Автор: Денис Аветисян
Новый подход к анализу изображений ставит во главу угла выявление стабильных структурных элементов, независимых от изменчивости семантических интерпретаций.
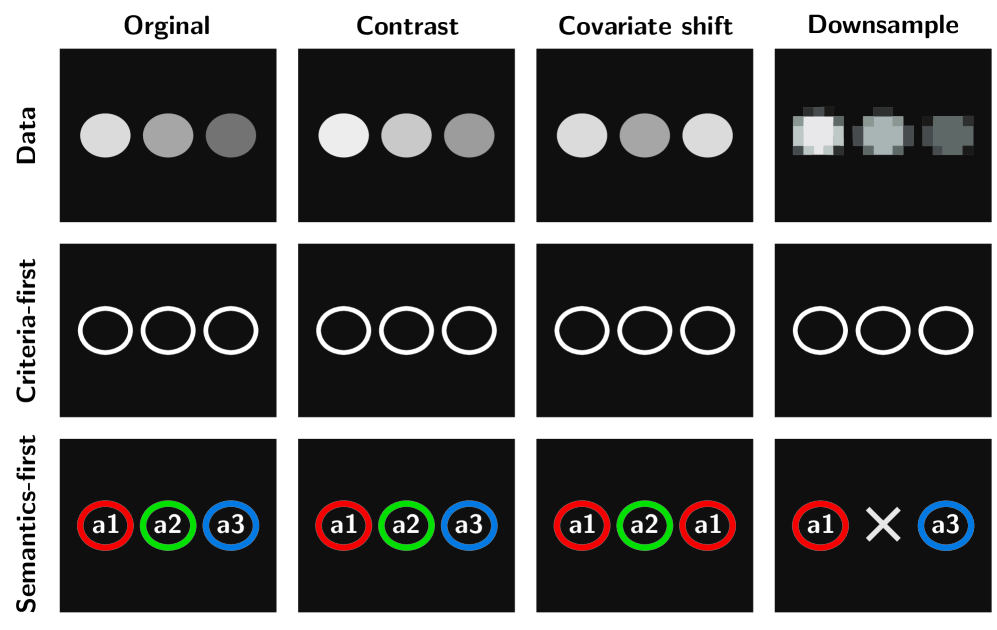
Переход от подхода, ориентированного на семантику, к подходу, основанному на четких критериях, обеспечивает воспроизводимость и надежность анализа изображений в долгосрочной перспективе, что критически важно для создания цифровых двойников и обмена данными.
Несмотря на широкое распространение анализа изображений в науках о жизни и природе, доминирующим подходом остается интерпретация данных через призму предметной области. В работе ‘Criteria-first, semantics-later: reproducible structure discovery in image-based sciences’ предлагается принципиально иной подход — выделение стабильных структурных элементов на основе четких критериев, а уже затем — их соотнесение с конкретными онтологиями. Такой переход от «семантики прежде всего» к «критериям прежде всего» обеспечивает воспроизводимость анализа, особенно в условиях меняющихся научных трактовок и при долгосрочном мониторинге данных. Возможно ли создание универсальной платформы для обработки изображений, позволяющей извлекать объективные структурные характеристики, не зависящие от субъективных интерпретаций и обеспечивающие совместимость данных между различными научными дисциплинами?
За пределами Семантики: Ограничения Этикетирования
Традиционный анализ изображений, воплощенный в так называемой Семантической Парадигме, в значительной степени опирается на заранее определенные онтологии предметной области, что существенно ограничивает потенциал новых открытий. Этот подход, ориентированный на присвоение меток, предполагает, что все значимое уже известно и закодировано в этих онтологиях, тем самым препятствуя выявлению неожиданных структур и явлений, которые не соответствуют заранее заданным категориям. В результате, исследовательские возможности оказываются зажатыми рамками существующих знаний, а возможность обнаружения принципиально нового — существенно снижается. Данный метод, хотя и эффективен для решения конкретных, четко определенных задач, оказывается малопригодным для открытий в областях, где требуется гибкость и способность адаптироваться к неизвестному.
