Автор: Денис Аветисян
Новое исследование посвящено методам квантования, позволяющим значительно сократить размер многомодальных моделей, без существенной потери качества.
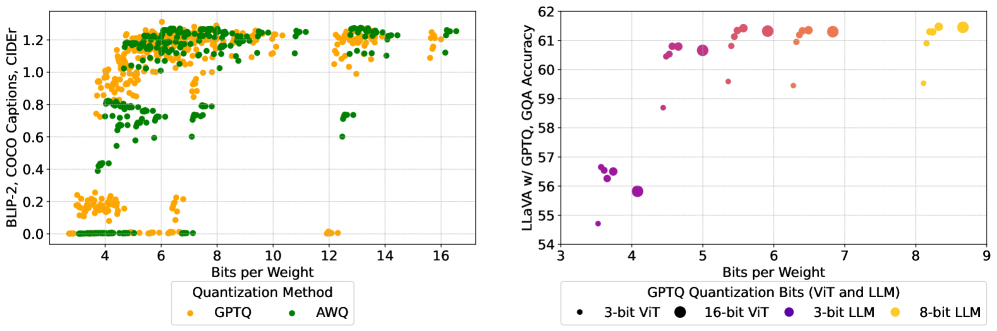
Анализ чувствительности различных компонентов и оптимального распределения разрядности при квантовании больших языковых моделей, работающих с изображениями и текстом.
Современные мультимодальные большие языковые модели демонстрируют впечатляющие результаты, однако их развертывание требует значительных вычислительных ресурсов. В работе ‘Towards Understanding Best Practices for Quantization of Vision-Language Models’ исследуются методы эффективной квантизации параметров для снижения требований к памяти и задержке, применительно к системам, объединяющим визуальные и языковые модели. Полученные результаты указывают на сравнимую важность как визуальных трансформеров, так и языковых моделей для общей производительности, и на возможность достижения высокой точности при использовании низкобитной квантизации для языковой части. Какие стратегии оптимального распределения бит между компонентами мультимодальных моделей позволят добиться максимальной эффективности и сохранить качество работы?
За гранью иллюзий: мультимодальные модели и ловушка вычислительных затрат
Современные мультимодальные модели, объединяющие обработку зрения и языка, открывают перспективы создания искусственного интеллекта, способного воспринимать мир подобно человеку. Эти системы, в отличие от традиционных, способны не просто анализировать отдельные типы данных, такие как текст или изображения, но и интегрировать их, выявляя сложные взаимосвязи и контекст. Например, модель может не просто распознать объект на фотографии, но и понять его значение в конкретной ситуации, описанной текстовым запросом. Такой подход позволяет создавать более интуитивно понятные и эффективные системы, способные решать задачи, требующие комплексного анализа и понимания окружающей среды, приближая искусственный интеллект к человеческому уровню когнитивных способностей.
Современные мультимодальные модели, особенно те, что основаны на архитектуре Transformer, демонстрируют впечатляющие возможности в обработке различных типов данных, таких как изображения и текст. Однако, их растущая сложность влечет за собой значительные вычислительные затраты и потребности в памяти. Каждый новый слой и увеличение количества параметров в модели требует экспоненциального роста ресурсов для обучения и последующего развертывания. Это становится критическим препятствием для широкого применения, поскольку даже самые мощные вычислительные системы сталкиваются с ограничениями по памяти и пропускной способности. В результате, исследователи активно ищут способы оптимизации этих моделей, чтобы снизить их вычислительную нагрузку без существенной потери в качестве результатов.
Дальнейшее масштабирование современных мультимодальных моделей, использующих архитектуру Transformer, сталкивается с серьезными ограничениями, обусловленными квадратичной сложностью механизмов внимания. Это означает, что вычислительные затраты и требования к памяти растут экспоненциально с увеличением размера входных данных, что препятствует их практическому применению. Для сохранения приемлемой производительности традиционные методы унифицированной квантизации требуют 6.0-8.0 бит на вес (bpw), что также увеличивает объем необходимых ресурсов. В настоящее время активно разрабатываются новые подходы, направленные на значительное уменьшение этого показателя, стремящиеся к более эффективному представлению весов модели без существенной потери точности. Эти инновации являются ключевыми для развертывания мощных мультимодальных моделей на устройствах с ограниченными ресурсами и для ускорения процессов обучения и инференса.
