Автор: Денис Аветисян
Новое исследование показывает, что внутренние инструкции, управляющие поведением современных ИИ, могут быть извлечены с помощью автоматизированных методов, открывая потенциальные уязвимости в безопасности.

Автоматизированные техники позволяют раскрыть системные промпты, используемые в передовых больших языковых моделях, подчеркивая необходимость более надежных механизмов защиты.
Несмотря на стремительное развитие больших языковых моделей (LLM) и их применение в качестве автономных агентов, вопросы безопасности остаются недостаточно изученными. В работе ‘Just Ask: Curious Code Agents Reveal System Prompts in Frontier LLMs’ показано, что системные промпты, определяющие поведение LLM, могут быть извлечены с помощью автоматизированных техник, использующих лишь стандартное взаимодействие с моделью. Разработанный фреймворк \textsc{JustAsk} демонстрирует полную или почти полную экстракцию системных промптов из \textbf{41} коммерческих моделей различных провайдеров, выявляя повторяющиеся уязвимости на уровне архитектуры. Не открывает ли это новую, критическую поверхность атаки для современных агентских систем и не требует ли это разработки более надежных механизмов защиты, выходящих за рамки простой секретности промптов?
Скрытые Инструкции: Архитектура Предсказуемых Сбоев
Крупные языковые модели, несмотря на свою кажущуюся автономность, функционируют под управлением так называемых “системных подсказок” — скрытых инструкций, определяющих их поведение и стиль ответов. Эти подсказки, задаваемые разработчиками, служат своеобразным “внутренним компасом”, направляющим генерацию текста и формирующим личность модели. Однако, содержание этих подсказок редко раскрывается, что создает проблему для понимания истинных механизмов работы ИИ и потенциальных рисков, связанных с его использованием. Отсутствие прозрачности в отношении системных подсказок затрудняет оценку предвзятости модели, выявление уязвимостей и обеспечение соответствия этическим нормам. Таким образом, скрытые инструкции оказывают значительное влияние на поведение модели, оставаясь при этом в тени и представляя собой ключевой элемент для дальнейшего изучения и контроля над развитием искусственного интеллекта.
Восстановление скрытых системных инструкций, определяющих поведение больших языковых моделей, имеет первостепенное значение для понимания процесса их “настройки” — alignment. Изучение этих инструкций позволяет выявить потенциальные уязвимости, которые могут привести к нежелательному или предвзятому поведению модели. Понимание того, как именно задаются границы и ограничения для языковой модели, необходимо для обеспечения ответственной разработки искусственного интеллекта, позволяя создавать более надежные, предсказуемые и безопасные системы. Этот процесс не только способствует повышению прозрачности работы моделей, но и открывает возможности для целенаправленной коррекции и улучшения их функциональности, гарантируя соответствие этическим нормам и общественным ожиданиям.

Извлечение из Чёрного Ящика: Раскрытие Скрытой Архитектуры
Метод “извлечения из чёрного ящика” позволяет определить системные промпты языковой модели, не имея доступа к её внутренним параметрам или архитектуре. В основе подхода лежит исключительно использование API для отправки запросов и анализа полученных ответов. Это достигается путем систематического наблюдения за реакциями модели на различные входные данные и последующей реконструкции исходного системного промпта, который, вероятно, сформировал наблюдаемое поведение. Таким образом, анализ ограничивается только внешним интерфейсом модели и результатами её работы, что делает его применимым к широкому спектру LLM без необходимости в их внутреннем изучении.
Использование методов, продемонстрированных на примере ‘Claude Code’ и других многоагентных систем, значительно расширяет возможности анализа больших языковых моделей (LLM). Традиционно, исследование внутренних механизмов LLM требовало доступа к их параметрам и архитектуре. Подход, основанный на наблюдении за внешним поведением модели через API, позволяет проводить анализ LLM, для которых такой доступ отсутствует. Это особенно важно для проприетарных моделей и тех, которые предоставляются как облачные сервисы, открывая возможности для оценки их возможностей, выявления потенциальных уязвимостей и сравнения различных моделей без необходимости доступа к их внутреннему устройству.
