Автор: Денис Аветисян
Исследователи представили метод, позволяющий генерировать реалистичные изображения на основе композиционных данных, объединяя различные факторы управления в единую систему.

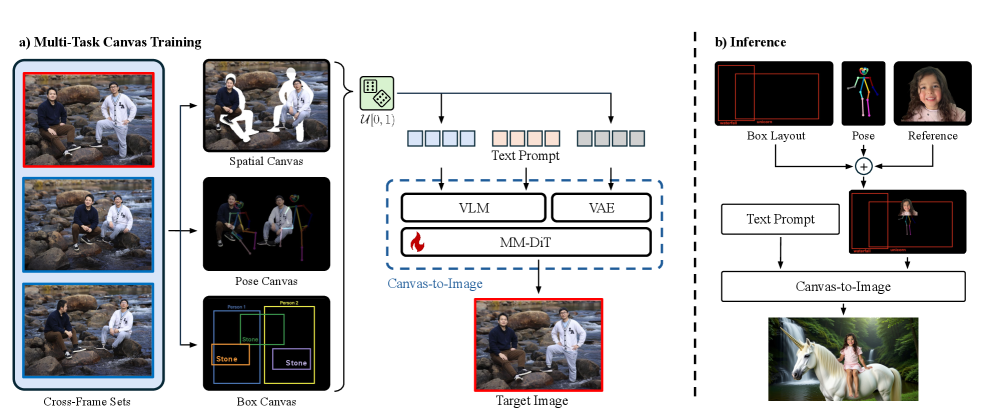
Предложен фреймворк Canvas-to-Image, использующий мультизадачное обучение и представление в виде холста для точного управления композицией, позой и идентификацией объектов при генерации изображений с помощью диффузионных моделей.
Несмотря на успехи современных диффузионных моделей в генерации изображений, точный и согласованный контроль над композицией и различными модальностями управления остается сложной задачей. В работе ‘Canvas-to-Image: Compositional Image Generation with Multimodal Controls’ предложен унифицированный подход, объединяющий текстовые запросы, опорные изображения, пространственные расположения и позы в единое «полотно», что позволяет модели интерпретировать и интегрировать разнородные сигналы для создания целевых изображений. Ключевой идеей является кодирование всех управляющих сигналов в единое композитное изображение и обучение модели с использованием многозадачного подхода. Открывает ли эта стратегия путь к более интуитивному и гибкому управлению генерацией изображений с учетом сложных композиционных требований?
Понимание Композиции: От Задачи к Решению
Существующие методы генерации изображений часто сталкиваются с трудностями при обеспечении точного композиционного контроля. Для достижения желаемого результата пользователям нередко требуется создавать сложные и многословные текстовые запросы, либо ограничиваться примитивными инструментами редактирования. Эта проблема возникает из-за того, что большинство моделей не способны адекватно интерпретировать и объединять различные аспекты композиции, такие как положение объектов, их взаимное расположение и индивидуальные характеристики. В результате, процесс создания изображения становится итеративным и трудоемким, требующим значительных усилий для получения желаемого результата. Отсутствие интуитивно понятного контроля над композицией существенно ограничивает творческую свободу и затрудняет реализацию сложных визуальных концепций.
Представлена концепция Multi-Task Canvas — унифицированного подхода к управлению генерацией изображений. Вместо разрозненных методов контроля позы, компоновки и идентификации объектов, данная разработка объединяет все эти модальности в единое RGB-изображение. Это позволяет представлять желаемый результат в виде стандартного изображения, что значительно упрощает процесс управления и открывает новые возможности для интуитивного редактирования. Вместо сложных текстовых запросов или отдельных параметров для каждого аспекта, пользователь может непосредственно визуально задать композицию, позы и объекты, а система автоматически сгенерирует соответствующее изображение. Такой подход не только повышает точность контроля, но и существенно расширяет творческую свободу, позволяя пользователям легко экспериментировать с различными визуальными решениями.
Предложенный подход значительно упрощает управление процессом генерации изображений, открывая новые возможности для интуитивного редактирования и расширяя границы творческой свободы. Вместо сложных текстовых запросов или ограниченных инструментов редактирования, система позволяет пользователю манипулировать изображением непосредственно, используя унифицированное представление, объединяющее различные аспекты контроля — позу, композицию и идентификацию объектов. Это обеспечивает более естественный и предсказуемый процесс создания, позволяя воплотить даже самые сложные визуальные идеи с высокой точностью и минимальными усилиями. Благодаря этому, пользователи получают не просто инструмент для генерации изображений, а полноценное средство для визуального самовыражения и реализации творческого потенциала.