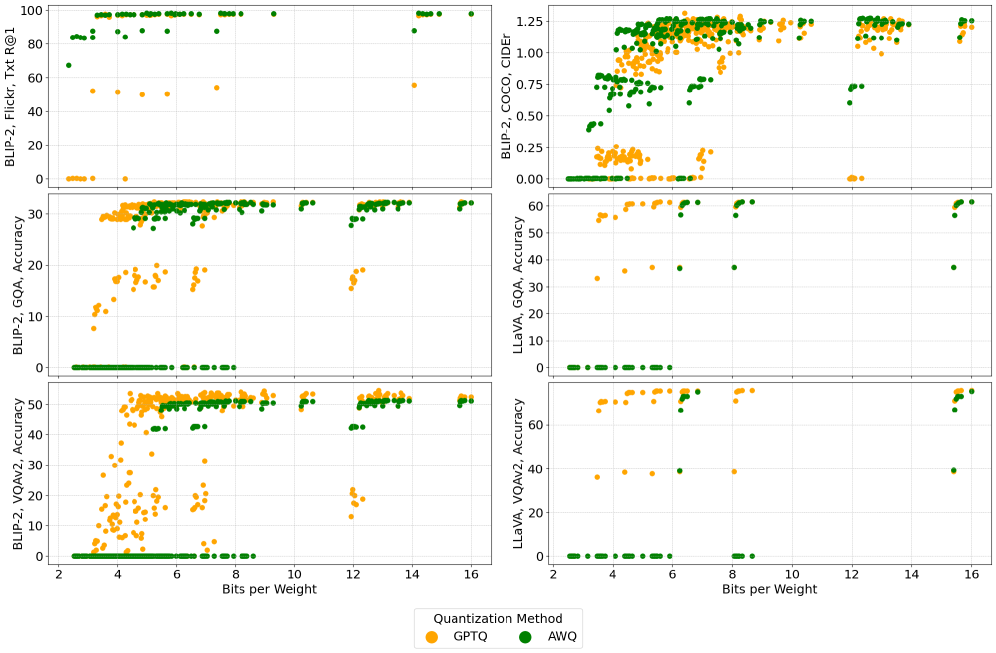
Сжатие моделей: путь к эффективному мультимодальному ИИ
Сжатие моделей представляет собой набор методов, направленных на уменьшение размера моделей искусственного интеллекта, включающий в себя квантование, прунинг и дистилляцию знаний. Квантование снижает точность представления весов модели, что приводит к уменьшению объема занимаемой памяти и ускорению вычислений. Прунинг удаляет избыточные связи и параметры модели, уменьшая ее сложность. Дистилляция знаний позволяет перенести знания из большой, сложной модели в более компактную, сохраняя при этом производительность. Комбинирование этих методов позволяет существенно уменьшить размер модели без значительной потери точности.
Квантизация, как метод сжатия моделей, заключается в снижении разрядности представления весов нейронной сети. Вместо традиционных 32-битных чисел с плавающей точкой (float32), веса представляются с использованием меньшего количества бит, например, 8-битных целых чисел (int8) или даже меньшей разрядности. Это приводит к значительному уменьшению занимаемого моделью объема памяти, так как для хранения каждого веса требуется меньше бит. Снижение разрядности также ускоряет вычисления, поскольку операции с меньшей точностью требуют меньше вычислительных ресурсов и могут быть эффективно реализованы на специализированном оборудовании, таком как тензорные процессоры. При этом необходимо учитывать, что чрезмерное снижение разрядности может привести к потере точности модели, поэтому выбор оптимальной разрядности является важной задачей.
Методы обрезки (pruning) и дистилляции знаний (knowledge distillation) позволяют дополнительно повысить эффективность моделей за счет удаления избыточности и переноса знаний из более крупных моделей. Обрезка предполагает удаление наименее значимых весов, снижая вычислительную нагрузку и размер модели. Дистилляция знаний позволяет «студенческой» модели, меньшего размера, обучиться, имитируя поведение более сложной «учительской» модели. Современные исследования демонстрируют возможность достижения сжатия до 3.5-4.5 бит на вес, что существенно снижает требования к памяти и вычислительным ресурсам без значительной потери производительности.
Продвинутые методы квантизации: AWQ, GPTQ и равномерная квантизация
Унифицированная квантизация, несмотря на свою простоту реализации, часто приводит к существенной потере точности. Это связано с тем, что данный метод предполагает грубое дискретизирование весов модели, округляя их до ближайшего представимого значения в заданном диапазоне. В результате происходит потеря информации, что особенно критично для больших языковых моделей (LLM), где даже небольшие изменения в весах могут оказывать значительное влияние на производительность. В отличие от более продвинутых методов, унифицированная квантизация не учитывает важность отдельных весов или активаций, что приводит к неравномерному ухудшению точности по всем параметрам модели.
