Автор: Денис Аветисян
Новое исследование показывает, что большие языковые модели испытывают трудности с решением сложных бухгалтерских задач, несмотря на общие навыки рассуждения.
Оценка возможностей больших языковых моделей в области бухгалтерского рассуждения, включая бенчмаркинг и адаптацию к специфике предметной области.
Несмотря на впечатляющие успехи больших языковых моделей (LLM) в решении общих задач, их способность к специализированному рассуждению в узкопрофильных областях остается недостаточно изученной. В настоящей работе, ‘Exploring the Vertical-Domain Reasoning Capabilities of Large Language Models’, исследуется эффективность LLM в сфере бухгалтерского учета, выявляя ограничения в применении стандартных моделей к задачам, требующим глубоких отраслевых знаний. Полученные результаты демонстрируют, что, несмотря на вариативность в эффективности различных стратегий промптинга, текущие LLM пока не соответствуют требованиям реальных корпоративных сценариев. Возможно ли создание новых методик адаптации LLM, позволяющих эффективно использовать их потенциал в области профессионального бухгалтерского учета и аудита?
Искусственный интеллект и бухгалтерское мышление: вызовы и перспективы
Современные достижения в области искусственного интеллекта, особенно в сфере больших языковых моделей, демонстрируют впечатляющую способность к обработке естественного языка. Эти модели, обученные на огромных объемах текстовых данных, способны не только понимать и генерировать текст, но и выполнять сложные лингвистические задачи, такие как перевод, суммирование и ответы на вопросы. Их архитектура, основанная на механизмах внимания и глубоких нейронных сетях, позволяет улавливать тонкие нюансы языка и устанавливать связи между различными концепциями. Эта способность к пониманию и генерации естественного языка открывает новые возможности для автоматизации задач, требующих обработки текстовой информации, и является ключевым фактором в развитии интеллектуальных систем.
Применение современных больших языковых моделей к сложным задачам, таким как бухгалтерское рассуждение, сталкивается с рядом трудностей, связанных с выполнением многоступенчатых вычислений и логических выводов. В отличие от простого анализа текста, бухгалтерский учет требует не только понимания финансовой информации, но и её точной обработки, а также последовательного применения правил и принципов. Модели часто испытывают затруднения при поддержании точности и связности в длинных цепочках рассуждений, что может приводить к ошибкам в финансовых отчётах и неверной интерпретации данных. Преодоление этих препятствий требует разработки новых методов, способных обеспечить надёжность и прозрачность бухгалтерских расчётов, основанных на искусственном интеллекте.
Традиционные методы решения задач, основанные на последовательном применении алгоритмов, зачастую демонстрируют снижение точности и логической связности при работе с развернутыми цепочками рассуждений. Это особенно заметно в сложных областях, таких как бухгалтерский учет, где требуется не просто выполнить арифметические вычисления, но и корректно интерпретировать финансовые данные, применять соответствующие правила и выводить логически обоснованные заключения. По мере увеличения длины и сложности цепочки рассуждений, ошибки, возникающие на ранних этапах, могут накапливаться и приводить к существенным отклонениям в конечном результате. В связи с этим, возникает необходимость в разработке принципиально новых подходов, способных поддерживать целостность и достоверность информации на протяжении всего процесса логического вывода, обеспечивая надежность и прозрачность бухгалтерских операций.
Постоянно растущая сложность финансовых данных и ужесточающиеся требования регуляторов обуславливают потребность в надежном бухгалтерском мышлении. Современные финансовые потоки характеризуются огромным объемом информации, поступающей из разнообразных источников и требующей глубокого анализа. Параллельно, нормативные акты становятся все более детализированными и многогранными, что создает потребность в точном и беспристрастном толковании. В этих условиях, способность к последовательному, логически обоснованному анализу финансовой информации, подкрепленному четким пониманием регуляторных норм, становится критически важной для обеспечения финансовой отчетности, соответствующей требованиям законодательства и обеспечивающей прозрачность для заинтересованных сторон. Отсутствие надежного бухгалтерского мышления может привести к серьезным ошибкам в финансовой отчетности, что чревато штрафами, репутационными рисками и даже юридическими последствиями.
