Автор: Денис Аветисян
Исследователи разработали метод, позволяющий значительно уменьшить размер моделей, состоящих из множества экспертов, практически не теряя при этом точности.
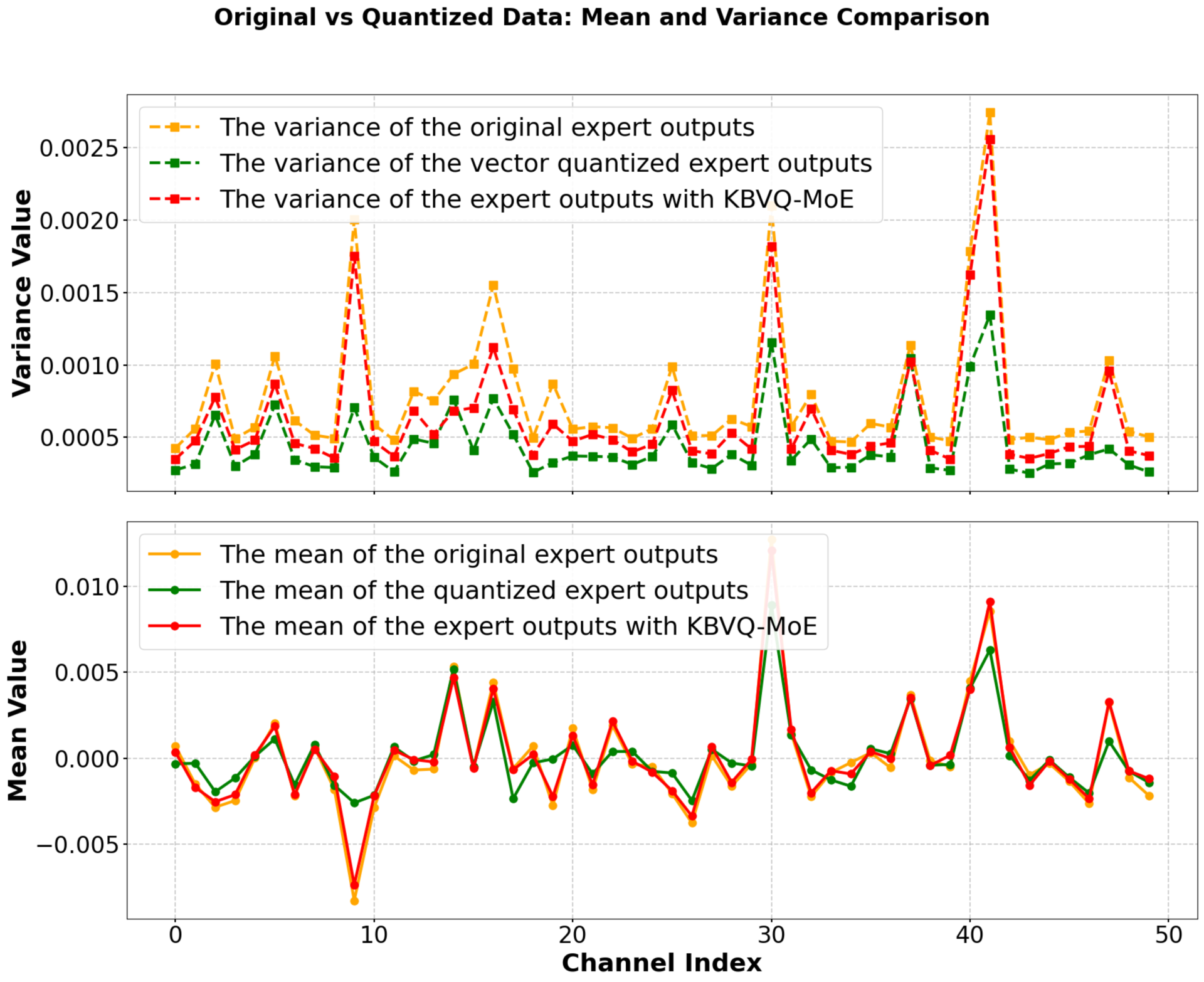
Представлена технология KBVQ-MoE, использующая векторизованную квантизацию с коррекцией смещений для эффективного сжатия моделей экспертов.