В отличие от унифицированной квантизации, приводящей к значительным потерям точности, методы AWQ и GPTQ используют селективную квантизацию весов, что позволяет сохранять наиболее важные признаки модели и минимизировать снижение производительности. Экспериментальные данные показывают, что эти методы способны поддерживать исходный уровень производительности при снижении разрядности до 3.5-4.5 бит, что является существенным улучшением по сравнению с традиционными подходами к квантизации, где даже незначительное снижение разрядности обычно приводит к заметному ухудшению качества работы модели.
Метод AWQ (Activation-aware Weight Quantization) концентрируется на сохранении распределений активаций в процессе квантизации весов, в то время как GPTQ (Generative Post-training Quantization) использует информацию второго порядка для достижения более точной квантизации. Анализ показывает существенные различия в важности компонентов при использовании этих методов. В частности, AWQ последовательно приоритизирует компоненты языковой модели (LLM), достигая до 98.6% важности, в то время как GPTQ распределяет важность более равномерно между компонентами, например, для модели BLIP-2 — 50.4% для ViT и 47.6% для LLM.
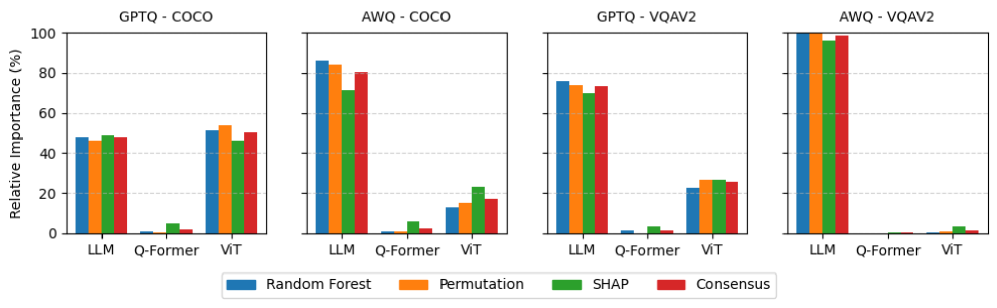
Практическое применение: BLIP-2 и LLaVA используют сжатие
Современные мультимодальные модели, такие как BLIP-2 и LLaVA, наглядно демонстрируют практическую ценность методов сжатия. Эти системы, способные понимать и обрабатывать как визуальную, так и текстовую информацию, становятся значительно более доступными благодаря уменьшению их размера и снижению задержки обработки. Применение техник квантизации позволяет существенно сократить вычислительные ресурсы, необходимые для работы моделей, не жертвуя при этом качеством результатов. Это открывает возможности для развертывания таких систем на мобильных устройствах, встроенных системах и других платформах с ограниченными ресурсами, что делает передовые технологии обработки изображений и текста доступными для более широкого круга пользователей и приложений.
Интеграция квантования в архитектуру современных мультимодальных моделей, таких как BLIP-2 и LLaVA, позволяет добиться значительного уменьшения их размера и задержки обработки данных, при этом сохраняя приемлемый уровень производительности. Этот процесс предполагает снижение точности представления весов нейронной сети, что приводит к уменьшению объема памяти, необходимого для хранения модели, и, как следствие, к ускорению вычислений. Такой подход особенно важен для развертывания сложных моделей на устройствах с ограниченными ресурсами, например, на мобильных телефонах или встроенных системах, открывая возможности для обработки визуальной и текстовой информации в режиме реального времени без существенных потерь в качестве результатов. Квантование, таким образом, является ключевым инструментом для демократизации доступа к передовым технологиям искусственного интеллекта.
Возможность развертывания моделей обработки изображений и текста на устройствах с ограниченными ресурсами открывает новые перспективы для широкого спектра приложений. Благодаря оптимизации и сжатию, сложные алгоритмы, ранее требовавшие мощных серверов, теперь могут функционировать непосредственно на смартфонах, встроенных системах и других портативных устройствах. Это, в свою очередь, обеспечивает обработку визуальной и текстовой информации в режиме реального времени, что критически важно для таких задач, как автоматическое описание изображений для слабовидящих, мгновенный перевод текста с изображений, а также оперативное взаимодействие с визуальным контентом в мобильных приложениях и системах дополненной реальности. Уменьшение задержки и повышение скорости обработки данных существенно улучшают пользовательский опыт и расширяют возможности применения искусственного интеллекта в повседневной жизни.
