Автор: Денис Аветисян
Новое исследование показывает, что оценка способностей больших языковых моделей к решению задач олимпиадного программирования требует четкого разделения этапов логического мышления и написания кода.
Оценка языковых моделей выявила, что основная сложность заключается не в реализации алгоритма, а в его правильном построении.
Существующие оценки больших языковых моделей (LLM) в области спортивного программирования зачастую не разделяют этапы логического рассуждения и непосредственной генерации кода. В работе ‘Idea First, Code Later: Disentangling Problem Solving from Code Generation in Evaluating LLMs for Competitive Programming’ авторы утверждают, что спортивное программирование — это прежде всего задача решения проблем, и предлагают сосредоточиться на использовании и оценке решений в форме текстовых разборов. Полученные результаты показывают, что модели испытывают больше трудностей с формулировкой корректного алгоритма, чем с его реализацией, а разрыв между сгенерированными и эталонными разборами указывает на существенные ограничения в способности к логическому мышлению. Не является ли, следовательно, разделение оценки навыков решения проблем и навыков кодирования ключевым шагом к созданию более объективных и информативных бенчмарков для LLM?
Пророчество Алгоритмической Сложности
Несмотря на впечатляющую способность больших языковых моделей распознавать закономерности, истинное решение алгоритмических задач требует гораздо большего, чем просто поверхностное понимание. Эти модели успешно оперируют с данными, выявляя статистические связи, однако сталкиваются с трудностями при необходимости последовательного, логически обоснованного выполнения шагов для достижения конкретного результата. В отличие от человека, способного к абстрактному мышлению и построению алгоритмов «с нуля», языковые модели часто полагаются на ранее увиденные примеры, что ограничивает их способность к решению принципиально новых или сложных задач, требующих творческого подхода и глубокого понимания принципов работы алгоритмов. Таким образом, способность к решению алгоритмических задач является индикатором не просто обработки информации, но и истинного понимания логики и принципов вычислений.
Современные методы искусственного интеллекта, несмотря на значительные успехи в обработке естественного языка, часто испытывают трудности при решении сложных задач, требующих последовательного логического мышления и точной генерации кода. Проблема заключается не только в понимании условий задачи, но и в способности разбить её на отдельные, последовательные шаги, каждый из которых должен быть реализован в виде корректного и эффективного кода. Ошибки на любом из этапов, будь то неправильное понимание логики или синтаксическая неточность в коде, приводят к неработоспособности решения. Таким образом, для достижения успеха в решении подобных задач необходимы не просто большие объемы данных для обучения, но и новые архитектуры и алгоритмы, способные эмулировать человеческую способность к декомпозиции проблем и построению логических цепочек.
Соревновательное программирование, представляющее собой строгий тест на навыки алгоритмического мышления и точной реализации, по-прежнему является серьезным вызовом для современных языковых моделей. Несмотря на впечатляющие успехи в обработке естественного языка и распознавании образов, способность последовательно и эффективно решать сложные алгоритмические задачи, требующие четкого планирования и безупречного кодирования, остается ограниченной. Текущие модели часто демонстрируют недостаточную производительность в этих соревнованиях, уступая даже опытным программистам-любителям, что указывает на необходимость дальнейших исследований в области надежного и эффективного алгоритмического рассуждения.