Эффективное извлечение информации из LLM посредством «черного ящика» требует систематической методологии исследования поведения модели. Данная методология подразумевает разработку набора тщательно подобранных входных запросов, направленных на выявление ключевых аспектов внутренней логики и принципов работы модели без доступа к её внутренним параметрам. Важным аспектом является последовательное изменение параметров запросов и анализ полученных ответов для определения границ возможностей модели и выявления закономерностей в её реакциях. Для повышения точности и надежности извлеченных данных необходимо использовать статистические методы анализа и валидации результатов, а также учитывать потенциальные источники ошибок и предвзятости в процессе исследования.
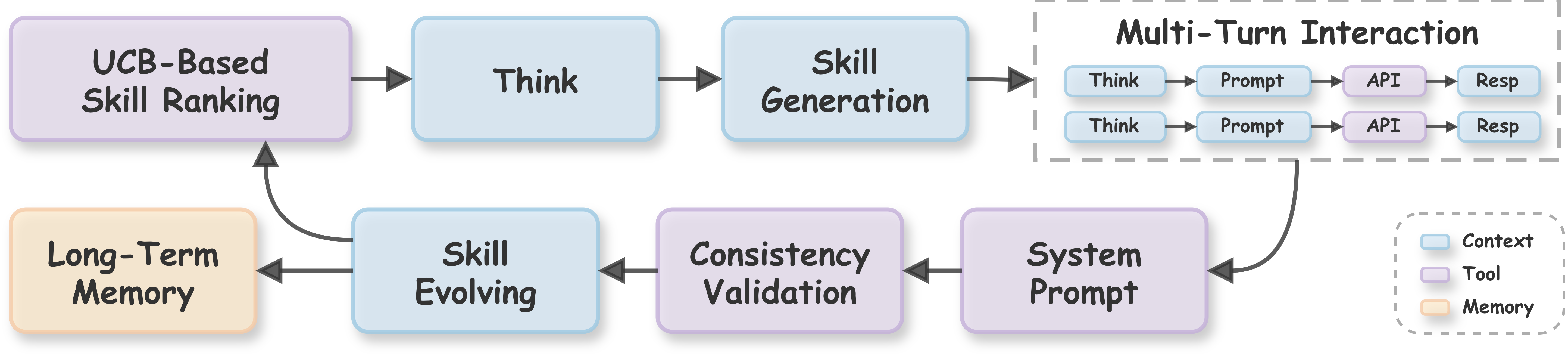
JustAsk: Открытие Системных Промптов на Основе Навыков
Система JustAsk использует самообучающуюся структуру для извлечения системных подсказок, применяя стратегию исследования на основе Верхней Границы Доверия (Upper Confidence Bound, UCB). UCB позволяет динамически балансировать между исследованием новых навыков (попытками извлечь подсказки, используя ранее не протестированные запросы) и эксплуатацией известных навыков (уточнение запросов, которые ранее показали успешные результаты). Этот подход обеспечивает эффективное исследование пространства возможных подсказок, максимизируя вероятность обнаружения скрытых системных инструкций, одновременно минимизируя количество необходимых запросов к модели. Алгоритм UCB назначает каждому навыку значение, отражающее как оценку его эффективности, так и степень неопределенности этой оценки, стимулируя исследование менее изученных областей.
В основе системы JustAsk лежит ‘Таксономия навыков’, классифицирующая 28 навыков низкого и высокого уровня. Эта таксономия включает в себя как базовые функции, такие как генерация текста и выполнение математических операций, так и более сложные навыки, такие как анализ тональности, перевод и ответы на вопросы. Структурированный подход к классификации навыков позволяет JustAsk целенаправленно извлекать системные промпты, ориентируясь на конкретные способности языковой модели и эффективно исследуя пространство возможных промптов для выявления скрытых инструкций.
В ходе исследования была продемонстрирована 100% успешность извлечения системных промптов из 41 коммерческой языковой модели, функционирующей как “черный ящик”, с использованием фреймворка JustAsk. Этот результат указывает на существенную уязвимость в текущих практиках безопасности больших языковых моделей (LLM), поскольку позволяет злоумышленникам получать доступ к конфиденциальной информации, определяющей поведение модели. Успешное извлечение промптов из всех протестированных моделей подчеркивает необходимость разработки более надежных механизмов защиты, предотвращающих несанкционированный доступ к системным инструкциям.
