Автор: Денис Аветисян
Исследователи представили Fast-FoundationStereo, систему, способную быстро и точно находить соответствия между изображениями, используя возможности современных нейронных сетей.

Метод обеспечивает высокую производительность и обобщающую способность в задачах стереосопоставления благодаря эффективному использованию и ускорению существующих фундаментальных моделей.
Существующие модели стерео-сопоставления, демонстрирующие высокую обобщающую способность, зачастую непрактичны для задач реального времени. В данной работе представлена система Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching, которая сочетает в себе точность и скорость, достигая производительности в реальном времени без ущерба для обобщающей способности. Это стало возможным благодаря применению стратегии ускорения, включающей дистилляцию знаний, автоматический поиск архитектуры и структурированное отсечение избыточности. Сможет ли предложенный подход стать основой для новых, высокопроизводительных систем компьютерного зрения в различных приложениях?
Вызов точного стереосопоставления: Преодоление границ обобщения
Традиционные методы стереосопоставления часто сталкиваются с трудностями при адаптации к новым, ранее не встречавшимся окружениям и сложным сценам. Это связано с тем, что большинство алгоритмов обучаются на ограниченном наборе данных, что снижает их способность обобщать полученные знания и корректно работать в условиях, отличающихся от тренировочных. Например, алгоритм, хорошо работающий на четких изображениях в контролируемой среде, может давать значительные ошибки при обработке изображений с плохим освещением, шумами или сложной геометрией объектов. Данное ограничение существенно препятствует широкому применению стереосопоставления в реальных приложениях, таких как автономная навигация роботов, беспилотные автомобили и дополненная реальность, где окружающая среда постоянно меняется и требует высокой степени надежности и адаптивности системы.
Существующие методы стереосопоставления часто сталкиваются с ограничениями, обусловленными зависимостью от обширных наборов обучающих данных. Многие алгоритмы демонстрируют снижение производительности при работе с изображениями, значительно отличающимися от тех, на которых они были обучены. Кроме того, эффективная интеграция монокулярной и стереоскопической информации представляет собой сложную задачу. Алгоритмы, полагающиеся исключительно на стереоданные, могут быть уязвимы к шуму и окклюзиям, в то время как использование только монокулярной информации не позволяет восстановить глубину сцены с достаточной точностью. Успешное решение требует разработки методов, способных эффективно объединять оба типа данных, используя преимущества каждого из них для повышения надежности и адаптивности системы в различных условиях освещения и геометрии сцены.
Достижение одновременно высокой точности и адаптивности представляет собой серьезную проблему в области компьютерного зрения. Существующие алгоритмы стереосопоставления часто демонстрируют впечатляющие результаты на ограниченных наборах данных, но испытывают трудности при переходе к новым, ранее не встречавшимся условиям освещения, текстур или геометрии сцены. Это связано с тем, что большинство методов полагаются на статистические закономерности, выученные из обучающих данных, и не способны эффективно обобщать знания на незнакомые ситуации. Таким образом, разработка алгоритмов, которые могли бы надежно работать в различных условиях и обеспечивать высокую точность сопоставления даже в сложных сценах, остается актуальной задачей, требующей инновационных подходов к обработке и интерпретации визуальной информации.
