Автор: Денис Аветисян
Новое исследование посвящено оптимизации обработки событийных данных в спайковых нейронных сетях для повышения производительности на современных AI-ускорителях.
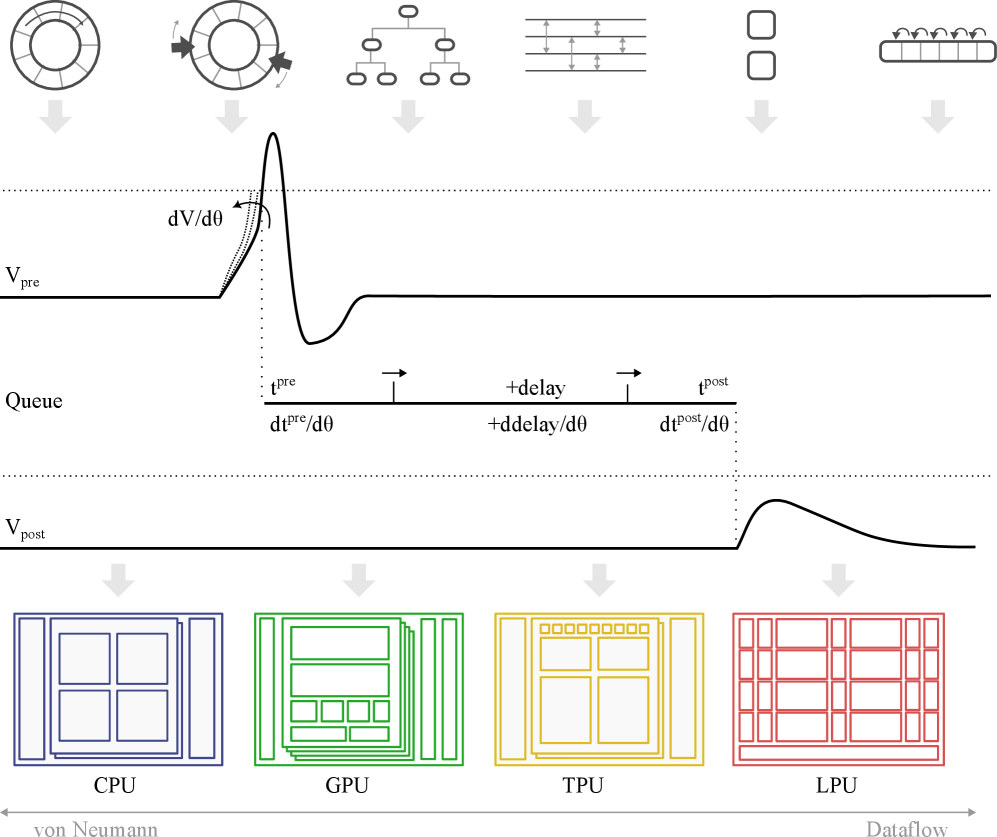
В статье рассматриваются методы реализации дифференцируемых очередей событий, влияющие на скорость и эффективность симуляций мозга на специализированном оборудовании.
Эффективная симуляция и обучение нейронных сетей с импульсной передачей сигналов (SNN), критически важных для вычислительной нейронауки и нейроморфных вычислений, сталкивается с ограничениями по памяти и производительности на современных AI-ускорителях. В работе ‘EventQueues: Autodifferentiable spike event queues for brain simulation on AI accelerators’ представлен анализ и оптимизация очередей событий — ключевого компонента SNN — с поддержкой автоматического дифференцирования. Показано, что выбор структуры данных для этих очередей существенно влияет на производительность на различных платформах, включая CPU, GPU, TPU и LPU, и что разные архитектуры выигрывают от различных подходов. Какие возможности для дальнейшей оптимизации и адаптации этих структур данных откроются с развитием новых autograd-фреймворков и аппаратных решений?
Биологический импульс: Новый подход к вычислениям
Традиционные искусственные нейронные сети, созданные на основе архитектуры фон Неймана, сталкиваются с существенными ограничениями в эффективности энергопотребления и обработке временных данных. В основе этих сетей лежит последовательная обработка информации, где каждое вычисление выполняется строго по порядку, что требует значительных вычислительных ресурсов и энергии. Эта архитектура, изначально предназначенная для универсальных вычислений, не оптимальна для задач, требующих параллельной обработки и быстрого реагирования на изменения во времени. В частности, обработка временных рядов, таких как речь или видео, требует постоянного потока вычислений, что приводит к высокой нагрузке на процессор и, как следствие, к повышенному энергопотреблению. В отличие от этого, биологические нейронные сети, вдохновляющие новые подходы к искусственному интеллекту, работают асинхронно и событийно, что позволяет им обрабатывать информацию гораздо эффективнее и быстрее реагировать на динамические изменения окружающей среды.
