Автор: Денис Аветисян
Новый метод адаптивной квантизации позволяет значительно уменьшить размер и повысить эффективность нейронных сетей при сохранении высокой точности.
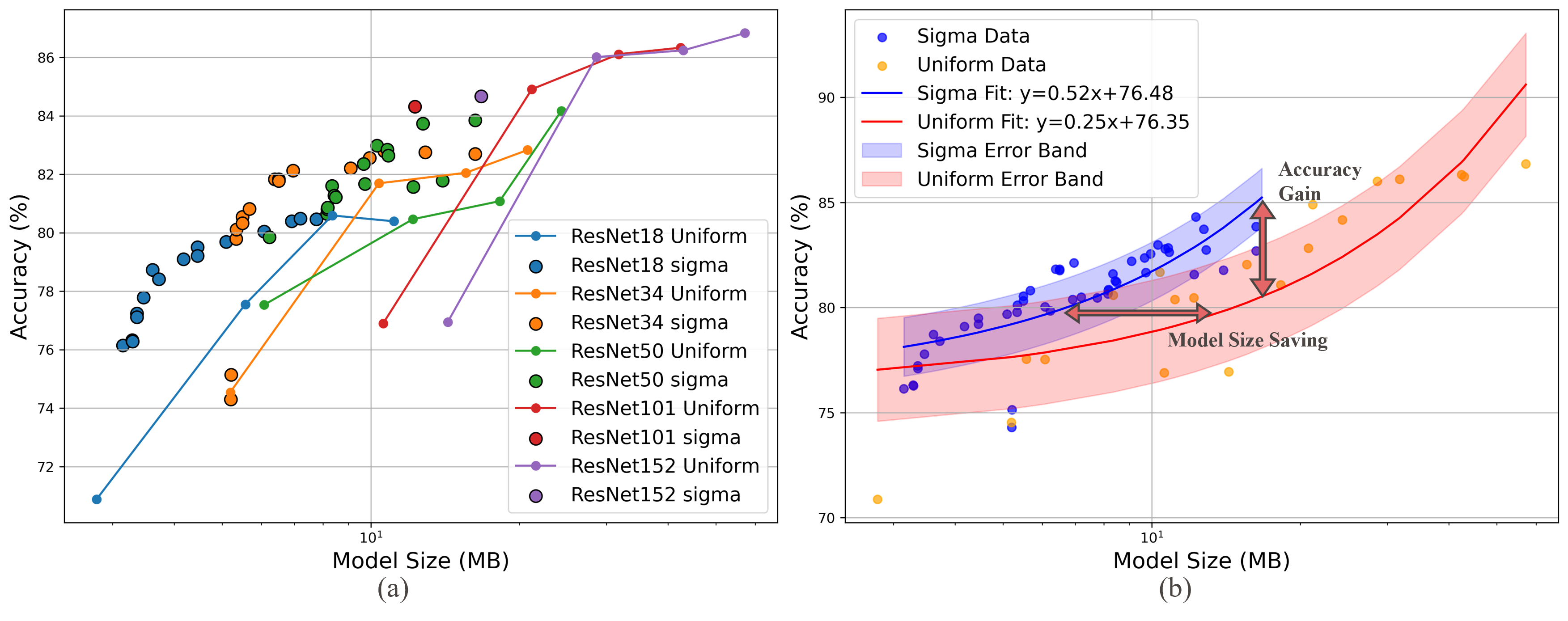
Представлена SigmaQuant — двухфазный гетерогенный подход к квантизации, учитывающий распределение весов и расхождение Кульбака-Лейблера для оптимизации производительности на целевом оборудовании.
