Автор: Денис Аветисян
Новая методика позволяет значительно уменьшить размер и повысить скорость работы мультимодальных моделей, не жертвуя точностью.
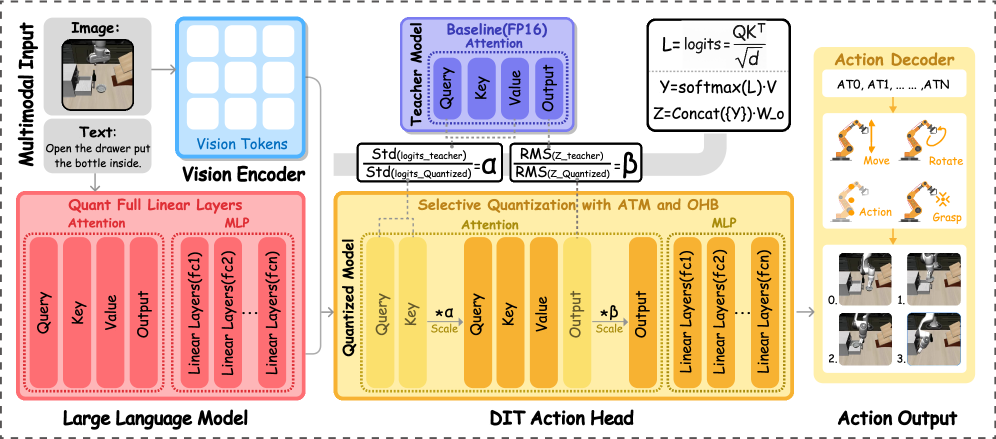
Представлен QuantVLA — фреймворк для постобработочной квантизации, оптимизирующий производительность DiT-based action head в задачах Vision-Language-Action.
Несмотря на впечатляющий прогресс в области моделей, объединяющих зрение, язык и действия (VLA), их практическое применение затруднено растущими вычислительными затратами и требованиями к памяти. В работе ‘QuantVLA: Scale-Calibrated Post-Training Quantization for Vision-Language-Action Models’ представлен новый фреймворк QuantVLA — метод постобработочной квантизации, позволяющий эффективно снизить точность представления моделей VLA без потери производительности. Ключевой особенностью подхода является калибровка масштаба, стабилизирующая квантованные веса и активации, особенно в архитектуре Diffusion Transformer (DiT), что позволяет превзойти результаты моделей, работающих в полной точности, и снизить потребление памяти примерно на 70%. Возможно ли дальнейшее совершенствование QuantVLA для расширения области применения низкобитовых моделей VLA в задачах, требующих ограниченных ресурсов?
Видение, язык и действие: между мечтой и реальностью
Модели, объединяющие зрение, язык и действия — так называемые VLA — становятся ключевым элементом в управлении роботами, преодолевая разрыв между восприятием окружающей среды и физическими действиями. Эти модели способны не просто распознавать объекты, но и понимать лингвистические команды, а затем преобразовывать их в последовательность действий, необходимых для выполнения поставленной задачи. В отличие от традиционных подходов, требующих ручного программирования каждого движения, VLA позволяют роботам адаптироваться к новым ситуациям и выполнять сложные инструкции, сформулированные естественным языком, открывая новые горизонты для автоматизации и взаимодействия человека с машинами. Благодаря способности к обучению на больших объемах данных, эти модели демонстрируют впечатляющие результаты в различных областях, от бытовой робототехники до промышленной автоматизации и поисково-спасательных операций.
Внедрение моделей «Зрение-Язык-Действие» (VLA) в реальные условия эксплуатации предъявляет повышенные требования к вычислительной эффективности, значительно превосходящие возможности традиционных подходов. Проблема заключается в том, что для обработки визуальной информации, лингвистических команд и генерации действий в реальном времени требуется огромное количество вычислительных ресурсов. Стандартные методы машинного обучения зачастую оказываются слишком ресурсоемкими для работы на бортовых компьютерах роботов или в условиях ограниченной инфраструктуры. Это требует разработки новых архитектур моделей и алгоритмов оптимизации, способных сохранять высокую производительность при минимальном потреблении энергии и вычислительных мощностей, чтобы VLA могли успешно функционировать за пределами лабораторных условий.
Существенная проблема при разработке моделей «Видение-Язык-Действие» заключается в поиске баланса между вычислительной мощностью модели и ограничениями, накладываемыми бортовыми компьютерами и необходимостью оперативной реакции. Увеличение сложности модели, необходимое для достижения высокой точности распознавания и планирования действий, приводит к росту требований к вычислительным ресурсам и времени обработки данных. Это создает препятствие для внедрения таких моделей в реальные робототехнические системы, где критически важна скорость реакции и возможность функционирования в условиях ограниченной энергии и вычислительной мощности. Необходимы инновационные подходы к архитектуре моделей и оптимизации алгоритмов, позволяющие добиться высокой производительности при сохранении приемлемого уровня точности и эффективности.