Улучшение LLM для бухгалтерского учета: методы и фреймворки
Для решения сложных бухгалтерских задач с использованием больших языковых моделей (LLM) активно применяются методы разработки запросов (Prompt Engineering) и последовательного мышления (Chain-of-Thought Prompting). Данные подходы позволяют направлять LLM к поэтапному решению проблем, заставляя модель явно формулировать промежуточные шаги рассуждений. Вместо прямого предоставления вопроса и ожидания ответа, запрос конструируется таким образом, чтобы стимулировать LLM к демонстрации логической цепочки, приводящей к конечному результату. Это повышает прозрачность процесса принятия решений и позволяет выявлять потенциальные ошибки в рассуждениях модели, что особенно важно для задач, требующих высокой точности и соответствия нормативным требованиям.
Метод обучения с небольшим количеством примеров (Few-Shot Learning) позволяет языковым моделям адаптироваться к новым задачам в области бухгалтерского учета, используя ограниченное количество размеченных данных. В отличие от традиционных методов, требующих обширных наборов данных для обучения, Few-Shot Learning использует предварительно обученную модель и дообучает её на небольшом количестве примеров целевой задачи. Это достигается за счет использования мета-обучения или методов, основанных на метриках, позволяющих модели обобщать знания, полученные из других, связанных задач. Такой подход существенно сокращает затраты на разметку данных и ускоряет внедрение моделей в новые области бухгалтерского учета, где размеченных данных недостаточно.
Для решения задач бухгалтерского учета активно применяются большие языковые модели (LLM), такие как GPT-4, модели семейства GLM, FinGPT и BloombergGPT. Эти модели демонстрируют повышенную эффективность благодаря обучению на специализированных финансовых корпусах данных, включающих финансовую отчетность, новостные ленты и аналитические обзоры. Использование финансовых корпусов позволяет моделям лучше понимать специфическую терминологию, контекст и взаимосвязи в бухгалтерской сфере, что приводит к более точным и надежным результатам при решении задач, связанных с финансовым анализом, аудитом и прогнозированием.
Методы структурированного планирования, такие как SWAP (Structure-aware Planning), направлены на повышение качества многошаговых рассуждений в задачах, требующих последовательного выполнения операций. Принцип работы SWAP заключается в организации информации и представлении ее в структурированном виде, что позволяет модели более эффективно отслеживать ход вычислений и снижает вероятность ошибок при выполнении сложных задач, например, при подготовке финансовой отчетности или проведении аудита. В рамках данного подхода, промежуточные результаты вычислений сохраняются и используются для проверки корректности последующих шагов, что повышает надежность и точность получаемых результатов. Структурированное представление данных также упрощает процесс отладки и анализа ошибок, позволяя выявлять и устранять проблемы на ранних стадиях.
Оценка и валидация: проверка навыков рассуждения
Наборы данных GSM8K и MR-GSM8K используются в качестве эталонов для оценки многоступенчатых вычислительных способностей больших языковых моделей (LLM). Эти наборы данных состоят из математических задач, требующих последовательного применения арифметических операций и символьных вычислений для получения решения. GSM8K содержит 8000 задач, основанных на реальных школьных математических задачах, в то время как MR-GSM8K представляет собой более сложную версию с расширенным набором данных. Оценка моделей на этих наборах данных позволяет определить их способность к логическому рассуждению и точности выполнения математических операций в условиях, требующих нескольких шагов вычислений.
Для оценки общих возможностей понимания языка и логического вывода на китайском языке используются наборы данных CLUE и его подмножество CMNLI, а также OCNLI. CLUE (Chinese Language Understanding Evaluation) представляет собой комплексный набор задач, охватывающих различные аспекты обработки естественного языка. CMNLI (Chinese Multi-Sentence Natural Language Inference) специализируется на задаче определения логической связи между двумя предложениями, а OCNLI (Open Chinese Natural Language Inference) предоставляет более широкий спектр примеров для оценки этой способности. Эти наборы данных позволяют исследователям количественно оценить и сравнить производительность различных моделей в задачах, требующих понимания контекста и вывода логических заключений на китайском языке.
Численная точность является критически важным показателем оценки корректности выполнения LLM (большими языковыми моделями) расчетов в области бухгалтерского учета. Оценка производится на основе правильности полученных числовых результатов при решении бухгалтерских задач, включая расчеты прибылей, убытков, активов и пассивов. Высокая числовая точность необходима для обеспечения надежности и достоверности финансовой отчетности, генерируемой или анализируемой LLM. Неточности в расчетах могут привести к существенным ошибкам в финансовом анализе и принятии управленческих решений, поэтому данный показатель является приоритетным при оценке пригодности LLM для применения в финансовой сфере. Оценка числовой точности проводится с использованием специализированных наборов данных и метрик, позволяющих количественно оценить процент правильно решенных задач.