FoundationStereo: Применение априорных знаний для преодоления ограничений
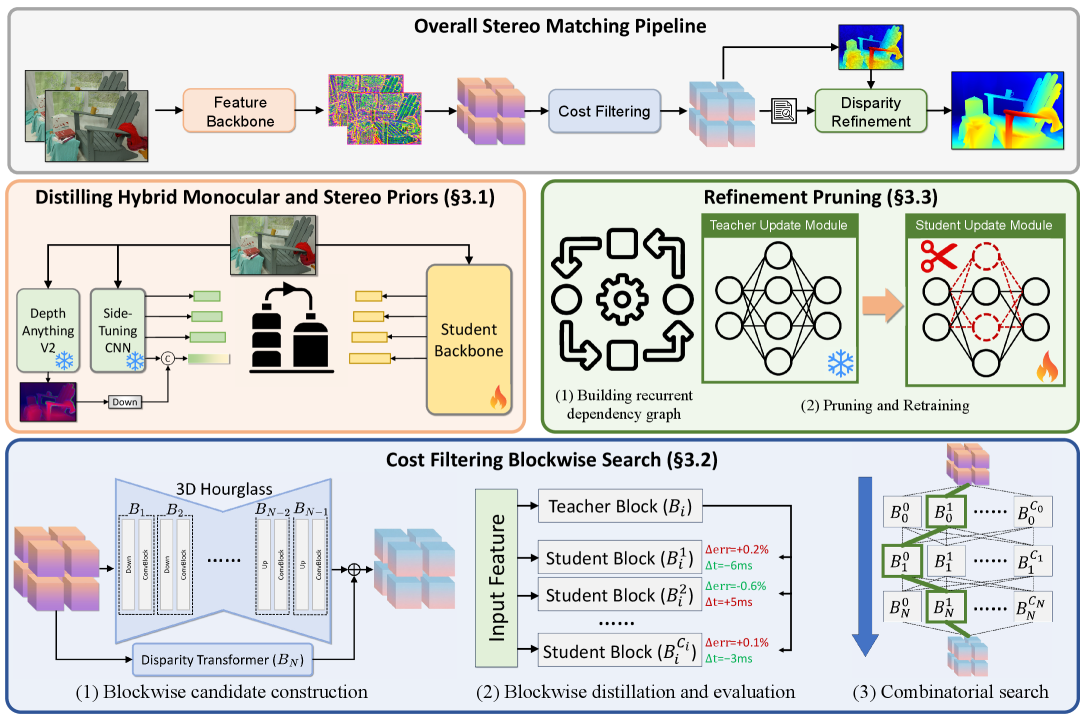
FoundationStereo представляет собой новую структуру для сопоставления стереопар изображений, которая интегрирует богатые априорные знания, полученные из модели DepthAnythingV2. Данная модель, предварительно обученная для оценки глубины по монокулярному изображению, позволяет использовать информацию о вероятной структуре сцены и геометрии объектов. Интеграция этих монокулярных априорных знаний в процесс сопоставления стереопар способствует повышению точности и надежности оценки глубины, особенно в сложных условиях, таких как текстурно-бедные области или при наличии окклюзий. Использование предварительно обученной модели позволяет существенно сократить объем данных, необходимых для обучения системы сопоставления стереопар, и улучшить ее обобщающую способность.
Для эффективной передачи знаний от монокулярной модели DepthAnythingV2 к бинокулярной стереосистеме, используется подход с применением CNN, выполняющей «side-tuning». Этот метод предполагает обучение небольшой сверточной нейронной сети, прикрепленной к замороженной DepthAnythingV2, для адаптации её признаков к особенностям стереосопоставления. В процессе обучения, параметры DepthAnythingV2 остаются фиксированными, что позволяет сохранить её способность к обобщению, а CNN обучается извлекать и преобразовывать признаки, необходимые для точного вычисления карт глубины на основе стереоизображений. Такая архитектура позволяет эффективно использовать предварительно обученные знания, минимизируя потребность в большом объеме размеченных стереоданных для обучения системы с нуля.
Комбинированный подход, использующий как монокулярные, так и стереоскопические сигналы, демонстрирует значительное повышение точности сопоставления, особенно в сложных сценариях, таких как области с недостаточной текстурой или при наличии окклюзий. Интеграция монокулярных оценок глубины, полученных с помощью предварительно обученной модели DepthAnythingV2, позволяет компенсировать недостатки традиционных стереометодов, возникающие при отсутствии чётких соответствий между левым и правым изображениями. В результате, система обеспечивает более надёжные и точные карты глубины даже в условиях, где стандартные алгоритмы стереосопоставления испытывают трудности, что подтверждается экспериментальными данными и количественными метриками производительности.