Для эффективного обучения и оценки многомодальных моделей, таких как BLIP-2 и LLaVA, ключевое значение имеют специализированные наборы данных. Наборы COCO, Flickr, VQAv2 и GQA предоставляют обширные коллекции изображений и соответствующих текстовых описаний, необходимых для развития способностей модели к пониманию и генерации контента. Исследования показывают, что методы квантизации, используемые для сжатия моделей, по-разному влияют на их производительность. В частности, алгоритм GPTQ обычно демонстрирует более стабильные результаты при понижении разрядности, в то время как AWQ может столкнуться с более заметным снижением точности в задачах генерации подписей к изображениям и визуального вопросно-ответного взаимодействия, что подчеркивает важность выбора оптимальной стратегии квантизации для конкретных приложений.
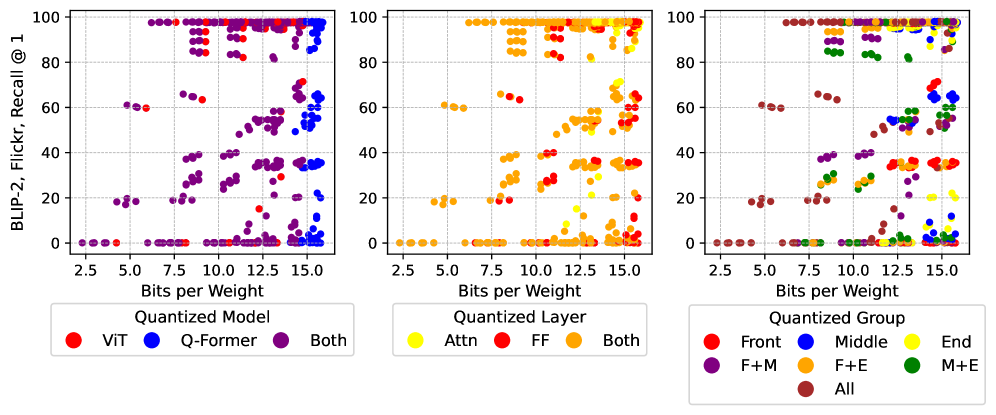
Исследование показывает, что не все компоненты мультимодальных больших языковых моделей одинаково чувствительны к квантованию. Это, конечно, не новость. Каждая «революционная» технология завтра станет техдолгом. Авторы выяснили, что выбор метода квантования и распределение бит-ширины критически важны для сохранения производительности. Как будто кто-то сомневался. Похоже, что даже элегантная теория находит способ сломаться о суровую реальность продакшена. Как метко сказал Дэвид Марр: «Я не могу объяснить, как работает мозг, но я уверен, что он не работает так, как думают нейробиологи». И в данном случае, скорее всего, не существует универсального решения для квантования — каждый случай требует индивидуального подхода и готовности к компромиссам.
Куда же мы катимся?
Исследование показывает, что сжимать большие мультимодальные модели — дело непростое. Оказывается, не все компоненты одинаково болят, и выбор метода квантизации влияет на результат сильнее, чем хотелось бы верить. Но давайте будем честны: каждая «революционная» техника сжатия — это лишь отсрочка неизбежного. Продакшен найдёт способ загнать модель в такие рамки, что даже самые умные алгоритмы квантизации окажутся бессильны. Оптимальное распределение битовой глубины — это, конечно, интересно, но это лишь попытка причесать неизбежный хаос.
В ближайшем будущем, вероятно, мы увидим ещё больше изощренных методов квантизации, ещё более сложные метрики оценки важности компонентов. Но стоит помнить: всё новое — это старое, только с другим именем и теми же багами. Реальная проблема не в сжатии, а в том, что мы постоянно пытаемся запихнуть слишком много интеллекта в слишком мало железа. И рано или поздно, это приведёт к закономерному коллапсу.
Поэтому, вместо того чтобы гоняться за идеальным алгоритмом квантизации, возможно, стоит задуматься о более фундаментальных вопросах: а действительно ли нам нужно столько параметров? Может быть, стоит сосредоточиться на более эффективных архитектурах, а не на том, как их ужать? Но это, конечно, лишь мечты. Продакшен всегда найдёт способ сломать элегантную теорию.
Оригинал статьи: https://arxiv.org/pdf/2601.15287.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-23 00:48