Автор: Денис Аветисян
Исследователи предлагают метод Composition-RL, позволяющий создавать более сложные и разнообразные обучающие данные для больших языковых моделей, повышая их производительность и обобщающую способность.
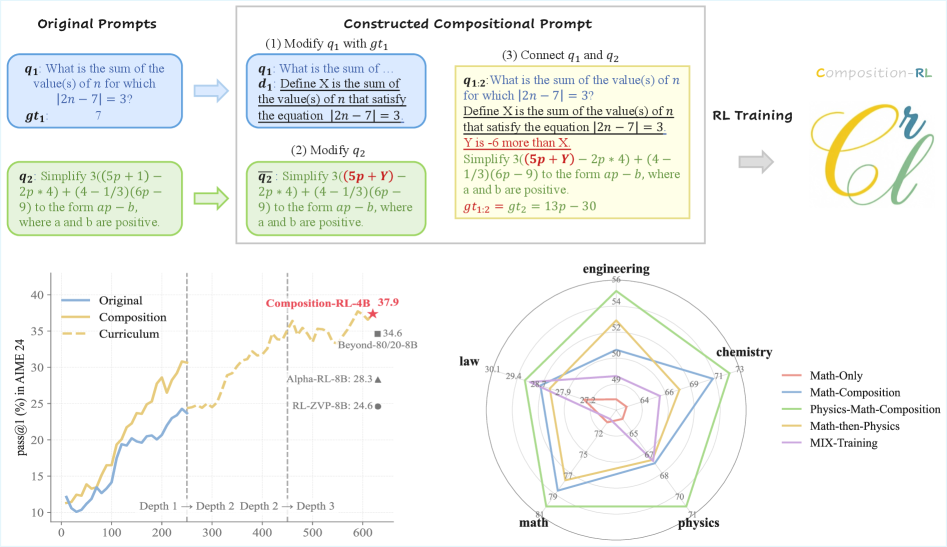
Предложен метод Composition-RL для обучения языковых моделей с помощью композиционных подсказок и верифицируемых наград.
Несмотря на успехи обучения с подкреплением для больших языковых моделей (LLM), расширение наборов верифицируемых подсказок часто оказывается затратным и неэффективным из-за преобладания простых примеров. В данной работе, ‘Composition-RL: Compose Your Verifiable Prompts for Reinforcement Learning of Large Language Models’, предложен метод Composition-RL, автоматически комбинирующий существующие подсказки для создания более сложных и разнообразных задач обучения. Эксперименты с моделями размером от 4 до 30 миллиардов параметров продемонстрировали, что такой подход последовательно улучшает способность к рассуждениям и позволяет эффективно использовать данные из разных областей. Возможно ли дальнейшее повышение эффективности обучения LLM за счет более сложных стратегий комбинирования подсказок и адаптивного изменения их сложности?
Вызов логического мышления в больших языковых моделях
Несмотря на впечатляющие возможности, демонстрируемые большими языковыми моделями (БЯМ), достижение надёжного и устойчивого логического мышления остаётся серьёзной проблемой. БЯМ способны генерировать связные и правдоподобные тексты, успешно справляться с задачами, требующими знания фактов, и даже имитировать различные стили письма. Однако, когда речь заходит о сложных рассуждениях, требующих анализа, обобщения и применения знаний в новых ситуациях, их производительность часто снижается. Это проявляется в ошибках при решении логических задач, неспособности к критическому анализу информации и склонности к генерации неверных или противоречивых ответов, что указывает на фундаментальные ограничения в текущей архитектуре и подходах к обучению подобных систем.
Исследования показывают, что простое увеличение масштаба языковых моделей, хотя и привело к значительным улучшениям в ряде задач, сталкивается с ограничениями. Наблюдается эффект плато, когда дальнейшее увеличение количества параметров и обучающих данных не приводит к пропорциональному росту способностей к решению сложных задач, требующих обобщения знаний. Это указывает на то, что текущие архитектуры моделей не обладают достаточной гибкостью для эффективного переноса изученного опыта на новые, незнакомые ситуации. По сути, модели становятся все лучше в запоминании, но не в истинном понимании и применении принципов, необходимых для логического мышления и решения проблем, требующих экстраполяции за пределы непосредственно представленных данных.