Развертывание глубоких нейронных сетей на мобильных и периферийных устройствах часто сдерживается ограниченностью ресурсов, несмотря на их высокую эффективность. В данной работе представлена методика SigmaQuant: Hardware-Aware Heterogeneous Quantization Method for Edge DNN Inference, предлагающая адаптивную гетерогенную квантизацию, учитывающую особенности аппаратной платформы. Ключевой особенностью предложенного подхода является динамическое назначение разрядности весов каждого слоя сети на основе анализа их распределения и расхождения Кульбака-Лейблера KL, что позволяет достичь значительного сжатия модели без существенной потери точности. Сможет ли SigmaQuant стать стандартом де-факто для оптимизации DNN в условиях ограниченных ресурсов?
Квантование как ключ к периферийным вычислениям
Глубокие нейронные сети стали неотъемлемой частью современных вычислительных систем, особенно в контексте периферийных вычислений, где обработка данных осуществляется непосредственно на устройствах, а не в облаке. Однако, несмотря на свою эффективность в решении сложных задач, эти сети характеризуются значительным размером и высокой вычислительной стоимостью. Это создает серьезные препятствия для их развертывания на устройствах с ограниченными ресурсами, таких как смартфоны, дроны и встроенные системы. Ограниченная пропускная способность памяти, энергопотребление и необходимость в мощных процессорах становятся критическими факторами, препятствующими широкому внедрению глубокого обучения в периферийной среде. Поэтому, оптимизация размера и вычислительной сложности нейронных сетей является ключевой задачей для обеспечения их эффективной работы на ресурсоограниченных устройствах.
Традиционные методы квантования, такие как равномерное квантование, зачастую достигают повышения вычислительной эффективности за счет снижения точности модели. Это происходит из-за упрощенного представления весов и активаций, где информация теряется при переходе от чисел с плавающей точкой к целочисленным значениям. В частности, при использовании равномерного квантования все веса в слое подвергаются одному и тому же процессу округления, не учитывая их индивидуальную значимость для итоговой производительности сети. Хотя это позволяет значительно уменьшить размер модели и ускорить вычисления, особенно на устройствах с ограниченными ресурсами, существенная потеря информации может приводить к заметному ухудшению метрик точности, что делает необходимым поиск более сложных и адаптивных стратегий квантования.
Для достижения оптимальной производительности при квантовании глубоких нейронных сетей необходимо применять дифференцированные стратегии, учитывающие чувствительность каждого слоя. Исследования показывают, что различные слои нейронной сети по-разному реагируют на процесс квантования, и унифицированный подход к снижению точности может привести к значительным потерям в производительности. Более эффективным является анализ чувствительности каждого слоя к квантованию — определение того, насколько сильно снижение разрядности влияет на его выходные данные и общую точность сети. Такой подход позволяет применять более агрессивное квантование к менее чувствительным слоям, сохраняя при этом высокую точность в критически важных частях сети. Это позволяет добиться существенного снижения размера модели и вычислительных затрат без значительной потери качества, открывая возможности для развертывания сложных нейронных сетей на устройствах с ограниченными ресурсами.