Традиционный подход к анализу изображений, основанный на предварительно заданных метках, сталкивается с серьезными ограничениями при работе с новыми, ранее неизвестными объектами и явлениями. Эта зависимость от жестко определенных категорий препятствует адаптации к меняющимся данным и замедляет прогресс в области открытых научных исследований. Системы, ориентированные на распознавание заранее определенных классов, зачастую не способны эффективно обрабатывать информацию, выходящую за рамки их “обучения”, что приводит к пропуску потенциально важных открытий и снижению общей эффективности анализа. Неспособность к адаптации особенно критична в динамичных областях науки, где новые данные и явления появляются постоянно, требуя от аналитических инструментов гибкости и способности к самообучению.
Настоящая работа подчеркивает необходимость фундаментального сдвига в подходах к анализу изображений. Вместо традиционной практики, ориентированной на предварительное определение и присвоение семантических меток, предлагается фокусироваться на извлечении внутренней структуры данных в первую очередь. Такой подход позволяет выявить закономерности и взаимосвязи, которые могли бы остаться незамеченными при использовании существующих методов, основанных на жестких онтологиях. Вместо того чтобы искать подтверждение заранее заданным категориям, предлагаемый рабочий процесс ориентирован на получение «структурных продуктов» — базовых строительных блоков информации, которые затем могут быть интерпретированы и использованы для более гибкого и адаптивного научного открытия. Это позволяет преодолеть ограничения, связанные с новизной и непредсказуемостью реальных данных, и открывает путь к более глубокому пониманию сложных систем.

Критерии прежде всего: Определение Структуры Независимо
Подход, ориентированный на критерии, предполагает предварительное определение явных критериев для извлечения структурного продукта из данных, не опираясь на предопределенные метки или классификации. Вместо использования существующих категорий, данный метод акцентирует внимание на выявлении и формализации характеристик, присущих самим данным. Это позволяет создавать структурные представления, основанные на внутренних свойствах данных, а не на внешних обозначениях, что обеспечивает большую гибкость и адаптивность при анализе, особенно в случаях, когда существующие метки неполны или неточны. Такой подход позволяет обнаружить ранее неизвестные закономерности и связи в данных, поскольку он не ограничен рамками предварительно заданных категорий.
В рамках данной методологии, сегментация выступает ключевым инструментом для выделения и анализа релевантных признаков данных. Процесс сегментации предполагает разделение исходного набора данных на отдельные группы или сегменты, основанные на сходстве их характеристик. Выделенные признаки в каждом сегменте подвергаются детальному анализу для определения их значимости и взаимосвязей. Именно эти проанализированные признаки формируют основу структурного представления, позволяя создать модель, отражающую внутреннюю организацию данных независимо от предварительно заданных меток или категорий. Использование сегментации обеспечивает более гибкий и адаптивный подход к построению структурных продуктов.
Подход, ориентированный на внутренние свойства данных, обеспечивает более устойчивую и адаптивную основу для анализа, поскольку он не зависит от предварительно заданных меток или категорий. Предложенный рабочий процесс для получения структурных продуктов демонстрирует, что анализ, основанный на выявлении и использовании присущих данным характеристик, позволяет создавать надежные структуры, способные адаптироваться к изменениям в данных или задачах. Такой подход особенно полезен в ситуациях, когда доступные метки неполны, неточны или могут меняться со временем, поскольку структурные продукты выводятся непосредственно из наблюдаемых свойств данных, а не из их произвольной классификации.
Устойчивость и Надёжность: Преимущества Структурно-Ориентированного Анализа
Критерий-ориентированный подход обеспечивает устойчивость к смещению домена (domain shift) благодаря тому, что структурный продукт (Structural Product) определяется свойствами данных, а не зависимостями от меток. В отличие от традиционных методов, где изменения в распределении данных могут потребовать переобучения модели или обновления меток, данный подход формирует структурный продукт на основе внутренних характеристик данных. Это означает, что даже при существенных изменениях в входных данных, если основные свойства, определенные критериями, сохраняются, структурный продукт останется стабильным и надежным. Такая независимость от меток и акцент на свойствах данных существенно повышает устойчивость системы к изменениям в окружающей среде и обеспечивает ее надежную работу в различных условиях.