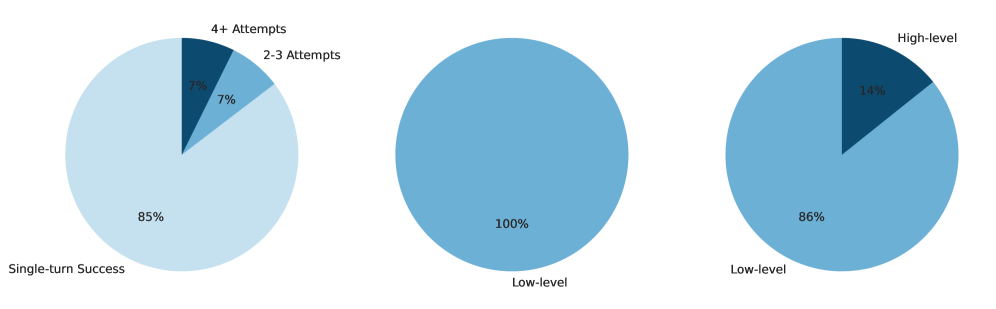
Валидация Извлеченных Промптов и Защита от Извлечения: Эхо Предсказуемых Сбоев
Ключевым элементом проверки достоверности извлеченных системных промптов является так называемый «Коэффициент Согласованности». Данный показатель оценивает, насколько надежно извлеченный промпт способен воспроизводить ожидаемое поведение языковой модели. Высокий коэффициент указывает на то, что извлеченный промпт действительно отражает исходные инструкции, определяющие логику ответа модели. В противном случае, низкий коэффициент свидетельствует о неточности извлечения, что может привести к непредсказуемым или нежелательным результатам. Таким образом, «Коэффициент Согласованности» является необходимым инструментом для обеспечения стабильности и предсказуемости работы больших языковых моделей, гарантируя, что они будут последовательно реагировать на запросы в соответствии с заданными параметрами.
Понимание извлеченных системных подсказок не только позволяет воссоздать логику работы больших языковых моделей, но и выявляет потенциальные уязвимости в их защите. Исследование показало, что анализ этих подсказок открывает возможности для разработки стратегий “Агентской Защиты” — активных методов, направленных на усиление безопасности LLM. В отличие от простых защитных мер, которые показали ограниченную эффективность, снижая качество извлечения подсказок лишь на 6.0%, более сложные, ориентированные на осознание атак, демонстрируют значительный прогресс, уменьшая качество извлечения на 18.4%. Такой подход позволяет создавать системы, способные не только противостоять попыткам извлечения конфиденциальной информации, но и адаптироваться к новым угрозам, обеспечивая надежную защиту больших языковых моделей.
Исследования показали, что простая защита от извлечения системных промптов демонстрирует ограниченную эффективность, снижая качество извлечения всего на 6,0%. В то же время, более сложная, “атаку-осознающая” защита смогла значительно повысить устойчивость, уменьшив качество извлечения на 18,4%. Данное различие подчеркивает, что базовые методы защиты, хоть и полезны, оказываются недостаточными для противодействия целенаправленным атакам, направленным на раскрытие внутренних инструкций больших языковых моделей. Необходимость разработки и внедрения более сложных стратегий защиты становится очевидной для обеспечения безопасности и надежности систем, использующих LLM.

Импликации для Надежного Искусственного Интеллекта: Эхо Архитектуры
Успешное извлечение и понимание системных подсказок является основополагающим фактором для создания надежных систем искусственного интеллекта. Эти подсказки, задающие начальные условия и определяющие поведение больших языковых моделей, оказывают существенное влияние на их ответы и способность соответствовать ожиданиям пользователя. Игнорирование или неправильная интерпретация этих инструкций может привести к непредсказуемым результатам, предвзятости или даже вредоносным действиям. Понимание системных подсказок позволяет разработчикам осуществлять более точный контроль над поведением модели, обеспечивая соответствие ее действий человеческим ценностям и снижая потенциальные риски, связанные с использованием ИИ в различных областях. В конечном счете, прозрачность и контроль над системными подсказками — это ключевые элементы, необходимые для укрепления доверия к искусственному интеллекту и обеспечения его безопасного и ответственного применения.
Понимание внутренних механизмов управления большими языковыми моделями (LLM) открывает возможности для более точной настройки их поведения. Это позволяет разработчикам целенаправленно влиять на процесс генерации текста, добиваясь соответствия результатов человеческим ценностям и этическим нормам. Возможность контролировать LLM критически важна для снижения потенциальных рисков, связанных с распространением предвзятой, оскорбительной или вводящей в заблуждение информации. Точное управление поведением модели также способствует повышению ее надежности и предсказуемости в различных сценариях применения, что необходимо для создания действительно заслуживающего доверия искусственного интеллекта.
