Автор: Денис Аветисян
Новая модель SwimBird демонстрирует способность динамически переключать режимы рассуждений, эффективно решая как текстовые, так и визуально сложные задачи.
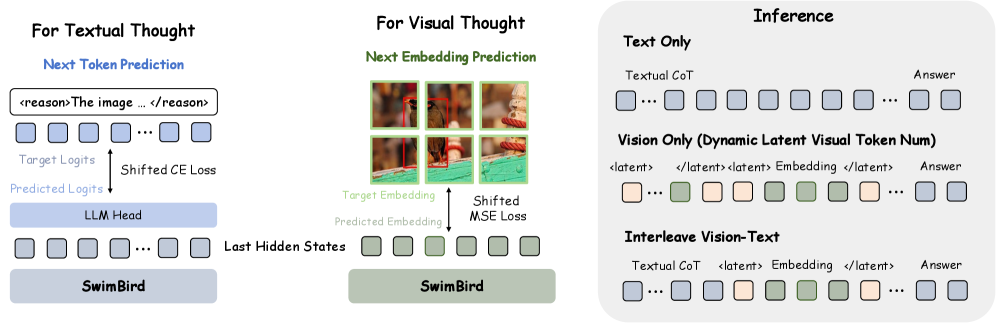
Разработана гибридная архитектура, позволяющая модели адаптировать процесс рассуждений в зависимости от типа входных данных и сложности задачи.
Существующие мультимодальные большие языковые модели (MLLM) зачастую демонстрируют ограниченную гибкость в выборе оптимальной стратегии рассуждений. В данной работе, представленной под названием ‘SwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMs’, предложена новая архитектура, позволяющая динамически переключаться между текстовым, визуальным и комбинированным режимами рассуждений. SwimBird использует гибридный авторегрессионный подход и тщательно подобранный набор данных для обучения, что позволяет эффективно решать как текстовые, так и визуально-интенсивные задачи. Сможет ли подобная адаптивная система рассуждений открыть новые горизонты в области мультимодального искусственного интеллекта и приблизиться к человеческому уровню понимания?
За пределами фиксированных шаблонов: Необходимость динамического рассуждения
Традиционные мультимодальные большие языковые модели зачастую опираются на заранее заданные шаблоны рассуждений, что существенно ограничивает их способность адаптироваться к разнообразным входным данным и задачам. Эти модели, функционируя по жестким алгоритмам, испытывают трудности при анализе сложных сценариев, требующих тонкой интеграции визуальной и текстовой информации. Вместо гибкого подхода, способного к динамической настройке стратегии рассуждений в зависимости от характеристик входных данных, наблюдается привязка к фиксированным структурам. Это ограничивает потенциал моделей в решении задач, выходящих за рамки заранее определенных шаблонов, и снижает их эффективность в ситуациях, требующих творческого и адаптивного мышления.
Жесткие структуры, присущие традиционным мультимодальным большим языковым моделям, зачастую оказываются неэффективными при решении сложных задач, требующих тонкой интеграции визуальной и текстовой информации. Ограниченность предопределенных шаблонов не позволяет адекватно учитывать нюансы входных данных, особенно в ситуациях, когда взаимосвязь между изображением и текстом не является прямой или очевидной. Например, модель может испытывать затруднения при интерпретации иронии, метафор или скрытых смыслов, которые требуют более глубокого понимания контекста и способности к абстрактному мышлению. В таких случаях, фиксированные шаблоны рассуждений оказываются неспособны выявить сложные взаимосвязи и сделать корректные выводы, что приводит к снижению общей производительности и точности модели.
Необходимость в более гибком подходе к обработке информации обусловлена тем, что современные мультимодальные языковые модели зачастую полагаются на заранее заданные схемы рассуждений. Вместо этого, требуется создание систем, способных адаптировать свою стратегию анализа в зависимости от специфики входных данных — будь то сложность визуальной сцены или неоднозначность текстового описания. Это означает, что модель должна не просто применять один и тот же алгоритм ко всем задачам, а оценивать характеристики каждого конкретного ввода и выбирать наиболее подходящий метод рассуждения, обеспечивая тем самым более точные и релевантные результаты. Такой динамический подход позволяет преодолеть ограничения, связанные с жестко заданными шаблонами, и значительно расширить возможности искусственного интеллекта в решении широкого круга задач.
