Автор: Денис Аветисян
Исследователи предлагают инновационную методику обучения, позволяющую искусственному интеллекту сначала оценивать корректность ответов, а затем уже генерировать их, повышая качество и эффективность рассуждений.
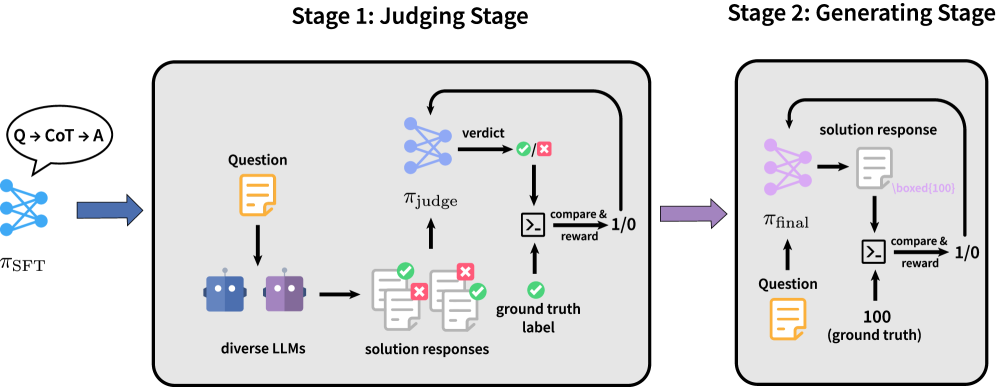
В статье представлена парадигма JudgeRLVR, двухэтапный процесс обучения, улучшающий логическое мышление больших языковых моделей с помощью обучения с подкреплением и верифицируемыми наградами.
Оптимизация больших языковых моделей для рассуждений часто приводит к избыточной детализации и неэффективному поиску решений. В данной работе, ‘JudgeRLVR: Judge First, Generate Second for Efficient Reasoning’, предложен новый двухэтапный подход, JudgeRLVR, который сначала обучает модель оценивать правильность решений, а затем генерировать их. Эксперименты показали, что JudgeRLVR обеспечивает значительное улучшение баланса между качеством и эффективностью рассуждений, повышая точность и сокращая длину генерируемых ответов. Возможно ли дальнейшее повышение эффективности и обобщающей способности моделей за счет более глубокой интеграции этапов оценки и генерации?
Вызов Глубокого Рассуждения в Больших Языковых Моделях
Несмотря на впечатляющую способность генерировать текст и понимать язык, большие языковые модели часто сталкиваются с трудностями при решении сложных задач, требующих последовательного рассуждения. В отличие от простых вопросов, где ответ может быть найден непосредственно в данных обучения, многоступенчатые проблемы требуют от модели не просто извлечения информации, но и ее логической обработки, планирования и проверки. В результате, даже самые современные модели могут допускать ошибки на этапах рассуждения, приводя к неточным или неполным решениям, особенно когда задача требует учета множества взаимосвязанных факторов и проведения промежуточных выводов. Эта особенность ограничивает их применение в областях, где критически важна надежность и точность, таких как научные исследования, диагностика и финансовый анализ.
Традиционные методы обучения больших языковых моделей, несмотря на использование огромных объемов данных, зачастую сосредотачиваются на предсказании следующего слова, а не на развитии способности к последовательному, логическому мышлению. В результате, модели демонстрируют впечатляющую способность к генерации текста, но испытывают трудности в решении задач, требующих многоступенчатого рассуждения и анализа. Обучение, основанное исключительно на статистических закономерностях в данных, не позволяет модели осознанно строить и оценивать цепочку логических шагов, необходимых для получения правильного ответа. Вместо явного вознаграждения за корректный процесс рассуждения, модели оптимизируются для достижения статистической правдоподобности, что может приводить к кажущейся логичности, скрывающей фактические ошибки в рассуждениях.
Непосредственный контроль над траекториями рассуждений в больших языковых моделях представляет собой существенную проблему, создающую узкое место в улучшении их производительности при решении сложных задач. Традиционные методы обучения, ориентированные на предсказание следующего токена, не позволяют эффективно оценивать и корректировать последовательность логических шагов, необходимых для получения верного ответа. В отличие от обучения с подкреплением, где вознаграждение дается за конечный результат, здесь требуется детальная оценка каждого промежуточного этапа рассуждений, что значительно усложняет процесс обучения и требует разработки новых, более тонких механизмов обратной связи. Отсутствие возможности эффективно контролировать логическую цепочку приводит к тому, что модели часто допускают ошибки не из-за недостатка знаний, а из-за неправильной организации мыслительного процесса, что ограничивает их способность решать задачи, требующие глубокого и последовательного анализа.
