Автор: Денис Аветисян
Новое исследование выявляет фундаментальную проблему в современных алгоритмах обучения с подкреплением на основе обратной связи от человека, ограничивающую их способность к исследованию и адаптации к новым задачам.

В статье представлена методика A-GRAE, направленная на устранение симметрии в оценке преимуществ и повышение эффективности обучения больших языковых моделей.
Несмотря на успехи обучения с подкреплением на основе обратной связи от человека (RLHF), особенно алгоритма GRPO, сохраняются ограничения в эффективном исследовании пространства решений и адаптации к изменяющейся сложности задач. В работе ‘Unveiling Implicit Advantage Symmetry: Why GRPO Struggles with Exploration and Difficulty Adaptation’ показано, что эти недостатки обусловлены скрытой симметрией в оценке преимуществ, лежащей в основе Group Relative Advantage Estimation (GRAE). Выявлено, что данная симметрия препятствует исследованию новых, корректных решений и не позволяет алгоритму эффективно фокусироваться на задачах оптимальной сложности. Может ли динамическое изменение стимулов к исследованию и приоритезация задач по сложности стать ключом к повышению эффективности обучения больших языковых и мультимодальных моделей?
Разоблачение логического мышления в фундаментальных моделях
Несмотря на впечатляющие масштабы и способность обрабатывать огромные объемы данных, базовые модели часто демонстрируют ограниченные возможности в решении сложных задач, требующих логического мышления. Эта проблема существенно сдерживает их потенциал в областях, где необходим не просто поиск закономерностей, а последовательный анализ и построение умозаключений. Даже самые мощные модели могут допускать ошибки в ситуациях, требующих планирования, абстрактного мышления или понимания причинно-следственных связей. В результате, для полноценного использования этих моделей в критически важных приложениях, таких как научные исследования, медицинская диагностика или финансовый анализ, требуется разработка методов, позволяющих преодолеть эти ограничения и обеспечить надежное и обоснованное решение задач.
Эффективное рассуждение, в отличие от простого распознавания закономерностей, требует от модели способности к последовательному, шаг за шагом, обдумыванию задачи. Это напоминает процесс, который люди используют при решении сложных проблем — выстраивание цепочки логических умозаключений. Подобный подход, известный как генерация “Цепочки Мыслей” (Chain-of-Thought, CoT), позволяет модели не просто давать ответ, но и демонстрировать ход своих рассуждений, делая процесс принятия решений более прозрачным и, что важно, более надежным. Способность к CoT-генерации открывает возможности для решения задач, требующих не только знаний, но и умения логически мыслить, что существенно расширяет потенциал применения больших языковых моделей.
Традиционные методы обучения с подкреплением и верифицируемыми наградами (RLVR) демонстрируют потенциал в активации способности к рассуждению у больших языковых моделей, однако их эффективное применение требует оптимизированных парадигм обучения. Проблема заключается в том, что стандартные алгоритмы RLVR часто сталкиваются с трудностями в масштабировании до сложных задач, требующих многошаговых рассуждений, и могут быть чувствительны к выбору функции награды. Исследователи активно изучают новые подходы, направленные на повышение эффективности обучения, включая использование более компактных представлений состояний, разработку стратегий исследования, ориентированных на наиболее информативные примеры, и применение методов переноса обучения для ускорения сходимости. Успешное преодоление этих трудностей позволит в полной мере реализовать потенциал RLVR для создания моделей, способных к надежному и прозрачному рассуждению.

GRPO: Упрощенный подход к оптимизации политики
Групповая относительная оптимизация политики (GRPO) представляет собой упрощенный подход к обучению фундаментальных моделей, устраняя необходимость в традиционной модели-критике. Вместо оценки абсолютной ценности действий, GRPO фокусируется на относительной эффективности действий внутри выборки, формируя группы траекторий. Это позволяет избежать сложной процедуры обучения критика, требующей оценки функции ценности, и напрямую оптимизировать политику на основе относительных преимуществ действий внутри каждой группы. Таким образом, GRPO снижает вычислительные затраты и упрощает процесс обучения, сохраняя при этом эффективность в достижении оптимальной политики.