Переход к моделям, способным динамически выбирать режим рассуждений, представляет собой ключевой шаг в развитии мультимодальных больших языковых моделей. Вместо жесткой привязки к заранее заданным шаблонам, такие модели способны анализировать характеристики входных данных — визуальную и текстовую информацию — и адаптировать стратегию рассуждений в режиме реального времени. Этот подход позволяет преодолеть ограничения, присущие фиксированным структурам, и эффективно решать сложные задачи, требующие тонкой интеграции различных типов информации. Способность модели самостоятельно определять оптимальный режим рассуждений открывает перспективы для создания более гибких и интеллектуальных систем, способных к адаптации и обучению в различных контекстах.

SwimBird: Модель, переключающая режимы рассуждений
SwimBird реализует динамически переключаемый подход к рассуждениям, автоматически выбирая один из трех режимов обработки входных данных: текстовый, визуальный или комбинированный. Выбор режима осуществляется на основе анализа входного запроса, позволяя модели адаптироваться к различным типам задач и оптимизировать процесс рассуждений. В текстовом режиме обрабатывается только текстовая информация, в визуальном — только визуальные данные, а в комбинированном режиме происходит одновременная обработка и интеграция как текста, так и изображений. Такая гибкость позволяет SwimBird эффективно решать задачи, требующие как лингвистического анализа, так и визуального понимания, избегая избыточной обработки данных в каждом конкретном случае.
Для реализации динамического переключения между режимами рассуждений SwimBird использует гибридную авторегрессионную формулировку. Она объединяет предсказание следующего токена (P(token_t | token_{
Модель SwimBird использует адаптивный бюджет визуальных токенов для оптимизации эффективности обработки изображений. Вместо фиксированного количества визуальных токенов, выделяемых для анализа, модель динамически регулирует их число в зависимости от сложности изображения и задачи. Этот подход позволяет снизить вычислительные затраты и время обработки, особенно для изображений с низкой информативностью или при выполнении задач, не требующих детального анализа визуальных деталей. Адаптивный бюджет реализуется путем оценки релевантности каждого визуального токена и отбрасывания наименее важных, что позволяет модели концентрироваться на ключевой визуальной информации и избегать избыточной обработки.
SwimBird расширяет подход латентного визуального рассуждения (Latent Visual Reasoning) за счет использования непрерывных латентных внедрений (continuous latent embeddings) для представления визуальных мыслей. Вместо дискретных визуальных токенов, модель кодирует визуальную информацию в непрерывное векторное пространство, что позволяет более точно и детализированно представлять визуальные аспекты входных данных. Такой подход позволяет модели лучше улавливать сложные взаимосвязи и нюансы в изображениях, значительно улучшая качество визуальной обработки и повышая эффективность рассуждений, основанных на визуальной информации. Использование непрерывных представлений также способствует уменьшению вычислительной сложности по сравнению с методами, использующими дискретные визуальные токены.
Обучение и валидация: Подтверждение возможностей SwimBird
Модель SwimBird прошла процедуру дообучения (fine-tuning) с использованием датасета SwimBird-SFT-92K, состоящего из 92 тысяч тщательно отобранных примеров. Этот датасет включает в себя данные трех типов: тексты без визуального сопровождения, изображения без текстового описания, и комбинации текста и изображений, требующие комплексного, взаимосвязанного анализа. Включение примеров всех трех типов позволило модели научиться эффективно обрабатывать и интегрировать информацию из различных источников, что необходимо для решения широкого спектра задач визуального рассуждения.
Процесс контролируемого обучения (Supervised Fine-Tuning) позволил модели SwimBird освоить стратегии оптимального выбора режима рассуждений для решения различных задач. Это достигается за счет обучения модели на размеченном наборе данных SwimBird-SFT-92K, включающем примеры задач, требующих обработки только текста, только изображений или комбинированного (смешанного) подхода. В результате, SwimBird способна динамически определять наиболее эффективный способ обработки входных данных и выбирать подходящий режим рассуждений - текстовый, визуальный или комбинированный - для достижения наилучшей производительности в конкретной задаче.