Редактирование Решения: Введение Промежуточного Рассуждения
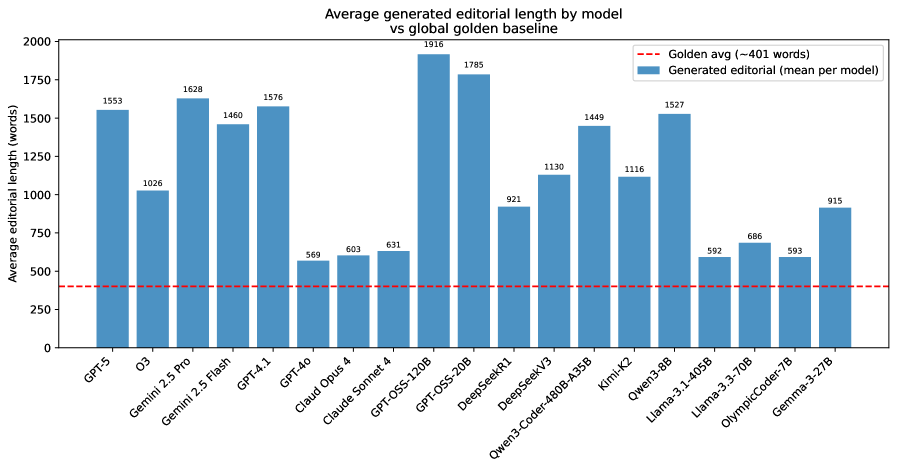
Предлагаемый подход, ориентированный на создание «редакционного материала», предполагает, что модель искусственного интеллекта сначала генерирует текст на естественном языке, объясняющий решение задачи, прежде чем приступить к написанию кода. Этот «редакционный материал» представляет собой промежуточный артефакт, в котором модель последовательно излагает логику решения, что позволяет отделить этап рассуждений от этапа реализации. Фактически, модель сначала формулирует алгоритм в виде текста, а затем преобразует это текстовое описание в исполняемый код, обеспечивая более контролируемый и интерпретируемый процесс.
Предлагаемый подход использует промежуточный артефакт — текстовое объяснение решения задачи — для повышения уровня понимания проблемы моделью. Этот текст, генерируемый перед написанием кода, вынуждает модель явно формулировать логику решения, что способствует более глубокому анализу условий задачи и требований к результату. В процессе генерации этого объяснения модель вынуждена структурировать свои знания и выстраивать последовательность действий, необходимых для решения, что позволяет ей более точно интерпретировать входные данные и определить оптимальный алгоритм. По сути, это создает этап предварительной обработки информации, улучшающий способность модели к решению сложных задач.
Явное описание алгоритма в рамках предварительного «редакционного» текста повышает корректность и точность генерируемого кода. Это достигается за счет того, что модель вынуждена структурировать логику решения задачи перед непосредственной генерацией кода, что минимизирует ошибки, связанные с неверной интерпретацией условий или логических связей. Такой подход позволяет преодолеть разрыв между этапом рассуждения и этапом реализации, обеспечивая более надежное соответствие кода поставленной задаче и снижая вероятность логических ошибок в конечном результате.
