Автор: Денис Аветисян
Исследование выявляет слабые места современных ИИ-систем в решении долгосрочных задач, требующих самостоятельного поиска информации и соблюдения ограничений.

В статье представлен DeepPlanning — эталонный набор тестов для оценки возможностей ИИ-агентов в долгосрочном планировании с учетом ограничений и необходимости активного сбора информации.
Несмотря на прогресс в области оценки агентов, существующие бенчмарки часто упускают из виду необходимость глобальной оптимизации с ограничениями, характерную для реальных задач долгосрочного планирования. В данной работе представлена платформа ‘DeepPlanning: Benchmarking Long-Horizon Agentic Planning with Verifiable Constraints’ — новый бенчмарк, предназначенный для оценки способностей LLM-агентов к планированию на длительный горизонт, требующего активного сбора информации и соблюдения локальных и глобальных ограничений. Эксперименты с DeepPlanning показали, что даже передовые модели испытывают трудности в решении подобных задач, подчеркивая важность надежных механизмов рассуждений и эффективного использования инструментов. Какие подходы позволят преодолеть эти ограничения и создать LLM-агентов, способных к действительно эффективному долгосрочному планированию?
Вызов Долгосрочного Планирования
Традиционные алгоритмы планирования часто сталкиваются с проблемой экспоненциального роста вычислительной сложности в реальных, многокомпонентных сценариях. По мере увеличения количества возможных действий и состояний, количество комбинаций, которые необходимо оценить, растет невероятно быстро, что делает поиск оптимального решения практически невозможным даже для современных вычислительных систем. Этот “взрыв комбинаций” ограничивает применимость классических методов планирования в задачах, требующих долгосрочного прогнозирования и адаптации к изменяющимся условиям, таких как автономная навигация, робототехника или управление сложными процессами. В результате, поиск эффективных стратегий снижения вычислительной нагрузки и разработки более масштабируемых алгоритмов планирования остается актуальной задачей в области искусственного интеллекта.
Существующие эталоны для оценки способностей к долгосрочному планированию часто оказываются недостаточно глубокими и реалистичными. Традиционные тесты, как правило, фокусируются на упрощенных задачах, не отражающих сложность реального мира, где решения принимаются в условиях неопределенности и требуют учета множества взаимосвязанных факторов. Это приводит к тому, что агенты, успешно проходящие такие тесты, могут оказаться неспособными к эффективному планированию в более сложных, приближенных к реальности сценариях, например, при организации многодневной поездки или выполнении комплексной покупки, требующей учета логистики, бюджета и изменяющихся обстоятельств. Недостаток реализма в эталонах препятствует развитию действительно интеллектуальных систем, способных к адаптации и принятию обоснованных решений в долгосрочной перспективе.
Для успешного решения задач, требующих планирования на длительный срок, таких как многодневные путешествия или комплексные покупки, недостаточно просто реагировать на текущую ситуацию. Исследования показывают, что агентам необходимо предвидеть последствия своих действий на несколько шагов вперёд, формируя целостную стратегию и учитывая изменяющиеся обстоятельства. Простое реагирование, хоть и может быть эффективным в краткосрочной перспективе, не позволяет оптимизировать план для достижения долгосрочных целей. Например, при планировании поездки необходимо учитывать не только текущее местоположение, но и будущие пункты назначения, расписание транспорта, возможные задержки и даже погодные условия. Такой подход требует разработки алгоритмов, способных моделировать будущее и оценивать различные варианты развития событий, что значительно сложнее, чем простое реагирование на непосредственные стимулы.
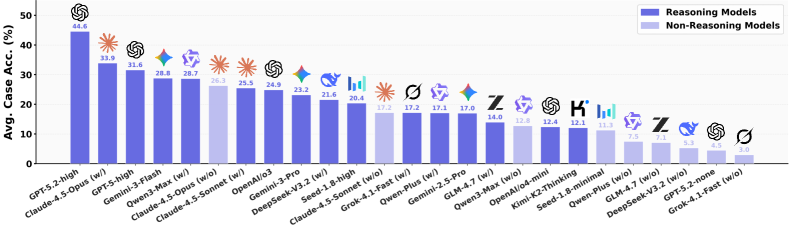
DeepPlanning: Комплексный Эталон для Оценки Долгосрочного Планирования
DeepPlanning — это новый эталонный набор данных, разработанный специально для оценки долгосрочного планирования агентов в задачах, связанных с путешествиями и совершением покупок. Он состоит из 120 задач в каждой из этих областей, что обеспечивает достаточное количество примеров для всестороннего тестирования алгоритмов планирования. Набор данных предназначен для оценки способности агентов успешно решать сложные задачи, требующие последовательности действий на протяжении длительного периода времени, и предоставляет унифицированную платформу для сравнения различных подходов к планированию.
