Автор: Денис Аветисян
Новый метод NanoQuant позволяет существенно уменьшить размер больших языковых моделей, открывая возможности для их развертывания на устройствах с ограниченными ресурсами.
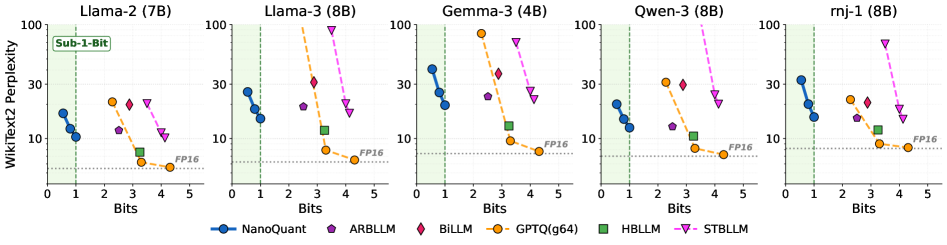
Представлена техника постобработочной квантизации, обеспечивающая сжатие моделей до менее чем 1 бита на параметр без значительной потери производительности.
Квантование весов является стандартным подходом к эффективному обслуживанию больших языковых моделей, однако существующих методов недостаточно для эффективной компрессии до бинарного (1-битного) уровня. В данной работе представлена методика NanoQuant: Efficient Sub-1-Bit Quantization of Large Language Models, новый метод постобработочной квантизации, формулирующий процесс как задачу низкоранховой бинарной факторизации. NanoQuant позволяет достичь компрессии до суб-1-битного уровня без значительной потери производительности, устанавливая новый рубеж в области квантования с низким потреблением памяти. Каковы перспективы дальнейшего снижения вычислительных затрат и повышения эффективности развертывания больших языковых моделей на потребительском оборудовании?
Предел масштабируемости: Большие языковые модели и эффективность
Современные большие языковые модели демонстрируют впечатляющие возможности в обработке и генерации текста, превосходя многие предыдущие подходы в задачах, требующих понимания естественного языка. Однако, эта производительность достигается ценой огромного размера моделей, насчитывающих миллиарды, а в некоторых случаях и триллионы параметров. Такой масштаб влечет за собой значительные вычислительные трудности, поскольку для обучения, хранения и развертывания этих моделей требуются колоссальные ресурсы памяти, вычислительной мощности и энергии. Увеличение числа параметров, хоть и способствует повышению точности и связности генерируемого текста, создает серьезные препятствия для их практического применения на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы, а также усложняет и удорожает процесс обучения и инференса.
Современные большие языковые модели (БЯМ) демонстрируют впечатляющие возможности, однако постоянное увеличение числа параметров, необходимое для улучшения их производительности, сталкивается с серьезными ограничениями в области памяти и энергопотребления. Это противоречие существенно затрудняет широкое внедрение БЯМ, особенно на мобильных устройствах и в системах с ограниченными ресурсами. Несмотря на растущую вычислительную мощность, потребность в хранении и обработке огромных объемов данных, связанных с миллиардами параметров, становится все более сложной задачей. В результате, эффективное развертывание и использование этих мощных инструментов ограничено инфраструктурой, способной справиться с их требованиями к ресурсам, что подчеркивает необходимость разработки инновационных методов сжатия и оптимизации моделей.
В связи с возрастающими требованиями к вычислительным ресурсам, необходимы инновационные методы компрессии больших языковых моделей. Исследования направлены на снижение размера моделей без существенной потери производительности, что позволит развертывать их на более широком спектре оборудования, включая мобильные устройства и периферийные вычисления. Различные подходы, такие как квантизация, прунинг и дистилляция знаний, активно изучаются для достижения этой цели. Успешная компрессия не только снизит затраты на энергию и инфраструктуру, но и откроет новые возможности для применения LLM в областях, где вычислительные ресурсы ограничены, делая передовые технологии искусственного интеллекта более доступными и эффективными.
