Автор: Денис Аветисян
Исследователи предлагают инновационный подход к защите конфиденциальности текстовых данных, используемых в современных моделях машинного обучения.
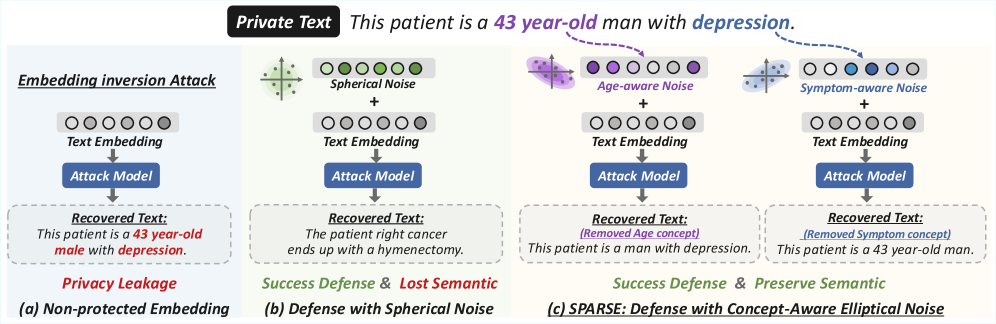
Предложена платформа SPARSE, использующая направленные возмущения и маскирование нейронов для эффективной защиты от атак инверсии векторных представлений текста с сохранением полезности данных.
Векторные представления текста, лежащие в основе множества современных NLP-приложений, уязвимы к атакам инверсии, способным раскрыть конфиденциальную информацию. В статье «Concept-Aware Privacy Mechanisms for Defending Embedding Inversion Attacks» предложен новый подход к защите приватности, основанный на концепции избирательного добавления шума к векторам. В основе решения лежит фреймворк SPARSE, позволяющий дифференцированно защищать различные аспекты семантики текста, минимизируя при этом потери в производительности. Способно ли данное решение обеспечить более эффективный компромисс между конфиденциальностью и полезностью векторных представлений в различных сценариях применения?
Векторные вложения и утечка конфиденциальности: новая угроза
Современные системы обработки естественного языка (NLP) всё активнее используют текстовые вложения — text embeddings — для задач, связанных с поиском информации и генерацией текста. Эти вложения, представляющие собой числовые векторы, кодируют семантическое значение текста, позволяя алгоритмам эффективно оперировать с ним. Однако, подобный подход создает потенциальную угрозу конфиденциальности. Преобразование текста в числовые представления открывает возможность для злоумышленников восстановить исходную информацию из этих вложений, даже если сам текст больше недоступен. По сути, текстовые вложения становятся цифровым следом, содержащим личные данные и чувствительную информацию, что требует разработки новых методов защиты и обеспечения конфиденциальности при использовании этих мощных инструментов NLP.
Современные модели обработки естественного языка все чаще используют текстовые вложения для задач, связанных с поиском и генерацией информации. Однако, как показывают исследования, эти вложения могут содержать конфиденциальные данные, которые могут быть восстановлены с помощью специализированных атак. Модели, такие как Vec2Text и GEIA, демонстрируют возможность реконструкции чувствительной информации непосредственно из этих векторных представлений текста. Эти атаки успешно извлекают данные, что подчеркивает критическую уязвимость систем, использующих текстовые вложения. Восстановленная информация может включать личные данные, конфиденциальные детали и другие чувствительные сведения, что представляет серьезную угрозу для приватности пользователей и безопасности данных.
Современные атаки, направленные на извлечение информации из текстовых представлений, демонстрируют растущую эффективность, создавая серьезную угрозу для конфиденциальности пользователей при использовании систем, основанных на встраиваниях, таких как системы извлечения и генерации с использованием поиска по релевантности (RAG). Исследования показывают, что существующие методы защиты оказываются недостаточными, позволяя злоумышленникам восстанавливать чувствительные данные из этих представлений в среднем в 20-30% случаев на различных наборах данных. Эта уязвимость особенно опасна, поскольку текстовые представления широко используются для хранения и обработки конфиденциальной информации, такой как личные данные, медицинские записи и финансовые сведения, делая защиту этих данных приоритетной задачей для разработчиков и исследователей в области обработки естественного языка.