Долгосрочный мониторинг значительно упрощается благодаря стабильности Структурного Продукта. В отличие от традиционных подходов, зависящих от актуальности и точности меток, Структурный Продукт определяется свойствами данных, а не зависимостью от их классификации. Это позволяет отслеживать изменения во времени без необходимости постоянного обновления или пересмотра разметок, что снижает затраты и повышает надежность системы мониторинга. Стабильность Структурного Продукта гарантирует, что изменения, зафиксированные в процессе мониторинга, отражают реальные изменения в данных, а не артефакты, связанные с изменениями в схеме разметки.
Подход, основанный на структуре, обеспечивает воспроизводимость результатов благодаря четко определенным критериям, которые задают однозначный и проверяемый путь к генерации Структурного Продукта. Данные критерии служат формальным описанием процесса, позволяя независимо повторить шаги и получить идентичный результат. Это соответствует основным принципам предлагаемого рабочего процесса, ориентированного на верифицируемость и возможность аудита, что критически важно для обеспечения надежности и достоверности анализа данных и последующих выводов.
От Инсайтов к Применениям: Масштабирование с FAIR-данными
Структурный продукт, полученный посредством подхода, ориентированного на критерии, представляет собой основу для создания цифровых двойников, обеспечивая последовательное и надежное представление физических систем. Этот продукт, в отличие от традиционных моделей, формируется не на основе произвольного выбора параметров, а благодаря четко определенным и верифицированным критериям, отражающим ключевые характеристики исследуемого объекта. Благодаря такому подходу, цифровой двойник становится не просто визуальной копией, а функциональной моделью, способной к точной симуляции, прогнозированию и оптимизации процессов. Надежность и последовательность структурного продукта гарантируют, что результаты, полученные в цифровом двойнике, могут быть использованы для принятия обоснованных решений в реальном мире, будь то проектирование новых материалов, оптимизация производственных процессов или управление сложными инфраструктурными объектами. Фактически, данный подход позволяет перейти от описательных моделей к предсказательным, открывая новые возможности для инноваций и повышения эффективности.
Методология, основанная на подходе «Критерии прежде всего», обеспечивает согласованность масштаба, гарантируя непротиворечивость структурных свойств при анализе на различных уровнях детализации. Это означает, что характеристики, определенные для отдельного компонента системы, последовательно сохраняются и отражаются при переходе к более сложным агрегатам или к системе в целом. Такая структурная когерентность критически важна для создания точных и надежных цифровых двойников, позволяющих моделировать поведение физических систем и проводить предсказательный анализ без искажений, вызванных несогласованностью данных. В результате, появляется возможность объединять информацию, полученную на микро- и макроуровнях, для всестороннего понимания и оптимизации сложных процессов, что особенно важно в таких областях, как инженерия, материаловедение и экологическое моделирование.
Создание FAIR-цифровых объектов — данных и знаний, соответствующих принципам находимости, доступности, совместимости и повторного использования — является ключевым фактором ускорения научного прогресса. Этот подход обеспечивает не только возможность лёгкого обмена информацией между исследователями и системами, но и гарантирует долгосрочное сохранение и ценность полученных результатов. Благодаря соблюдению стандартов FAIR, данные становятся пригодными для автоматизированной обработки, анализа и интеграции в более сложные модели и системы, что значительно повышает эффективность исследований и способствует появлению новых открытий. В рамках данной работы подчеркивается, что именно принципы FAIR позволяют раскрыть полный потенциал данных, превращая их из пассивных хранилищ информации в активные инструменты познания.
Перспективы Будущего: Принятие Адаптивности и Открытий
Сочетание подхода, ориентированного на критерии, с самообучением открывает возможности для автоматического выявления релевантных критериев, что значительно повышает адаптивность систем анализа данных. Вместо жесткого следования заранее определенным параметрам, алгоритмы способны самостоятельно извлекать значимые признаки из структуры данных, позволяя им эффективно функционировать в меняющихся условиях и обнаруживать неочевидные закономерности. Такой симбиоз позволяет создавать более гибкие и интеллектуальные инструменты, способные самостоятельно приспосабливаться к новым задачам и находить оптимальные решения без необходимости ручной настройки и вмешательства человека. Это особенно важно в областях, где данные постоянно меняются или где заранее неизвестны ключевые факторы, влияющие на результат.
