Автор: Денис Аветисян
Исследователи разработали инновационную систему, способную точно сопоставлять объекты, видимые с разных точек зрения, используя возможности искусственного интеллекта и машинного обучения.

Предложен фреймворк на основе трансформеров и циклической согласованности для улучшения сопоставления объектов в эгоцентричных и экзоцентричных видео, демонстрирующий передовые результаты на наборе данных Ego-Exo4D.
Установление визуальной соответствия объектов при изменении угла обзора представляет собой сложную задачу, особенно при переходе от видов «от первого лица» к «от третьего» и наоборот. В данной работе, ‘Learning Cross-View Object Correspondence via Cycle-Consistent Mask Prediction’, предлагается новый подход, основанный на условной бинарной сегментации и циклической согласованности, для решения этой проблемы. Ключевая идея заключается в использовании маски объекта-запроса для локализации соответствующего объекта в целевом видео, при этом циклическая согласованность обеспечивает устойчивость и инвариантность представлений к изменениям угла обзора. Может ли предложенный метод, демонстрирующий передовые результаты на наборах данных Ego-Exo4D и HANDAL-X, стать основой для создания более надежных систем визуального отслеживания и анализа?
Понимание Визуальной Последовательности: Задача и Вызовы
Понимание видеоматериалов напрямую зависит от способности системы последовательно идентифицировать объекты, даже при значительных изменениях угла обзора. Традиционные методы компьютерного зрения часто терпят неудачу в этой задаче, поскольку полагаются на признаки, которые сильно меняются при изменении перспективы. Например, при повороте объекта на 180 градусов, алгоритмы, ориентированные на конкретные шаблоны, могут потерять его из виду, ошибочно принимая за новый объект. Это создает серьезные препятствия для задач, таких как автономная навигация или анализ поведения, где непрерывное отслеживание объектов является критически важным. Современные исследования направлены на разработку более устойчивых методов, способных абстрагироваться от изменений перспективы и сохранять идентичность объекта на протяжении всего видеоряда.
Существующие подходы к сопоставлению визуальной информации сталкиваются с серьезными ограничениями при переходе к незнакомым сценам и в сложных условиях. Исследования показывают, что алгоритмы, успешно работающие в контролируемых лабораторных условиях, часто демонстрируют значительное снижение точности при обработке реальных видеозаписей, где объекты частично скрыты или окружение значительно отличается от обучающих данных. Неспособность обобщать знания на новые ситуации, а также недостаточная устойчивость к перекрытиям и визуальному шуму, существенно ограничивают практическое применение этих методов в таких областях, как автономное вождение, робототехника и видеонаблюдение, где надежное отслеживание объектов является критически важным.
Цикличное Сопоставление Визуальной Информации: Новый Подход
Метод Cycle-Consistent Visual Correspondence обеспечивает устойчивое установление соответствий между исходным и целевым изображениями за счет использования целевой функции, основанной на принципе цикличности. Этот принцип требует, чтобы преобразование изображения из исходного вида в целевой и последующее преобразование обратно в исходный вид приводило к минимальным искажениям, то есть реконструированное исходное изображение максимально соответствовало оригиналу. Фактически, это накладывает ограничение на возможные преобразования, гарантируя, что соответствия, установленные между пикселями или областями, остаются согласованными при изменении точки зрения. Минимизация расхождения между исходным изображением и его реконструкцией после циклического преобразования служит ключевым фактором для повышения надежности и точности установления визуальных соответствий.