Модели, основанные на архитектуре Mixture-of-Experts (MoE), демонстрируют впечатляющую производительность, однако их огромные размеры представляют серьезные трудности для развертывания в условиях ограниченных ресурсов. В данной работе, посвященной разработке фреймворка ‘KBVQ-MoE: KLT-guided SVD with Bias-Corrected Vector Quantization for MoE Large Language Models’, предложен новый подход к квантованию весов, позволяющий достичь высокой точности при ультранизком разрешении. В основе метода лежит устранение избыточности и коррекция смещений, достигаемые за счет использования Karhunen-Loeve Transform (KLT) и аффинной компенсации. Возможно ли с помощью KBVQ-MoE значительно расширить возможности развертывания больших языковых моделей на периферийных устройствах и в других ресурсоограниченных средах?
Масштабируемость больших языковых моделей: вызовы и перспективы
Современные большие языковые модели, такие как Qwen3-Next-80B-A3B и Mixtral-8x7B, демонстрируют впечатляющие возможности в обработке и генерации текста, однако их масштабные размеры сопряжены со значительными вычислительными издержками. Для эффективной работы с этими моделями требуется колоссальное количество памяти и вычислительной мощности, что существенно ограничивает их доступность и возможности развертывания на стандартном оборудовании. Каждый новый параметр в модели увеличивает потребность в ресурсах, что приводит к росту затрат на обучение и инференс, а также к увеличению времени отклика. Таким образом, несмотря на впечатляющие результаты, огромный размер моделей представляет собой серьезное препятствие для их широкого применения и интеграции в различные системы и приложения.
Традиционные методы масштабирования языковых моделей, заключающиеся в увеличении числа параметров, сталкиваются с законом убывающей доходности. По мере роста модели, прирост производительности становится всё менее значительным, в то время как вычислительные затраты и требования к памяти растут экспоненциально. Это приводит к увеличению стоимости обучения и развертывания, что серьезно ограничивает доступность и практическое применение мощных языковых моделей для широкого круга пользователей и организаций. В результате, даже при наличии перспективных архитектур, экономические и технические барьеры препятствуют повсеместному внедрению этих технологий, сдерживая развитие инноваций и усложняя решение задач, требующих обработки больших объемов данных.
Архитектура “Смесь экспертов” (MoE) представляет собой перспективное решение для масштабирования языковых моделей без сопутствующего экспоненциального роста вычислительных затрат. В отличие от традиционных плотных моделей, где каждый параметр участвует в каждой операции, MoE распределяет параметры между множеством “экспертов” — небольших подмоделей. При обработке каждого входного токена, лишь небольшая часть экспертов активируется, определяемая “гейтом” — другой нейронной сетью. Это позволяет значительно увеличить общую емкость модели — количество параметров — не увеличивая пропорционально вычислительную нагрузку на этапе инференса. Таким образом, MoE позволяет создавать модели с повышенной способностью к обучению и генерации, сохраняя при этом приемлемую скорость работы и снижая требования к ресурсам, что открывает возможности для более широкого применения и развертывания крупных языковых моделей.
