Автор: Денис Аветисян
Новое исследование выявило конкретный механизм, отвечающий за инициацию процесса перевода в больших языковых моделях, открывая возможности для повышения качества и эффективности их обучения.

Использование разреженных автоэнкодеров позволило идентифицировать и изолировать ‘переключатель’, запускающий процесс перевода, а также разработать стратегию отбора данных для оптимизации тонкой настройки.
Несмотря на впечатляющую способность больших языковых моделей (LLM) к переводу, внутренние механизмы, обеспечивающие эту возможность без специальной настройки, остаются неясными. В работе ‘Finding the Translation Switch: Discovering and Exploiting the Task-Initiation Features in LLMs’ представлен новый подход, использующий разреженные автокодировщики, для выявления и анализа так называемых “функций инициации перевода”. Установлено, что активация этих функций является ключевым фактором качества перевода, а их подавление приводит к галлюцинациям и отклонениям от задачи. Может ли понимание этих внутренних механизмов привести к созданию более эффективных и надежных LLM, способных к самообучению и адаптации?
Взлом Перевода: Как Модели Сами Учатся Говорить на Других Языках
Современные большие языковые модели демонстрируют удивительную способность к переводу, несмотря на то, что они не обучались специально для этой задачи. Это явление, получившее название «нулевой перевод», указывает на то, что модели способны обобщать знания, полученные в процессе обучения на огромных объемах текстовых данных, и применять их к новым, не предусмотренным задачам. Вместо явного обучения переводу, модели, по-видимому, извлекают информацию о взаимосвязях между языками из косвенно представленных примеров переводов, содержащихся в обучающем корпусе. Эта способность поражает, поскольку показывает, что сложные навыки могут возникать как побочный эффект масштабного обучения, а не как результат целенаправленной разработки, открывая новые перспективы в области искусственного интеллекта и обработки естественного языка.
Появление способности к переводу у больших языковых моделей ставит под сомнение устоявшиеся представления о необходимости специализированного обучения для выполнения конкретных задач в области обработки естественного языка. Традиционно предполагалось, что для эффективного перевода требуется целенаправленное обучение на параллельных корпусах текстов. Однако, наблюдаемая способность моделей к переводу без предварительного обучения этой задаче демонстрирует, что понимание языка и способность к обобщению могут быть достаточными для достижения приемлемых результатов даже в сложных лингвистических задачах. Этот феномен указывает на то, что модели способны извлекать знания о переводе из огромного объема текстовых данных, на которых они обучались, и применять их в новых ситуациях, что открывает новые перспективы для разработки более универсальных и адаптивных систем обработки языка.
Предварительные данные, на которых обучаются большие языковые модели, вероятно, содержат случайные примеры переводов, что может объяснить их неожиданную способность к переводу без специального обучения. Анализ этих данных показывает, что в огромных объемах текстов, собранных из интернета, неизбежно присутствуют пары предложений на разных языках — например, веб-страницы с параллельными переводами или комментарии пользователей. Хотя эти примеры не были специально предназначены для обучения переводу, модель, обрабатывая петабайты данных, неизбежно «научается» сопоставлять фразы и предложения на разных языках, формируя базовое понимание соответствий. Таким образом, кажущееся «чудо» перевода без обучения может быть результатом не волшебства, а закономерного извлечения знаний из огромного массива случайно включенных примеров перевода.
Несмотря на впечатляющие способности больших языковых моделей к внезапному переводу, лежащие в основе этого феномена механизмы остаются практически неизученными. Исследователи полагают, что способность к переводу возникает как побочный эффект масштабного предварительного обучения на огромных массивах текстовых данных, но точные процессы, посредством которых модель «учится» переводить без явной тренировки, остаются загадкой. Изучение этих внутренних процессов требует новых методологических подходов и инструментов анализа, позволяющих проследить, как модель обрабатывает и преобразует языковые структуры для выполнения задачи перевода. Понимание этих механизмов не только прояснит природу emergent behavior, но и откроет возможности для создания более эффективных и гибких систем машинного перевода.
