Автор: Денис Аветисян
Исследователи предлагают метод, позволяющий значительно улучшить процесс обучения больших языковых моделей за счет повышения стабильности и эффективности алгоритмов обучения с подкреплением.
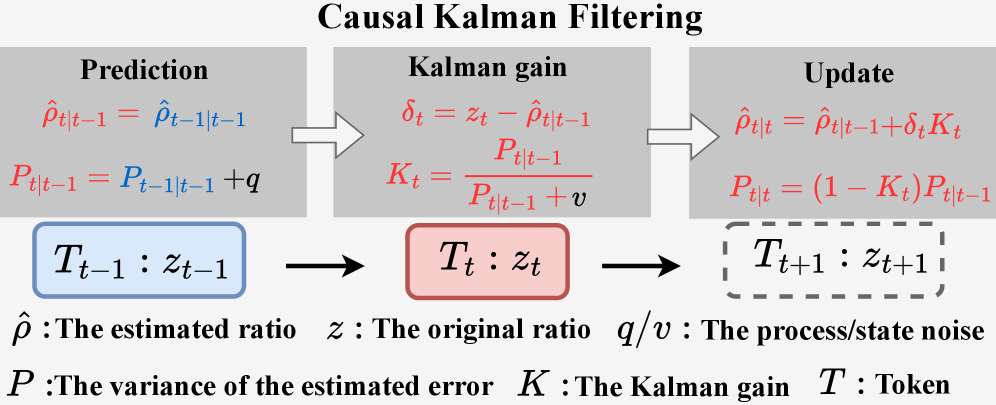
В статье представлен KPO — алгоритм, использующий фильтр Калмана для сглаживания оценок важности при обучении языковых моделей с подкреплением и сохранения локальной связности.
Обучение с подкреплением для больших языковых моделей часто сталкивается с высокой дисперсией оценок важности на уровне токенов, что дестабилизирует оптимизацию стратегии в масштабе. В данной работе, посвященной ‘Online Causal Kalman Filtering for Stable and Effective Policy Optimization’, впервые эмпирически выявлена структурная непоследовательность локальных отклонений от политики на уровне токенов, приводящая к искажению градиентных обновлений и коллапсу обучения. Для решения этой проблемы предлагается метод KPO, основанный на фильтре Кальмана, моделирующем желаемое отношение важности как латентное состояние, эволюционирующее во времени и обновляемое онлайн на основе состояний предыдущих токенов. Сможет ли KPO обеспечить более стабильное и эффективное обучение языковых моделей и открыть новые возможности для решения сложных задач рассуждений?
Стабильность обучения вне политики: вызовы и перспективы
Обучение с подкреплением представляет собой перспективный путь для дальнейшего совершенствования больших языковых моделей после их предварительного обучения, однако эффективность этого подхода существенно ограничивается нестабильностью, возникающей в сценариях обучения вне политики (off-policy). В то время как предварительное обучение позволяет моделям усваивать общие языковые закономерности, обучение с подкреплением способно адаптировать их к конкретным задачам и целям. Проблема заключается в том, что стандартные алгоритмы обучения с подкреплением часто демонстрируют нестабильное поведение при использовании данных, собранных другой политикой, что приводит к снижению производительности и трудностям в достижении оптимальных результатов. Эта нестабильность особенно заметна при работе со сложными моделями, такими как большие языковые модели, и требует разработки новых методов для обеспечения устойчивого и эффективного обучения.
Традиционные методы обучения с подкреплением, такие как GRPO, сталкиваются с серьезными трудностями при работе с большими языковыми моделями. В частности, наблюдается тенденция к «схлопыванию энтропии», когда политика становится слишком детерминированной и теряет способность к исследованию пространства решений. Это усугубляется высокой дисперсией градиентов политики, что затрудняет стабильное обучение. Особую проблему представляют архитектуры, основанные на Mixture-of-Experts (MoE), где дискретность выбора экспертов приводит к резким изменениям в политике и, как следствие, к нестабильности процесса обучения. Данные недостатки ограничивают эффективность GRPO при адаптации больших языковых моделей, требуя разработки более устойчивых алгоритмов.
Нестабильность обучения с подкреплением в отрыве от текущей политики (off-policy learning) усугубляется расхождениями между условиями обучения и применения модели. Во время обучения, алгоритмы могут оперировать с высокой точностью вычислений и доступом к большим объемам данных, тогда как в процессе использования, модель функционирует в условиях ограниченных ресурсов и потенциально менее точных вычислений. Эта разница создает сложности, поскольку политика, оптимизированная в идеальных условиях обучения, может демонстрировать значительное снижение производительности при развертывании. Кроме того, ограничения численной точности, связанные с использованием форматов данных с плавающей точкой, могут приводить к накоплению ошибок и дальнейшей дестабилизации процесса обучения, особенно в сложных моделях, таких как те, что основаны на Mixture-of-Experts, где даже незначительные отклонения могут приводить к резким изменениям в поведении.