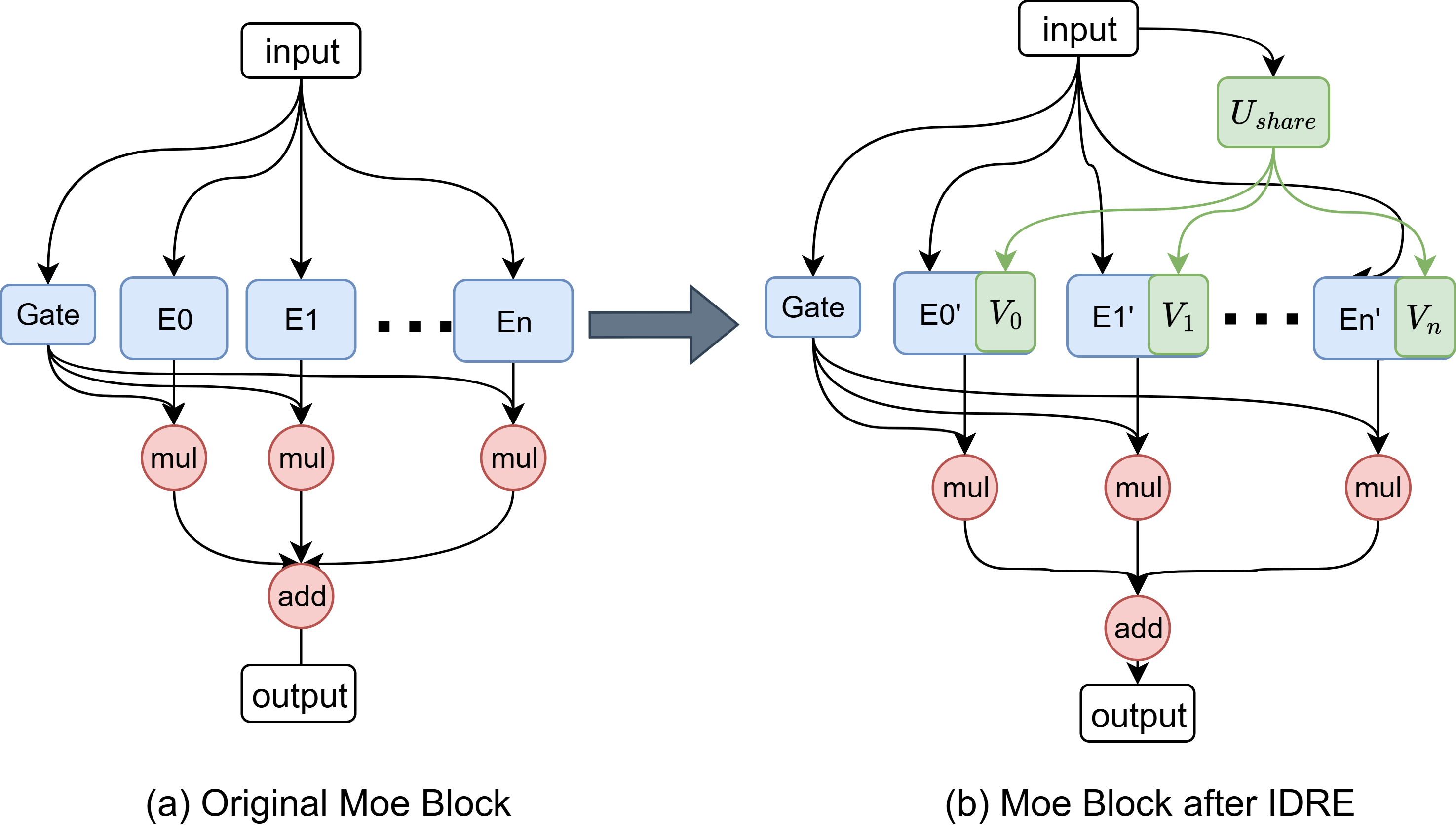
Устранение избыточности в архитектуре «Смесь экспертов»
В моделях «Смесь экспертов» (MoE) часто возникает проблема избыточности экспертов, заключающаяся в дублировании функциональных ролей. Это приводит к неэффективному использованию вычислительных ресурсов, поскольку несколько экспертов могут обрабатывать одни и те же типы входных данных. Избыточность снижает общую производительность модели, увеличивает потребление памяти и замедляет процесс обучения, поскольку параметры, связанные с избыточными экспертами, требуют обновления, не внося существенного вклада в обобщающую способность модели. Эффективное устранение избыточности является критически важным для масштабирования MoE-моделей и достижения оптимальной производительности.
Метод InputDrivenRedundancyElimination, реализованный в KBVQ-MoE, использует преобразование Карунена-Лоэва (KLT) и сингулярное разложение (SVD) для выявления и устранения избыточных связей между экспертами в модели Mixture of Experts. KLT применяется для анализа корреляции входных данных и определения главных компонент, а SVD используется для декомпозиции матриц весов связей между входными данными и экспертами. Анализ полученных сингулярных значений позволяет идентифицировать линейно зависимые связи, которые указывают на функциональное дублирование экспертов. Устранение этих избыточных связей способствует более эффективному распределению нагрузки и специализации экспертов, что приводит к повышению общей производительности модели.
Метод KBVQ-MoE направлен на повышение эффективности использования каждого эксперта в модели, оптимизируя специализацию каждого из них. Это достигается за счет анализа и перераспределения входящих связей между экспертами и входными данными, что позволяет более точно направлять каждый вход к наиболее подходящему эксперту для обработки. В результате, снижается избыточность, когда несколько экспертов обрабатывают одни и те же данные, и максимизируется вклад каждого эксперта в общую производительность модели, что приводит к повышению общей эффективности и снижению вычислительных затрат.