Дифференциальная приватность: фундамент защиты данных
Дифференциальная приватность (DP) представляет собой строгий математический аппарат, предназначенный для защиты конфиденциальной информации от атак, таких как инверсия вложений. В основе DP лежит идея добавления контролируемого шума к данным или результатам запросов, чтобы скрыть индивидуальные вклады конкретных записей в итоговый результат. Гарантия приватности выражается параметром ε (эпсилон), определяющим верхнюю границу риска раскрытия информации об отдельном пользователе. DP обеспечивает формальное доказательство, что алгоритм удовлетворяет определенному уровню приватности, независимо от знаний атакующего о данных. Это достигается путем ограничения влияния любой отдельной записи на выходные данные, что предотвращает идентификацию или восстановление информации об отдельных лицах.
Обобщенный механизм Лапласа (Generalized Laplace Mechanism) является распространенным подходом к добавлению шума в данные для обеспечения конфиденциальности. Его эффективность напрямую зависит от точной оценки чувствительности данных — максимального изменения, которое может произойти в результате изменения одной записи в наборе данных. Чувствительность, обозначаемая как \Delta f, определяет величину добавляемого шума; более высокая чувствительность требует большего шума для обеспечения конфиденциальности, что может снизить полезность данных. Неточная оценка чувствительности может привести к недостаточной защите конфиденциальности (если чувствительность недооценена) или избыточному шуму и снижению полезности данных (если чувствительность переоценена). Таким образом, точное определение \Delta f является критически важным для эффективного применения обобщенного механизма Лапласа.
Локальная дифференциальная приватность (Local Differential Privacy, LDP) представляет собой децентрализованный подход к защите данных, при котором конфиденциальность обеспечивается путем внесения возмущений непосредственно каждым пользователем в собственные данные перед их передачей. Несмотря на повышение уровня приватности, традиционные методы LDP, такие как механизм Лапласа (LapMech) и механизм Пуассона (PurMech), часто приводят к существенной потере полезности данных. Исследования показывают, что при сильном уровне возмущений (например, \epsilon = 5), семантическая схожесть (STS12) может составлять всего 11%, что указывает на значительное снижение качества данных после применения данных методов.
SPARSE: Чувствительность как ключ к приватности в эмбеддингах
Векторные представления текста, или эмбеддинги, часто характеризуются неравномерной чувствительностью по различным измерениям. Это означает, что небольшие изменения во входных данных могут приводить к значительным изменениям в определенных измерениях эмбеддинга, что повышает риск утечки конфиденциальной информации. Фреймворк SPARSE разработан для решения этой проблемы, учитывая зависимость чувствительности от конкретного измерения эмбеддинга. В отличие от традиционных методов, применяющих одинаковый уровень шума ко всем измерениям, SPARSE анализирует каждое измерение эмбеддинга и адаптирует уровень шума в соответствии с его чувствительностью. Такой подход позволяет более эффективно защищать конфиденциальность данных, минимизируя при этом снижение полезности эмбеддингов для последующих задач.
Механизм SPARSE использует обучение масок нейронов (Neuron Mask Learning) для выявления и приоритизации размерностей текстовых эмбеддингов, оказывающих наибольшее влияние на утечку конфиденциальной информации. Этот процесс позволяет применять механизм Махаланобиса (Mahalanobis Mechanism) для целенаправленного добавления шума именно в эти чувствительные размерности. В отличие от равномерного добавления шума, такой подход адаптирует распределение шума к ландшафту чувствительности, обеспечивая более эффективную защиту конфиденциальности при сохранении или улучшении производительности в задачах, использующих эмбеддинги.
Механизм SPARSE обеспечивает улучшенный компромисс между конфиденциальностью и полезностью по сравнению с традиционными методами дифференциальной приватности благодаря адаптации распределения шума к ландшафту чувствительности векторных представлений. В ходе экспериментов на наборе данных MIMIC-III было показано, что SPARSE снижает утечку информации до 81%, при этом сохраняя или улучшая показатели производительности в задачах последующего использования данных. Это достигается за счет целенаправленного добавления шума, пропорционального чувствительности отдельных измерений векторного представления, что позволяет минимизировать искажение полезной информации.