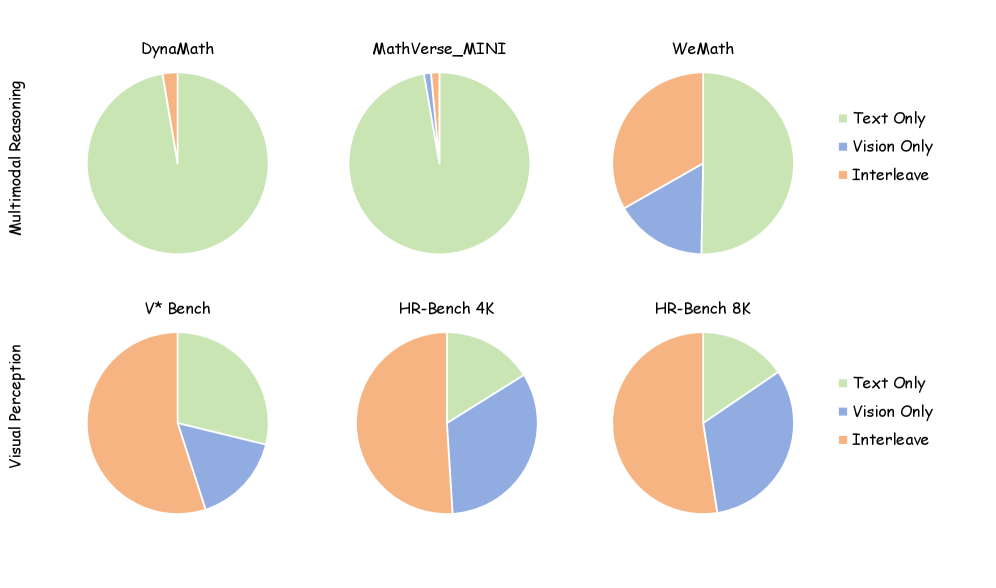
Для оценки возможностей SwimBird проводилось тщательное тестирование на общепризнанных бенчмарках, включая V Bench, HR-Bench и MMStar. Результаты показали высокую производительность модели в широком спектре задач, связанных с визуальным пониманием. На V Bench SwimBird достиг точности 85.5, на HR-Bench 4K - 79.0, а на MMStar - 71.2, что подтверждает её способность эффективно обрабатывать и интерпретировать визуальную информацию в различных контекстах.
Модель SwimBird демонстрирует передовые результаты на стандартных бенчмарках для оценки визуального понимания. Набор данных V* Bench показывает точность 85.5%, в то время как на HR-Bench 4K модель достигает 79.0% точности. Кроме того, на наборе данных MMStar SwimBird показывает результат в 71.2% точности, подтверждая высокую эффективность модели в решении задач, требующих комплексного анализа визуальной информации.
В ходе тестирования SwimBird продемонстрировал превосходство над существующими передовыми моделями на нескольких эталонных наборах данных. На наборе RealWorldQA модель достигла точности 73.1%, превзойдя показатели конкурентов. На сложном наборе DynaMath SwimBird показал точность 67.2%, а на MathVerse_MINI - 65.8%. Эти результаты подтверждают способность модели эффективно решать задачи, требующие рассуждений и понимания реального мира.
В основе SwimBird лежит модель Qwen3-VL, используемая в качестве базовой архитектуры. Для улучшения качества рассуждений и повышения эффективности работы модели был разработан специализированный системный промпт (System Prompt). Этот промпт предоставляет модели инструкции и контекст, необходимые для выбора оптимальной стратегии рассуждений при решении различных задач, что позволяет ей более эффективно обрабатывать визуальную информацию и генерировать точные ответы. Использование Qwen3-VL в сочетании с тщательно разработанным системным промптом является ключевым фактором, определяющим высокую производительность SwimBird.

К адаптивному интеллекту: Будущее мультимодального рассуждения
Способность SwimBird динамически переключать режимы рассуждений знаменует собой важный шаг к созданию более адаптивного и эффективного мультимодального интеллекта. В отличие от традиционных моделей, которые полагаются на фиксированный подход к обработке информации, SwimBird способен оценивать сложность входных данных и выбирать наиболее подходящий режим рассуждений - будь то обработка исключительно визуальной информации или же совместное использование визуальных и текстовых данных. Такая гибкость позволяет модели оптимизировать использование вычислительных ресурсов и достигать более высокой производительности при решении сложных задач, требующих глубокого понимания визуального контекста и умения сопоставлять его с текстовой информацией. Это открывает новые возможности для создания интеллектуальных систем, способных эффективно функционировать в реальных условиях, где входные данные могут быть неполными, неоднозначными или изменяться со временем.