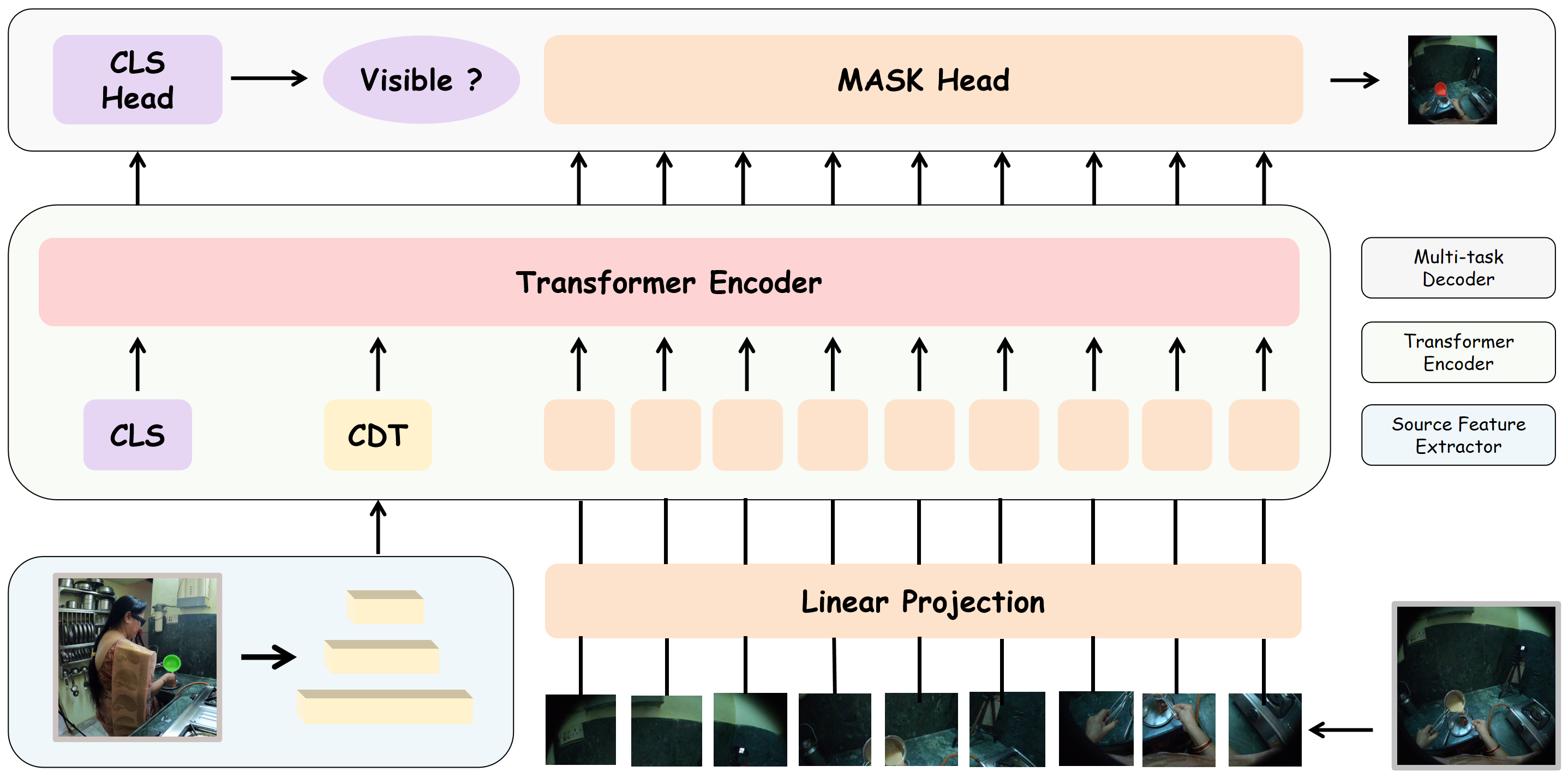
В основе нашей системы лежит интеграция предварительно обученной модели компьютерного зрения DINOv3 для извлечения информативных визуальных признаков. DINOv3 обеспечивает получение высокоуровневых представлений изображений, которые служат входными данными для последующей обработки. Для передачи информации об исходном изображении в Transformer-архитектуру используется Condition Token (CDT) — специальный токен, который кодирует ключевые характеристики исходного изображения и встраивается в последовательность входных токенов. Это позволяет Transformer-модели учитывать контекст исходного изображения при генерации результатов для целевого вида, обеспечивая более точное и согласованное соответствие между изображениями.
В рамках предложенного подхода используется Transformer Encoder для обработки визуальных токенов, полученных из признаков изображений. Этот энкодер выполняет кодирование последовательности токенов, представляющих визуальную информацию, для извлечения контекстно-зависимых признаков. После обработки энкодером, признаки передаются в Mask Head, который генерирует маски сегментации для целевого изображения. Mask Head выполняет пиксельную классификацию, определяя принадлежность каждого пикселя к определенному объекту или классу, обеспечивая тем самым точное выделение сегментов на целевом изображении.