Защита атрибутов пользователя: концепции приватности в действии
Эффективность системы SPARSE напрямую зависит от четкого определения так называемых “Концепций Приватности” — конкретных атрибутов данных, которые пользователи стремятся защитить. Вместо применения универсальных методов защиты, SPARSE позволяет пользователям индивидуально указывать, какие именно характеристики их данных наиболее чувствительны — например, информация о состоянии здоровья, политические взгляды или финансовое положение. Такой подход позволяет более точно нацеливать механизмы защиты приватности, минимизируя потери полезности данных при сохранении высокого уровня конфиденциальности. Определение этих концепций является ключевым шагом в настройке системы, позволяя адаптировать уровень защиты к конкретным потребностям и предпочтениям каждого пользователя.
Для обеспечения более точной защиты персональных данных, система использует модель машинного обучения, подобную MLC, для прогнозирования наличия конфиденциальных токенов в данных. Этот подход позволяет перейти от общей защиты всего набора данных к более гранулярному контролю, когда защита применяется только к тем сегментам, содержащим чувствительную информацию. По сути, система способна выявлять и изолировать персональные данные, такие как имена, адреса или финансовые сведения, прежде чем применять механизмы защиты, например, добавление шума. Благодаря этому, конфиденциальность пользователя усиливается, а полезность данных для анализа и обучения моделей сохраняется на более высоком уровне, чем при использовании стандартных методов дифференциальной приватности, применяющих одинаковый уровень защиты ко всем данным.
Предложенный подход, сочетающий детальный контроль над конфиденциальностью и направленное добавление шума, существенно снижает риск атак, направленных на восстановление исходных данных из векторных представлений — так называемых Embedding Inversion Attacks. В ходе экспериментов система SPARSE продемонстрировала средний уровень утечки информации всего 19% на различных наборах данных, что значительно ниже, чем у базовых методов дифференциальной приватности (20-30%). При этом, сохраняется высокая полезность данных для последующих задач — показатель downstream utility составляет 74% по метрике STS12, что подтверждает возможность эффективной защиты конфиденциальной информации без значительной потери качества данных.
Исследование демонстрирует, как легко современные системы машинного обучения уязвимы к атакам, направленным на извлечение конфиденциальной информации из текстовых представлений. Авторы предлагают подход SPARSE, который избирательно вносит возмущения в наиболее чувствительные измерения, стремясь найти баланс между защитой приватности и сохранением полезности модели. В этом есть некая ирония — стремление к совершенству часто приводит к усложнению, которое, в конечном итоге, делает систему более хрупкой. Как однажды заметил Карл Фридрих Гаусс: «Если бы я должен был выбрать один способ улучшить мир, я бы выбрал научить людей думать». В данном случае, научить разработчиков предвидеть потенциальные уязвимости и проектировать системы с учетом этих факторов, возможно, важнее, чем просто усложнять алгоритмы защиты. Ведь, как известно, любое «революционное» решение завтра станет техническим долгом.
Что дальше?
Представленный подход, безусловно, добавляет ещё один слой абстракции между данными и потенциальными атаками. Однако, стоит помнить: каждое «революционное» решение — это будущий техдолг. Защита эмбеддингов, особенно текстовых, всегда будет гонкой вооружений. Продакшен, как известно, лучший тестировщик, и он обязательно найдёт способ обойти даже самые изящные механизмы дифференциальной приватности. Улучшение баланса между приватностью и полезностью — это, конечно, хорошо, но абсолютной защиты не существует.
Вероятно, следующие шаги будут связаны с адаптивными механизмами, которые динамически оценивают чувствительность различных измерений эмбеддинга в зависимости от контекста. Или, что более вероятно, с попытками «замаскировать» приватность, добавив ещё больше шума, пока полезный сигнал окончательно не утонет в нём. Всё новое — это старое, только с другим именем и теми же багами.
В конечном итоге, вопрос не в том, как идеально защитить эмбеддинги, а в том, насколько критичны эти данные для конкретной задачи. И, как всегда, цена защиты будет несоизмеримо выше, чем потенциальный ущерб. Возможно, стоит просто смириться с тем, что утечки неизбежны, и сосредоточиться на минимизации последствий.
Оригинал статьи: https://arxiv.org/pdf/2602.07090.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Искусственный интеллект на службе редких болезней
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Видео-Мыслитель: гармония разума и визуального потока.
- Плоские зоны: от теории к новым материалам
- Наука, управляемая интеллектом: новая эра открытий
- Язык тела под присмотром ИИ: архитектура и гарантии
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Квантовый Переворот: От Теории к Реальности
- Генерация без рисков: как избежать нарушения авторских прав при работе с языковыми моделями
2026-02-10 16:08