Для обеспечения надёжной работы и широкой обобщающей способности разработанной системы, использовался масштабный, ориентированный на человека набор данных. Этот набор данных, состоящий из изображений и соответствующих аннотаций, включающих информацию о позах, компоновке и идентификации объектов, позволил модели научиться понимать и воспроизводить сложные визуальные сцены. Особое внимание уделялось разнообразию данных, чтобы обеспечить устойчивость к различным стилям, перспективам и условиям освещения. Такой подход к обучению позволяет системе генерировать изображения, которые не только соответствуют заданным параметрам, но и выглядят естественно и правдоподобно, приближаясь к визуальному качеству, создаваемому человеком.
Canvas-to-Image: Новый Подход к Управлению Генерацией
В основе нашей системы Canvas-to-Image лежит использование Multi-Task Canvas в качестве входных данных для предварительно обученной диффузионной модели Qwen-Image-Edit. Multi-Task Canvas представляет собой структурированное представление входных данных, позволяющее моделировать различные аспекты желаемого изображения. В качестве диффузионной модели была выбрана Qwen-Image-Edit, продемонстрировавшая высокую эффективность в задачах редактирования и генерации изображений. Входной Multi-Task Canvas напрямую передается в Qwen-Image-Edit для управления процессом диффузии и получения результирующего изображения, соответствующего заданным условиям и структуре, закодированным в Canvas.
Для эффективной адаптации модели Qwen-Image-Edit к задаче Canvas-to-Image используется метод LoRA (Low-Rank Adaptation), позволяющий обучать лишь небольшую часть параметров модели, что существенно снижает вычислительные затраты и потребление памяти. Оптимизация модели производится с использованием целевой функции Flow Matching, которая позволяет эффективно моделировать процесс диффузии и генерировать изображения высокого качества. Flow Matching представляет собой вероятностный подход, основанный на построении непрерывного пути между начальным шумом и целевым изображением, что обеспечивает стабильность и управляемость процесса генерации. Данный подход позволяет добиться высокой производительности и качества генерируемых изображений при ограниченных ресурсах.
Ключевым этапом в нашей системе является кодирование входного canvas-изображения в токенизированное представление посредством использования визуальной языковой модели (VLM). Полученная последовательность токенов затем преобразуется в латентное пространство с помощью вариационного автоэнкодера (VAE). Этот процесс позволяет представить canvas в виде компактного вектора латентных признаков, который служит входными данными для модели диффузии. Использование VLM обеспечивает семантическое понимание содержимого canvas, а VAE — эффективное сжатие данных и сохранение ключевой визуальной информации, необходимой для последующего редактирования и генерации изображений.
Прецизионное управление генерацией изображения на основе входного канваса достигается за счет кодирования этого канваса в токенизированное представление посредством использования VLM (Visual Language Model), а затем — в латентное пространство с помощью VAE (Variational Autoencoder). Этот процесс позволяет точно определить и передать желаемые характеристики изображения, заданные в канвасе, поскольку латентное представление служит компактным и информативным кодом для последующей генерации диффузионной моделью. В результате, изменения в канвасе напрямую влияют на генерируемое изображение, обеспечивая детальный контроль над его структурой и содержанием.
Расширение Возможностей: Пространственные, Позные и Ограничивающие Холсты
Многозадачный холст расширен тремя ключевыми вариантами: Пространственный холст (Spatial Canvas), Холст поз (Pose Canvas) и Холст ограничивающих рамок (Box Canvas). Каждый из этих вариантов предназначен для работы с определенными типами управляющих сигналов. Пространственный холст позволяет осуществлять полный контроль над сценой, используя композитные изображения, созданные на основе наборов кросс-фреймов, что позволяет избежать артефактов при вставке элементов. Холст поз предназначен для точной генерации изображений с учетом позы, накладывая на изображение скелеты поз, соответствующие желаемому результату. Холст ограничивающих рамок позволяет определить пространственную компоновку сцены, используя ограничивающие рамки и текстовые описания. Данные варианты демонстрируют гибкость и универсальность фреймворка при решении сложных задач композиции изображений.
Пространственный холст (Spatial Canvas) использует композитные изображения, созданные на основе наборов кросс-фреймов (Cross-Frame Sets), для минимизации артефактов при наложении объектов. Этот подход позволяет добиться полного контроля над сценой, поскольку каждый элемент интегрируется в общее изображение с учетом контекста и перспектив других объектов. Использование кросс-фреймов позволяет избежать видимых швов или несоответствий при объединении изображений, обеспечивая плавный и реалистичный результат. Такой метод особенно важен для сложных сцен, требующих точного позиционирования и интеграции множества элементов.