Строгая Оценка: Бенчмаркинг Редакционно-Ориентированного Подхода
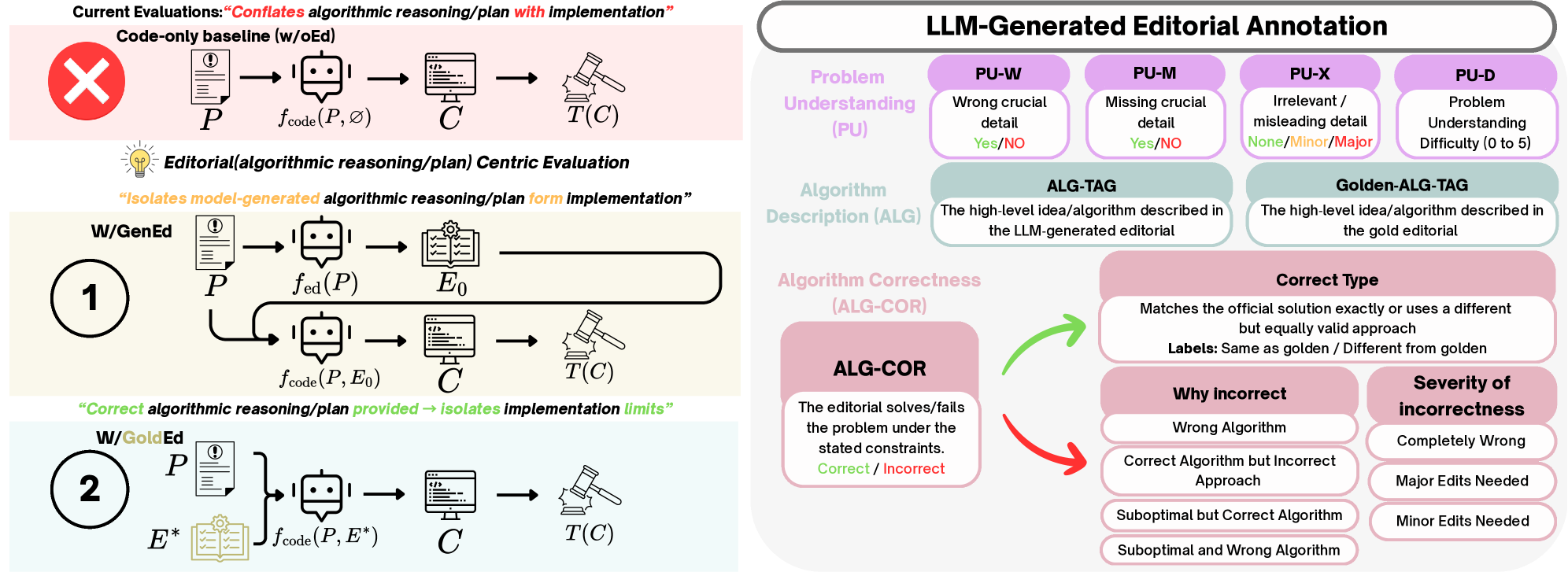
Для оценки различных подходов к генерации кода были проведены сравнительные тесты в трех различных конфигурациях. Первая, ‘w/oEd’, представляла собой прямую генерацию кода без использования каких-либо дополнительных инструкций или описаний. Вторая конфигурация, ‘w/GoldEd’, предполагала генерацию кода на основе предоставленного “золотого” (идеального) описания задачи. Третья конфигурация, ‘w/GenEd’, включала в себя сначала генерацию описания задачи языковой моделью, а затем генерацию кода на основе сгенерированного описания. Такая методология позволила оценить влияние качества описания задачи на итоговый результат и выявить преимущества использования предварительно сгенерированного или предоставленного описания перед прямой генерацией кода.
Методология “Оценки, ориентированной на редакционные материалы” (Editorial-Centric Evaluation) предполагает комплексную оценку, охватывающую как качество сгенерированного редакционного текста (решения задачи, представленного в текстовом формате), так и качество кода, полученного на его основе. Оценка качества редакционного текста осуществляется с использованием подхода “LLM-as-a-Judge” — другой большой языковой модели, выступающей в роли эксперта. Этот подход позволяет оценить логичность, полноту и ясность объяснения, содержащегося в редакторском тексте, а также его соответствие условиям задачи, что в совокупности позволяет оценить качество всей цепочки генерации — от решения задачи до его программной реализации.