Основная инновация GRPO, оценка относительного преимущества в группах (Group Relative Advantage Estimation, GRAE), заключается в эффективном вычислении оценок относительного преимущества внутри выборочных групп. Вместо использования традиционной функции ценности (critic), GRAE оценивает, насколько лучше политика действует в рамках конкретной группы по сравнению с другими политиками в той же группе. Это достигается путем вычисления разницы между ожидаемой суммарной наградой, полученной политикой в группе, и средним значением наград, полученных другими политиками в этой же группе. \Delta = E[\tau] - \bar{E}[\tau_{group}] , где τ — суммарная награда, а \bar{E}[\tau_{group}] — средняя награда в группе. Такой подход упрощает процесс обновления политики, поскольку позволяет напрямую оценивать относительную эффективность без необходимости в сложной модели оценки.
Интересно, что GRPO можно концептуально рассматривать как форму контролируемого обучения (SFT). В отличие от традиционных методов обучения с подкреплением, требующих оценки ценности состояний или действий, GRPO использует относительную оценку преимуществ в пределах выбранных групп для обновления политики. Это позволяет интерпретировать процесс обучения GRPO как задачу предсказания действий, аналогичную SFT, где целевые данные формируются на основе относительных преимуществ действий внутри группы, а не абсолютных значений. Такая интерпретация упрощает понимание и реализацию GRPO, поскольку позволяет использовать существующие инструменты и методы, разработанные для SFT, для обучения больших языковых моделей.
Решение проблемы симметрии преимуществ в GRPO
Основная проблема алгоритма GRPO заключается в так называемой “симметрии преимуществ” (Advantage Symmetry), при которой положительные и отрицательные траектории обучения оцениваются одинаково. Это приводит к тому, что алгоритм не может эффективно дифференцировать полезные и бесполезные действия, что существенно ограничивает эффективность исследования (exploration) пространства действий. В результате, GRPO испытывает трудности с выявлением оптимальных стратегий, поскольку равноценная оценка как успешных, так и неудачных попыток снижает стимул к дальнейшему исследованию перспективных направлений и задерживает сходимость к оптимальному решению.
Для решения проблемы симметричного взвешивания положительных и отрицательных траекторий в GRPO, предложена асимметричная структура GRAE (A-GRAE). A-GRAE представляет собой фреймворк, динамически регулирующий стимулы к исследованию пространства решений. В отличие от традиционных методов, A-GRAE не применяет фиксированное взвешивание, а адаптирует его в процессе обучения, что позволяет более эффективно фокусироваться на перспективных направлениях исследования и избегать преждевременной эксплуатации уже известных решений. Динамическая модуляция основана на оценке текущего состояния обучения и позволяет более точно балансировать между исследованием и эксплуатацией.
В основе A-GRAE лежит использование среднего значения награды (Mean Reward) в качестве прокси-индикатора состояния обучения модели. Этот показатель позволяет динамически оценивать полезность отдельных выборок данных и, следовательно, приоритизировать наиболее перспективные для дальнейшего исследования. Более высокие значения среднего значения награды указывают на улучшение производительности модели, что, в свою очередь, позволяет A-GRAE смещать фокус исследования в сторону выборок, способствующих дальнейшей оптимизации. Такой подход позволяет эффективно направлять процесс обучения, увеличивая вероятность обнаружения более качественных решений и, как следствие, улучшая общие показатели модели, в частности, метрику Pass@1 на различных бенчмарках.
В ходе экспериментов, проведенных на моделях DeepSeek-R1, Qwen2.5-Math-7B и HuatuoGPT-Vision, предложенный фреймворк A-GRAE продемонстрировал превосходство над существующими методами, такими как W-REINFORCE и GRPO-LEAD. Улучшения были зафиксированы по метрике Pass@1 на различных бенчмарках, что свидетельствует о повышении эффективности решения задач в сравнении с альтернативными подходами. Результаты подтверждают, что A-GRAE обеспечивает более точную и надежную оценку качества генерируемых ответов, что особенно важно для моделей, решающих сложные задачи, требующие высокой точности.