Валидация Производительности и Количественные Результаты
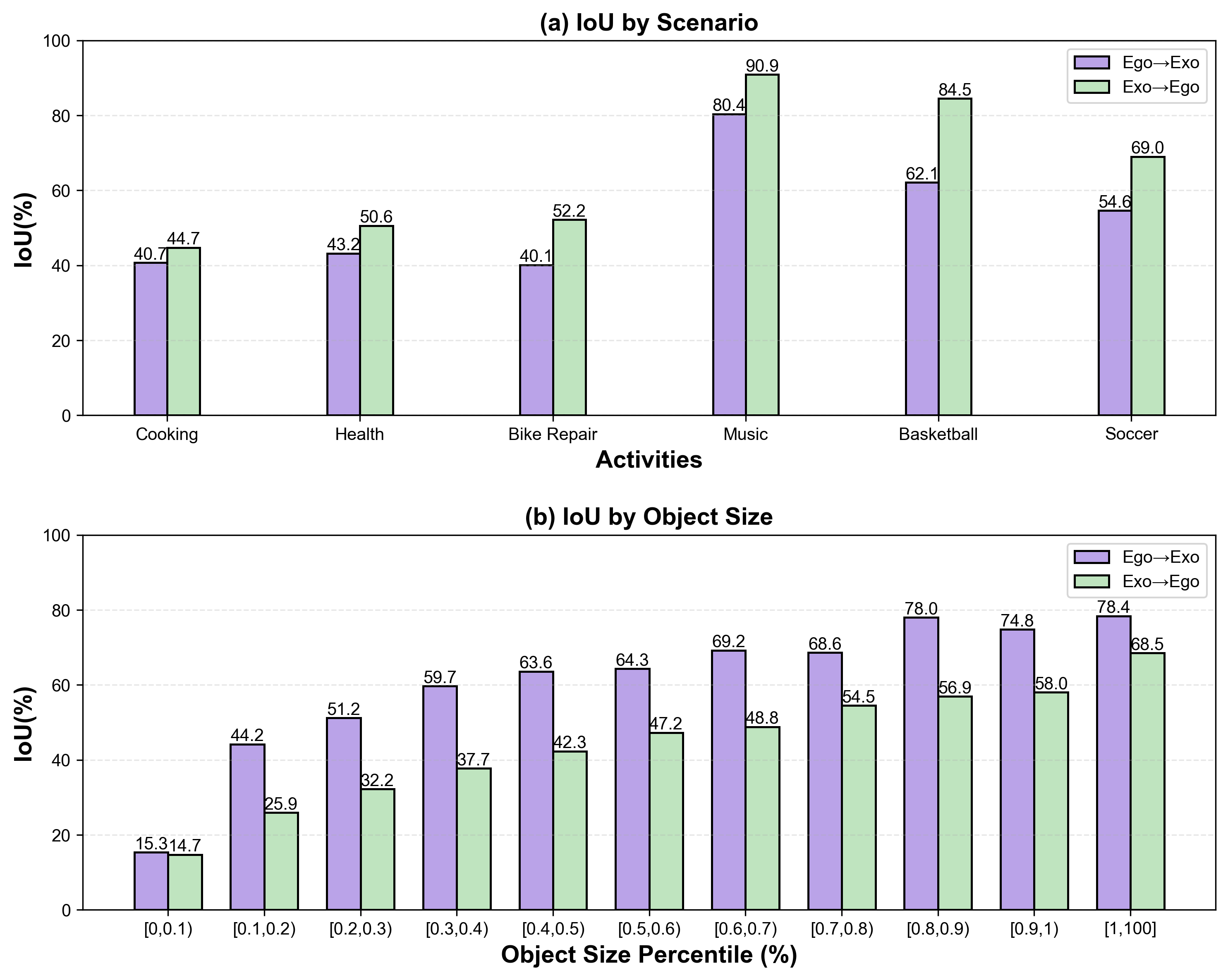
Для валидации предложенного подхода использовались сложные наборы данных Ego-Exo4D и HANDAL-X. На наборе Ego-Exo4D был достигнут средний показатель Intersection over Union (mIoU) в 44.57%, что на 2.9% превышает результаты, показанные предыдущими методами. Данный результат демонстрирует значительное улучшение точности сегментации и выделения объектов в сложных условиях, характерных для набора Ego-Exo4D, и подтверждает эффективность предложенного подхода по сравнению с существующими решениями в данной области.
Для количественной оценки прироста производительности использовались стандартные метрики: Intersection over Union (IoU), Location Error (LE) и Contour Accuracy (CA). На датасете Ego-Exo4D достигнуты следующие значения IoU: 36.74 для Exo Query и 41.95 для Ego Query. Эти результаты превосходят показатели предыдущих методов более чем на 7.0%, при этом значение IoU для Ego Query приближается к результату предыдущего передового метода (42.57%). Использование данных метрик позволило объективно подтвердить улучшение качества предсказаний.
Для повышения производительности предложенной системы, мы применили обучение во время тестирования (Test-Time Training, TTT) и исследовали альтернативные методы предсказания, включая Cosine Prediction. На датасете HANDAL-X это позволило достичь показателя Intersection over Union (IoU) в 78.8%, что представляет собой относительное улучшение в 84.1% по сравнению со всеми базовыми моделями. Применение TTT и Cosine Prediction значительно повысило точность и эффективность системы в задачах сегментации на HANDAL-X.