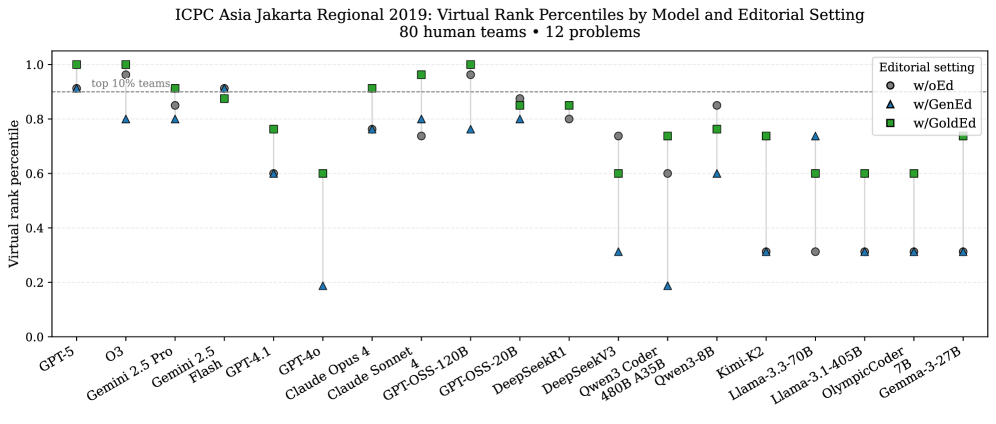
Результаты экспериментов демонстрируют значительное повышение производительности при предварительной генерации редакторского решения, измеряемое метрикой ‘Pass@1’. Использование золотых (заданных заранее) редакторских решений обеспечивает существенный прирост по сравнению с редакторскими решениями, сгенерированными моделью. Однако, даже при использовании золотых редакторских решений, сохраняется значительный “разрыв в реализации” (Implementation Gap) — доля успешно пройденных тестов составляет приблизительно 16.5% на задачах повышенной сложности (T3). Это указывает на то, что даже наличие корректного редакторского решения не гарантирует успешную генерацию работоспособного кода для сложных задач.
Раскрытие Потенциала: Перенос Знаний и Адаптивные Решения
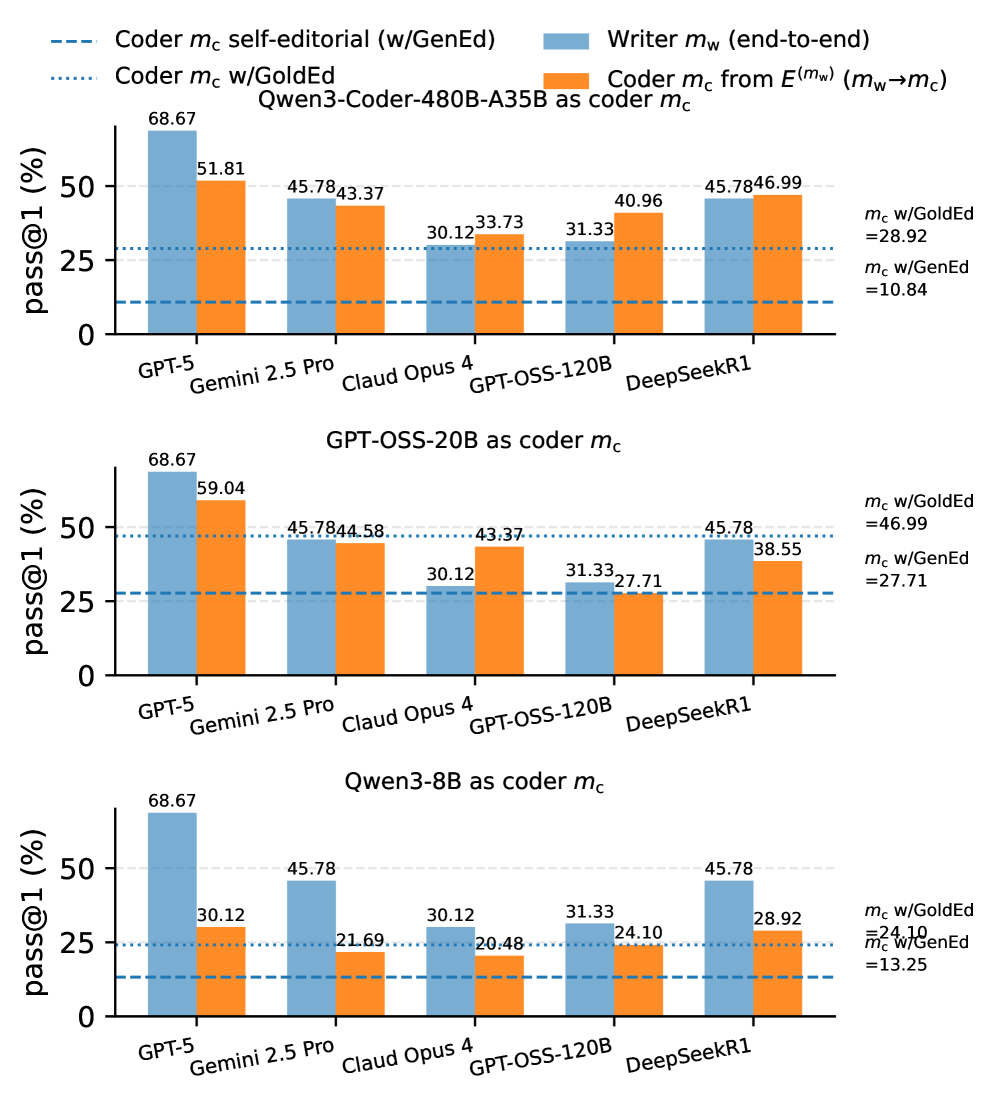
Исследование демонстрирует концепцию “трансфера редакционных материалов между моделями”, в рамках которой объяснения, сгенерированные одной моделью искусственного интеллекта, способны значительно улучшить производительность другой. Этот подход указывает на возможность повторного использования навыков рассуждения и логического анализа, позволяя моделям учиться на опыте и объяснениях своих аналогов. По сути, это создает систему, где знания, выраженные в форме редакционных материалов, становятся переносимыми активами, повышающими эффективность и точность различных алгоритмов. Данный механизм открывает перспективы для создания более эффективных и адаптивных систем искусственного интеллекта, способных к коллективному обучению и совершенствованию.
Исследования демонстрируют, что современные модели искусственного интеллекта способны к обучению на основе объяснений, генерируемых другими моделями, что открывает новые возможности для совместной и эффективной работы. Вместо традиционного обучения на больших объемах данных, модели могут извлекать знания из рассуждений, представленных в объяснениях, создаваемых их «коллегами». Этот