Автор: Денис Аветисян
Новый подход к дистилляции датасетов позволяет создавать компактные, но информативные наборы данных, не теряя при этом качества обучения моделей машинного обучения.

В статье представлена методика InfoUtil, использующая значения Шепли и нормы градиентов для создания интерпретируемых синтетических датасетов, обеспечивающих оптимальное соотношение информативности и практической ценности.
Сокращение объёма обучающих данных без потери качества остаётся сложной задачей в современном машинном обучении. В работе ‘Grounding and Enhancing Informativeness and Utility in Dataset Distillation’ предложен новый подход к дистилляции наборов данных, основанный на формализации понятий информативности и полезности отдельных экземпляров. Авторы представляют InfoUtil — фреймворк, использующий значения Шепли и нормы градиента для создания компактного и эффективного синтетического набора данных, демонстрируя улучшение производительности на 6.1% по сравнению с современными подходами на ImageNet-1K. Сможет ли предложенный метод стать основой для создания более интерпретируемых и компактных наборов данных для широкого спектра задач машинного обучения?
Предел Вычислительных Ресурсов: Вызов Глубокому Обучению
Обучение глубоких нейронных сетей, особенно на масштабных наборах данных, таких как ImageNet, представляет собой значительную вычислительную задачу. Для успешного завершения этого процесса требуются огромные ресурсы, включающие в себя мощные графические процессоры (GPU) и значительные объемы оперативной памяти. Время обучения может измеряться днями или даже неделями, что обусловлено необходимостью обработки миллиардов параметров и выполнения триллионов операций. Это создает серьезные препятствия для исследователей и разработчиков, ограничивая скорость итераций и возможность экспериментировать с новыми архитектурами и гиперпараметрами. Помимо вычислительных затрат, возникает проблема энергопотребления и охлаждения, что делает обучение таких моделей дорогостоящим и экологически неблагоприятным.
Огромный объем данных, с которым сталкиваются современные алгоритмы машинного обучения, зачастую становится серьезным препятствием для эффективной разработки и внедрения моделей. Несмотря на растущую вычислительную мощность, обработка петабайтов информации требует колоссальных временных затрат и ресурсов, замедляя процесс итераций и экспериментов. Это особенно актуально для задач, требующих быстрого прототипирования или работы в условиях ограниченной инфраструктуры. Более того, увеличение масштаба данных не всегда линейно коррелирует с улучшением производительности модели, что подчеркивает необходимость поиска более эффективных методов работы с информацией и оптимизации процессов обучения.
Существующие методы обучения моделей глубокого обучения сталкиваются с серьезными трудностями при значительном сокращении объема используемых данных, что зачастую приводит к существенной потере точности. Традиционные подходы, полагающиеся на обработку всего доступного набора данных, оказываются неэффективными при попытке обучения моделей на сильно уменьшенных подмножествах. Это связано с тем, что уменьшение размера данных может привести к потере важной информации и снижению способности модели обобщать полученные знания на новые, ранее не виденные примеры. Попытки компенсировать недостаток данных за счет увеличения сложности модели или изменения архитектуры, как правило, не дают желаемого результата и приводят к переобучению, когда модель запоминает обучающие примеры, но не способна эффективно работать с новыми данными. В результате, разработка эффективных методов, позволяющих сохранять высокую точность при значительном сокращении объема обучающих данных, представляет собой важную задачу в области машинного обучения.
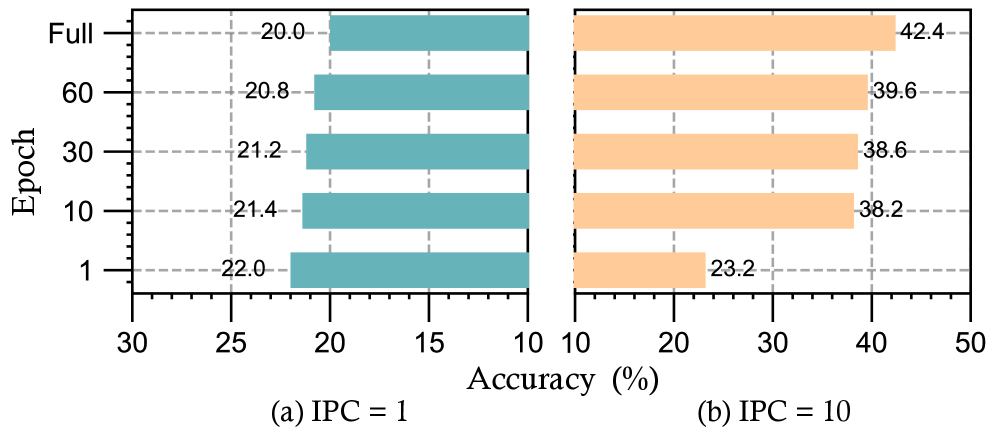
Дистилляция Данных: Путь к Эффективности
Дистилляция наборов данных представляет собой перспективное решение для работы с большими объемами информации, заключающееся в создании уменьшенного, репрезентативного синтетического набора данных (SyntheticDataset) из исходного, значительно большего набора. Этот процесс предполагает выбор подмножества данных или генерацию новых образцов, которые сохраняют ключевые характеристики и информационное содержание исходного набора. В результате получается набор данных меньшего размера, который может быть использован для обучения моделей машинного обучения с сохранением приемлемого уровня производительности и снижением вычислительных затрат, связанных с обработкой больших объемов данных. Эффективность дистилляции зависит от способности синтетического набора данных точно отражать распределение и структуру исходного набора.