Квантизация: Ключевая стратегия сжатия моделей
Квантизация является эффективным методом снижения объема памяти и вычислительной сложности нейронных сетей за счет уменьшения разрядности представления весов. Традиционно, веса в нейронных сетях хранятся с использованием 32-битной плавающей точки (float32). Квантизация позволяет представить эти веса, используя меньшее количество бит, например, 8-битную целую точность (int8) или даже меньше. Уменьшение разрядности напрямую снижает объем памяти, необходимый для хранения модели, и ускоряет вычисления, так как операции с целыми числами выполняются быстрее, чем с числами с плавающей точкой. Степень сжатия и ускорения зависит от выбранной разрядности и архитектуры сети, однако даже переход к int8 может обеспечить значительное уменьшение размера модели и повышение производительности.
Квантование, заключающееся в представлении весов нейронной сети с использованием меньшего количества бит, существенно снижает размер модели и ускоряет процесс инференса. Традиционно веса хранятся в формате FP32 (32-битное число с плавающей точкой), однако квантование позволяет перейти к представлениям FP16 (16 бит), INT8 (8 бит) или даже более низким разрядностям. Снижение разрядности напрямую влияет на уменьшение объема памяти, необходимого для хранения модели, а также на сокращение количества операций, требуемых для вычислений во время инференса. Например, переход от FP32 к INT8 приводит к четырехкратному уменьшению размера модели и потенциальному четырехкратному ускорению вычислений, поскольку операции с 8-битными целыми числами выполняются быстрее, чем с 32-битными числами с плавающей точкой. Это особенно важно для развертывания моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы.
Пост-обучающая квантизация (PTQ) представляет собой эффективный метод сжатия моделей, позволяющий снизить их размер и вычислительную сложность без необходимости проведения дорогостоящей повторной тренировки. PTQ использует уже обученные модели и снижает точность представления весов (например, с 32-битной плавающей точки до 8-битного целого числа), что значительно уменьшает объем памяти, необходимый для хранения модели, и ускоряет процесс инференса. Реализация PTQ опирается на специализированные фреймворки, обеспечивающие калибровку квантованных весов и минимизацию потери точности, что позволяет быстро внедрять сжатые модели в производственную среду.
Бинарные сети: Разрушая границы сжатия
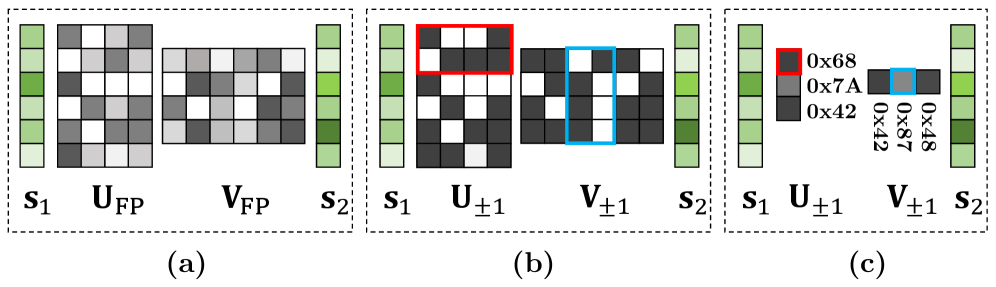
Бинарные нейронные сети используют веса, ограниченные значениями +1 или -1, что позволяет достичь экстремальной степени сжатия модели и повысить вычислительную эффективность. Ограничение весов до двух значений значительно уменьшает объем памяти, необходимый для хранения параметров сети, и снижает сложность вычислений. Это достигается за счет замены операций с плавающей точкой на бинарные операции, которые могут выполняться значительно быстрее на специализированном оборудовании или с использованием оптимизированных библиотек. Такой подход особенно полезен для развертывания моделей глубокого обучения на устройствах с ограниченными ресурсами, таких как мобильные телефоны и встраиваемые системы. Хотя использование бинарных весов может привести к некоторой потере точности, существуют методы, позволяющие смягчить этот эффект и сохранить приемлемый уровень производительности.