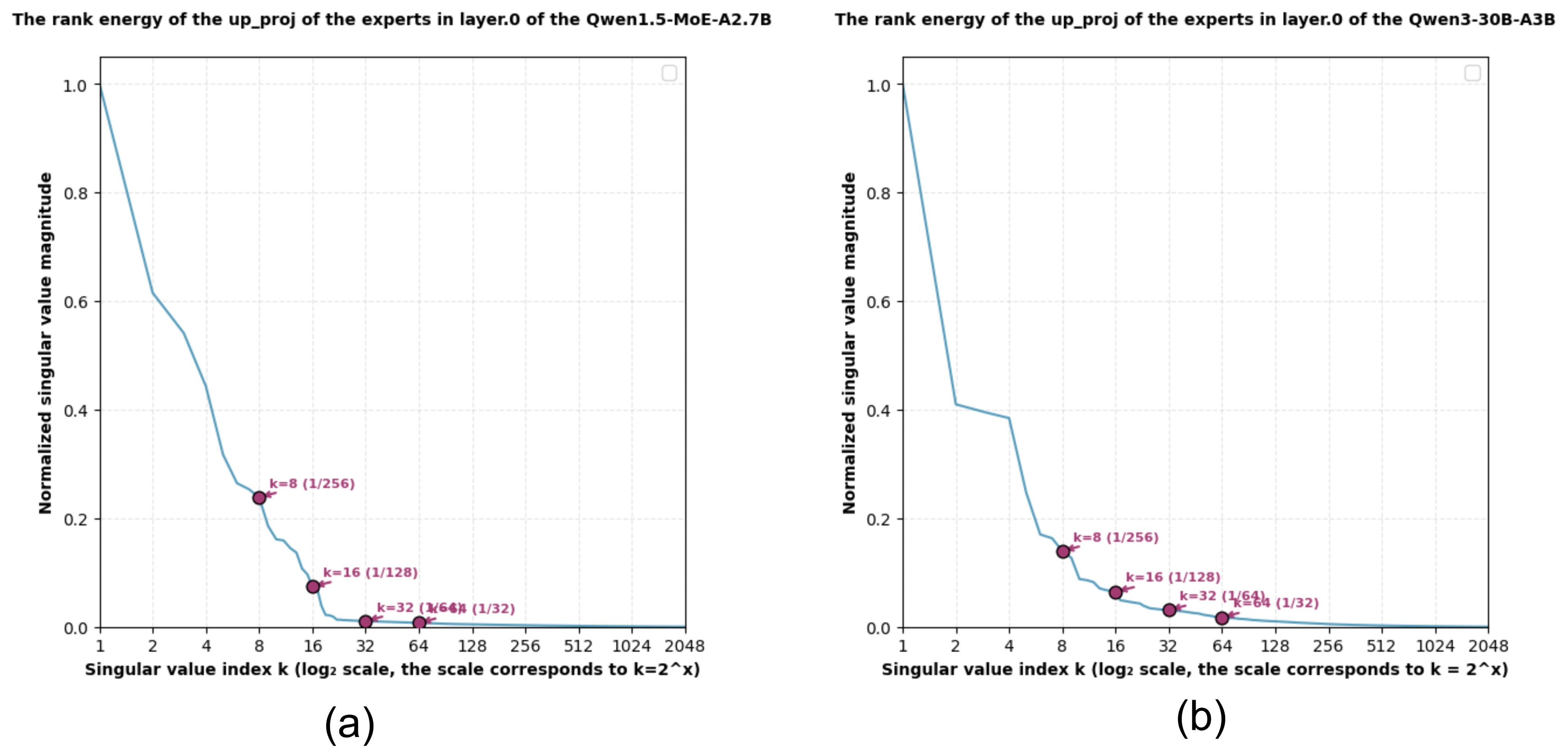
Квантование и проблема кумулятивной ошибки: математическая строгость
Посттренировочная квантизация (PostTrainingQuantization) является ключевым методом для эффективного развертывания моделей MoE, однако использование низкобитовой квантизации может усугубить проблему кумулятивной ошибки квантизации (CumulativeQuantizationError). Эта ошибка возникает из-за последовательного накопления погрешностей округления при преобразовании весов и активаций модели в формат с меньшей точностью. Снижение битовой глубины, хотя и уменьшает размер модели и требования к памяти, приводит к увеличению этих ошибок, что негативно сказывается на производительности и точности модели. Таким образом, при применении посттренировочной квантизации к моделям MoE необходимо тщательно балансировать между степенью сжатия и допустимым уровнем деградации производительности.