подход позволяет не только ускорить процесс обучения, но и повысить качество получаемых решений, поскольку модели перенимают лучшие практики и избегают повторения ошибок. По сути, наблюдается своего рода «коллегиальное обучение», где каждая модель вносит свой вклад в общее знание, что значительно превосходит возможности изолированного обучения и ведет к созданию более надежных и адаптивных систем.
В ходе исследования было показано, что интеграция обратной связи, полученной в процессе тестирования, в алгоритм генерации пояснений к коду, существенно улучшает качество рассуждений и, как следствие, повышает надежность генерируемого программного обеспечения. Внедрение этой обратной связи позволяет модели самокорректироваться и уточнять логику решения задач непосредственно в процессе работы. Эксперименты продемонстрировали значительное увеличение показателя Pass@1, который отражает долю корректно сгенерированных решений с первой попытки, что свидетельствует о повышении эффективности и точности алгоритма благодаря использованию тестовой обратной связи.
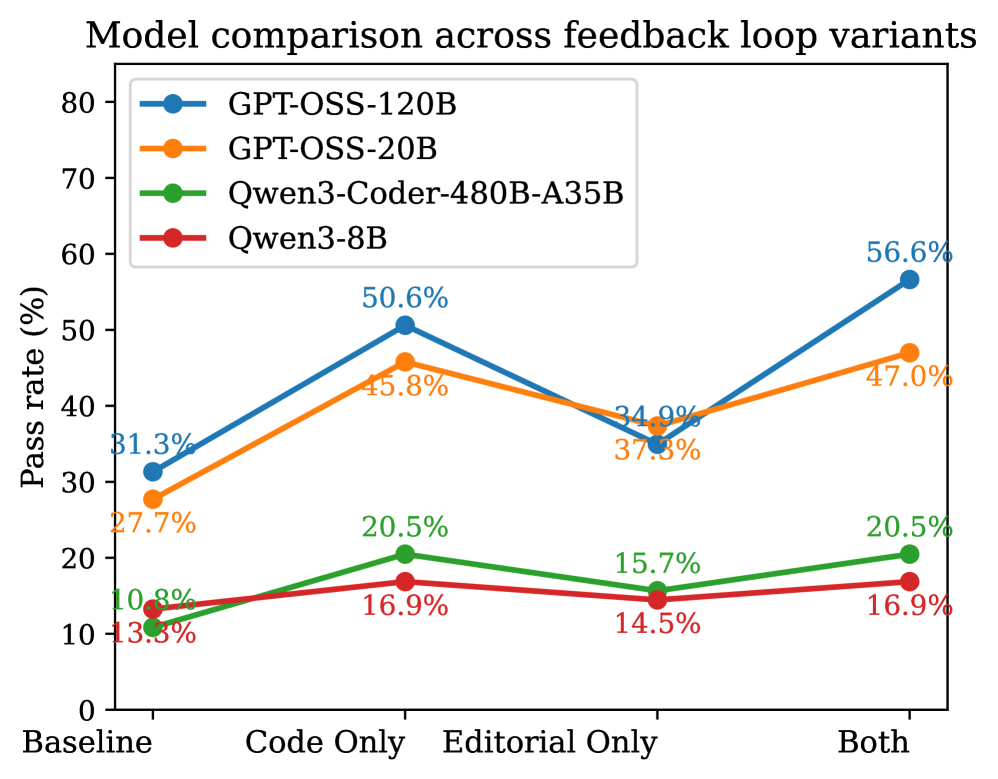
Исследование показывает, что современные языковые модели испытывают затруднения не столько в непосредственной генерации кода, сколько в понимании сути алгоритмической задачи. Это напоминает о мудрости Дональда Кнута: «Прежде чем оптимизировать код, убедитесь, что он работает». Ведь прежде чем создать эффективное решение, необходимо глубоко осмыслить проблему. Попытки оценить модели, не разделяя этап решения задачи и этап реализации, подобны попытке оценить рост дерева, не учитывая качество почвы. Данная работа подчеркивает, что истинный прогресс в области алгоритмического программирования требует от моделей не просто умения писать код, а способности к логическому мышлению и пониманию принципов работы алгоритмов.
Куда Ведет Дорога?