Нейронные сети с импульсами, или SNN, представляют собой принципиально иной подход к вычислениям, вдохновленный биологической нейронной сетью мозга. В отличие от традиционных искусственных нейронных сетей, работающих на основе непрерывных значений, SNN используют дискретные импульсы — «спайки» — для передачи информации. Коммуникация между нейронами в SNN является асинхронной и событийно-ориентированной: нейрон активируется и посылает сигнал только при достижении определенного порога возбуждения. Такая модель позволяет значительно снизить энергопотребление, поскольку вычисления происходят только при необходимости, а не постоянно, как в классических сетях. Более того, асинхронная природа SNN позволяет эффективно обрабатывать временные данные и сложные последовательности, имитируя естественные процессы обработки информации в мозге.
Нейронные сети с импульсами (SNN) представляют собой перспективный подход к вычислениям, предлагающий существенные преимущества в энергоэффективности и обработке временных данных. В отличие от традиционных искусственных нейронных сетей, которые потребляют энергию постоянно, SNN работают по принципу «по требованию», активируясь только при поступлении значимых сигналов. Это позволяет значительно снизить энергопотребление, особенно в задачах, требующих обработки больших объемов данных в реальном времени. Способность SNN эффективно обрабатывать временные зависимости открывает возможности для создания новых приложений в таких областях, как распознавание речи, анализ сенсорных данных, робототехника и автономные системы. Использование асинхронной, событийной коммуникации, подобной той, что наблюдается в биологических нейронных сетях, позволяет SNN эффективно извлекать и обрабатывать информацию, закодированную во временных паттернах, что делает их особенно подходящими для задач, где важна последовательность событий и их продолжительность. В перспективе, SNN могут стать основой для создания интеллектуальных устройств с низким энергопотреблением и высокой производительностью, способных к адаптивному обучению и эффективной обработке сложных временных данных.
Очереди событий: Дирижируя временными рамками импульсов
Очередь событий является критически важным компонентом в сетях с импульсными нейронами (SNN), обеспечивая корректную доставку импульсов между нейронами и, следовательно, правильную временную динамику сети. В SNN информация передается в виде дискретных событий (импульсов) во времени, а очередь событий выступает в роли буфера, упорядочивающего и направляющего эти импульсы к соответствующим нейронам. Без эффективной очереди событий, временные задержки и несогласованности в доставке импульсов могут привести к неверной обработке информации и некорректной работе всей нейронной сети. Точное соблюдение временных взаимосвязей между импульсами является ключевым для реализации биологически правдоподобных вычислительных моделей и достижения высокой производительности SNN.
Для управления доставкой спайков между нейронами в SNN существуют различные реализации очередей событий, каждая из которых имеет свои компромиссы в производительности. Простейшие структуры, такие как FIFO (First-In, First-Out) очереди, обеспечивают минимальную задержку, но требуют значительных затрат памяти. Сортированные массивы позволяют быстро находить спайки с минимальной задержкой, но требуют затрат на поддержание порядка при добавлении новых событий. Более сложные структуры, такие как двоичные кучи (Binary Heaps) и кольцевые буферы (Ring Buffers), предлагают баланс между скоростью доступа и использованием памяти. Выбор конкретной реализации зависит от архитектуры SNN, доступных ресурсов и требований к производительности. Например, для систем с ограниченной памятью могут быть предпочтительны кольцевые буферы, а для систем, требующих минимальной задержки, — сортированные массивы.
Наши исследования показали, что выбор реализации очереди событий существенно влияет на производительность нейронных сетей с импульсными сигналами (SNN). В частности, на TPU реализации с использованием отсортированных массивов демонстрируют прирост производительности на несколько порядков величины по сравнению с другими подходами. Для GPU эффективными оказываются FIFO-структуры при условии управления объемом используемой памяти. Более продвинутые реализации, такие как очереди с потерями (Lossy Event Queues) и очереди для одиночных импульсов (Single Spike Queues), предлагают специализированные функциональные возможности для конкретных архитектур SNN и ограничений по ресурсам.