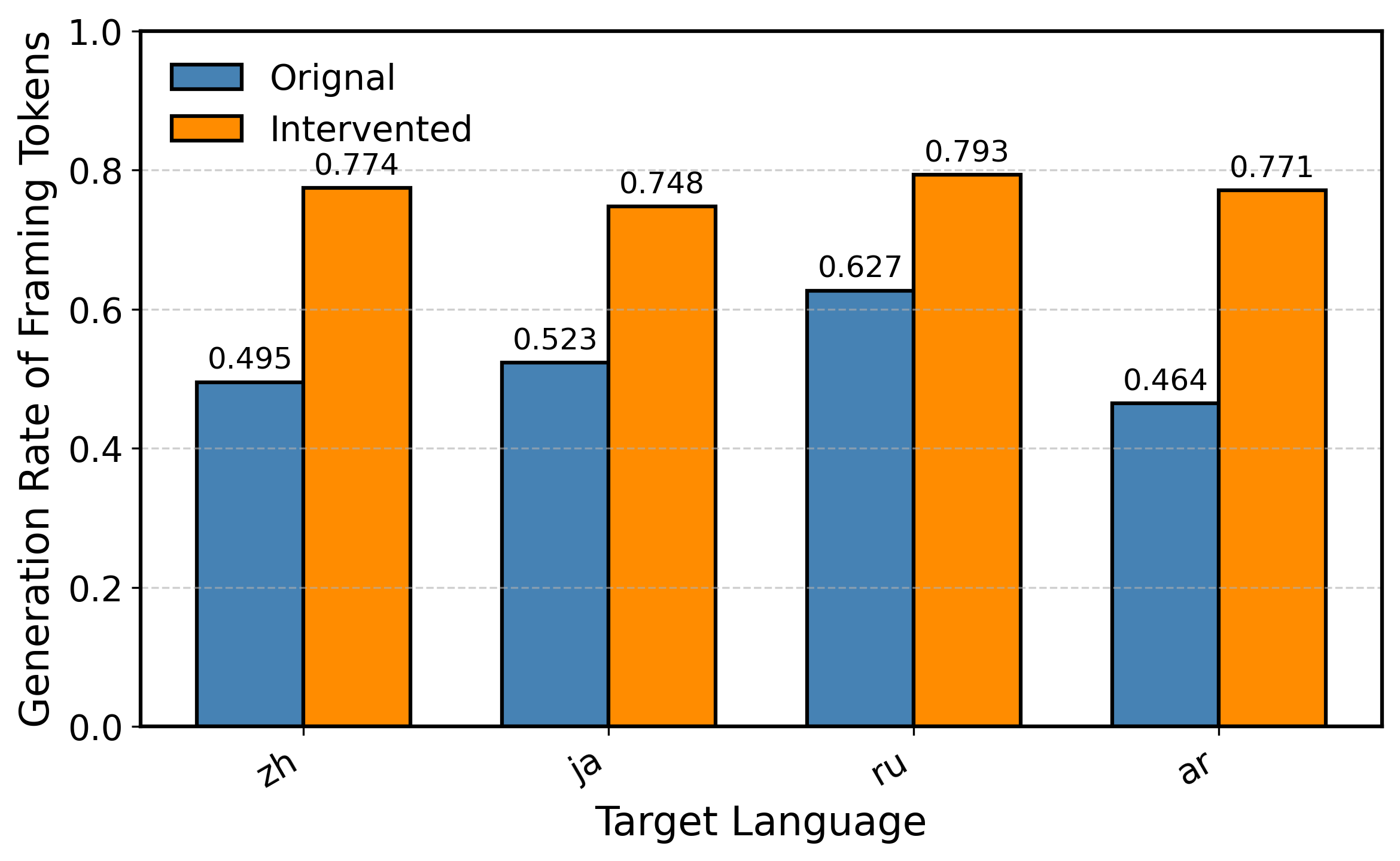
Дешифровка Чёрного Ящика: Выявление Признаков Инициации Перевода
Для деконструкции скрытых состояний больших языковых моделей (БЯМ) с целью выявления ключевых признаков, необходимых для процесса перевода, были использованы разреженные автоэнкодеры (Sparse Autoencoders). Данный подход позволил снизить размерность представления скрытых состояний БЯМ, выделив наиболее значимые компоненты, которые предположительно управляют инициацией перевода. Разреженные автоэнкодеры, в отличие от традиционных методов снижения размерности, акцентируют внимание на извлечении небольшого числа активных признаков, что способствует более интерпретируемому и компактному представлению данных, необходимому для дальнейшего анализа и выявления специфических признаков инициации перевода.