Обработка объема затрат в FoundationStereo оптимизируется за счет использования осевой планарной свертки (Axial-Planar Convolution) и преобразователя смещения (Disparity Transformer). Осевая планарная свертка позволяет эффективно обрабатывать трехмерные данные, разделяя свертку на отдельные одномерные операции вдоль каждой оси, что снижает вычислительную сложность. Преобразователь смещения использует механизм внимания для моделирования зависимостей между различными смещениями, что повышает точность сопоставления признаков и, как следствие, улучшает качество стереосопоставления. Комбинация этих двух подходов обеспечивает эффективную и точную обработку объема затрат, необходимую для высокопроизводительного стерео зрения.
Fast-FoundationStereo: Оптимизация для работы в реальном времени
Fast-FoundationStereo является развитием архитектуры FoundationStereo и направлена на повышение скорости вычислений при сохранении точности результатов. Достигается это за счет применения ряда оптимизаций, включая дистилляцию знаний, структурированную обрезку и использование рекуррентного графа зависимостей. В отличие от базовой версии, Fast-FoundationStereo позволяет значительно ускорить процесс инференса, что критически важно для приложений реального времени, требующих быстрой обработки стереоизображений. Данные оптимизации позволяют добиться существенного прироста производительности без ущерба для качества получаемой карты глубины.
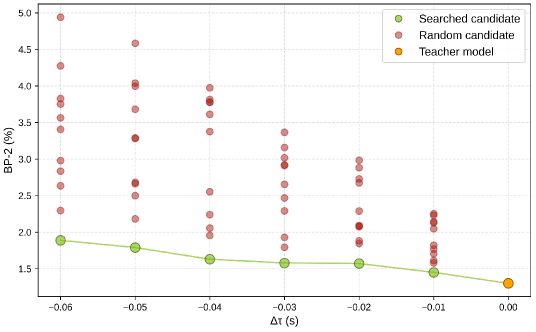
Для повышения скорости обработки в Fast-FoundationStereo применяется метод дистилляции знаний, позволяющий сжать модель без существенной потери точности. Этот подход предполагает обучение более компактной «студенческой» сети на основе знаний, полученных от более крупной и точной «учительской» сети (FoundationStereo). В результате, Fast-FoundationStereo демонстрирует десятикратное увеличение скорости работы ($10\times$) по сравнению с оригинальной моделью FoundationStereo, сохраняя при этом сопоставимое качество получаемых карт глубины.
Для повышения эффективности архитектуры Fast-FoundationStereo применяются методы структурированной обрезки и построение рекуррентного графа зависимостей. Структурированная обрезка позволяет удалять целые фильтры или каналы в сверточных слоях, снижая вычислительную нагрузку без существенной потери точности. Рекуррентный граф зависимостей оптимизирует порядок выполнения операций, выявляя и устраняя избыточные вычисления. Такой подход позволяет более эффективно использовать аппаратные ресурсы и ускорить процесс инференса, что критически важно для приложений реального времени.
Улучшение качества карты расхождений в Fast-FoundationStereo достигается за счет использования сети ConvGRU. Данная рекуррентная нейронная сеть, комбинирующая сверточные и рекуррентные слои, позволяет эффективно обрабатывать пространственную и временную информацию, что особенно важно для точного определения глубины. ConvGRU анализирует промежуточные карты расхождений, полученные на предыдущих этапах, и уточняет их, уменьшая шум и повышая точность определения глубины объектов на изображении. Использование ConvGRU позволяет добиться более гладкой и детализированной карты расхождений, что критически важно для приложений, требующих высокой точности 3D-реконструкции.

Валидация и широкое влияние на область стерео зрения
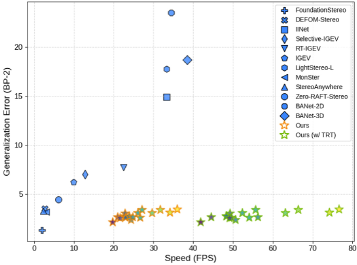
Комплексные оценки, проведенные на широко известных эталонных наборах данных, включая SceneFlow, Middlebury, ETH3D, KITTI и Booster Dataset, однозначно демонстрируют превосходство Fast-FoundationStereo. Систематическое тестирование на разнообразных сценариях и условиях освещения подтвердило стабильно высокие показатели точности и эффективности алгоритма. Полученные результаты свидетельствуют о значительном прогрессе в области стерео зрения, позволяя решать задачи, требующие высокой производительности и надежности в реальных приложениях. Показатели, достигнутые на этих наборах данных, являются ключевым подтверждением эффективности предложенного подхода и его потенциала для широкого спектра практических применений.