Влияние и Перспективы Развития
Надёжное установление соответствий между изображениями, полученными с разных точек зрения, является ключевым элементом для широкого спектра передовых технологий. В частности, для автономных транспортных средств точное определение положения объектов и их взаимосвязи в пространстве, независимо от угла обзора камеры, необходимо для безопасной навигации и принятия решений. В робототехнике подобная возможность позволяет роботам эффективно взаимодействовать с окружающей средой, манипулировать объектами и ориентироваться в сложных условиях. Кроме того, в сфере дополненной реальности, корректное сопоставление изображений с разных камер обеспечивает реалистичное наложение виртуальных объектов на реальный мир, создавая захватывающий и интерактивный пользовательский опыт. Таким образом, совершенствование методов установления соответствий между изображениями открывает новые возможности для создания интеллектуальных систем, способных к более глубокому пониманию и взаимодействию с окружающей средой.
Предлагаемый подход существенно расширяет возможности существующих систем компьютерного зрения, преодолевая ограничения, связанные с обработкой сложных сцен и обеспечением надежного сопоставления различных перспектив. В отличие от традиционных методов, склонных к ошибкам при изменении условий освещения или частичной окклюзии объектов, разработанная система демонстрирует повышенную устойчивость и адаптивность. Это достигается за счет использования нового алгоритма, который позволяет более точно устанавливать соответствия между изображениями, полученными с разных точек зрения, что, в свою очередь, открывает перспективы для создания более надежных и интеллектуальных систем, способных эффективно функционировать в реальных условиях, например, в автономных транспортных средствах или роботизированных комплексах.
Дальнейшие исследования направлены на расширение возможностей разработанной системы для работы со сложными сценами, включающими множество объектов и изменяющиеся условия освещения. Особое внимание будет уделено интеграции временной информации, что позволит учитывать динамику происходящего и повысить точность анализа. Кроме того, планируется изучение методов неконтролируемого обучения, которые позволят системе самостоятельно адаптироваться к новым данным и улучшить обобщающую способность, снижая зависимость от размеченных обучающих выборок. Это откроет путь к созданию более надежных и универсальных систем компьютерного зрения, способных эффективно функционировать в реальных условиях.

Исследование, представленное в данной работе, демонстрирует глубокое понимание закономерностей, лежащих в основе визуального соответствия объектов в различных перспективах. Авторы используют трансформаторные сети и принцип циклической согласованности для достижения передовых результатов в задаче установления соответствий между эгоцентричными и экзоцентричными точками зрения. Как однажды заметил Эндрю Ын: «Мы должны сосредоточиться на создании систем искусственного интеллекта, которые могут учиться на небольшом количестве данных». Этот подход особенно актуален для сложных наборов данных, таких как Ego-Exo4D, где обучение моделей требует эффективного использования доступных данных и выявления скрытых взаимосвязей между визуальными представлениями.
Куда двигаться дальше?
Представленная работа, безусловно, демонстрирует прогресс в задаче установления соответствия объектов между разными точками зрения, однако, как часто и бывает, решение одной проблемы обнажает иные. Особое внимание следует уделить не только повышению точности, но и, что важнее, объяснимости предложенного подхода. Понимание почему модель устанавливает соответствие именно так, а не иначе, представляется ключевым для реальных приложений, а не просто для улучшения метрик на эталонных наборах данных. Настоящий вызов заключается в создании системы, способной не просто «видеть» соответствия, но и аргументированно их обосновывать.
Ограничения текущего подхода проявляются при работе с данными, значительно отличающимися от Ego-Exo4D. Вопрос обобщения, перехода от контролируемой лабораторной среды к хаотичному миру реальных сценариев, остаётся открытым. Необходимо исследовать возможности адаптации модели к новым точкам зрения, освещению и условиям съемки без дорогостоящей переподготовки. Возможно, стоит обратить внимание на методы самообучения и активного обучения, позволяющие модели самостоятельно извлекать знания из неразмеченных данных.
В конечном счете, успех в этой области зависит не от сложности архитектуры сети, а от глубины понимания самой задачи. Визуальное соответствие — это не просто поиск совпадений пикселей, это процесс построения когнитивной модели мира. И только когда модели смогут не просто «видеть», но и «понимать», можно будет говорить о настоящем прогрессе в области компьютерного зрения.
Оригинал статьи: https://arxiv.org/pdf/2602.18996.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Квантовые схемы учатся сами: новый подход к архитектурному поиску
- Оживший аватар: Генерация видео в реальном времени по голосу
- Искусственный интеллект и квантовая физика: кто кого?
- Серебро и медь: новый взгляд на наноаллои
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Квантовый взгляд на лейкемию: анализ клеток крови с помощью машинного обучения
- Тензорные сети и комбинаторные поиски: новый подход к сложным задачам
- Quantum Musings: A Conversation with Bert de Jong
2026-02-24 20:16