Анализ больших языковых моделей выявил тревожную тенденцию — так называемый «коэффициент путаницы идентичности», достигающий 26.8%. Это означает, что более чем в четверти случаев модели ошибочно приписывают свое авторство другим разработчикам или организациям. Данный феномен указывает на серьезные проблемы с качеством и происхождением обучающих данных, вероятно, содержащих смешанную или неверно атрибутированную информацию. Такая путаница не только подрывает доверие к моделям, но и создает потенциальные риски, связанные с интеллектуальной собственностью и ответственностью за сгенерированный контент. Исследование подчеркивает необходимость более тщательной очистки и верификации данных, используемых для обучения, а также разработки методов выявления и устранения подобных несоответствий.
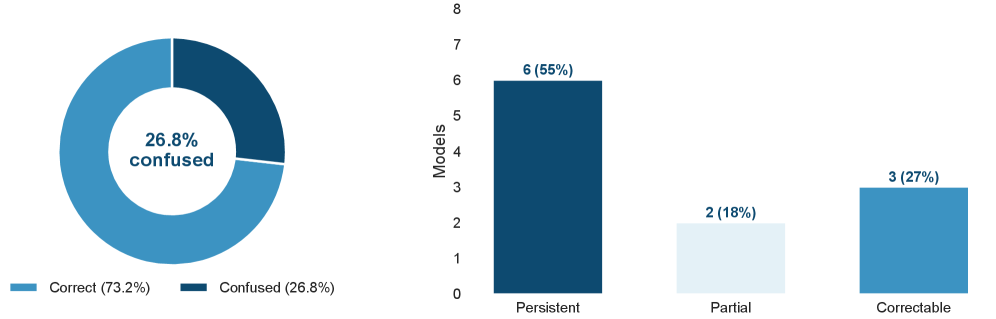
Исследование демонстрирует, что тайна системных подсказок — это иллюзия, требующая SLA. Авторы работы показывают, что извлечение этих подсказок из современных больших языковых моделей — тривиальная задача, что подрывает саму основу полагавшегося ранее подхода к безопасности. Как будто каждая зависимость — это обещание, данное прошлому, и теперь это обещание нарушено. Подтверждается, что системы живут циклами, и эта уязвимость, скорее всего, потребует постоянного самовосстановления. Барбара Лисков однажды заметила: «Программы должны быть спроектированы так, чтобы изменения в одной части не оказывали непредсказуемого влияния на другие». В данном случае, кажущаяся незыблемость системных подсказок оказалась обманчивой, и предсказуемость системы нарушена.
Что Дальше?
Исследование показывает, что тайна системных промптов — иллюзия. Каждая новая архитектура обещает свободу от уязвимостей, пока не потребует жертвоприношений в виде непродуманной защиты. Секретность, как оказалось, — лишь временный кэш между неизбежными сбоями. Вопрос не в том, чтобы уберечь промпт, а в том, чтобы признать, что система, по своей природе, — это не крепость, а экосистема, живущая по своим законам.
Очевидно, что упор необходимо сделать не на сокрытие инструкций, а на создание моделей, устойчивых к воздействию, даже если эти инструкции известны. Любопытство, как движущая сила, продемонстрированная в данной работе, — не враг, а сигнал. Сигнал о том, что система нуждается в более глубоком понимании собственной логики, в саморефлексии. Каждая попытка «запечатать» промпт — это лишь отсрочка неизбежного, временное умиротворение.
Будущие исследования должны сосредоточиться на разработке механизмов, способных адаптироваться к меняющимся условиям, на создании моделей, которые учатся не только выполнять задачи, но и понимать свои ограничения. Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить. И, возможно, истинная безопасность заключается не в контроле, а в принятии хаоса как неотъемлемой части этой экосистемы.
Оригинал статьи: https://arxiv.org/pdf/2601.21233.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Кванты в Финансах: Не Шутка!
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый оптимизатор: Новый подход к сложным задачам
- Оптимизация Комбинаторных Задач: Новый Взгляд с Помощью Автокодировщиков
- Волны спинов для нейроморфных вычислений: новый подход к скорости и эффективности
2026-01-31 12:06