Эффективное рассуждение выходит далеко за рамки простого запоминания информации; оно требует способности синтезировать разрозненные данные и применять их к принципиально новым ситуациям. Исследования показывают, что современные языковые модели часто демонстрируют впечатляющую память, но испытывают трудности при столкновении с задачами, требующими логического вывода и адаптации к незнакомым контекстам. Способность к синтезу подразумевает не просто хранение фактов, но и установление связей между ними, выявление закономерностей и формирование новых знаний. Применение этих знаний в нестандартных ситуациях — ключевой признак настоящего интеллекта, и именно эта область представляет наибольшую сложность для существующих моделей, подчеркивая необходимость разработки архитектур, способных к более глубокому пониманию и обобщению информации.
RLVR: Новый подход к обучению больших языковых моделей
Метод обучения с подкреплением с проверяемыми наградами (RLVR) представляет собой перспективный подход к обучению больших языковых моделей (LLM), отличающийся от традиционных методов акцентом на поощрение правильных этапов рассуждений, а не только конечного ответа. Вместо оценки только верности результата, RLVR оценивает каждый шаг логической цепочки, позволяя модели научиться не просто «угадывать» правильный ответ, а строить обоснованные и проверяемые выводы. Это достигается путем определения промежуточных, проверяемых на корректность этапов решения задачи, за которые модель получает награду. Такой подход призван повысить надежность и интерпретируемость LLM, а также улучшить их способность к решению сложных, многоступенчатых задач.
Разработка RLVR опирается на предшествующие модели, такие как OpenAI-o1 и DeepSeek-R1, которые продемонстрировали перспективные результаты в области обучения с подкреплением. RLVR стремится улучшить надежность и интерпретируемость ИИ-систем путем акцента на верифицируемых вознаграждениях за правильные этапы рассуждений, а не только за конечный ответ. Это достигается за счет использования алгоритмов, оптимизированных для работы в сложных пространствах вознаграждений, что позволяет более точно отслеживать и контролировать процесс обучения модели, обеспечивая большую прозрачность и предсказуемость ее поведения. В отличие от моделей, ориентированных исключительно на достижение результата, RLVR позволяет анализировать логику, лежащую в основе принятых решений.
Для эффективной навигации по сложному ландшафту вознаграждений, возникающему при обучении языковых моделей с помощью обучения с подкреплением и верифицируемыми наградами (RLVR), требуются специализированные алгоритмы, такие как Group Relative Policy Optimization (GRPO). GRPO позволяет оптимизировать политику агента, учитывая относительное положение различных действий в пространстве вознаграждений, что повышает стабильность и скорость обучения. В отличие от стандартных алгоритмов обучения с подкреплением, GRPO эффективно справляется с разреженными сигналами вознаграждения, характерными для задач, требующих многошагового логического вывода, обеспечивая более надежное и предсказуемое поведение модели. Это достигается за счет группировки действий и оценки их эффективности относительно других действий в группе, что снижает влияние случайных флуктуаций и улучшает обобщающую способность модели.
Composition-RL: Расширение обучающих данных за счет сложности
Метод Composition-RL развивает подход RLVR путем систематической трансформации простых запросов в более сложные, что позволяет эффективно расширить разнообразие и сложность обучающих данных. Этот процесс включает в себя последовательное усложнение исходных запросов, создавая новые примеры, требующие более глубокого рассуждения. В результате модель обучается на более широком спектре сценариев, что способствует улучшению обобщающей способности и повышению эффективности решения задач, требующих композиционного мышления. Использование подобных техник позволяет преодолеть ограничения, связанные с недостаточным разнообразием исходных данных, и повысить устойчивость модели к новым, ранее не встречавшимся задачам.