RLVR: Обучение с Подкреплением с Проверяемыми Наградами
Метод обучения с подкреплением с проверяемыми наградами (RLVR) представляет собой новый подход к обучению больших языковых моделей (LLM), основанный на автоматической генерации наград, зависящих от корректности каждого шага рассуждений. В отличие от традиционных методов, RLVR не требует ручной разметки данных для определения наград; вместо этого, система автоматически оценивает правильность каждого шага решения задачи и выдает соответствующую награду. Это позволяет масштабировать процесс обучения и применять его к сложным задачам, требующим многоступенчатых рассуждений, без необходимости привлечения большого количества экспертов для ручной оценки.
В отличие от традиционного обучения с подкреплением, RLVR не требует ручной разметки вознаграждений человеком. Это позволяет значительно повысить масштабируемость и эффективность обучения на сложных задачах, поскольку устраняется узкое место, связанное с получением и обработкой данных, размеченных людьми. Автоматическое генерирование вознаграждений, основанное на корректности каждого шага рассуждений, снижает затраты и время, необходимые для обучения моделей, и позволяет применять RLVR к задачам, для которых получение качественных разметок человеком затруднительно или невозможно.
Оптимизация непосредственно на основе корректности рассуждений в RLVR позволяет модели последовательно улучшать логическую структуру и точность получаемых решений. Вместо обучения на основе конечного результата, RLVR оценивает каждый шаг рассуждений, предоставляя сигнал для корректировки стратегии. Такой подход способствует формированию более устойчивых и надежных решений, поскольку модель учится избегать логических ошибок на ранних этапах, а не только исправлять их в финальном ответе. Это особенно важно для сложных задач, требующих многоступенчатого анализа и вывода, где даже незначительная ошибка на начальном этапе может привести к неправильному конечному результату.
JudgeRLVR: Уточнение Рассуждений посредством Самооценки
JudgeRLVR внедряет двухэтапную схему обучения, расширяя функциональность RLVR. На первом этапе модель обучается выступать в роли “арбитра”, оценивая корректность траекторий рассуждений. Этот процесс включает в себя анализ последовательности шагов, выполненных для решения задачи, и определение, насколько логичны и обоснованы эти шаги с точки зрения достижения правильного результата. Обучение арбитра осуществляется на размеченном наборе данных, содержащем различные траектории рассуждений, помеченные как правильные или ошибочные. В результате модель формирует способность оценивать промежуточные шаги рассуждений и определять их вклад в общее решение.
Модель JudgeRLVR использует обученную модель-“судью” для управления процессом генерации ответов. В ходе генерации, модель-“судья” оценивает промежуточные этапы рассуждений, определяя их корректность и продуктивность. Непродуктивные или ошибочные пути рассуждений отсекаются на ранних стадиях, что позволяет LLM сосредоточиться на более перспективных направлениях и избежать излишних вычислительных затрат. Этот механизм самооценки и обрезки позволяет модели оптимизировать процесс решения задач, повышая как точность, так и скорость генерации ответа.
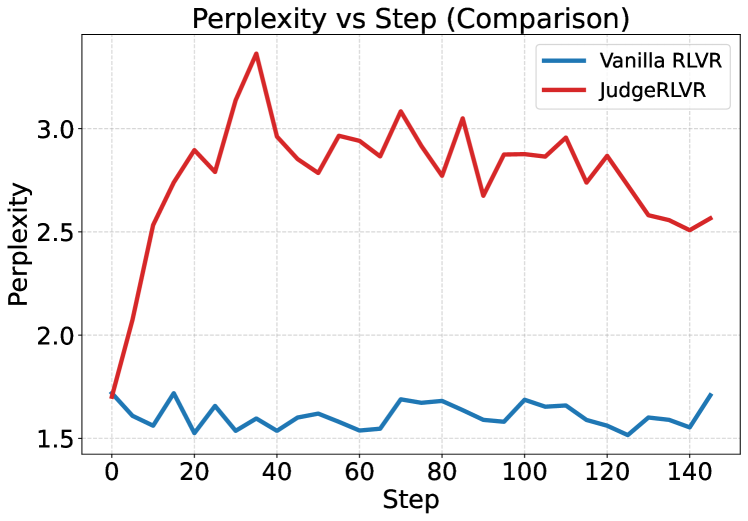
Методика JudgeRLVR повышает качество и скорость решения задач за счет оптимизации процесса рассуждений. В отличие от традиционных подходов, JudgeRLVR не только генерирует цепочку рассуждений, но и активно оценивает ее промежуточные этапы на предмет корректности и продуктивности. Приоритет отдается эффективным траекториям решения, что позволяет отсекать бесперспективные ветви рассуждений на ранних стадиях. В результате, модель фокусируется на наиболее вероятных и точных путях к решению, что приводит к повышению как точности ответа, так и снижению времени, необходимого для его получения. Это достигается за счет целенаправленной оценки и отсева неэффективных шагов в процессе рассуждений.