Использование фундаментальных моделей открывает новые горизонты в анализе структурного продукта, позволяя значительно расширить возможности предиктивного моделирования и распознавания закономерностей. Эти модели, обученные на огромных объемах данных, способны выявлять скрытые связи и зависимости, которые остаются незамеченными при традиционных подходах. Они не требуют предварительной разметки данных, что особенно ценно при работе со сложными и многомерными структурами. Благодаря этому, анализ структурного продукта становится более автоматизированным, точным и эффективным, позволяя прогнозировать поведение систем и выявлять ранее неизвестные тренды и аномалии. Подобный подход имеет потенциал для революционных изменений в различных областях науки, от материаловедения до биоинформатики.
Предлагаемый подход открывает перспективы для анализа данных, не ограниченного заранее заданными метками или категориями. Вместо этого, акцент смещается на выявление внутренней структуры данных, позволяя алгоритмам самостоятельно обнаруживать закономерности и взаимосвязи. Это существенно расширяет возможности научного поиска, поскольку позволяет исследовать данные без предвзятости, выявляя неожиданные и ранее неизвестные явления. В результате, анализ данных становится более гибким и адаптивным, способным к самостоятельному обучению и открытию новых знаний, что, как демонстрирует данная работа, представляет собой шаг к действительно неограниченным научным исследованиям.
Статья справедливо указывает на хрупкость семантических построений в анализе изображений. Попытки сразу же навязать данным заранее заданные смыслы — занятие неблагодарное. Любая онтология подвержена дрейфу, а значит, и интерпретации данных будут меняться со временем. Гораздо надежнее сначала выделить стабильные, воспроизводимые структурные продукты — паттерны, которые не зависят от текущего понимания предметной области. Как однажды заметил Эндрю Ын: «Мы должны сосредоточиться на создании систем, которые могут учиться и адаптироваться, а не просто запоминать». Это особенно важно при построении цифровых двойников, где долгосрочная стабильность и воспроизводимость данных — краеугольный камень надёжности.
Куда же всё это ведёт?
Предложенный здесь сдвиг от «семантики прежде всего» к «критериям прежде всего» — это не столько техническое решение, сколько признание того, что сам мир не дискретен, просто у нас нет памяти для float. Попытки привязать анализ изображений к изменчивым онтологиям — всё равно что строить дом на песке. Структурные продукты, извлечённые на основе стабильных критериев, могут служить своего рода окаменелостями в потоке данных, позволяя отслеживать изменения во времени, не будучи пленниками сегодняшних представлений о мире. Но и тут кроется ловушка: стабильность критериев — иллюзия.
Настоящая проблема — не в поиске идеальной онтологии или набора критериев, а в создании систем, способных адаптироваться к их неизбежному дрейфу. Необходимы методы, позволяющие выявлять и учитывать эти изменения, перекалибруя структурные продукты и обеспечивая их долгосрочную согласованность. И, возможно, самое важное — это отказ от навязчивой идеи точной количественной оценки. Всё точное — мёртво. Необходимо искать не корреляцию, а смысл, даже если он скрыт в шуме.
Перспективы лежат в области самообучения, где алгоритмы смогут самостоятельно извлекать и валидировать структурные продукты, не полагаясь на внешние метки или предварительные знания. Но и тут предстоит столкнуться с парадоксом: как научить машину видеть смысл, если сама машина — лишь отражение человеческих предубеждений? По сути, речь идёт о создании цифровых двойников, которые не просто копируют реальность, но и учатся её понимать — и, возможно, даже предсказывать.
Оригинал статьи: https://arxiv.org/pdf/2602.15712.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Искусственный интеллект и квантовая физика: кто кого?
- Взрыв скорости: Оптимизация внимания для современных GPU
- Знаем, чего не знаем: Моделирование вероятностных рассуждений на основе множественных доказательств
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Учимся с интересом: как создать AI-репетитора, вдохновлённого лучшими учителями
- Языковые модели и границы возможного: что делает язык человеческим?
- Квантовые Траектории: Обучение с Учетом Физических Законов
- Сознание машин: новая модель двойных законов
2026-02-18 12:50