Методы дистилляции данных, такие как KnowledgeDistillationMethods, используют предварительно обученную TeacherModel для направления процесса создания SyntheticDataset. TeacherModel служит источником знаний, передавая информацию о взаимосвязях в исходном наборе данных в меньший SyntheticDataset. Этот процесс включает в себя обучение StudentModel на основе выходных данных TeacherModel, а не напрямую на исходных данных. В результате StudentModel имитирует поведение TeacherModel, сохраняя критически важную информацию и обобщающую способность, при этом работая с существенно меньшим объемом данных. Выбор архитектуры TeacherModel и функции потерь для обучения StudentModel оказывает значительное влияние на качество полученного SyntheticDataset и итоговую производительность моделей, обученных на нем.
Сжатие набора данных является ключевой задачей в процессе дистилляции, однако простое уменьшение размера не является достаточным условием успешной реализации. Важнейшим критерием является сохранение или даже улучшение производительности модели, обученной на дистиллированном наборе данных. Уменьшение размера должно быть сбалансировано с необходимостью сохранения репрезентативности данных и, как следствие, точности модели. Оптимальное сжатие достигается путем выбора наиболее информативных образцов, которые позволяют модели эффективно обобщать и сохранять высокую точность предсказаний на исходных данных, даже при значительно меньшем размере дистиллированного набора.

Поиск Баланса: Информативность и Польза в Дистилляции
Традиционные методы дистилляции знаний, как правило, не предусматривают четкого механизма для количественной оценки важности каждого отдельного образца данных. Это означает, что все образцы обрабатываются одинаково, вне зависимости от их вклада в обучение модели-студента. В результате, модель может тратить ресурсы на обработку неинформативных или избыточных данных, что снижает эффективность и скорость обучения. Отсутствие взвешенного подхода к выборке данных ограничивает способность модели-студента эффективно усваивать знания от модели-учителя и приводит к снижению обобщающей способности.
Метод InfoUtil решает проблему отсутствия количественной оценки важности каждого образца данных в традиционных методах дистилляции знаний. Он явно балансирует два ключевых аспекта: информативность (способность образца предоставлять новую информацию модели) и полезность (вклад образца в улучшение процесса обучения). Это достигается путем одновременной оптимизации этих двух факторов в процессе дистилляции, что позволяет более эффективно использовать данные и повысить производительность модели. В результате, InfoUtil позволяет обучать более точные и эффективные модели, используя ограниченный набор данных.
Метод InfoUtil использует значение Шэпли ShapleyValue для оценки вклада каждого обучающего примера в процесс дистилляции знаний. Это позволяет количественно определить важность каждого примера, что необходимо для эффективного отбора данных. Дополнительно, для максимизации полезности каждого примера при обучении, применяется метрика GradientNorm, измеряющая норму градиента потерь по отношению к входным данным. Экспериментальные результаты на наборах данных ImageNet-100 и ImageNet-1K демонстрируют повышение производительности на 16% и 6.1% соответственно, по сравнению с традиционными методами дистилляции.

Новые Горизонты: Влияние Дистилляции на Будущее Машинного Обучения
Современные методы дистилляции данных, такие как MatchingBasedMethods и InfoUtil, демонстрируют значительный прогресс в области уменьшения объёма обучающих наборов, не жертвуя при этом точностью моделей. Эти подходы позволяют отобрать наиболее информативные примеры из исходного датасета, создавая компактные подмножества, способные эффективно обучать сложные модели. В отличие от традиционных методов, основанных на случайном отборе, MatchingBasedMethods и InfoUtil используют сложные алгоритмы для оценки вклада каждого примера в процесс обучения, обеспечивая более качественную и репрезентативную дистилляцию данных. Результаты показывают, что применение этих методов позволяет существенно сократить время обучения и потребление памяти, открывая новые возможности для обучения моделей на ограниченных вычислительных ресурсах и больших датасетах.
Разработанные методы снижения размерности данных демонстрируют значительное уменьшение временных и вычислительных затрат при обучении моделей, не приводящее к потере точности. Исследования показывают, что по сравнению с системой TESLA, предложенные подходы позволяют в 50 раз сократить время обучения и в 100 раз уменьшить потребление памяти. Это достигается за счет более эффективного отбора наиболее информативных данных, что позволяет обучать модели на значительно меньших наборах, сохраняя при этом высокую производительность и открывая возможности для применения в условиях ограниченных ресурсов.