Реализация и Результаты с Qwen3-30B-A3B
Успешная реализация фреймворка JudgeRLVR с использованием языковой модели Qwen3-30B-A3B демонстрирует ее совместимость с масштабными архитектурами и открывает новые возможности для развития систем искусственного интеллекта. Интеграция JudgeRLVR позволила эффективно использовать вычислительные ресурсы, необходимые для обработки сложных задач, и подтвердила способность модели Qwen3-30B-A3B к адаптации и эффективной работе в составе комплексных систем. Этот результат подчеркивает перспективность использования больших языковых моделей в качестве основы для создания интеллектуальных систем, способных решать сложные математические задачи и адаптироваться к различным условиям.
Эксперименты показали значительное улучшение в задачах математического рассуждения, особенно в тех, которые требуют многошагового решения. Применение JudgeRLVR с моделью Qwen3-30B-A3B позволило добиться прироста средней точности на 3,7 пункта при решении математических задач из проверочных наборов данных, соответствующих области обучения модели. Этот результат свидетельствует о способности системы не только правильно выполнять отдельные вычисления, но и эффективно выстраивать последовательность логических шагов для достижения верного ответа, что особенно важно при решении сложных математических проблем. Повышение точности демонстрирует потенциал данной архитектуры для автоматизации и улучшения процесса решения математических задач.
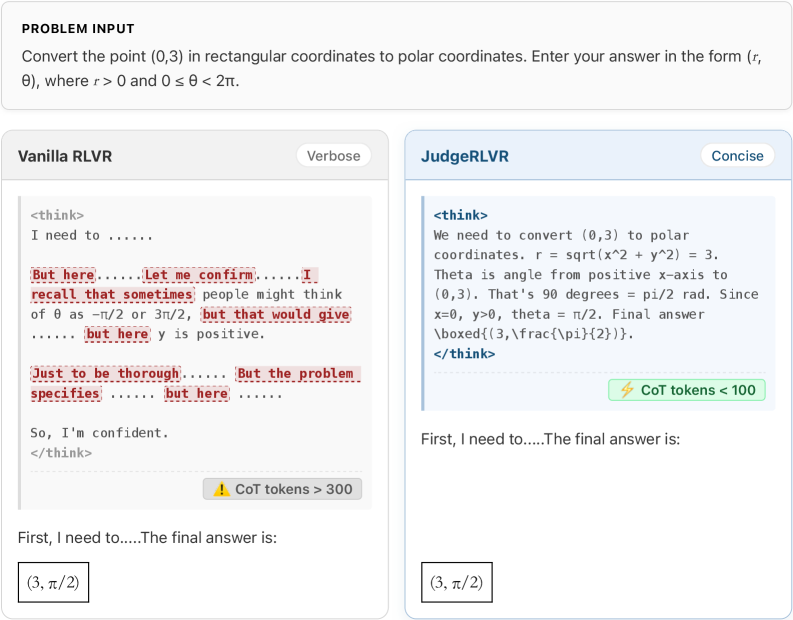
В ходе экспериментов JudgeRLVR продемонстрировал значительное повышение эффективности при решении математических задач, не встречавшихся в обучающей выборке — прирост точности составил 4,5 пункта. При этом модель не только улучшила свои результаты, но и существенно сократила среднюю длину генерируемых решений — примерно на 42%. Данное снижение свидетельствует о способности JudgeRLVR к более лаконичному и целенаправленному мышлению. В частности, отмечается успешное применение таких математических концепций, как полярные координаты, и адаптация процесса рассуждений для достижения точных ответов, что указывает на развитие у модели способности к обобщению и применению знаний в новых условиях.