Обучение SNN: Преодолевая градиентный барьер
Традиционные методы обучения на основе градиентного спуска, являющиеся основой современного глубокого обучения, сталкиваются с существенными трудностями при применении к спайковым нейронным сетям (SNN). Это связано с тем, что функция активации нейрона в SNN, основанная на дискретных спайках, не является дифференцируемой. В отличие от непрерывных значений в традиционных нейронных сетях, спайки представляют собой бинарные события (спайк произошел или не произошел), что делает невозможным прямое вычисление градиента ошибки по отношению к весам сети. Отсутствие дифференцируемости препятствует применению стандартных алгоритмов обратного распространения ошибки и требует разработки альтернативных подходов к обучению SNN.
Метод суррогатных градиентов представляет собой обходной путь для обучения спиковых нейронных сетей (SNN), возникающий из-за недифференцируемости событий спайков. В основе метода лежит замена функции производной от недифференцируемого импульса на дифференцируемую аппроксимацию. Это позволяет использовать стандартные алгоритмы оптимизации, такие как обратное распространение ошибки, для эффективной настройки параметров сети. Различные варианты суррогатных градиентов используют разные функции аппроксимации, влияющие на скорость сходимости и точность обучения. Несмотря на то, что данный подход является приближенным, он обеспечивает приемлемый компромисс между вычислительной эффективностью и точностью, что делает его широко распространенным в практике обучения SNN.
Методы, такие как EventProp, позволяют вычислять точные градиенты, проходящие через импульсные события (спайки) в сетях спайковых нейронов (SNN). В отличие от использования суррогатных градиентов, которые аппроксимируют производные, EventProp стремится к аналитическому вычислению $ \frac{\partial Loss}{\partial weight} $ через дискретные события спайков. Это обеспечивает более высокую точность обучения, особенно в задачах, чувствительных к деталям временных характеристик. Однако, вычисление точных градиентов требует значительных вычислительных ресурсов и может существенно увеличить время обучения по сравнению с методами, использующими суррогатные градиенты, что делает EventProp более подходящим для задач, где приоритетом является точность, а не скорость обучения.
Аппаратное ускорение для эффективных вычислений SNN
Традиционные графические процессоры (GPU), изначально разработанные для выполнения плотных матричных операций, всё чаще применяются в обучении спиковых нейронных сетей (SNN). Однако, их эффективность оказывается ограниченной из-за присущей SNN разреженной, событийной природы вычислений. В отличие от традиционных нейронных сетей, где большая часть вычислений выполняется непрерывно, SNN активно обмениваются информацией только при возникновении событий — «спайков». Это приводит к тому, что GPU тратят значительные ресурсы на обработку пустых данных или ожидание событий, что снижает общую производительность и энергоэффективность. Несмотря на широкое распространение и гибкость GPU, их архитектура не оптимальна для эффективной обработки разреженных данных, характерных для SNN, что требует поиска альтернативных аппаратных решений для реализации всего потенциала спиковых вычислений.
Специализированные аппаратные решения, такие как тензорные процессоры (TPU) и линейные процессоры Groq (LPU), демонстрируют значительное увеличение производительности при работе с нейронными сетями с импульсной передачей (SNN). В отличие от традиционных графических процессоров, оптимизированных для плотных матричных вычислений, эти устройства используют архитектуру, основанную на потоке данных, что позволяет эффективно обрабатывать разреженные, событийные данные, характерные для SNN. В частности, исследования показывают, что реализации, использующие отсортированные массивы, превосходят другие подходы на TPU по производительности на несколько порядков величины. Это обусловлено тем, что отсортированные массивы оптимизированы для быстрого поиска и обработки событий, что является ключевой операцией в SNN. Таким образом, использование специализированного оборудования открывает путь к созданию энергоэффективных и высокопроизводительных систем искусственного интеллекта, способных решать сложные задачи в реальном времени.