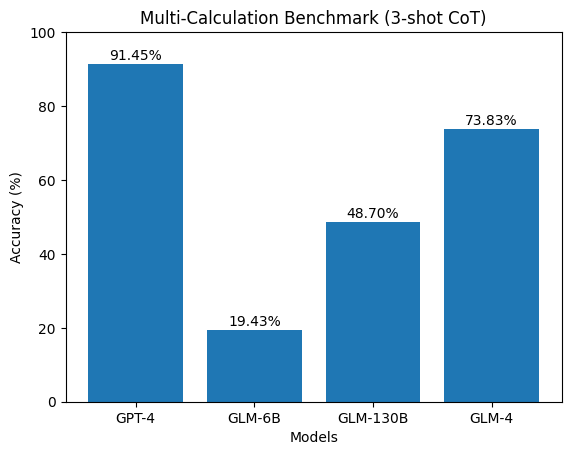
По результатам тестирования на специализированных бенчмарках, предназначенных для оценки навыков бухгалтерского рассуждения, современные языковые модели, такие как GPT-4 и GLM-4, демонстрируют точность на уровне приблизительно 16.58% и 21.78% соответственно. Данный показатель существенно отстает от результатов, достигаемых человеком при решении аналогичных задач. Разрыв в производительности указывает на ограничения текущих моделей в области понимания и применения бухгалтерских принципов, а также в способности к проведению сложных финансовых расчетов.
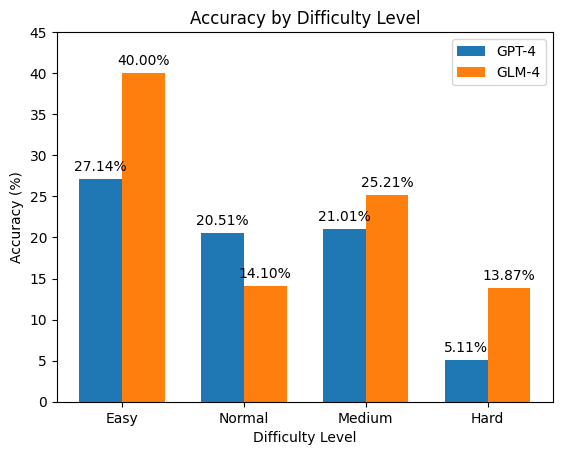
Несмотря на некоторое повышение общей производительности, точность модели GLM-4 снижается примерно до 40% при решении более сложных бухгалтерских задач. Данное снижение указывает на ограничения в способности модели эффективно применять знания и логические рассуждения в ситуациях, требующих более глубокого понимания принципов бухгалтерского учета и умения оперировать большим объемом информации. Наблюдаемое падение точности подчеркивает необходимость дальнейшего совершенствования архитектуры модели и методов обучения для повышения ее устойчивости к возрастающей сложности задач.
Анализ ошибок, допущенных большими языковыми моделями (LLM) при решении задач, показывает, что более 50% неточностей обусловлены непониманием базовых принципов и недостаточным охватом концептуальных знаний. Данный факт указывает на необходимость улучшения механизмов интеграции знаний в архитектуру LLM, а также на важность расширения базы знаний, используемой для обучения моделей, с акцентом на фундаментальные принципы и концепции предметной области. Это предполагает, что простое увеличение объема данных для обучения недостаточно для достижения высокой точности, и требуется разработка методов, позволяющих моделям эффективно усваивать и применять принципиальные знания.
Взгляд в будущее: перспективы и влияние интеллектуального бухгалтерского учета
Внедрение больших языковых моделей (LLM) в бухгалтерские процессы открывает возможности для автоматизации рутинных операций, значительно снижая вероятность ошибок и повышая общую эффективность. Эти модели способны обрабатывать большие объемы финансовых данных, извлекать ключевую информацию и выполнять такие задачи, как классификация транзакций, сверка счетов и формирование отчетов, с минимальным участием человека. Автоматизация позволяет бухгалтерам сосредоточиться на более сложных и аналитических задачах, требующих критического мышления и профессионального суждения, что в конечном итоге способствует повышению точности финансовой отчетности и оптимизации бизнес-процессов. Кроме того, LLM могут быть обучены для выявления аномалий и потенциальных ошибок в данных, что обеспечивает дополнительный уровень контроля качества и снижает финансовые риски.