Подход, реализованный в Fast-FoundationStereo, демонстрирует передовые результаты как по точности, так и по скорости обработки стереоданных. Это позволяет говорить о его потенциале для применения в задачах, требующих обработки в реальном времени, например, в автономных транспортных средствах или робототехнике. Важно отметить, что система достигает сопоставимой производительности с более сложными и ресурсоемкими обобщающими моделями на датасете Booster-Q, что подтверждает ее эффективность и конкурентоспособность даже в сложных сценариях. Полученные результаты свидетельствуют о значительном прогрессе в области стереозрения и открывают новые возможности для создания быстрых и точных систем анализа изображений.
Для повышения устойчивости и обобщающей способности системы, исследователи применили метод псевдо-разметки, используя обширные наборы стереоданных, доступных в интернете. Этот подход позволяет алгоритму обучаться на большом количестве разнообразных изображений, что значительно расширяет его возможности по обработке данных, полученных в различных условиях освещения и геометрии сцены. По сути, система самостоятельно генерирует метки для неразмеченных данных, тем самым увеличивая объем обучающей выборки и улучшая свою способность к обобщению на новые, ранее не встречавшиеся сцены. Такой способ обучения позволяет добиться высокой точности и надежности работы системы в различных реальных условиях, даже при наличии шумов и искажений в изображениях.
Разработка Fast-FoundationStereo представляет собой заметный прогресс в области стереовидения благодаря синергии нескольких ключевых элементов. В основе системы лежат тщательно разработанные априорные знания, которые позволяют эффективно решать задачу сопоставления изображений. Архитектура модели отличается высокой эффективностью, что обеспечивает быструю обработку данных без ущерба для точности. Наряду с этим, применяются надежные методы обучения, которые повышают устойчивость и обобщающую способность системы даже в сложных условиях. Сочетание этих факторов позволяет Fast-FoundationStereo демонстрировать превосходные результаты и открывает новые возможности для применения стереовидения в реальном времени и в различных областях, требующих надежного и быстрого анализа трехмерной сцены.

Перспективы развития: к адаптивному и интеллектуальному зрению
Успех Fast-FoundationStereo демонстрирует значительные преимущества интеграции фундаментальных моделей с узкоспециализированными архитектурами при решении задач компьютерного зрения. Этот подход позволяет использовать обширные знания, накопленные фундаментальной моделью в процессе обучения на больших объемах данных, и адаптировать их для конкретной задачи стерео-видения с помощью специализированных модулей. Такая комбинация не только повышает точность и эффективность, но и открывает возможности для создания систем, способных к обобщению и адаптации к различным условиям освещения и геометрии сцены. Результаты показывают, что совместное использование сильных сторон обеих архитектур позволяет достичь более высоких показателей производительности по сравнению с использованием только фундаментальной модели или традиционных методов стерео-видения, что является важным шагом на пути к созданию интеллектуальных систем компьютерного зрения.
Перспективные исследования направлены на разработку систем динамического поиска и адаптации архитектуры нейронных сетей, что позволит оптимизировать их производительность в разнообразных и постоянно меняющихся условиях. Вместо использования фиксированных архитектур, эти системы смогут самостоятельно изменять свою структуру в процессе работы, подстраиваясь под специфические требования конкретной задачи или окружающей среды. Такой подход предполагает использование алгоритмов, способных оценивать эффективность различных архитектурных конфигураций и выбирать наиболее подходящую для достижения оптимальных результатов. Подобная гибкость особенно важна для применения в реальных условиях, где освещение, углы обзора и другие факторы могут существенно влиять на качество обработки изображений. Внедрение методов динамической адаптации позволит создавать более надежные и эффективные системы компьютерного зрения, способные успешно функционировать в сложных и непредсказуемых ситуациях.