Анализ скрытых состояний больших языковых моделей с использованием разреженных автокодировщиков выявил конкретные признаки, обозначенные как «Признаки Инициации Перевода». Эти признаки, представляющие собой специфические активационные паттерны в нейронных сетях, демонстрируют корреляцию с началом процесса перевода. Наблюдения показывают, что изменение этих признаков приводит к предсказуемым изменениям в начале генерации перевода, что указывает на их роль в контроле запуска процесса. Дальнейшие исследования направлены на точное определение функций каждого признака и их взаимодействия для более полного понимания механизмов инициации перевода в больших языковых моделях.
Вектор влияния признаков (Feature Influence Vector) представляет собой количественную оценку причинно-следственной связи между идентифицированными признаками и процессом инициации перевода в больших языковых моделях. Он вычисляется на основе анализа изменений в выходных данных модели при намеренном воздействии на активность конкретных признаков. Значение вектора для каждого признака указывает на степень его влияния на вероятность успешной инициации перевода; более высокие значения свидетельствуют о более сильном причинном воздействии. Данный вектор позволяет не только определить наиболее важные признаки, но и оценить их вклад в общую эффективность процесса инициации перевода, предоставляя возможность для дальнейшей оптимизации модели.
Для оценки когерентности выделенных признаков инициации перевода был использован показатель согласованности на основе метода главных компонент (Principal Component Analysis, PCA) — ‘PCA Consistency Score’. Полученное значение составило 0.95. Данный показатель измеряет степень, в которой различные признаки коррелируют друг с другом в пространстве скрытых состояний модели. Превышение порога, установленного для идентификации когерентной схемы признаков инициации перевода, подтверждает, что выделенные признаки образуют взаимосвязанную и функционально значимую цепь, участвующую в процессе запуска механизма перевода. Высокий ‘PCA Consistency Score’ указывает на то, что наблюдаемая корреляция признаков не является случайной, а отражает истинную внутреннюю структуру модели.

Механическая Тонкая Настройка: Стратегия Отбора Данных
Традиционные методы дообучения (fine-tuning) больших языковых моделей часто требуют использования обширных наборов данных для достижения приемлемого уровня производительности. Это обусловлено необходимостью охвата широкого спектра лингвистических явлений и случаев использования, что влечет за собой значительные вычислительные затраты на сбор, разметку и обработку данных. Высокий объем требуемых данных не только увеличивает стоимость обучения, но и создает логистические трудности, особенно в сценариях с ограниченными ресурсами или при работе с узкоспециализированными доменами, где доступ к большим объемам размеченных данных ограничен или отсутствует. В результате, эффективность и масштабируемость традиционных подходов дообучения становятся проблемой для многих практических приложений.
Предлагаемая стратегия отбора данных основывается на приоритезации обучающих примеров, активирующих идентифицированные “Признаки Инициации Перевода” (Translation Initiation Features). Данный подход предполагает анализ активации этих признаков в скрытых слоях модели для каждого примера в обучающем наборе. Примеры, демонстрирующие наибольшую активацию указанных признаков, получают более высокий приоритет и включаются в подмножество данных для обучения. Эффективность стратегии обусловлена фокусировкой на данных, непосредственно вовлекающих механизмы перевода модели, что позволяет достичь сопоставимой производительности при значительном сокращении объема используемых данных.