Метод InfoUtil продемонстрировал впечатляющие результаты на широко используемом наборе данных ImageNet-1K, достигнув точности в 43.88% при использовании всего 10 образцов на класс (IPC=10). Этот показатель превосходит результаты, полученные с использованием других методов совместного отбора данных, на целых 7.6%. В дальнейшем планируется сосредоточить усилия на более тонкой настройке баланса между информативностью и полезностью отбираемых данных, что позволит повысить эффективность алгоритма. Кроме того, исследователи намерены изучить возможности применения данного подхода в задачах, выходящих за рамки классификации изображений, включая, например, обработку естественного языка и анализ временных рядов, что открывает перспективы для создания более компактных и эффективных моделей машинного обучения в различных областях.
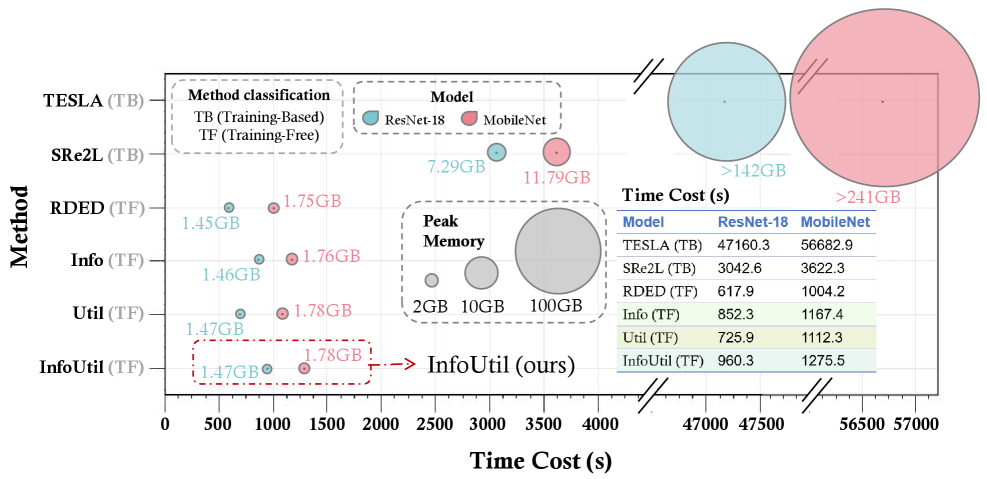
Исследование, представленное в статье, демонстрирует стремление к созданию синтетических наборов данных, которые не просто воспроизводят поведение оригинальных данных, но и сохраняют ключевую информацию и полезность для обучения моделей. Этот подход перекликается с высказыванием Барбары Лисков: «Программы должны быть спроектированы так, чтобы изменения в одной части не влияли на другие части». Подобно принципам проектирования программного обеспечения, InfoUtil стремится к созданию набора данных, который, будучи дистилляцией оригинального, сохраняет его целостность и функциональность. Использование Shapley values для оценки вклада каждого образца в информативность и полезность, а также gradient norms для определения значимости, позволяет создать устойчивую и интерпретируемую систему, где изменения в одном аспекте не приводят к непредсказуемым последствиям в другом. Этот метод позволяет «взломать» сложность исходных данных, выделив самое важное для эффективного обучения моделей.
Куда дальше?
Представленная работа, безусловно, открывает новые возможности в области дистилляции наборов данных. Однако, следует признать, что баланс между информативностью и полезностью, достигаемый с помощью значений Шепли и норм градиентов, — это лишь один из возможных подходов. Истинная сложность заключается не в поиске “правильных” метрик, а в осознании их принципиальной неполноты. Каждый набор данных, каждая модель — это артефакт, несущий в себе следы предвзятости создателей и ограничений используемых инструментов.
Будущие исследования, вероятно, сосредоточатся на разработке методов, позволяющих выявлять и смягчать эти скрытые предубеждения. Интересно было бы исследовать, как динамические, адаптивные стратегии дистилляции, учитывающие меняющиеся требования к модели, могут превзойти статические подходы. Попытки включить в процесс дистилляции принципы обратной инженерии — то есть, не просто сжатие данных, а активное «взламывание» структуры модели для извлечения наиболее ценных знаний — представляются особенно перспективными.
В конечном счете, задача не в создании идеальных синтетических данных, а в понимании того, что любое упрощение — это всегда потеря. Задача исследователя — не избегать потерь, а осознавать их и минимизировать, признавая, что хаос, возможно, является более плодородной почвой для понимания, чем любая документация.
Оригинал статьи: https://arxiv.org/pdf/2601.21296.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Графы и действия: новый подход к планированию для роботов
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Bibby AI: Новый помощник для исследователей в LaTeX
- Квантовый скачок венчурного капитала: между надеждой и реальностью
- Визуальный разум: Как видеомодели научились понимать текст и создавать изображения
- Искусственный интеллект в медицине: новый уровень самостоятельности
- Поиск знаний: Студенты выбирают между классикой и искусственным интеллектом
- Многокритериальная оптимизация: взгляд на народные методы
2026-02-08 10:15