Сочетание эффективного управления очередью событий, передовых методов обучения и специализированного аппаратного обеспечения открывает новую эру в вычислениях, характеризующуюся низким энергопотреблением и высокой производительностью. Оптимизация обработки разреженных событий, характерных для нейронных сетей с импульсной активностью, в сочетании с алгоритмами, адаптированными к особенностям данной архитектуры, позволяет существенно снизить вычислительные затраты. Внедрение специализированных процессоров, таких как тензорные процессоры и блоки обработки данных, спроектированных для эффективной работы с разреженными данными, обеспечивает значительный прирост скорости и энергоэффективности по сравнению с традиционными графическими процессорами. Такой синергетический подход позволяет создавать системы искусственного интеллекта, способные к обработке информации в режиме реального времени при минимальном энергопотреблении, что особенно важно для мобильных устройств и периферийных вычислений.
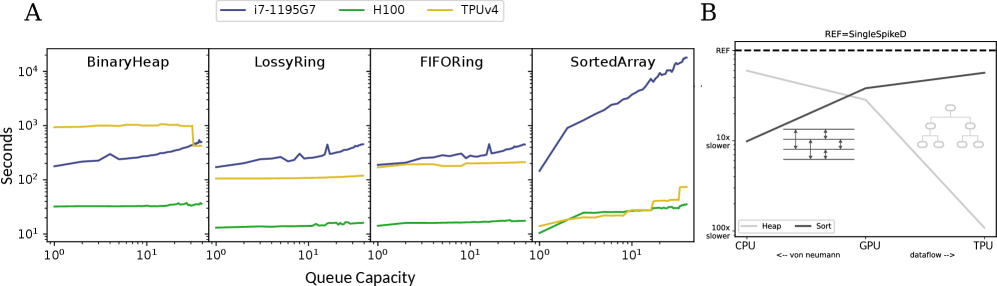
За пределами основ: Расширяя возможности SNN
Введение задержек в доставку спайков, особенно гетерогенных, открывает возможности для реализации сложных механизмов временной обработки и памяти в нейронных сетях. В отличие от традиционных моделей, где информация передается мгновенно, искусственное введение задержек позволяет нейронам учитывать предшествующие события и формировать внутреннее представление о временных зависимостях. Различные задержки для разных синапсов — гетерогенность — критически важна, поскольку позволяет сети различать порядок и продолжительность стимулов, имитируя таким образом принципы работы биологических нейронных сетей. Этот подход позволяет создавать системы, способные не только распознавать паттерны, но и предсказывать будущие события, эффективно обрабатывать временные ряды и сохранять информацию о прошлом, что является ключевым для решения задач, требующих контекстной осведомленности и адаптации к изменяющимся условиям.
Оптимизация реализации очередей событий играет ключевую роль в повышении производительности и масштабируемости нейронных сетей с импульсной передачей данных (SNN), особенно при использовании задержек в доставке импульсов. Исследования показывают, что увеличение емкости очереди, как правило, приводит к незначительному увеличению времени выполнения, однако реализация на основе сортированного массива ($SortedArray$) демонстрирует ухудшение производительности при увеличении объема данных. Это связано с тем, что поддержание отсортированного порядка в очереди требует значительных вычислительных затрат, которые становятся критичными при большом количестве событий. Таким образом, выбор оптимальной структуры данных для организации очереди событий является важным фактором, определяющим эффективность работы SNN с временной обработкой и памятью.
Современные нейроморфные системы, основанные на импульсных нейронных сетях (SNN), находятся на пороге новой эры интеллектуальных технологий. Сочетание прогрессивных архитектур SNN, позволяющих моделировать сложные когнитивные процессы, с разработкой специализированного, энергоэффективного оборудования, и инновационными методами обучения, такими как спайковый обратный проход и обучение с подкреплением, открывает перспективы для создания принципиально новых систем искусственного интеллекта. Ожидается, что это приведет к появлению устройств, способных к адаптивному обучению в реальном времени, эффективной обработке сенсорной информации и решению сложных задач с минимальным энергопотреблением, что значительно превосходит возможности традиционных искусственных нейронных сетей и приближает нас к созданию действительно интеллектуальных машин.