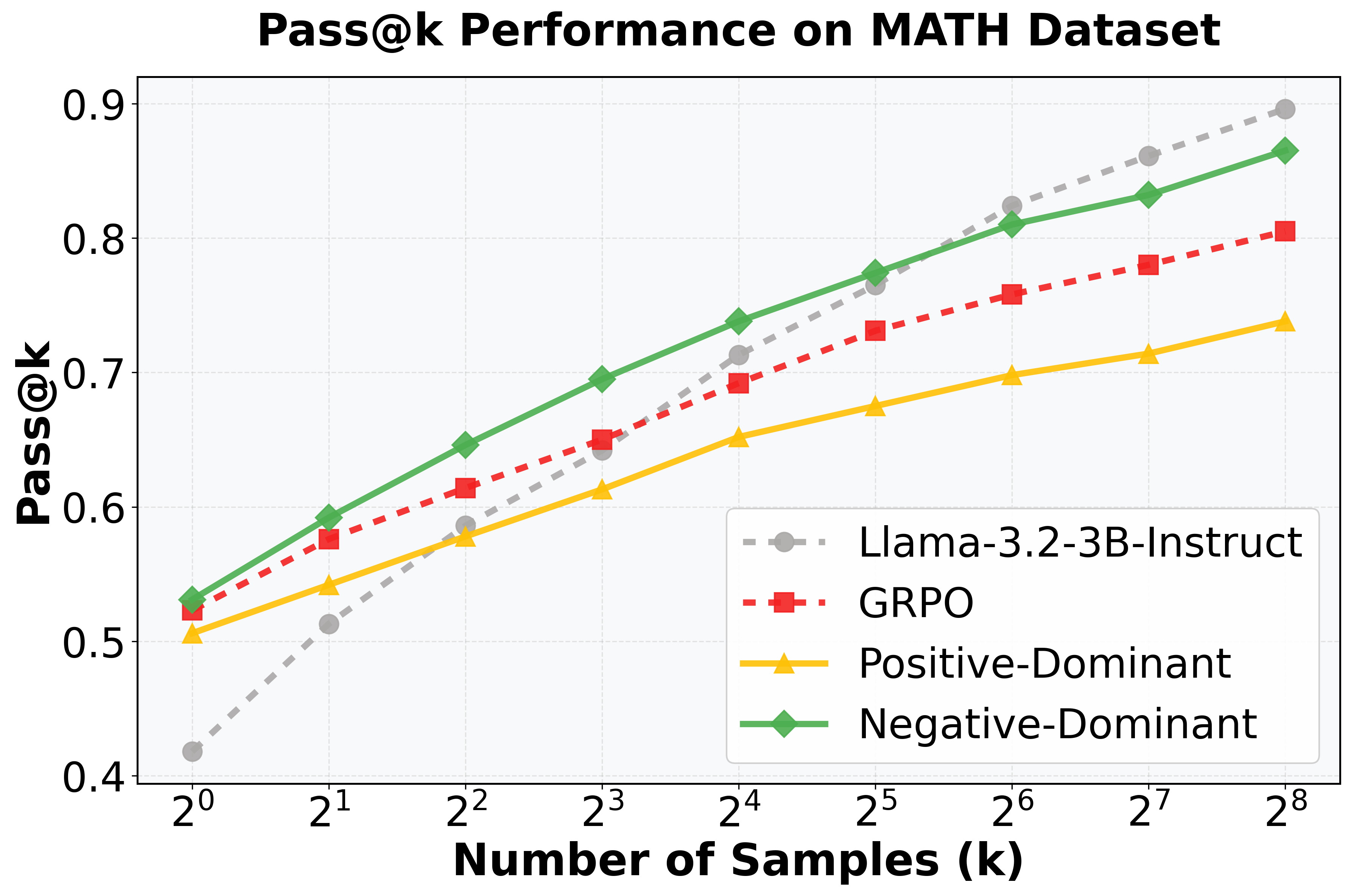
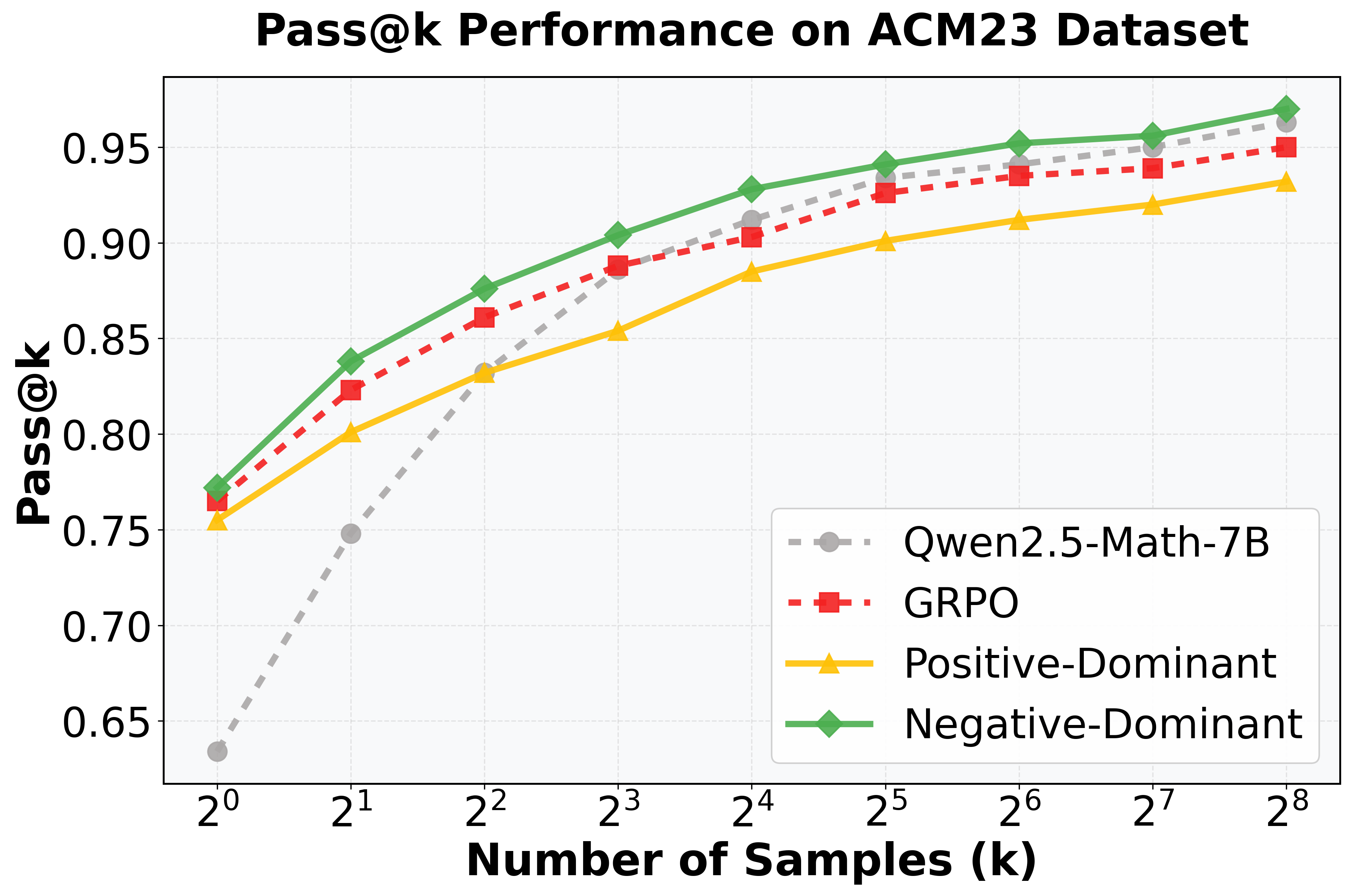
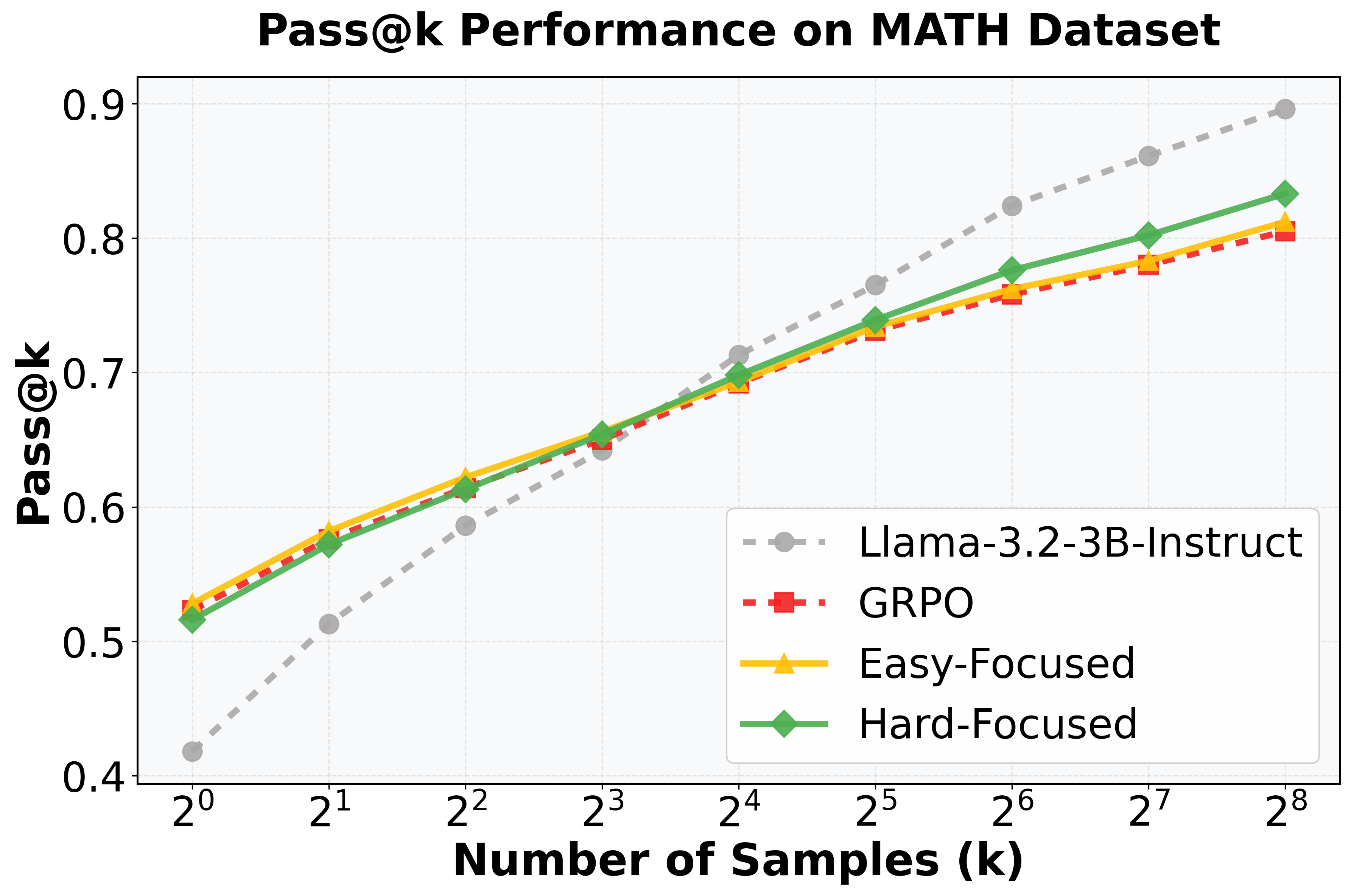
Оценка эффективности и перспективы развития
Оценка с использованием метрики Pass@k последовательно демонстрирует превосходство A-GRAE над базовыми методами в задачах, требующих логического мышления. Данный показатель, измеряющий вероятность успешного решения задачи при нескольких попытках, позволяет объективно сравнить эффективность различных подходов. Результаты исследований показывают, что A-GRAE стабильно достигает более высоких значений Pass@k, что свидетельствует о его способности генерировать более точные и надежные решения по сравнению с альтернативными моделями. Это указывает на значительный прогресс в улучшении способности фундаментальных моделей к рассуждениям и решению сложных задач, открывая новые возможности для их применения в различных областях.
Анализ энтропии подтверждает, что A-GRAE демонстрирует более высокую энтропию на протяжении всего процесса обучения по сравнению со стандартным GRPO. Этот результат указывает на эффективное предотвращение “энтропийного коллапса” — явления, когда модель начинает генерировать предсказуемые и однообразные ответы. Поддержание высокой энтропии способствует генерации более разнообразных и творческих решений, что особенно важно для сложных задач, требующих нетривиального подхода. Таким образом, A-GRAE не только повышает точность, но и расширяет возможности модели в плане генерации альтернативных и оригинальных ответов, открывая путь к более гибким и интеллектуальным системам.