KPO: фильтр Калмана для оптимизации политики
KPO (Kalman Policy Optimization) представляет собой новый подход к оптимизации политик, использующий онлайн-фильтр Калмана для оценки истинного коэффициента важности (importance sampling ratio). В отличие от традиционных методов, KPO не вычисляет коэффициент важности напрямую, а моделирует его как состояние в пространстве состояний. Это позволяет фильтру Калмана последовательно обновлять оценку коэффициента важности на основе поступающих данных, снижая влияние шума и дисперсии, присущих стандартным методам оценки коэффициентов важности. Применение фильтра Калмана обеспечивает более стабильную и точную оценку, что критически важно для эффективного обучения политик в задачах обучения с подкреплением.
В KPO, отношение важности (Importance Sampling Ratio) рассматривается как состояние в модели пространства состояний, что позволяет получить сглаженную и стабильную оценку. Применение фильтра Калмана в режиме онлайн позволяет снизить влияние шума и дисперсии, присущих традиционным методам оценки IS-отношения. В частности, фильтр рекурсивно обновляет оценку IS-отношения, объединяя предсказания модели с поступающими наблюдениями, тем самым эффективно уменьшая погрешность и повышая надежность оценки в процессе оптимизации политики. Это позволяет KPO более точно оценивать вклад различных действий в общую награду и, следовательно, улучшать процесс обучения агента.
Метод KPO решает проблемы, связанные с использованием фиксированного коэффициента важности на уровне последовательности (Sequence-Level IS Ratio), который часто страдает от высокой дисперсии и неустойчивости. В отличие от GRPO, полагающегося на этот фиксированный коэффициент, KPO применяет онлайн-фильтр Калмана для динамической оценки истинного коэффициента важности, что позволяет снизить его дисперсию и повысить стабильность обучения. Это расширяет возможности GRPO, обеспечивая более надежную и эффективную оптимизацию политики, особенно в задачах с длинными последовательностями действий и сложными функциями вознаграждения. Использование фильтра Калмана позволяет KPO адаптироваться к изменяющимся условиям и более точно оценивать вклад каждого действия в общую стратегию.

Характеризация динамики IS-отношения с помощью статистики токенов
Метод KPO использует ключевые статистические характеристики поведения токенов — длину последовательности токенов (Token Run-Length), частоту переключения токенов (Token Switching Frequency) и долю низкочастотных токенов (Low-Frequency Ratio) — для моделирования динамических свойств коэффициента IS. Длина последовательности токенов отражает продолжительность последовательностей одного и того же токена, частота переключения токенов определяет скорость смены токенов в потоке, а доля низкочастотных токенов указывает на процент токенов, встречающихся редко. Совместное использование этих статистических данных позволяет KPO создавать более точную и надежную модель динамики коэффициента IS, что является основой для последующей фильтрации и повышения точности оценок.
Статистические показатели, такие как длина последовательности токенов, частота переключения токенов и доля низкочастотных токенов, предоставляют информацию о стабильности и предсказуемости коэффициента IS (Inter-Symbol Ratio). Высокая стабильность коэффициента IS позволяет фильтру Калмана более точно оценивать его текущее и будущее значения, поскольку уменьшается неопределенность, связанная с изменениями этого коэффициента. Использование этих статистических данных в модели пространства состояний повышает надежность оценок, особенно в условиях шумов и помех, что приводит к улучшению производительности системы. Чем более предсказуем коэффициент IS, тем эффективнее фильтр Калмана может сглаживать шум и выделять полезный сигнал.
Метод KPO повышает устойчивость и точность моделирования динамики IS-отношения за счет включения в модель пространства состояний шума наблюдений и шума процесса, что позволяет учитывать присущие системе неопределенности. В результате применения фильтрации наблюдается значительное увеличение коэффициента низкой частоты (Low-Frequency Ratio) с 0.12 до 0.98, что свидетельствует о существенном улучшении стабильности и предсказуемости моделируемого процесса.

Влияние и перспективы развития
Экспериментальные результаты демонстрируют, что предложенный метод KPO значительно повышает стабильность процесса обучения, снижает дисперсию и обеспечивает улучшенные показатели производительности по сравнению с базовыми подходами. Особенно заметно превосходство KPO при работе с моделями, такими как Qwen3-4B, где наблюдается более устойчивое схождение и повышение точности решения задач. Данное свойство особенно важно в контексте обучения больших языковых моделей, где нестабильность может приводить к значительным затратам ресурсов и снижению качества генерируемого текста. Полученные данные указывают на потенциал KPO в качестве эффективного инструмента для оптимизации обучения и повышения надежности LLM.