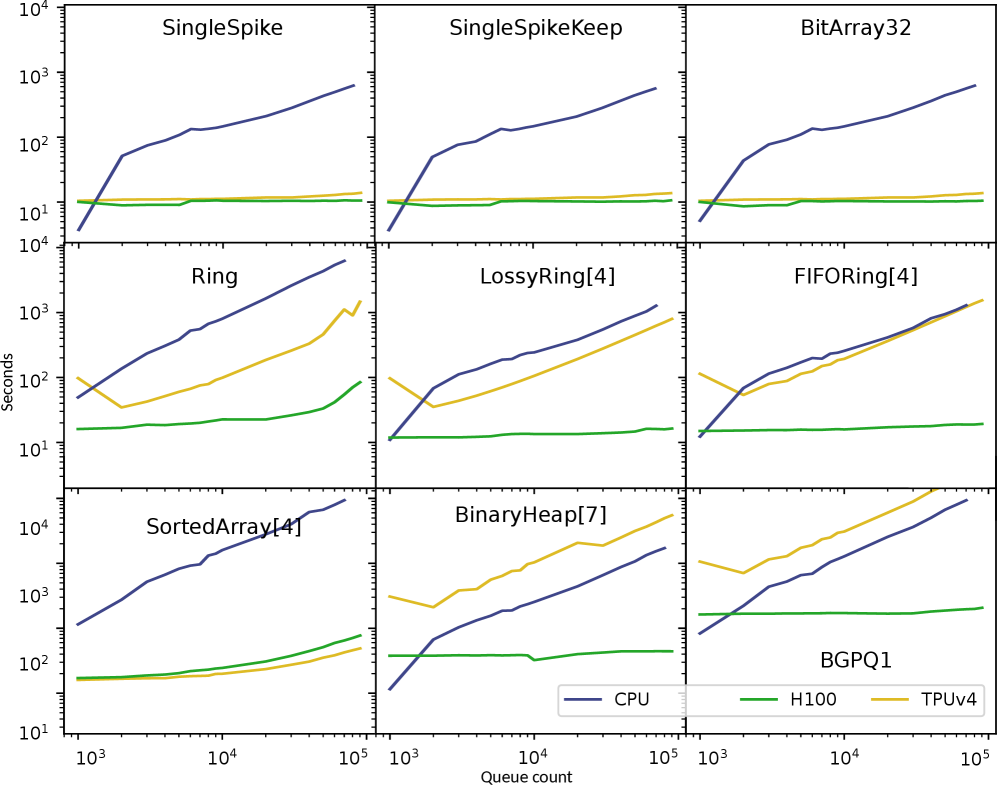
Исследование, представленное в статье, демонстрирует, что выбор структуры данных для обработки событий в спайковых нейронных сетях критически влияет на производительность и эффективность вычислений на AI-ускорителях. Это подчеркивает важность глубокого понимания внутренних механизмов систем, с которыми работает исследователь. Как заметил Дональд Кнут: «Преждевременная оптимизация — корень всех зол». Данное высказывание особенно актуально в контексте neuromorphic computing, где оптимизация на уровне структуры данных и архитектуры может принести существенный выигрыш, но требует тщательного анализа и понимания принципов работы системы прежде, чем приступать к реализации.
Куда же дальше?
Представленные исследования, по сути, лишь обнажили глубину проблемы: эффективная симуляция спайковых нейронных сетей на современных ускорителях — это не столько вопрос оптимизации алгоритмов, сколько реверс-инжиниринг самой концепции «события». Выбор структуры данных для очередей событий оказался критичным, но это лишь симптом. Настоящая задача — понять, как архитектура ускорителя диктует оптимальную организацию информации, а не наоборот. Каждый «патч» в виде новой структуры данных — это философское признание несовершенства текущего подхода.
Очевидно, что универсального решения не существует. Специализированные архитектуры требуют специфических решений, а значит, абстракция от «железа» — иллюзия. Следующим шагом видится не столько поиск идеальной структуры данных, сколько разработка компиляторов, способных автоматически адаптировать алгоритмы к конкретному ускорителю. Или, возможно, стоит пересмотреть саму парадигму симуляции, отказавшись от строгой эмуляции биологических процессов в пользу более абстрактных, но эффективных моделей.
В конечном счете, лучший «хак» — это осознанность того, как всё работает. Понимание того, что «задержка» — это не ошибка, а неотъемлемая часть системы, а «разреженность» — это не ограничение, а возможность, позволит создать действительно масштабируемые и энергоэффективные спайковые нейронные сети. И тогда, возможно, мы сможем приблизиться к созданию машин, которые не просто имитируют мозг, но и превосходят его в определенных задачах.
Оригинал статьи: https://arxiv.org/pdf/2512.05906.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2025-12-09 04:56