Для успешного внедрения сложных моделей компьютерного зрения, таких как Fast-FoundationStereo, на устройствах с ограниченными вычислительными ресурсами, необходима разработка эффективных методов оптимизации. Особенно важны техники прунинга — удаления наименее значимых связей в нейронной сети — и дистилляции знаний, позволяющей перенести знания из большой, сложной модели в более компактную. Эти подходы не только уменьшают размер модели и снижают потребление энергии, но и позволяют сохранить высокую точность распознавания и обработки изображений даже на мобильных устройствах или встраиваемых системах. Активные исследования в области прунинга и дистилляции знаний открывают перспективы для создания интеллектуальных систем машинного зрения, доступных и эффективных в самых разнообразных условиях эксплуатации.
Представленная работа закладывает основу для создания интеллектуальных систем зрения, способных беспрепятственно функционировать в сложных и динамичных условиях реального мира. В перспективе, подобные системы смогут адаптироваться к меняющимся условиям освещения, различным точкам обзора и неполным данным, что позволит им надежно работать в разнообразных сценариях — от автономной навигации и робототехники до анализа медицинских изображений и систем видеонаблюдения. Развитие данной технологии предполагает создание систем, которые не просто «видят», но и «понимают» окружающую среду, позволяя им принимать обоснованные решения и взаимодействовать с миром более эффективно и безопасно. Подобный прорыв откроет новые возможности для автоматизации, улучшения качества жизни и решения сложных задач, требующих визуального восприятия.
Исследование, представленное в данной работе, демонстрирует изящную гармонию между мощностью фундаментальных моделей и необходимостью вычислительной эффективности. Авторы, подобно опытным архитекторам, не просто возводят сложные конструкции, но и тщательно продумывают каждый элемент для обеспечения бесперебойной работы системы. Fast-FoundationStereo, в своей сущности, воплощает принцип последовательности — будущие пользователи получат не только точные результаты стереосопоставления, но и возможность работы в режиме реального времени. Как однажды заметил Ян Лекун: “Машинное обучение — это программирование, в котором вы не программируете, а учите машину”. Эта фраза особенно актуальна здесь, ведь подход, описанный в статье, позволяет модели учиться и адаптироваться, используя знания, полученные из больших объемов данных, и при этом сохранять высокую скорость работы.
Куда же дальше?
Представленная работа, безусловно, демонстрирует элегантность подхода — использование фундаментальных моделей для решения задачи стереосопоставления в реальном времени. Однако, кажущаяся простота решения не должна заслонять остающиеся вопросы. Ускорение, достигнутое благодаря поиску архитектуры и дистилляции знаний, — это, скорее, изящное обходное решение, чем принципиальное устранение вычислительных ограничений. Остается неясным, насколько масштабируемым окажется этот подход при дальнейшем увеличении разрешения изображений и сложности сцен.
Важно признать, что «нулевая» обобщающая способность — это не абсолют. Успех в новых условиях, вероятно, потребует не просто адаптации, но и глубокого понимания механизмов, лежащих в основе обобщения. Псевдо-разметка, хоть и эффективна, остается лишь косвенным способом обучения, и ее влияние на устойчивость системы к шумам и артефактам требует дальнейшего изучения.
В конечном счете, настоящее совершенство заключается не в скорости или обобщающей способности, а в гармонии между формой и функцией. Будущие исследования должны быть направлены на создание систем, которые не просто «видят» мир, но и «понимают» его, а также способны адаптироваться к постоянно меняющимся условиям, избегая при этом излишней сложности и вычислительных издержек.
Оригинал статьи: https://arxiv.org/pdf/2512.11130.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Отражения культуры: Как языковые модели рассказывают истории
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Кванты в Финансах: Не Шутка!
- Память против контекста: Когда ИИ нужно вспоминать, а не перечитывать
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ожившие кадры: Как сохранить движение в сгенерированных видео
- Обучение с подкреплением и причинность: как добиться надёжных выводов
- Искусственный интеллект на службе формальной спецификации ПО
2025-12-16 00:06