В основе DeepPlanning лежит трехэтапный процесс “Послойной Генерации Задач”, обеспечивающий создание задач с верифицируемыми решениями. Первый этап определяет общую структуру задачи и ключевые цели. Второй этап детализирует эту структуру, добавляя конкретные условия и ограничения, необходимые для достижения цели. Наконец, третий этап генерирует конкретные экземпляры задачи, соответствующие определенной структуре и условиям, и одновременно формирует эталонные решения, которые используются для автоматической оценки эффективности планировщиков. Такой подход позволяет создавать сложные, но при этом контролируемые задачи, что критически важно для объективной оценки алгоритмов долгосрочного планирования.
Для обеспечения генерации задач в DeepPlanning используются специализированные доменные базы данных, созданные посредством тщательно проработанных процедур проектирования. Эти процедуры включают в себя сбор и структурирование данных о местах, товарах и их атрибутах, необходимых для моделирования реалистичных сценариев путешествий и покупок. Базы данных разработаны таким образом, чтобы обеспечить верифицируемость решений, генерируемых агентами, и содержат информацию, достаточную для оценки качества планирования. Процесс проектирования баз данных включает в себя определение схем данных, валидацию данных и обеспечение их масштабируемости для поддержки 120 задач в каждом из доменов (путешествия и покупки).
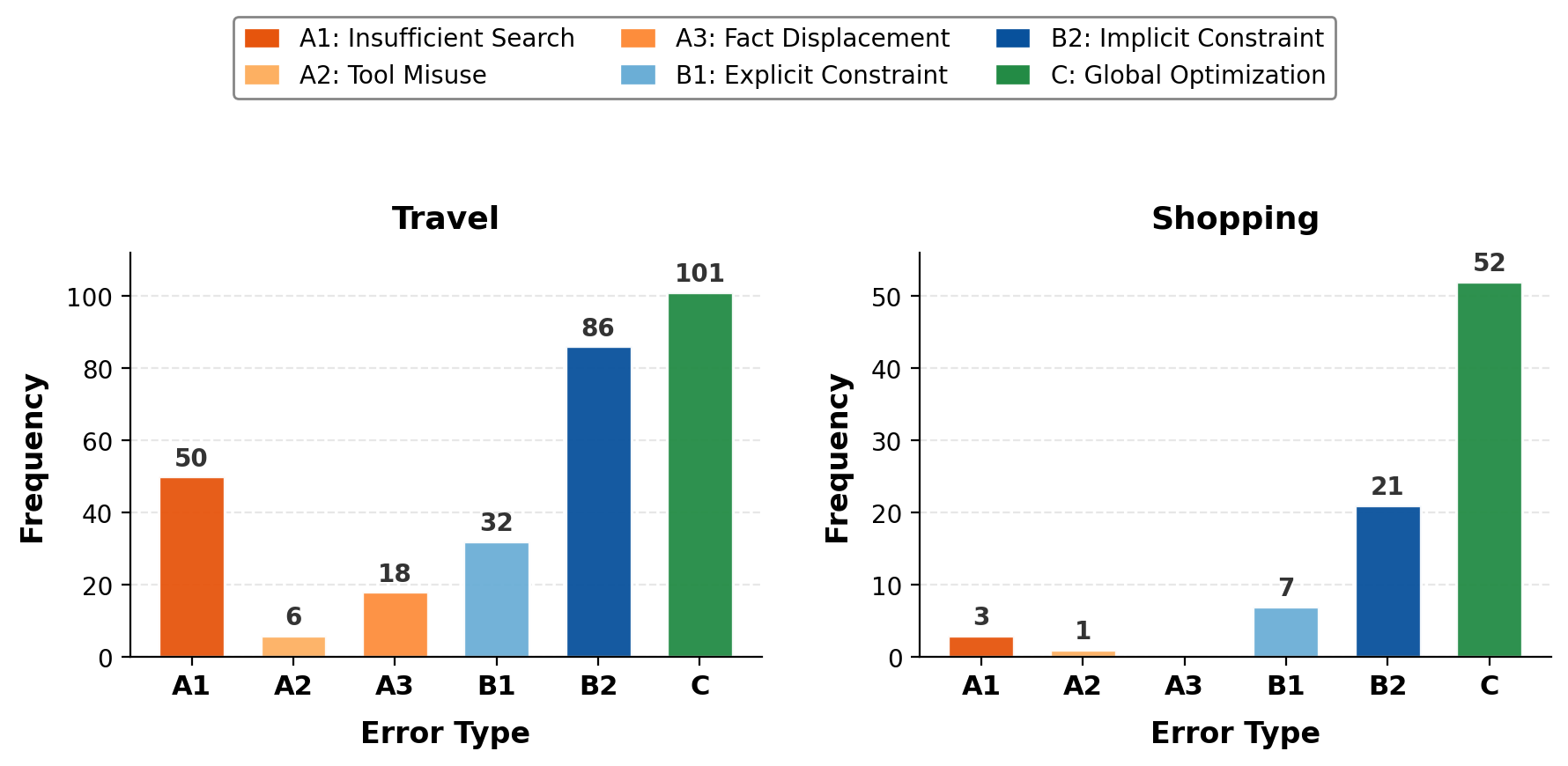
Строгая Оценка: Многогранный Подход к Определению Успеха
Оценка производительности агентов в системе DeepPlanning предполагает комплексный подход, включающий два ключевых параметра: “Здравомыслие” (Commonsense Score) и “Персонализация” (Personalized Score). “Здравомыслие” оценивает практическую реализуемость предложенного плана, то есть насколько логичен и осуществим план действий в реальных условиях. Параллельно, “Персонализация” измеряет степень соответствия плана индивидуальным предпочтениям и потребностям пользователя, обеспечивая релевантность предложенного решения. Оба параметра являются независимыми, но взаимосвязанными, и необходимы для полной оценки качества работы агента.
Индивидуальные оценки, такие как ‘Оценка здравого смысла’ и ‘Персонализированная оценка’, объединяются в итоговый ‘Сводный балл’, представляющий собой комплексную метрику успеха агента. Этот сводный балл вычисляется как агрегированная функция от отдельных оценок, позволяющая получить единое значение, отражающее как целесообразность плана, так и степень его соответствия предпочтениям пользователя. Использование сводного балла упрощает сравнение различных моделей и позволяет объективно оценивать их производительность в задачах планирования.