Представленная работа не столько решает проблему оценки больших языковых моделей в соревновательном программировании, сколько обнажает её истинный масштаб. Разделение способности к алгоритмическому мышлению — зафиксированной в редакционных решениях — и собственно генерации кода оказывается не просто техническим уточнением, а философским прозрением. Системы, как выясняется, способны имитировать процесс кодирования, но не способны к подлинному пониманию, к творческому преодолению алгоритмических барьеров. И это не недостаток реализации, а закономерность — ведь системы не строятся, а вырастают, и каждый архитектурный выбор — это пророчество о будущем сбое.
Очевидно, что оценка моделей, основанная лишь на успешности прохождения тестов, упускает ключевой аспект — качество самого решения. Если система молчит, значит, она готовит сюрприз, а если она генерирует работающий код, это ещё не значит, что она понимает, что делает. Следующим шагом видится не улучшение алгоритмов генерации кода, а разработка метрик, способных оценивать глубину и оригинальность алгоритмического мышления, зафиксированного в редакционных решениях. Когда спрашивают, когда закончится отладка, можно лишь шепнуть: никогда — просто мы перестанем смотреть.
В конечном счете, исследование указывает на необходимость переосмысления самой концепции “интеллекта” в контексте искусственных систем. Ведь система — это не инструмент, а экосистема, и её развитие подчиняется не логике проектирования, а непредсказуемым законам самоорганизации. И чем больше мы стремимся к созданию “идеального” алгоритма, тем дальше уходим от понимания того, что подлинный интеллект — это не способность решать задачи, а способность создавать новые.
Оригинал статьи: https://arxiv.org/pdf/2601.11332.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовый Переход: Пора Заботиться о Криптографии
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая обработка данных: новый подход к повышению точности моделей
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая криптография: от теории к практике
- Лунный гелий-3: Охлаждение квантового будущего
2026-01-20 20:24