Механический отбор данных фокусируется на примерах, которые непосредственно активируют механизмы перевода в модели. Этот подход основан на предположении, что наиболее информативными для обучения являются данные, вызывающие значимую реакцию в слоях, ответственных за процесс перевода — то есть, преобразование входных данных в выходные представления. Отбор осуществляется путем оценки степени активации этих ключевых слоев для каждого примера в обучающем наборе и приоритезации примеров с наиболее высокой активацией. Данные, слабо активирующие механизмы перевода, исключаются из процесса обучения, что позволяет сократить размер обучающего набора без существенной потери производительности.
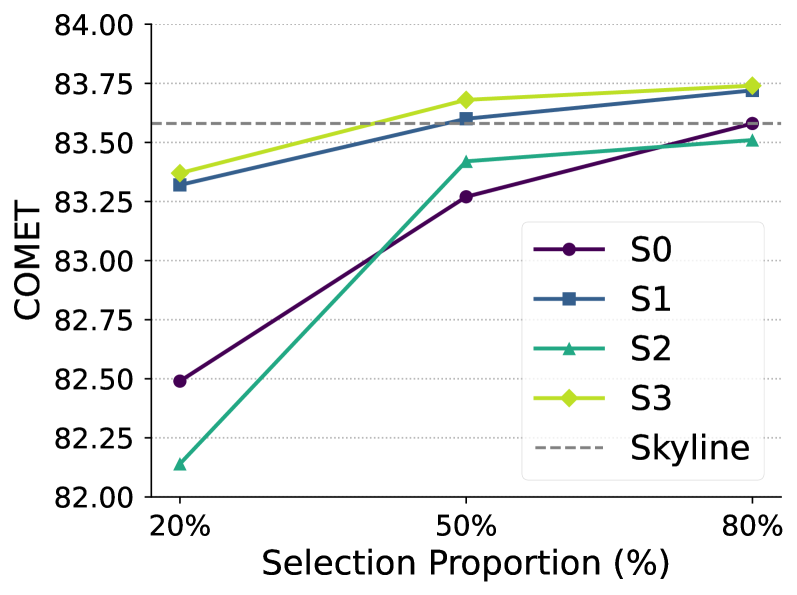
В ходе экспериментов было продемонстрировано, что применение предложенной стратегии отбора данных позволило достичь производительности, сопоставимой с обучением на полном наборе данных, при использовании лишь 50% от его объема. Это свидетельствует о высокой эффективности отбора примеров, ориентированного на активацию ‘Translation Initiation Features’, и указывает на возможность значительного сокращения вычислительных затрат и времени обучения без потери в качестве модели. Полученные результаты подтверждают перспективность данного подхода для задач, требующих обучения больших языковых моделей на ограниченных ресурсах.

Производительность и Надёжность: Оценка Качества Перевода
Для оценки качества перевода, полученного от дообученных моделей, включая ‘Gemma-2’ и ‘LLaMA’, использовалась метрика COMET Score. Этот показатель позволяет комплексно оценивать адекватность и беглость перевода, учитывая как грамматическую корректность, так и семантическое соответствие исходному тексту. Применение COMET Score позволило провести объективное сравнение различных подходов к обучению моделей машинного перевода и выявить наиболее эффективные стратегии повышения качества получаемого результата. Полученные данные демонстрируют, что данная метрика является надежным инструментом для оценки и сопоставления различных систем машинного перевода.
Особое внимание в ходе оценки качества перевода уделялось измерению так называемой «галлюцинаторности» — частоты появления неточных или искаженных фрагментов в переводе. Этот показатель, отражающий склонность модели к «выдумыванию» информации, не содержащейся в исходном тексте, является критически важным для определения надежности машинного перевода. Высокая частота галлюцинаций подрывает доверие к системе, поскольку пользователь получает не только неточные, но и потенциально вводящие в заблуждение результаты. Точная оценка галлюцинаторности позволяет выявить и исправить слабые места модели, обеспечивая более верный и правдивый перевод исходного материала.