KBVQ-MoE использует технику векторной квантизации, известную как BiasCorrectedOutputStabilization, для смягчения смещения и стабилизации выходных данных в процессе квантизации. Данный подход корректирует смещение, возникающее из-за дискретизации, и предотвращает отклонения в выходных значениях, которые могут возникнуть при использовании низкобитной квантизации. Это достигается за счет внесения поправок в выходные данные, основанных на статистических характеристиках квантованного представления, что позволяет сохранить точность модели даже при значительном снижении битовой глубины.
При использовании 2-3 битной квантизации, разработанная методика KBVQ-MoE демонстрирует впечатляющее соотношение сжатия в 87%, что позволяет существенно снизить требования к объему памяти. Это достигается за счет эффективной векторной квантизации, минимизирующей потери информации при представлении данных в низкобитном формате. Сжатие до такого уровня особенно важно для развертывания больших моделей, таких как Mixture-of-Experts (MoE), где объем параметров может быть значительным, и снижение требований к памяти напрямую влияет на возможность их использования на устройствах с ограниченными ресурсами.
Эмпирическая валидация и производительность на ключевых бенчмарках
Эксперименты, проведенные на наборах данных WikiText2 и ARC-Challenge, показали, что KBVQ-MoE превосходит базовые методы векторной квантизации, такие как VPTQ и GPTVQ. В ходе тестов KBVQ-MoE продемонстрировал более высокие показатели в задачах языкового моделирования и решения логических задач, что свидетельствует о его эффективности в сохранении информации при снижении точности представления данных. Полученные результаты подтверждают, что KBVQ-MoE обеспечивает лучшую производительность по сравнению с альтернативными подходами к квантизации векторов.
При оценке на корпусе WikiText2, модель KBVQ-MoE в сочетании с Mixtral-8x7B демонстрирует перплексию в 2.39. Этот показатель ниже, чем у моделей Sub-MoE и D2-MoE, у которых зафиксирована перплексия 2.90. Полученные результаты указывают на превосходство KBVQ-MoE в задаче языкового моделирования при использовании Mixtral-8x7B, что подтверждается более низкой перплексией по сравнению с альтернативными подходами.
При оценке на наборе данных ARC-Challenge, модель KBVQ-MoE, использующая Mixtral-8x7B, продемонстрировала точность 63.12%. Этот результат превосходит показатели других моделей: Sub-MoE и D2-MoE показали точность 56.48%, а EAC-MoE — 62.34%. Превышение точности KBVQ-MoE над EAC-MoE составило 0.78 процентных пункта, что подтверждает ее эффективность в задачах, требующих высокой точности и сложных рассуждений.
Результаты экспериментов демонстрируют высокую эффективность KBVQ-MoE в сохранении точности модели при агрессивной квантизации. В частности, на эталонных наборах данных WikiText2 и ARC-Challenge, KBVQ-MoE превосходит альтернативные методы векторной квантизации, такие как VPTQ, GPTVQ, Sub-MoE, D2-MoE и EAC-MoE, что подтверждает ее способность минимизировать потерю производительности при значительном снижении вычислительных затрат и требований к памяти. Это делает KBVQ-MoE особенно привлекательным для развертывания моделей в условиях ограниченных ресурсов, таких как мобильные устройства или периферийные вычисления.
К эффективным и доступным большим языковым моделям: взгляд в будущее
Разработанная архитектура KBVQ-MoE представляет собой перспективный подход к созданию и внедрению высокоэффективных больших языковых моделей. В отличие от традиционных плотных моделей, KBVQ-MoE использует разреженную структуру, что позволяет значительно сократить вычислительные затраты и требования к памяти. Ключевым нововведением является применение векторной квантизации для уменьшения размера параметров, сохраняя при этом высокую производительность. Это достигается путем группировки весов модели в векторы и представления каждого вектора с помощью ближайшего центра кластера. В результате, модели становятся более компактными и доступными для развертывания на устройствах с ограниченными ресурсами, расширяя возможности использования искусственного интеллекта для более широкого круга пользователей и приложений. Такой подход открывает путь к более устойчивым и экономичным решениям в области обработки естественного языка.