Архитектуры VLA: в поисках оптимального решения
Для решения задач повышения эффективности работы больших языковых моделей (LLM) разработано несколько фреймворков VLA (Very Large Array). Среди них выделяются OpenPI π0.5, GR00T N1.5, TinyVLA, SmolVLA, EfficientVLA и VLA-Cache. Эти фреймворки представляют собой различные подходы к оптимизации LLM, направленные на снижение вычислительных затрат и требований к памяти без существенной потери производительности. Каждая из реализаций предлагает свой набор методов, включая уменьшение размера модели, асинхронный вывод и использование кэширования для ускорения обработки данных.
Различные подходы к оптимизации VLA (Very Large Array) включают в себя несколько ключевых стратегий. Компактные конструкции трансформеров направлены на уменьшение количества параметров модели без существенной потери производительности. Асинхронный вывод позволяет параллельно обрабатывать данные, повышая пропускную способность. Механизмы кэширования сокращают время доступа к часто используемым данным, а техники прунинга (отсечения) удаляют наименее важные параметры модели, снижая вычислительные затраты и размер модели. Каждая из этих стратегий применяется в различных VLA-фреймворках, таких как OpenPI π0.5, GR00T N1.5 и других, для достижения оптимального баланса между размером модели, вычислительной сложностью и эффективностью выполнения задач в симуляционной среде LIBERO.
Каждый из рассматриваемых фреймворков для эффективных VLA (OpenPI π0.5, GR00T N1.5, TinyVLA, SmolVLA, EfficientVLA и VLA-Cache) демонстрирует уникальный компромисс между размером модели, вычислительными затратами и производительностью на задачах, оцениваемых в симуляционной среде LIBERO. Размер модели, измеряемый в количестве параметров, напрямую влияет на требуемый объем памяти и скорость вычислений. Вычислительные затраты, как правило, выражаются в FLOPS (операциях с плавающей точкой в секунду) или времени инференса. Производительность в LIBERO измеряется по конкретным метрикам, зависящим от решаемой задачи, что позволяет количественно оценить эффективность каждого подхода в достижении оптимального баланса между этими тремя ключевыми факторами.

QuantVLA: пост-тренировочная квантизация для VLA
QuantVLA представляет собой фреймворк пост-тренировочной квантизации, разработанный специально для визуальных языковых моделей (VLA). Он позволяет значительно снизить потребление памяти за счет квантизации отдельных модулей, достигая до 70% относительной экономии памяти. В отличие от универсальных решений, QuantVLA оптимизирован для архитектур VLA, что позволяет эффективно уменьшить размер модели без существенной потери производительности. Этот подход особенно важен для развертывания VLA на устройствах с ограниченными ресурсами, таких как роботы или встроенные системы.
Для решения специфических задач квантования VLAs (Variable Length Arrays) в QuantVLA используется комплексный подход, включающий в себя методы DuQuant, Attention Temperature Matching и Output Head Balancing. DuQuant оптимизирует процесс квантования путем динамической адаптации масштаба и смещения для каждого тензора. Attention Temperature Matching корректирует температурные параметры в механизмах внимания, что позволяет сохранить информативность при пониженной точности. Output Head Balancing калибрует выходные слои модели для минимизации потерь точности, вызванных квантованием. В совокупности эти методы направлены на смягчение деградации производительности и обеспечение высокой точности квантованных VLAs при выполнении сложных задач.
Применение методов DuQuant, Attention Temperature Matching и Output Head Balancing в QuantVLA позволяет минимизировать потерю производительности при квантовании VLA, обеспечивая высокую точность и отзывчивость в задачах пространственного мышления, манипулирования объектами и долгосрочного управления в рамках платформы LIBERO. Тестирование показало, что квантованные модели достигают показателей успешности в 97.6% на OpenPI π0.5 и 88.0% на GR00T N1.5, что подтверждает эффективность предложенных методов по сохранению функциональности VLA после квантизации.
Квантизация, несмотря на снижение потребления памяти, может приводить к явлению “смещения масштаба” (Scale Drift) в архитектуре Diffusion Transformer. Данное смещение влияет на энергию остаточного потока (Residual Stream Energy), что требует тщательной калибровки параметров квантования для сохранения стабильности и эффективности модели. Некорректная калибровка может привести к снижению точности предсказаний и ухудшению производительности в задачах, требующих высокой чувствительности к изменениям входных данных.