Результаты экспериментов демонстрируют превосходство KPO над алгоритмом GSPO в различных бенчмарках, что подтверждается достигнутыми показателями Avg@16. В частности, KPO показал результат 37.91 на AIME’24, 36.87 на AIME’25, впечатляющие 87.50 на AMC’23, 89.42 на MATH500 и 54.06 на OlympiadBench. Эти цифры наглядно иллюстрируют способность KPO эффективно решать сложные задачи, требующие логического мышления и математических навыков, и свидетельствуют о его потенциале для дальнейшего развития в области обучения больших языковых моделей.
Предложенный метод, KPO, представляет собой существенный прорыв в области обучения с подкреплением вне политики для больших языковых моделей. В отличие от традиционных подходов, KPO позволяет значительно повысить стабильность процесса обучения и снизить его вариативность, что, в свою очередь, приводит к более эффективному использованию вычислительных ресурсов и сокращению времени, необходимого для достижения желаемых результатов. Это открывает возможности для создания более надежных и производительных языковых моделей, способных успешно решать сложные задачи, и закладывает основу для разработки более совершенных и масштабируемых конвейеров обучения, которые могут быть адаптированы к широкому спектру приложений и архитектур.
Дальнейшие исследования KPO могут быть направлены на расширение его применимости к более сложным задачам и архитектурам больших языковых моделей. Особый интерес представляет изучение адаптивных стратегий моделирования шума, позволяющих динамически настраивать процесс обучения в зависимости от характеристик решаемой задачи и поведения модели. Это позволит не только повысить устойчивость обучения, но и оптимизировать производительность KPO в различных условиях, открывая новые возможности для эффективного обучения LLM в сложных и непредсказуемых средах. Такой подход может значительно улучшить обобщающую способность моделей и способствовать созданию более надежных и интеллектуальных систем.
Исследование представляет собой элегантный подход к стабилизации обучения с подкреплением для больших языковых моделей. Авторы демонстрируют, как фильтр Калмана, применяемый к весам важности токенов, позволяет сгладить процесс обучения и сохранить локальную связность последовательностей. Этот метод, названный KPO, направлен на решение проблемы нестабильности, часто возникающей при обучении языковых моделей вне политики. Как заметил Пол Эрдёш: «Математика — это не просто решение задач, это искусство находить красоту и гармонию в числах и структурах». В данном исследовании красота проявляется в простоте и эффективности предложенного алгоритма, который позволяет находить баланс между стабильностью и производительностью в сложных системах обучения.
Куда Далее?
Представленная работа, стремясь к стабилизации внеполисной оптимизации обучения с подкреплением для больших языковых моделей, лишь приоткрывает дверь в сложный лабиринт нерешенных вопросов. Успех предложенного подхода, основанного на фильтре Кальмана, заставляет задуматься: что на самом деле оптимизируется — локальная когерентность последовательностей или фундаментальная стабильность процесса обучения? Простота, в данном случае, не минимализм, а ясное разграничение необходимого от случайного в потоке вероятностных оценок.
Очевидным направлением для дальнейших исследований представляется адаптация предложенного метода к задачам, требующим долгосрочного планирования и учета сложных зависимостей. Ключевым вызовом остаётся преодоление расхождения между моделью и реальностью, особенно в условиях неполной информации и стохастической природы языка. Необходимо исследовать возможности комбинирования фильтра Кальмана с другими методами, такими как байесовское обучение и мета-обучение, для создания более робастных и адаптивных систем.
В конечном итоге, истинный прогресс потребует не только совершенствования алгоритмов, но и глубокого переосмысления самой парадигмы обучения с подкреплением. Нужно задаться вопросом: достаточно ли просто сглаживать шум в оценках важности, или необходимо принципиально пересмотреть подход к представлению и обработке информации в больших языковых моделях? Ответ, вероятно, кроется в элегантном дизайне, рожденном из простоты и ясности.
Оригинал статьи: https://arxiv.org/pdf/2602.10609.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Квантовый Переворот: От Теории к Реальности
- Видео-Мыслитель: гармония разума и визуального потока.
- Оптимизация квантовых схем: новый алгоритм для NISQ-устройств
- Язык тела под присмотром ИИ: архитектура и гарантии
- Плоские зоны: от теории к новым материалам
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
2026-02-12 18:40