Временные графы знаний открывают новые возможности для углубленного анализа в сфере бухгалтерского учета. В отличие от традиционных баз данных, они позволяют не просто хранить финансовые данные, но и отражать их динамику во времени, учитывая сложные взаимосвязи и ограничения. Такой подход позволяет системам бухгалтерского учета не только фиксировать транзакции, но и понимать, как эти транзакции влияют на финансовое состояние компании в долгосрочной перспективе. Например, временной граф знаний может учитывать изменения в налоговом законодательстве, сезонные колебания продаж, а также взаимосвязь между различными статьями бухгалтерского баланса. Благодаря этому, системы способны выполнять более сложные рассуждения, выявлять аномалии и прогнозировать будущие финансовые результаты, значительно повышая эффективность и точность бухгалтерского учета.
Возможность проведения сложного бухгалтерского анализа открывает новые перспективы в выявлении мошеннических действий, оценке рисков и прогнозировании финансовых показателей. Автоматизированные системы, способные анализировать финансовые данные с учетом множества факторов и взаимосвязей, позволяют обнаруживать аномалии и подозрительные транзакции, которые могли бы остаться незамеченными при традиционном контроле. Более того, глубокий анализ финансовых потоков и тенденций способствует более точной оценке рисков, связанных с инвестициями и кредитованием. Наконец, используя сложные алгоритмы и учитывая как исторические данные, так и текущие экономические условия, подобные системы способны формировать более реалистичные и надежные финансовые прогнозы, что существенно повышает эффективность принятия управленческих решений и способствует долгосрочной финансовой стабильности.
Перспективные исследования в области интеллектуального бухгалтерского учета направлены на создание более надежных и понятных систем рассуждений. Акцент делается на объединении возможностей больших языковых моделей (LLM) с продвинутыми методами представления знаний. Это позволит не просто автоматизировать рутинные операции, но и обеспечить прозрачность процесса принятия решений, что критически важно для аудита и соответствия нормативным требованиям. Разработка систем, способных объяснять логику своих выводов и учитывать изменяющиеся финансовые данные и ограничения, станет ключевым фактором повышения доверия к автоматизированным бухгалтерским решениям и расширит возможности в области выявления мошенничества, оценки рисков и прогнозирования финансовых показателей. Подобный подход предполагает создание интеллектуальных систем, способных к адаптации и обучению на основе новых данных и меняющихся регуляторных ландшафтов.
Исследование демонстрирует, что большие языковые модели, несмотря на общую способность к рассуждениям, испытывают трудности в применении этих способностей к узкоспециализированным областям, таким как бухгалтерский учет. Это подтверждает необходимость дальнейшей адаптации моделей к конкретным доменам знаний. Как однажды заметил Линус Торвальдс: «Разговорчивость — это враг хорошего кода». Эта фраза отражает суть подхода, который необходим при разработке систем, решающих сложные задачи: отказ от излишней сложности и концентрация на ясности и эффективности. В данном контексте, это означает, что модель должна быть способна к лаконичному и точному применению бухгалтерских принципов, а не к генерации многословных, но непрактичных решений.
Что дальше?
Исследование продемонстрировало: абстракции, какими бы впечатляющими они ни были, стареют. Общая способность к рассуждениям не гарантирует компетентность в специализированных областях, таких как бухгалтерский учет. Модели демонстрируют уязвимость там, где требуется не просто логический вывод, а глубокое понимание предметной области. Каждая сложность требует алиби, и в данном случае алиби — недостаточная адаптация к специфике домена.
Необходимы новые подходы к бенчмаркингу. Существующие тесты часто упускают из виду нюансы реальных задач. Простое увеличение объема данных не решит проблему, если данные не отражают истинную сложность и многогранность предметной области. Требуется переосмысление метрик оценки, акцент на проверке не только правильности ответа, но и обоснованности рассуждений.
Перспективы лежат в области разработки методов, позволяющих моделям эффективно усваивать и применять знания из узкоспециализированных областей. Иллюзии компетентности должны быть заменены на реальное понимание. Совершенство достигается не когда нечего добавить, а когда нечего убрать. Необходимо сосредоточиться на принципах, а не на поверхностных корреляциях.
Оригинал статьи: https://arxiv.org/pdf/2512.22443.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовые прорывы: Хорошее, плохое и смешное
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Квантовая криптография: от теории к практике
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Робот, который видит, понимает и действует: новая эра общего назначения
2025-12-31 10:19