Дальнейшие исследования направлены на изучение адаптивных стратегий квантования, позволяющих динамически регулировать точность представления параметров модели в зависимости от их важности. Особое внимание уделяется взаимосвязи между устранением избыточности в структуре модели и ошибками, возникающими при квантовании. Ученые предполагают, что эффективное удаление избыточных параметров может снизить чувствительность к ошибкам квантования, позволяя использовать более низкую точность представления данных без существенной потери производительности. Такой подход может существенно снизить вычислительные затраты и требования к памяти, делая большие языковые модели более доступными и эффективными для широкого круга приложений, особенно на устройствах с ограниченными ресурсами.
Решение текущих задач, связанных с оптимизацией разреженности и квантованием моделей экспертов (MoE), открывает путь к значительному повышению эффективности и доступности больших языковых моделей. Устранение этих препятствий позволит в полной мере реализовать потенциал MoE-архитектур, снижая потребность в вычислительных ресурсах и энергозатратах. Это, в свою очередь, сделает передовые технологии искусственного интеллекта более устойчивыми и позволит применять их в широком спектре областей, включая экологический мониторинг, персонализированную медицину и образовательные программы, способствуя созданию более значимых и полезных приложений для общества.
Представленная работа демонстрирует элегантность подхода к квантованию моделей Mixture-of-Experts. Авторы, стремясь к минимизации избыточности и коррекции смещения, достигают впечатляющих результатов, приближающихся к точности полноразрядных вычислений. Как отмечал Анри Пуанкаре: «Математика — это искусство давать верные ответы на вопросы, которые никто не задавал». В данном исследовании, подобно математическому доказательству, алгоритм KBVQ-MoE представляет собой логически обоснованное решение, где каждая операция направлена на повышение эффективности и снижение вычислительных затрат, что соответствует принципу доказательства корректности алгоритма, а не просто его работоспособности на тестовых данных.
Что дальше?
Представленная работа, безусловно, демонстрирует элегантность подхода к квантованию моделей типа Mixture-of-Experts. Однако, пусть N стремится к бесконечности — что останется устойчивым? Сокращение битов — это лишь симптом, а не лекарство от фундаментальной проблемы: экспоненциального роста параметров в современных языковых моделях. Вопрос не в том, насколько сильно можно сжать, а в том, как избежать необходимости в столь огромном количестве параметров изначально. Устойчивость к возмущениям, наблюдаемая в экспериментах, не гарантирует абсолютную надежность в условиях непредвиденных входных данных или при масштабировании до еще больших моделей.
Дальнейшие исследования должны быть направлены не только на улучшение алгоритмов квантования, но и на поиск принципиально новых архитектур, способных достигать аналогичной производительности при значительно меньшем количестве параметров. Необходимо углубиться в понимание внутренней структуры представлений, формируемых моделями, и выявить избыточные или несущественные компоненты. В частности, перспективным направлением представляется разработка методов, позволяющих динамически адаптировать архитектуру модели в процессе обучения, отбрасывая ненужные параметры и оптимизируя структуру связей.
Наконец, важно помнить, что любое приближение, даже самое изящное, вносит определенную погрешность. Вопрос заключается в том, насколько эта погрешность критична для конкретной задачи и возможно ли ее контролировать. Простое увеличение точности на тестовых данных — недостаточный критерий. Необходимо проводить более глубокий анализ влияния квантования на обобщающую способность модели и ее устойчивость к враждебным атакам.
Оригинал статьи: https://arxiv.org/pdf/2602.11184.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Физика под контролем: Как «научить» модели понимать мир
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Пространственная Архитектура для Эффективного Ускорения Нейросетей
- Рассуждения на графах: как большие языковые модели учатся видеть мир
- Гибкие нейросети: как динамическая выборка меняет правила игры
- Грань между Творчеством и Риском: Искусственный Интеллект и Эротический Контент
2026-02-15 22:35