особенно важно для применения в критически важных областях, где требуется прозрачность и объяснимость принимаемых решений.
Исследование демонстрирует закономерность, которую можно наблюдать в любой сложной системе: после этапа обучения формируется внутренняя структура, определяемая не изначальным замыслом, а фактически сложившимися зависимостями. Это напоминает о том, что архитектура — это не схема, а компромисс, переживший деплой. Как однажды заметил Линус Торвальдс: «Плохой код можно исправить, а плохой дизайн нужно переписывать». В данном случае, возможность пост-тренировочной реструктуризации, выявление и консолидация эффективно усвоенных зависимостей, — это не оптимизация, а реанимация надежды, попытка придать порядок системе, которая, несмотря на свою сложность, стремится к упрощению и эффективности.
Что дальше?
Работа демонстрирует, что крупные нейронные сети, в процессе обучения, неизбежно формируют внутреннюю структуру. Что, в общем-то, не ново. Вселенная любит порядок, а продакшен — упрощения. Теперь, когда мы умеем констатировать факт “структурной разреженности”, возникает вопрос: а что с этим делать? Консолидация зависимостей — это хорошо, но эта консолидация, как и любые другие оптимизации, — лишь отсрочка проблем. Рано или поздно, в продакшене найдется способ сломать даже самую элегантную архитектуру, заставив вспомнить о забытых краевых случаях.
Очевидно, что текущие методы “пост-тренировочной реструктуризации” — это лишь первый шаг. Будущие исследования, вероятно, будут сосредоточены на динамической реструктуризации, способной адаптироваться к меняющимся данным и требованиям. Хотя, если честно, звучит это как бесконечная гонка вооружений между разработчиками и аномалиями. Впрочем, в этом и есть вся прелесть машинного обучения — вечное повторение пройденного, только с другими багами и более сложными именами.
И, конечно, нельзя забывать о фундаментальном вопросе: а нужно ли вообще это всё? Может быть, проще обучить сеть побольше и смириться с неизбежной неэффективностью? В конце концов, иногда самое элегантное решение — это просто добавить ещё ресурсов. Всё новое — это хорошо забытое старое, и эта истина особенно актуальна в мире больших моделей.
Оригинал статьи: https://arxiv.org/pdf/2601.15871.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-24 11:48