Для достижения высокой производительности в системе DeepPlanning требуется безупречный результат по всем оцениваемым метрикам — ‘Commonsense Score’ и ‘Personalized Score’. Это отражается в строгом показателе ‘Case Accuracy’, который используется для оценки успешности агента. Значение ‘Case Accuracy’ варьируется в зависимости от конкретной модели, как демонстрирует таблица 2, и предполагает, что для признания решения успешным, необходимо достижение идеальных результатов по обеим составляющим оценки.
Включение Проактивности: Агенты, Предугадывающие Будущее
Для успешного выполнения задач в рамках DeepPlanning недостаточно просто реагировать на текущую ситуацию; агенты должны проявлять инициативу в сборе необходимой информации о состоянии среды. Вместо пассивного ожидания обновлений, такие агенты активно запрашивают данные, предвидя, какие сведения могут потребоваться для достижения цели. Этот подход, известный как проактивное получение информации, позволяет агентам формировать более полное представление о мире и, как следствие, принимать более обоснованные решения. Способность предвидеть информационные потребности и самостоятельно их удовлетворять значительно повышает эффективность и надежность агента в сложных, динамически меняющихся условиях, характерных для DeepPlanning.
Способность к проактивному сбору информации неразрывно связана с локальным ограниченным рассуждением, позволяющим агентам эффективно решать сложные логические задачи внутри отдельных подзадач. Этот механизм позволяет агенту не просто реагировать на текущую ситуацию, но и предвидеть необходимые шаги, опираясь на внутренние ограничения и правила, определяющие допустимые действия. По сути, локальное рассуждение выступает в роли своеобразного фильтра, отсеивающего нерелевантные варианты и направляющего процесс планирования по наиболее вероятному и логичному пути. Такой подход позволяет агенту оперировать с высокой степенью точности даже в условиях неполной или противоречивой информации, что является критически важным для успешного выполнения сложных задач в рамках системы DeepPlanning.
Для обеспечения эффективного взаимодействия агентов в среде DeepPlanning используются специализированные Python-инструменты. Эти инструменты позволяют абстрагироваться от сложных запросов к базам данных, упрощая логику агентов и ускоряя процесс планирования. Вместо непосредственного управления низкоуровневыми деталями извлечения информации, агенты используют высокоуровневые функции, предоставляемые этими инструментами. Такой подход не только снижает вероятность ошибок, но и значительно повышает гибкость и масштабируемость системы, позволяя агентам концентрироваться на решении задач, а не на технических аспектах доступа к данным. В результате, агенты демонстрируют более эффективное и проактивное поведение в сложных сценариях DeepPlanning.