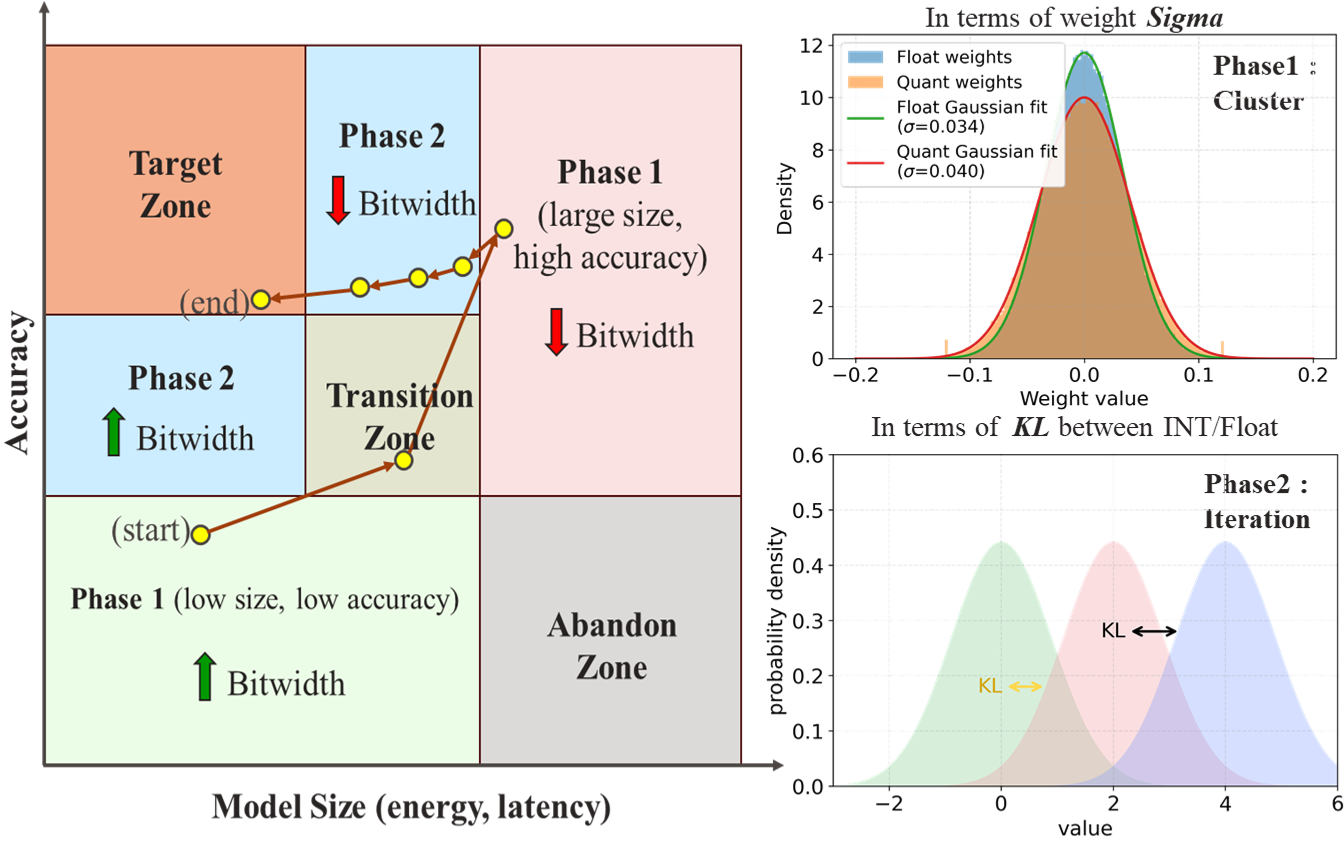
Гетерогенное квантование: адаптация точности к чувствительности
Гетерогенная квантизация представляет собой метод повышения эффективности вычислений путем назначения различной разрядности каждому слою нейронной сети. В отличие от традиционной квантизации, где все веса и активации представляются одинаковым количеством бит, гетерогенная квантизация позволяет более точно адаптировать точность представления данных к специфике каждого слоя. Это достигается путем анализа чувствительности каждого слоя к снижению точности и последующего выбора оптимальной разрядности (например, 8, 4 или даже 2 бита) для минимизации потерь точности модели при сохранении или улучшении её производительности. Использование различных разрядностей позволяет снизить объём памяти, необходимый для хранения модели, и ускорить вычисления, особенно на специализированном оборудовании.
Эффективность гетерогенной квантизации напрямую зависит от точной оценки чувствительности каждого слоя нейронной сети. Для этого часто используются такие метрики, как стандартное отклонение весов и расхождение Кульбака-Лейблера (KL-дивергенция). Стандартное отклонение весов позволяет оценить разброс значений весов в слое, косвенно указывая на его вклад в общую точность модели. Более высокие значения стандартного отклонения могут указывать на большую чувствительность слоя к уменьшению точности представления. Расхождение KL-дивергенции, в свою очередь, измеряет разницу между распределениями активаций слоев в процессе прямой и квантованной передачи, предоставляя информацию о потере информации при квантовании. Комбинированное использование этих метрик позволяет определить оптимальное распределение битовой глубины для каждого слоя, максимизируя эффективность квантизации при минимальной потере точности.