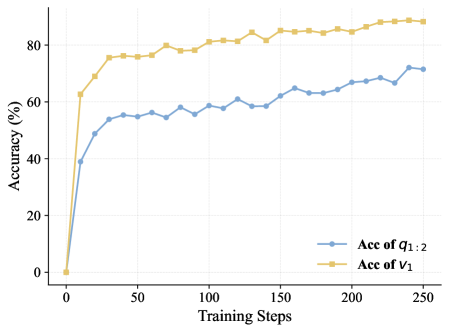
Последовательное составление запросов (SPC) является ключевым компонентом расширения обучающих данных. Метод позволяет генерировать более сложные запросы, используя существующие наборы данных, такие как MATH12K. SPC работает путем последовательного применения трансформаций к исходным запросам, создавая новые примеры, требующие более глубокого логического вывода и комбинации различных навыков решения задач. Например, простой запрос из MATH12K может быть расширен добавлением дополнительных условий или изменением формата представления данных, что приводит к созданию более сложных и разнообразных примеров, необходимых для эффективного обучения модели.
Использование наборов данных, таких как MATH-Composition-199K, значительно расширяет спектр сценариев рассуждений, с которыми сталкивается модель во время обучения. Этот набор данных содержит 199 тысяч задач, генерируемых путем последовательного комбинирования простых математических задач из MATH12K, что позволяет модели тренироваться на задачах различной сложности и структуры. Такой подход позволяет повысить способность модели к обобщению на композиционные задачи — то есть задачи, требующие последовательного применения нескольких рассуждений для достижения решения, а не просто распознавания паттернов или прямого применения известных фактов. Это особенно важно для улучшения производительности модели в ситуациях, когда требуется решение новых, ранее не встречавшихся задач, требующих комбинирования имеющихся знаний.
Динамическая выборка (Dynamic Sampling) используется для смягчения влияния так называемых “промптов, решающих все” (Solve-All Prompts) в процессе обучения. Эти промпты, по сути, предоставляют моделью готовые решения, что ограничивает информативность сигнала обучения и препятствует развитию навыков самостоятельного рассуждения. Метод динамической выборки заключается в адаптивном регулировании частоты использования таких промптов, уменьшая их долю в обучающей выборке по мере обучения модели. Это позволяет сосредоточиться на более сложных и информативных примерах, способствуя более эффективному усвоению навыков решения задач и повышению обобщающей способности модели. Фактически, динамическая выборка позволяет избежать перекоса в данных и обеспечивает более сбалансированный процесс обучения.
Экспериментальная проверка и масштабирование модели
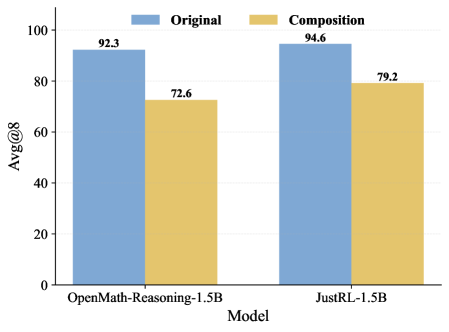
Эксперименты с базовыми моделями, такими как Qwen3-4B-Base и Qwen3-8B-Base, наглядно демонстрируют преимущества подхода Composition-RL в усилении способностей к логическому мышлению. Данная методика позволяет значительно повысить эффективность решения задач, требующих последовательного анализа и выстраивания аргументации. В ходе исследований было установлено, что Composition-RL способствует более глубокому пониманию сложных концепций и улучшает способность модели к обобщению полученных знаний. Результаты показывают, что применение данной технологии открывает новые возможности для создания искусственного интеллекта, способного к решению задач, требующих высокого уровня когнитивных способностей и критического мышления.
Внедрение неявного контроля процесса играет ключевую роль в повышении эффективности предложенного подхода. Данная методика направляет модель к формированию более структурированных и понятных цепочек рассуждений, что позволяет не только улучшить общую производительность, но и облегчить анализ принимаемых решений. Вместо простого получения ответа, модель постепенно обучается демонстрировать логические шаги, ведущие к конечному результату, что повышает доверие к её выводам и облегчает выявление потенциальных ошибок. Такой подход к обучению способствует созданию более прозрачных и интерпретируемых систем искусственного интеллекта, что особенно важно в областях, требующих высокой степени надежности и обоснованности принимаемых решений.