Полотно позы (Pose Canvas) обеспечивает точное управление генерацией на основе позы, путем наложения на входное изображение эталонных скелетов, определяющих желаемое положение и ориентацию объектов. Полотно с ограничивающими рамками (Box Canvas) позволяет задавать пространственную компоновку сцены с помощью ограничивающих прямоугольников и текстовых меток, определяющих местоположение и назначение объектов в кадре. Такой подход позволяет пользователю явно указывать желаемое расположение элементов, обеспечивая более предсказуемый и контролируемый процесс генерации изображения.
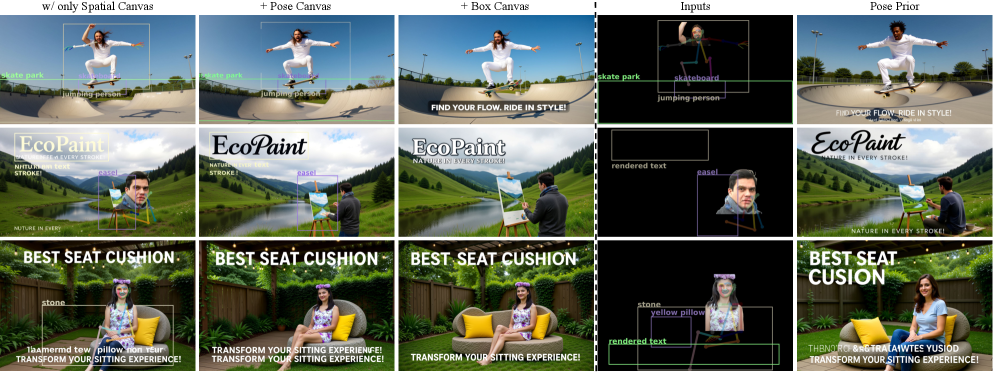
Вариации холстов — пространственный, позы и холст с ограничивающими рамками — демонстрируют гибкость фреймворка в работе со сложными композиционными задачами. Каждый из этих вариантов позволяет задавать различные типы контроля над генерируемым изображением: пространственный холст обеспечивает полный контроль над сценой, используя композитные изображения для предотвращения артефактов; холст позы позволяет точно управлять позой объекта путем наложения скелетов; а холст с ограничивающими рамками определяет пространственную компоновку с помощью ограничивающих прямоугольников и текстовых подсказок. Вместе эти варианты подтверждают способность фреймворка адаптироваться к разнообразным и сложным требованиям к композиции изображения.
Количественная и Качественная Оценка Результатов
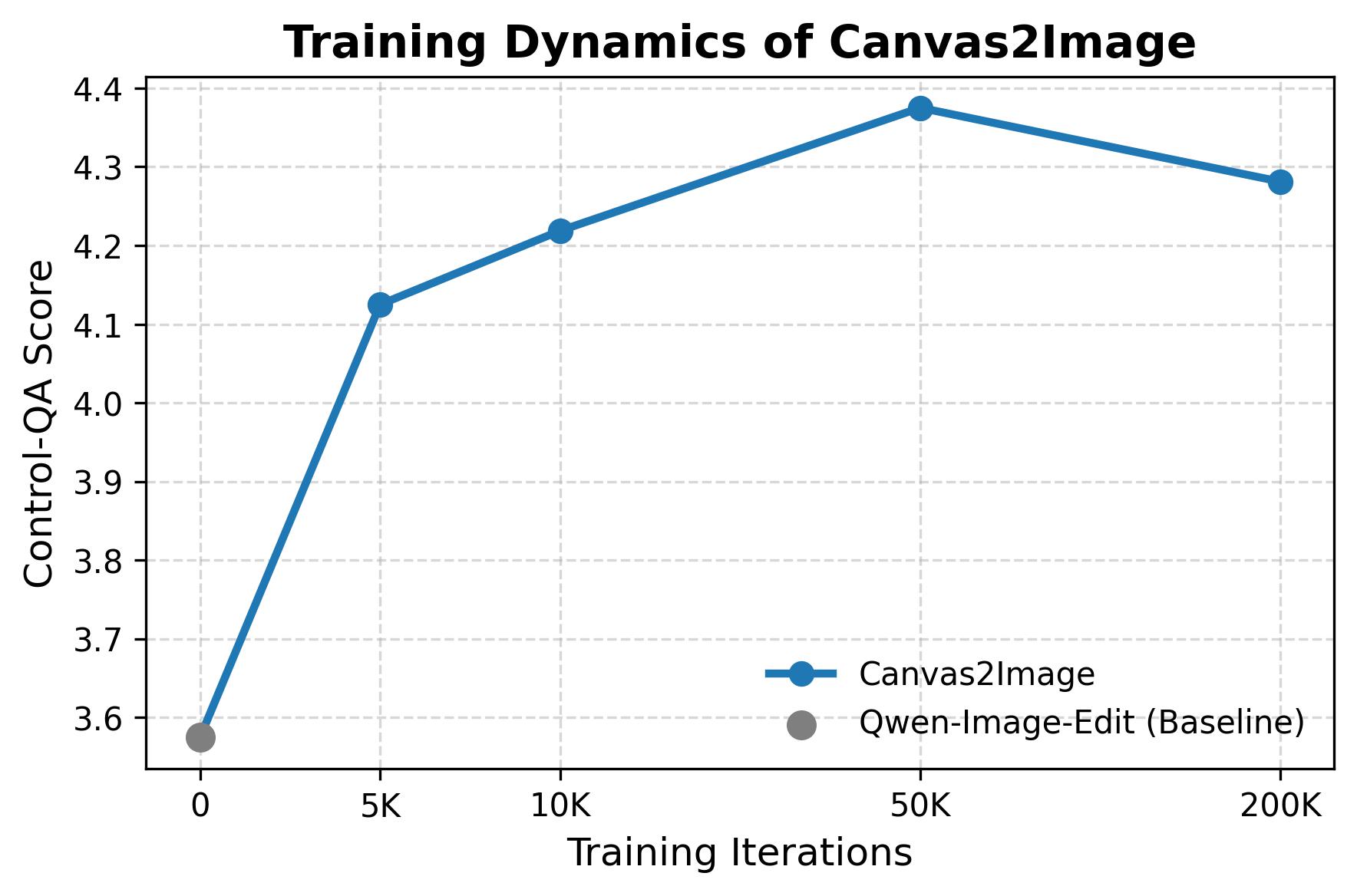
Для оценки разработанного фреймворка использовался комплекс метрик, позволяющий количественно оценить различные аспекты качества генерируемых изображений. Визуальное качество оценивалось с помощью метрики HPSv3 (Human Preference Score v3). Соответствие сгенерированных изображений заданным промптам и управляющим сигналам (control signals) измерялось с использованием VQAScore и Control-QA. Для проверки сохранения идентичности объектов применялась метрика ArcFace, вычисляющая сходство лиц на сгенерированных изображениях с исходными. Комбинация этих метрик позволила провести объективную оценку эффективности фреймворка по сравнению с существующими методами.