За горизонтом: будущее эффективных VLA и их влияние
Современные достижения в области эффективности визуальных языковых моделей (VLA), демонстрируемые такими фреймворками, как MoLe-VLA и QuantVLA, открывают новые перспективы для создания более совершенных и доступных роботов. Эти модели, оптимизированные для снижения вычислительных затрат, позволяют внедрять сложные алгоритмы обработки изображений и принятия решений непосредственно на борту робота, расширяя его возможности автономной навигации, взаимодействия с окружающей средой и выполнения задач. Благодаря этому, роботы становятся менее зависимыми от мощных серверов и стабильного интернет-соединения, что делает их пригодными для использования в широком спектре применений, включая сельское хозяйство, логистику, домашнюю автоматизацию и даже исследования в труднодоступных местах. Увеличение эффективности VLA является ключевым фактором для демократизации робототехники, позволяя создавать более дешевые, компактные и энергоэффективные устройства, способные решать сложные задачи и улучшать качество жизни людей.
Современные достижения в области виртуальных локальных сетей (VLA) позволяют значительно снизить вычислительные затраты, что открывает возможности для развертывания этих моделей непосредственно на периферийных устройствах. Это означает, что сложные алгоритмы управления роботами могут функционировать в режиме реального времени, не требуя постоянного подключения к облачным серверам. Такая децентрализация не только повышает скорость реакции и надежность систем, но и обеспечивает конфиденциальность данных, поскольку обработка информации происходит локально, на самом устройстве. Размещение вычислений на периферии также снижает задержки, вызванные сетевыми соединениями, что критически важно для приложений, требующих мгновенного отклика, таких как автономные транспортные средства и промышленные роботы.
Дальнейшие исследования в области эффективных визуальных языковых моделей (VLA) сосредоточены на трех ключевых направлениях. Во-первых, изучаются новые методы квантования, позволяющие снизить точность вычислений без существенной потери качества, что критически важно для развертывания моделей на устройствах с ограниченными ресурсами. Во-вторых, разрабатываются адаптивные стратегии вычислений, которые динамически регулируют сложность вычислений в зависимости от входных данных и текущей задачи. Наконец, значительное внимание уделяется аппаратному ускорению, включая использование специализированных процессоров и графических ускорителей для оптимизации операций, связанных с VLA. Комбинирование этих подходов позволит существенно повысить эффективность VLA, открывая новые возможности для робототехники и других областей, требующих обработки визуальной информации в реальном времени.
Исследование QuantVLA демонстрирует неизбежность компромиссов. Авторы пытаются обуздать “хаос управляемым” способом, калибруя квантование для моделей Vision-Language-Action. Подобно тому, как багтрекер фиксирует дневник боли при столкновении теории с реальностью, QuantVLA регистрирует чувствительность DiT-based action head к квантованию. Дональд Дэвис однажды заметил: «Простота — это конечное совершенство, достигнутое после долгих усилий». В данном случае, стремление к эффективному выводу в условиях низкого битрейта — это поиск этой самой простоты, но цена её — точная калибровка и учет особенностей архитектуры. Попытки упростить модель всегда сталкиваются с необходимостью отладки и исправления неизбежных ошибок.
Что дальше?
Предложенный фреймворк QuantVLA, безусловно, демонстрирует снижение вычислительной нагрузки. Однако, не стоит обольщаться — каждое «самовосстанавливающееся» решение лишь откладывает неизбежное. Повышение эффективности за счет квантизации — это всегда компромисс, и рано или поздно, производственный процесс найдёт способ вывернуть этот компромисс наизнанку. Особенно учитывая, что DiT-based action head оказался настолько чувствителен к квантизации — видимо, элегантная теория встретилась с суровой реальностью.
Следующим этапом, вероятно, станет попытка автоматизировать процесс калибровки. Учитывая, что документация — это, в лучшем случае, форма коллективного самообмана, автоматизация — единственный способ хоть как-то удержаться на плаву. Вопрос в том, насколько успешно удастся скрыть истинные причины ошибок под слоем алгоритмической магии. Если баг воспроизводится — значит, у нас стабильная система, а не наоборот.
И, конечно, стоит помнить, что Vision-Language-Action модели — это лишь вершина айсберга. В конечном счёте, всё это — ещё один уровень абстракции, который рано или поздно потребует пересмотра. Всё, что сейчас кажется прорывом, завтра станет техническим долгом. И это, пожалуй, самое предсказуемое будущее.
Оригинал статьи: https://arxiv.org/pdf/2602.20309.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
2026-02-25 14:49