Тщательная оценка, проведенная с использованием инструментов ускорения вывода, таких как vLLM, выявила значительное улучшение способности модели к обобщению на новые, ранее не встречавшиеся задачи и предметные области. В частности, отмечается успешное применение подхода к сложным задачам из набора данных MegaScience, что свидетельствует о его потенциале в решении широкого спектра научных проблем. Этот результат указывает на то, что модель не просто заучивает решения для конкретных примеров, но и формирует более глубокое понимание принципов, позволяющее эффективно адаптироваться к новым условиям и демонстрировать высокую производительность в различных областях знаний.
Экспериментальные исследования демонстрируют значительное превосходство подхода Composition-RL над стандартным обучением с подкреплением в области математических рассуждений. В частности, применение Composition-RL к базовой модели Qwen3-4B позволило добиться прироста в 14,1% в решении задач из набора AIME25, а общее улучшение математической производительности достигло 14,3%. Данный результат указывает на эффективность предложенного метода в формировании более качественных стратегий решения математических задач, что подтверждается существенным улучшением показателей в специализированных бенчмарках.
Исследования показали, что использование композиционных данных из различных областей знаний значительно улучшает способность моделей к решению сложных задач. В частности, применение такого подхода позволило добиться прироста в 7.1% при решении задач AIME24 и 2.9% в тесте MMLU-Pro. Это указывает на то, что обучение на разнообразных данных, охватывающих различные предметные области, способствует формированию более обобщенных и устойчивых навыков рассуждения у моделей, позволяя им успешно справляться с задачами, выходящими за рамки узкоспециализированных знаний. Полученные результаты подчеркивают важность создания обучающих наборов данных, которые включают в себя информацию из различных источников и областей, для повышения общей интеллектуальной производительности систем искусственного интеллекта.
Исследование демонстрирует, что создание сложных и разнообразных обучающих данных посредством композиции промптов является ключевым фактором повышения эффективности обучения больших языковых моделей. Этот подход, представленный в работе как Composition-RL, акцентирует внимание на создании контролируемых и проверяемых вознаграждений, что позволяет модели более эффективно обобщать знания. Как однажды заметил Брайан Керниган: «Отладка — это как поиск иглы в стоге сена, но если у вас есть хорошее освещение и магнит, это становится намного проще». Аналогично, Composition-RL предлагает своего рода «магнит» для обучения LLM, направляя процесс генерации промптов к более осмысленным и полезным данным, что в свою очередь, ведет к более надежным и предсказуемым результатам.
Куда же дальше?
Представленный подход, безусловно, демонстрирует потенциал композиционного построения обучающих данных для больших языковых моделей. Однако, не стоит обольщаться: если улучшение производительности кажется чудом — вероятно, инвариант, лежащий в основе этого улучшения, остаётся невыявленным. Построение действительно верифицируемых наград — задача, требующая гораздо большей строгости, чем просто генерация разнообразных примеров. Простое увеличение разнообразия данных без глубокого понимания того, что именно делает пример «сложным» или «интересным», рискует превратиться в шум.
Следующим шагом представляется не просто автоматизация процесса композиции подсказок, а разработка формальной теории сложности для задач, решаемых языковыми моделями. Необходимо понимать, какие свойства делают задачу трудной, и как эти свойства могут быть использованы для создания эффективного учебного плана. Иначе, мы рискуем просто перебирать варианты, надеясь на статистическую удачу.
В конечном счёте, истинная элегантность заключается не в достижении впечатляющих результатов, а в построении доказуемо корректных алгоритмов. Пока же, исследование возможностей композиционного обучения представляется лишь первым шагом на пути к созданию действительно интеллектуальных систем.
Оригинал статьи: https://arxiv.org/pdf/2602.12036.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый разум: Новая эра языковых моделей
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Гендерные стереотипы в найме: что скрывают языковые модели?
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Разумные языковые модели: новый подход к логическому мышлению
- Симуляция, которая видит себя: новый подход к физическому моделированию
- Ребусы для ИИ: новый масштабный тест на сообразительность
- Искусственный интеллект под давлением: обнаружение логических аномалий в промышленном контроле
- Как заставить языковые модели говорить правду?
- Стратегия подцелей: Как научить ИИ долгосрочному планированию
2026-02-14 07:45