Определение оптимального распределения разрядности для гетерогенной квантизации представляет собой вычислительно сложную задачу, поскольку пространство возможных комбинаций разрядностей экспоненциально растет с увеличением числа слоев в нейронной сети. Полный перебор всех комбинаций недопустим даже для умеренно больших моделей. Существующие методы, такие как жадные алгоритмы или эволюционные стратегии, стремятся найти субоптимальные решения за разумное время, однако не гарантируют нахождение глобального оптимума. Более того, оценка влияния каждой разрядности требует повторной квантизации и оценки производительности модели, что увеличивает общую вычислительную нагрузку. В связи с этим, продолжаются исследования в области разработки более эффективных алгоритмов оптимизации и эвристик для решения данной проблемы.

SigmaQuant: двухфазный поиск оптимального квантования
SigmaQuant применяет двухфазную стратегию поиска для эффективного исследования пространства возможных распределений разрядности. Вместо полного перебора всех комбинаций, что вычислительно нецелесообразно, система последовательно сужает область поиска. Первая фаза генерирует ограниченное количество перспективных конфигураций, а вторая — итеративно уточняет их, стремясь к оптимальному балансу между точностью модели и ее вычислительной эффективностью. Такой подход позволяет значительно сократить время поиска оптимальной разрядности для каждой операции в нейронной сети, делая процесс квантизации более практичным и масштабируемым.
На первом этапе алгоритм SigmaQuant использует адаптивную кластеризацию K-Means для генерации конфигураций квантования на основе чувствительности слоёв нейронной сети. В процессе кластеризации слои группируются с учётом их влияния на общую точность модели. Адаптивный подход позволяет динамически определять оптимальное количество кластеров, что повышает эффективность поиска и позволяет более точно учитывать различия в чувствительности между слоями. В результате формируется набор кандидатов на оптимальные конфигурации, учитывающий специфику каждого слоя и обеспечивающий баланс между точностью и степенью квантования.
Итеративная фаза уточнения в SigmaQuant направлена на оптимизацию конфигураций квантования, полученных на первом этапе. Процесс включает в себя последовательное изменение битовой ширины отдельных слоев нейронной сети с целью минимизации потерь точности и одновременного повышения вычислительной эффективности. На каждом шаге итерации оценивается влияние изменения битовой ширины на общую точность модели, и конфигурация корректируется до тех пор, пока не будет достигнут оптимальный баланс между точностью и эффективностью. Применяемые метрики включают в себя процент снижения точности и прирост производительности, измеряемый в операциях в секунду или энергопотреблении.

Влияние и перспективы: эффективное периферийное развертывание
Система SigmaQuant демонстрирует значительное уменьшение размера моделей и вычислительной сложности, измеряемой в BOPs, при этом сохраняя высокую точность. В ходе исследований было установлено, что использование SigmaQuant позволяет сократить размер модели до 40% по сравнению с традиционной равномерной квантизацией. Такое снижение достигается за счет оптимизированного подхода к квантизации весов и активаций нейронной сети, что позволяет эффективно сжимать модель без существенных потерь в производительности. Сохранение высокой точности, несмотря на значительное уменьшение размера, делает SigmaQuant особенно привлекательным для применения в задачах, где ресурсы ограничены, например, при развертывании моделей на периферийных устройствах и мобильных платформах.