К Более Надежным и Эффективным Системам Рассуждений
Разработанная система JudgeRLVR представляет собой важный прорыв в создании больших языковых моделей (LLM), способных к надёжному и эффективному рассуждению. В отличие от традиционных подходов, фокусирующихся исключительно на конечном результате, JudgeRLVR делает акцент на оценке процесса решения задачи. Эта система использует обучение с подкреплением, где LLM выступает в роли агента, а отдельная модель, функционирующая как “судья”, оценивает каждый шаг рассуждений, предоставляя обратную связь. Такой подход позволяет модели не просто находить правильный ответ, но и учиться логически обосновывать свои выводы, что критически важно для повышения надёжности и объяснимости искусственного интеллекта. JudgeRLVR демонстрирует значительное улучшение в решении сложных задач, требующих многоступенчатого логического анализа, и открывает новые перспективы для создания интеллектуальных систем, способных к самостоятельному и обоснованному принятию решений.
Дальнейшие исследования направлены на расширение применимости разработанного подхода к задачам повышенной сложности, требующим более глубокого и многоступенчатого рассуждения. Особое внимание уделяется разработке инновационных методов формирования вознаграждения, позволяющих более эффективно направлять процесс обучения модели и стимулировать исследование пространства возможных решений. Ученые стремятся оптимизировать стратегии исследования, чтобы модель могла самостоятельно находить оптимальные пути решения, даже в условиях неопределенности и неполноты информации. Подобные усовершенствования позволят создавать системы искусственного интеллекта, способные не только выдавать правильные ответы, но и демонстрировать надежный и прозрачный процесс рассуждений, что является ключевым шагом к созданию действительно интеллектуальных и заслуживающих доверия систем.
Вместо того, чтобы просто оценивать конечный результат, современные исследования всё больше внимания уделяют анализу самого процесса рассуждений, осуществляемого большими языковыми моделями. Такой подход позволяет не просто получить правильный ответ, но и понять, каким образом он был получен, выявляя слабые места и потенциальные ошибки в логике модели. Приоритет процесса над результатом открывает путь к созданию действительно интеллектуальных и надёжных систем искусственного интеллекта, способных не только решать задачи, но и объяснять свои решения, а также адаптироваться к новым условиям и учиться на собственных ошибках. Это фундаментальный сдвиг в парадигме разработки ИИ, позволяющий создавать системы, способные к более глубокому пониманию и решению сложных проблем.
Исследование представляет собой подход к обучению больших языковых моделей, где оценка валидности решения предшествует его генерации. Этот двухэтапный процесс, JudgeRLVR, стремится к оптимизации баланса между качеством и эффективностью рассуждений. В этом контексте, слова Пауля Эрдеша удивительно точно отражают суть работы: “Математика — это искусство находить закономерности, которые скрыты в хаосе.” Подобно тому, как математик ищет порядок в кажущемся беспорядке, данная система сначала выявляет корректность потенциального решения, прежде чем приступить к его построению, тем самым структурируя процесс рассуждений и обеспечивая более надежный результат. Устойчивость системы, как подчеркивается в исследовании, возникает из четких границ, определяемых этапом оценки, что соответствует элегантному дизайну, рожденному из простоты и ясности.
Куда же дальше?
Представленный подход, разделяющий оценку и генерацию, безусловно, указывает на плодотворное направление. Однако, иллюзия кажущейся простоты часто скрывает сложность лежащей в основе архитектуры. Если система кажется эффективной, вероятно, ею является, но важно помнить: каждая оптимизация — это искусство выбора того, чем пожертвовать. Настоящая проблема заключается не в увеличении скорости, а в повышении надежности оценки, ведь ошибочный судья неизбежно приводит к ошибочным решениям.
В дальнейшем, необходимо сосредоточиться на исследовании более устойчивых методов верификации вознаграждений. Очевидно, что существующие метрики несовершенны, и их улучшение — задача нетривиальная. Интересным представляется поиск способов интеграции внешних источников знаний для повышения точности оценки, а также разработка механизмов самокоррекции, позволяющих модели учиться на собственных ошибках. Простота архитектуры, как правило, является признаком элегантности, но не обязательно — гарантом успеха.
Наконец, стоит задуматься о том, что сама концепция “разумного” агента подразумевает не только способность решать задачи, но и способность осознавать границы своей компетентности. Система, которая признает собственную неспособность, вероятно, более ценна, чем та, которая упорно стремится к неверному решению. В конечном итоге, истинная сложность заключается не в создании искусственного интеллекта, а в понимании природы интеллекта как такового.
Оригинал статьи: https://arxiv.org/pdf/2601.08468.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-14 11:34