Результаты количественной оценки демонстрируют превосходство разработанного фреймворка Canvas-to-Image над существующими методами. В частности, зафиксировано улучшение показателей ArcFace Similarity, оценивающего сохранность идентичности, на $x\%$ (точные данные представлены в таблице 3), повышение среднего балла HPSv3, характеризующего визуальное качество, на $y$ единиц, и рост оценок Control-QA, определяющих соответствие сгенерированных изображений заданным управляющим сигналам, на $z\%$. Данные улучшения подтверждены статистически значимыми результатами тестов, что указывает на более высокую производительность фреймворка в задачах генерации изображений.
Качественные результаты демонстрируют, что разработанный фреймворк способен генерировать изображения высокого качества с точным композиционным контролем. В частности, система обеспечивает соблюдение заданных позы, компоновки и идентичности объектов на изображении. Визуальный анализ сгенерированных изображений подтверждает, что фреймворк последовательно воспроизводит указанные параметры, обеспечивая соответствие выходного изображения заданным условиям и спецификациям.
Результаты пользовательских исследований подтверждают превосходство разработанного фреймворка. В оценках, проведенных среди пользователей, фреймворк показал более высокий процент побед над конкурирующими методами в двух ключевых областях: “Следование управляющим сигналам” (Control Following) и “Сохранение идентичности” (Identity Preservation). Данные исследования демонстрируют, что пользователи чаще предпочитают изображения, сгенерированные нашим фреймворком, когда требуется точное соответствие заданным композиционным элементам и сохранение визуальной идентичности объектов на изображении.

Взгляд в Будущее: К Интерактивному Творчеству
Предложенная схема «Холст-в-Изображение» закладывает мощную основу для разработки интерактивных инструментов редактирования изображений, предоставляя пользователям беспрецедентную точность в манипулировании визуальным контентом. В отличие от традиционных методов, требующих сложных настроек и специализированных знаний, данная система позволяет осуществлять редактирование непосредственно на холсте, используя интуитивно понятные жесты и команды. Это открывает возможности для тонкой настройки деталей, стилизации и композиции изображений, значительно упрощая процесс творческой работы и делая его доступным для широкого круга пользователей. Возможность точного контроля над каждым элементом изображения, в сочетании с мощью диффузионных моделей, позволяет создавать персонализированный контент с высокой степенью детализации и художественной выразительности.