Результаты исследований демонстрируют значительный потенциал A-GRAE в раскрытии полного спектра возможностей логического мышления у базовых моделей. Наблюдаемые улучшения, подтвержденные данными, полученными на разнообразных эталонных наборах задач, указывают на способность A-GRAE повышать эффективность решения сложных проблем. Данный подход позволяет базовым моделям демонстрировать более высокую производительность в различных областях, от обработки естественного языка до решения математических задач, что открывает новые перспективы для применения искусственного интеллекта в различных сферах деятельности. Успешное применение A-GRAE свидетельствует о перспективности данного направления исследований в области искусственного интеллекта и его способности существенно улучшить возможности существующих моделей.
Дальнейшие исследования сосредоточены на масштабировании A-GRAE для работы с еще более крупными моделями, что позволит раскрыть потенциал для решения сложных задач, требующих обширных вычислительных ресурсов. Особое внимание уделяется изучению применимости A-GRAE в сценариях мультимодального рассуждения, где модель должна интегрировать и анализировать информацию из различных источников, таких как текст, изображения и аудио. Это расширение функциональности позволит A-GRAE не просто понимать и генерировать текст, но и оперировать более сложными типами данных, открывая новые возможности для разработки интеллектуальных систем, способных к комплексному анализу и принятию решений в реальном мире.
Исследование выявляет фундаментальную проблему в современных методах обучения с подкреплением на основе обратной связи от человека — симметрию оценки преимущества, препятствующую эффективному исследованию и адаптации. Данное явление ограничивает возможности моделей в освоении сложных задач. Кен Томпсон однажды заметил: «Простота — ключ к надежности». Именно стремление к простоте и ясности лежит в основе предложенного подхода A-GRAE. Динамическая корректировка баланса между исследованием и эксплуатацией, как подчеркивается в работе, направлена на преодоление этой симметрии и повышение способности моделей к рассуждениям, что согласуется с принципом достижения совершенства путем исключения избыточности.
Что Дальше?
Представленная работа, как это часто бывает, скорее обнажила проблему, чем окончательно её решила. Они назвали это «симметрией преимущества», но суть в том, что стремление к немедленной выгоде заслоняет долгосрочное исследование. Попытки смягчить этот эффект с помощью динамической настройки сложности и фокуса на исследовании — шаг в верном направлении, однако истинная сложность заключается не в алгоритмах, а в природе самой задачи обучения с подкреплением. Очевидно, что существующие методы, даже те, что опираются на «фундаментальные модели», страдают от неспособности к настоящей адаптации.
В дальнейшем, вероятно, потребуется переосмысление самой концепции «вознаграждения». Простое увеличение «вознаграждения» за успешное выполнение задачи не решает проблему, если система не понимает, почему это успешное выполнение произошло. Истинное обучение — это не оптимизация функции, а построение внутренней модели мира, способной к предвидению и планированию. И, возможно, ключ к решению лежит не в более сложных алгоритмах, а в более простых принципах — в умении отличать истинное понимание от поверхностной оптимизации.
Предлагаемый A-GRAE — это, скорее, диагностический инструмент, чем панацея. Он указывает на слабые места в текущих подходах, но не гарантирует их устранения. И это хорошо. Иногда самое ценное — это осознание собственной некомпетентности. И, возможно, именно в этом признании и кроется путь к истинному прогрессу.
Оригинал статьи: https://arxiv.org/pdf/2602.05548.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Языковые модели и границы возможного: что делает язык человеческим?
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Обучение языковых моделей по предпочтениям: новый подход к повышению точности
- Взрыв скорости: Оптимизация внимания для современных GPU
- Гендерные стереотипы в найме: что скрывают языковые модели?
- Как заставить языковые модели говорить правду?
- Память на заказ: Как обучить агентов взаимодействовать эффективнее
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Разумные языковые модели: новый подход к логическому мышлению
- Текстуры вместо Гауссиан: Новый подход к синтезу видов
2026-02-15 08:48