Исследования показали, что применение метода «Механистического отбора данных» демонстрирует существенное улучшение качества машинного перевода. Полученные результаты свидетельствуют о достижении оценки COMET в 83.68 пункта, что незначительно превосходит показатель в 83.58 пункта, полученный при использовании полного набора данных в качестве основы. Особенно важно отметить, что данный подход позволил почти вдвое снизить частоту возникновения «галлюцинаций» — неверных или искаженных переводов, что является ключевым фактором для повышения надежности и достоверности систем машинного перевода. Таким образом, «Механистический отбор данных» представляет собой перспективное направление для создания более точных и заслуживающих доверия инструментов автоматического перевода.
Разработанный подход открывает перспективы для создания более надежных и заслуживающих доверия систем машинного перевода. Благодаря тщательному отбору данных, основанному на механистическом анализе, удается не только повысить качество перевода, демонстрируемое улучшенным результатом COMET Score, но и существенно снизить частоту возникновения галлюцинаций — неточностей и искажений в переводе. Это позволяет приблизиться к созданию систем, способных предоставлять пользователям точную и достоверную информацию, что особенно важно в критически важных областях, где требуется высокая степень надежности перевода, таких как медицина, юриспруденция и международные отношения. Внедрение подобного метода позволяет перейти от простого воспроизведения текста к его осмысленному и корректному переводу, укрепляя доверие к автоматизированным системам перевода.
Исследование демонстрирует, что даже в сложных системах, таких как большие языковые модели, существуют ключевые точки влияния. Авторы, подобно инженерам-реверсерам, выявили специфическую функцию, отвечающую за инициацию перевода, и доказали её причинно-следственную связь с качеством результата. Как говорил Клод Шеннон: «Информация — это способность изменять неопределенность». В данном случае, выявление и контроль над этой функцией инициации позволяет не только понять, как модель принимает решение о переводе, но и целенаправленно улучшить её работу, эффективно управляя неопределенностью и повышая точность. Это яркий пример того, как понимание внутренней структуры системы позволяет взломать её ограничения и добиться желаемого результата.
Куда же дальше?
Представленная работа лишь приоткрывает ящик с бубном, именуемым «большая языковая модель». Выделение признака, ответственного за инициацию перевода, — это, скорее, диагностика, чем лечение. Вопрос в том, насколько эта «точка входа» универсальна? Действительно ли подобные признаки, определяющие ключевые функциональные возможности, существуют и для других задач, или же мы имеем дело с уникальной аномалией, характерной лишь для перевода? И, что более интересно, как эти признаки взаимодействуют друг с другом — формируют ли они иерархию, или же представляют собой запутанную сеть взаимозависимостей?
Стратегия отбора данных для тонкой настройки, основанная на выявленных признаках, выглядит многообещающе, но требует дальнейшей проверки. Не превратится ли оптимизация под конкретный признак в своего рода «тоннельное зрение», игнорирующее более тонкие аспекты языковой компетенции? Ведь, как известно, дьявол кроется в деталях, а детали часто ускользают от автоматизированных алгоритмов. В конце концов, искусственный интеллект — это лишь зеркальное отражение нашей собственной сложности.
Вместо того, чтобы стремиться к созданию «идеальной» модели, возможно, стоит сосредоточиться на разработке инструментов, позволяющих «взломать» существующие. Понимание принципов работы «чёрного ящика» важнее, чем его совершенствование. В конце концов, самое интересное рождается на границе хаоса и порядка, в процессе деконструкции и рекомбинации.
Оригинал статьи: https://arxiv.org/pdf/2601.11019.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Восполняя пробелы в знаниях: Как языковые модели учатся делать выводы
- Сердце музыки: открытые модели для создания композиций
- Квантовый скачок из Андхра-Прадеш: что это значит?
- Визуальное мышление нового поколения: V-Thinker
- Квантовые эксперименты: новый подход к воспроизводимости
- Виртуальная примерка без границ: EVTAR учится у образов
- Точность фазовой оценки: адаптивный подход превосходит стандартный
- Разгадывая тайны квантового мира: переработка кубитов и шум как тайная приправа?
- Скрытая сложность: Необратимые преобразования в квантовых схемах
- Автономный поисковик научных статей: новый подход
2026-01-20 05:12