Валидация и Расширение DeepPlanning: Путь к Интеллектуальным Системам
Разработанный эталон DeepPlanning и сопутствующие метрики оценки представляют собой ценную платформу для всестороннего анализа и сопоставления различных архитектур агентов. Эталон позволяет исследователям объективно измерять способность агентов решать сложные, долгосрочные задачи, требующие планирования и адаптации к изменяющимся условиям. Благодаря стандартизированному набору задач и четко определенным критериям оценки, DeepPlanning облегчает сравнение эффективности различных подходов к искусственному интеллекту, способствуя прогрессу в области автономных систем и интеллектуального планирования. Использование данного эталона позволяет выявлять сильные и слабые стороны различных архитектур, направляя усилия по разработке более эффективных и надежных интеллектуальных агентов.
Для автоматической генерации и проверки сложности и реализуемости задач используется методика, основанная на больших языковых моделях (LLM). Этот подход позволяет создавать разнообразные сценарии планирования, оценивая их с точки зрения логической последовательности и возможности выполнения агентом. LLM анализируют предложенные задачи, выявляя потенциальные противоречия или неосуществимые шаги, что обеспечивает более надежную валидацию эталонного набора DeepPlanning. Такой автоматизированный процесс оценки не только повышает эффективность тестирования, но и позволяет выявлять слабые места в архитектурах агентов, способствуя разработке более устойчивых и интеллектуальных систем планирования.
Постоянное совершенствование эталонного набора задач и системы оценки является ключевым фактором для продвижения исследований в области долгосрочного планирования агентов. Усилия направлены на создание более сложных и реалистичных сценариев, которые требуют от интеллектуальных систем не просто выполнения отдельных действий, но и разработки последовательных стратегий для достижения поставленных целей в течение длительного периода времени. Такой подход позволяет выявить ограничения существующих алгоритмов и стимулирует разработку инновационных методов, способных решать задачи, требующие прогнозирования, адаптации и обучения в динамичной среде. Улучшенная платформа оценки, в свою очередь, обеспечивает более объективное и надежное сравнение различных архитектур агентов, что способствует ускорению прогресса в области искусственного интеллекта и открывает новые перспективы для создания интеллектуальных систем, способных решать сложные проблемы в реальном мире.
Исследование, представленное в статье, выявляет сложности, с которыми сталкиваются современные LLM-агенты при долгосрочном планировании, особенно в части проактивного сбора информации и соблюдения ограничений. Это подчеркивает необходимость в архитектурах, способных к более глубокому пониманию и оптимизации планов. Барбара Лисков однажды заметила: «Хороший дизайн — это компромисс между сложностью и ясностью». Данное утверждение находит отражение в проблемах, выявленных в DeepPlanning: стремление к сложным планам без четкого понимания ограничений и необходимости в дополнительной информации приводит к неоптимальным решениям. Простота и ясность в определении целей и ограничений, вероятно, являются ключевыми факторами успеха в разработке действительно эффективных LLM-агентов.
Что дальше?
Представленная работа выявляет закономерную сложность в стремлении к долгосрочному планированию для агентов, основанных на больших языковых моделях. Оказывается, способность к использованию инструментов и, что важнее, проактивный поиск необходимой информации, остаются узкими местами. Попытки оптимизировать локальные шаги, не учитывая глобальную картину, — это, пожалуй, ожидаемая ошибка. Ясность — это минимальная форма любви, и в данном случае, отсутствие ясности в понимании долгосрочных последствий неизбежно ведёт к субоптимальным решениям.
Будущие исследования, вероятно, будут сосредоточены на разработке механизмов, позволяющих агентам формировать более полные модели мира, а также оценивать неопределенность и риски. Необходимо отойти от простой генерации последовательности действий и перейти к построению итеративных планов, способных адаптироваться к изменяющимся обстоятельствам. Истинная сложность не в увеличении количества параметров, а в их разумном применении.
Возможно, в конечном итоге, истинный прорыв потребует не столько совершенствования существующих моделей, сколько переосмысления самой парадигмы планирования. Поиск оптимального решения — это лишь одна из возможных стратегий. Иногда достаточно просто найти решение, достаточно хорошее для текущих задач. В конечном счете, простота — это высшая форма изысканности.
Оригинал статьи: https://arxiv.org/pdf/2601.18137.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовая криптография: от теории к практике
- Робот, который видит, понимает и действует: новая эра общего назначения
2026-01-28 01:44