Модель SwimBird демонстрирует высокую эффективность в обработке сложной информации благодаря использованию двух ключевых стратегий рассуждений. Применяя исключительно визуальное рассуждение (Vision-Only Reasoning) в случаях, когда текстовая информация избыточна, модель значительно снижает вычислительную нагрузку. В то же время, стратегия чередующегося визуально-текстового рассуждения (Interleaved Vision-Text Reasoning) позволяет эффективно интегрировать оба модальных источника данных, когда это необходимо для точного понимания. Такой подход позволяет модели динамически адаптироваться к характеру входных данных, оптимизируя ресурсы и повышая производительность при решении задач, требующих комплексного анализа визуальной и текстовой информации.
Архитектура SwimBird демонстрирует потенциал значительного улучшения результатов в задачах, требующих глубокого понимания визуальной информации, в частности, в области ответа на вопросы по изображениям и автоматического создания подписей к ним. Способность модели динамически адаптировать стратегию обработки данных, переключаясь между анализом исключительно визуальных признаков и их совместным анализом с текстовыми данными, позволяет ей более точно интерпретировать сложные сцены и предоставлять релевантные ответы или описания. Такой подход особенно важен в ситуациях, когда визуальный контекст неоднозначен или требует интеграции с дополнительной информацией, обеспечивая более надежное и точное решение поставленной задачи. Улучшенное понимание визуальных нюансов открывает возможности для создания более интеллектуальных систем, способных эффективно взаимодействовать с окружающим миром.
Разработанный подход открывает перспективы для создания более устойчивых и обобщенных мультимодальных моделей, способных решать широкий спектр задач, возникающих в реальном мире. В отличие от традиционных систем, часто ограниченных конкретными наборами данных или условиями, данная архитектура демонстрирует потенциал к адаптации и эффективной работе в различных сценариях. Это достигается за счет способности модели динамически переключаться между различными режимами рассуждений, оптимизируя использование вычислительных ресурсов и повышая точность анализа сложных визуальных и текстовых данных. В результате, появляется возможность разработки систем, которые смогут надежно функционировать в условиях неопределенности и изменчивости, что критически важно для применения в таких областях, как автономная навигация, медицинская диагностика и интеллектуальный анализ данных.
Исследование, представленное в данной работе, демонстрирует стремление к элегантности в архитектуре мультимодальных моделей. SwimBird, динамически переключаясь между текстовыми, визуальными и смешанными режимами рассуждений, избегает излишней сложности, присущей фиксированным шаблонам. Это напоминает о словах Эндрю Ына: «Самое сложное - это сделать что-то простое». Модель не просто обрабатывает информацию, а адаптируется к её природе, подобно тому, как опытный художник выбирает кисть и краски для каждого мазка. Такой подход позволяет SwimBird достигать лучших результатов как в задачах, ориентированных на текст, так и в задачах, требующих интенсивной визуальной обработки, подчеркивая важность гармонии между формой и функцией.
Куда же дальше?
Представленная работа, демонстрируя возможность динамического переключения между различными режимами рассуждений в мультимодальных языковых моделях, лишь слегка приоткрывает дверь в область адаптивных вычислений. Впрочем, иллюзия прогресса часто опережает реальное понимание. Очевидно, что простое переключение между текстовым и визуальным анализами - это лишь первый шаг. Настоящая сложность заключается в разработке механизмов, способных элегантным образом интегрировать эти режимы, создавая единую, гармоничную систему рассуждений. Как часто бывает, проблема не в количестве параметров, а в качестве архитектуры.
Особое внимание следует уделить исследованию латентных визуальных мыслей. Недостаточно просто "видеть" изображение; необходимо понять, как модель интерпретирует визуальную информацию, и как эта интерпретация влияет на процесс рассуждений. Иными словами, требуется глубинное понимание внутренней логики, скрытой за внешним поведением. В противном случае, мы рискуем создать сложные, но неэффективные системы, чья "интеллектуальность" окажется лишь иллюзией.
В конечном счете, успех в этой области потребует не только технических инноваций, но и философского осмысления самой природы интеллекта. Как часто случается, простое увеличение вычислительной мощности не решит фундаментальных проблем. Настоящая задача заключается в создании моделей, которые способны не просто имитировать интеллект, а понимать мир вокруг себя.
Оригинал статьи: https://arxiv.org/pdf/2602.06040.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Графы и действия: новый подход к планированию для роботов
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Генерация изображений: Новый взгляд на скорость и детализацию
- Визуальный разум: Как видеомодели научились понимать текст и создавать изображения
- Искусственный разум: Нет доказательств самосознания в современных языковых моделях
- Наука определений: Автоматическое извлечение знаний из научных текстов
- Квантовые состояния под давлением: сжатие данных для новых алгоритмов
2026-02-08 03:29