Эффективность, демонстрируемая SigmaQuant, имеет решающее значение для развертывания моделей глубокого обучения на периферийных AI-ускорителях с ограниченными ресурсами. Достигнутое снижение энергопотребления на 20.6% и задержки на 17.5% по сравнению с INT8-квантизацией на моделях ResNet открывает новые возможности для применения искусственного интеллекта в устройствах, работающих от батарей или требующих обработки в реальном времени. Данные показатели позволяют значительно расширить спектр задач, решаемых непосредственно на устройстве, снижая зависимость от облачных вычислений и повышая конфиденциальность данных. Уменьшение требований к вычислительным ресурсам и энергопотреблению делает возможным создание более компактных, экономичных и эффективных систем искусственного интеллекта для широкого круга приложений, включая мобильные устройства, системы видеонаблюдения и автономных роботов.
В ходе исследований продемонстрировано, что SigmaQuant позволяет существенно снизить размер модели без значительной потери точности. В частности, применительно к ResNet-34, удалось достичь Top-1 Accuracy в 81.7% при одновременном уменьшении размера модели, при этом максимальная потеря точности составила не более 2.97%. Данный результат свидетельствует о высокой эффективности SigmaQuant в сохранении производительности даже при значительном сокращении вычислительных ресурсов, что особенно важно для внедрения глубокого обучения на устройствах с ограниченной мощностью и энергопотреблением.
Интеграция SigmaQuant с процедурами калибровки и обучением с учетом квантования (Quantization-Aware Training, QAT) значительно повышает надежность и эффективность квантованных моделей. Калибровка позволяет точно определить оптимальные параметры квантования для конкретной модели и набора данных, минимизируя потери точности. В свою очередь, QAT позволяет модели адаптироваться к процессу квантования во время обучения, что приводит к существенному улучшению производительности по сравнению со стандартным квантованием после обучения. Такой комбинированный подход не только снижает вычислительную сложность и энергопотребление, но и обеспечивает стабильную работу моделей даже в условиях ограниченных ресурсов, что критически важно для развертывания на периферийных устройствах и в системах искусственного интеллекта.
«`html
Представленная работа демонстрирует элегантность подхода к оптимизации глубоких нейронных сетей. SigmaQuant, с его адаптивным назначением разрядности слоям на основе анализа распределения весов и расхождения Кульбака-Лейблера, напоминает тонкую настройку сложного механизма. Как и в архитектуре, где необходимо понимать кровоток прежде чем приступать к трансплантации сердца, данная методика учитывает взаимосвязь между различными компонентами сети. Тим Бернерс-Ли однажды сказал: «Веб должен быть для всех, везде». Аналогично, SigmaQuant стремится к эффективности и доступности глубокого обучения, позволяя развертывать сложные модели на устройствах с ограниченными ресурсами, не жертвуя при этом точностью.
Что дальше?
Представленный подход, SigmaQuant, безусловно, демонстрирует элегантность в стремлении к оптимальному распределению битовой точности. Однако, подобно любому упрощению сложной системы, возникают вопросы о границах применимости. Очевидно, что эффективность метода тесно связана с особенностями архитектуры сети и характерами распределений весов. Неизбежно, потребуются дальнейшие исследования для оценки устойчивости SigmaQuant к различным типам сетей и задачам, а также для выявления сценариев, в которых адаптивное назначение битовой точности не приносит ожидаемой выгоды.
Особый интерес представляет вопрос о взаимодействии между оптимизацией модели и спецификой аппаратного обеспечения. Успех SigmaQuant указывает на необходимость перехода от универсальных методов сжатия к решениям, учитывающим не только теоретическую возможность снижения точности, но и реальные ограничения и возможности конкретных вычислительных платформ. Будущие работы, вероятно, будут сосредоточены на разработке автоматизированных систем, способных одновременно оптимизировать как модель, так и ее аппаратную реализацию.
В конечном итоге, стремление к сжатию моделей — это лишь часть более общей задачи: создание действительно интеллектуальных систем, способных эффективно использовать ограниченные ресурсы. SigmaQuant — это шаг в правильном направлении, но путь к достижению этой цели требует не только технических инноваций, но и глубокого понимания принципов, лежащих в основе как искусственного интеллекта, так и физической реальности.
Оригинал статьи: https://arxiv.org/pdf/2602.22136.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
2026-02-26 17:52