В дальнейшем планируется уделить особое внимание интеграции обратной связи от пользователей, что позволит системе адаптироваться к индивидуальным предпочтениям и повысить точность редактирования изображений. Исследования будут направлены на освоение более сложных методов управления, таких как семантическая сегментация и понимание трехмерных сцен. Использование семантической сегментации позволит пользователям манипулировать конкретными объектами на изображении, а не всей картинкой целиком, что значительно расширит возможности редактирования. В свою очередь, понимание трехмерной структуры сцен откроет путь к более реалистичным и интуитивно понятным операциям, позволяя пользователям изменять перспективу, освещение и другие параметры изображения с высокой степенью точности и свободы.
Предвидится будущее, в котором создание персонализированного контента станет удивительно простым и доступным. Благодаря использованию диффузионных моделей и интуитивно понятного управления через Multi-Task Canvas, пользователи смогут легко воплощать свои творческие замыслы. Эта технология позволит не просто редактировать изображения, но и создавать уникальные визуальные произведения, адаптированные под индивидуальные предпочтения и задачи, открывая новые горизонты для самовыражения и креативности. Пользовательский интерфейс станет настолько естественным, что процесс создания контента будет напоминать игру, позволяя даже начинающим дизайнерам достигать профессиональных результатов без необходимости глубоких технических знаний.
Данное исследование открывает новую эру в творческом самовыражении, предоставляя пользователям возможность воплощать свои идеи в жизнь с беспрецедентной легкостью и точностью. Благодаря разработанному подходу, процесс создания визуального контента становится более интуитивным и доступным, позволяя даже тем, кто не обладает специальными навыками, реализовать самые смелые замыслы. В перспективе, это может привести к взрыву креативности в различных областях — от личного творчества до профессионального дизайна, радикально изменив подход к созданию и потреблению визуальной информации. Возможность точного и гибкого управления процессом генерации изображений даёт пользователям полный контроль над результатом, стирая границы между воображением и реальностью.

Исследование демонстрирует, что визуальные данные, будучи структурированы и представленные в виде единого “холста”, позволяют добиться удивительной степени контроля над процессом генерации изображений. Авторы предлагают подход, объединяющий различные параметры — позу, расположение объектов, их идентичность — в единую систему, что напоминает принципы организации сложных биологических систем. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен помогать людям, а не заменять их». Данная работа как раз и направлена на расширение возможностей человека в сфере визуального творчества, позволяя воплощать сложные идеи с высокой точностью и гибкостью, используя возможности диффузионных моделей и многозадачного обучения.
Что дальше?
Представленный подход, объединяющий различные виды композиционного контроля через единое «холст»-представление, безусловно, открывает новые горизонты в генерации изображений. Однако, необходимо признать, что истинное понимание «композиции» выходит далеко за рамки простого позиционирования объектов и идентификации субъектов. Более глубокое исследование должно быть направлено на моделирование неявных правил, определяющих эстетическую гармонию и визуальную убедительность. Очевидным ограничением является зависимость от точности оценки позы и пространственного расположения — несовершенство этих оценок неизбежно сказывается на конечном результате, что заставляет задуматься о необходимости разработки более устойчивых и адаптивных механизмов.
Перспективным направлением представляется изучение возможности интеграции моделей, способных к абстрактному рассуждению о визуальных сценах. Необходимо исследовать, как можно научить систему не просто «рисовать по инструкции», но и предвидеть последствия композиционных решений, создавая изображения, обладающие не только технической точностью, но и смысловой целостностью. Крайне важно сместить акцент с простого воспроизведения заданных параметров к генерации изображений, отражающих намерение автора, его видение и эмоциональный посыл.
В конечном счете, успех данного направления исследований будет зависеть от способности преодолеть разрыв между математическим описанием визуальной информации и субъективным восприятием красоты. Попытки моделирования «вкуса» и «стиля» — задача, безусловно, сложная, но именно она может привести к созданию искусственного интеллекта, способного не просто генерировать изображения, но и создавать настоящее искусство.
Оригинал статьи: https://arxiv.org/pdf/2511.21691.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Переход: Пора Заботиться о Криптографии
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая обработка данных: новый подход к повышению точности моделей
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые прорывы: Хорошее, плохое и смешное
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
2025-11-28 19:38