Реализация бинарных нейронных сетей требует применения высокооптимизированных матричных операций, таких как Binary GEMM (General Matrix Multiplication) и Binary GEMV (General Matrix-Vector Multiplication), для сохранения производительности. В отличие от стандартных матричных операций с числами с плавающей точкой, Binary GEMM и GEMV оперируют только бинарными значениями (+1 или -1), что значительно снижает вычислительную сложность и потребление памяти. Оптимизация этих операций включает использование битовых операций и специализированных алгоритмов для максимизации пропускной способности и минимизации задержек. Эффективная реализация Binary GEMM и GEMV критически важна для компенсации потери точности, связанной с использованием бинарных весов, и для обеспечения сопоставимой или близкой к ней производительности по сравнению с полноразмерными сетями.
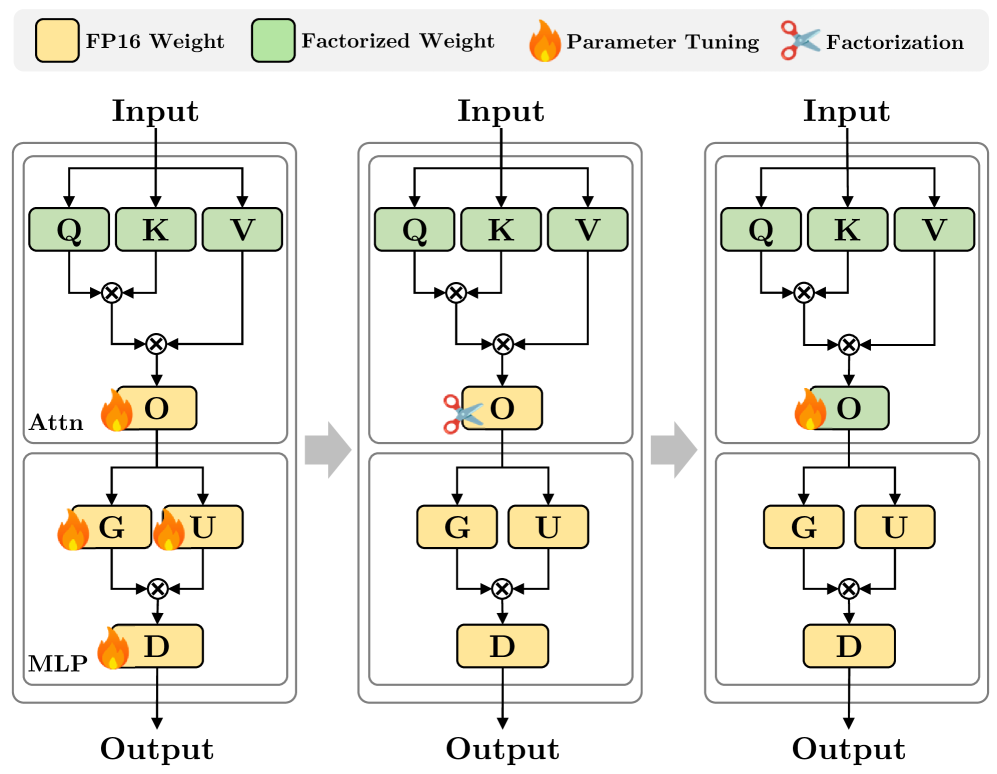
Факторизация на матрицы низкого ранга является методом дальнейшей компрессии в бинарных нейронных сетях, заключающимся в аппроксимации исходных матриц весов их низкоранговыми представлениями. Этот подход позволяет значительно уменьшить количество параметров модели без существенной потери точности, что особенно важно при экстремальной компрессии. Вместо хранения полной матрицы W размера m \times n, факторизация предполагает её представление как произведение двух матриц меньшего размера: W \approx U \cdot V, где U имеет размер m \times k, а V — k \times n, причём k < min(m, n). Эффективность данного метода обусловлена тем, что многие матрицы, используемые в нейронных сетях, обладают внутренней избыточностью и могут быть адекватно представлены с использованием значительно меньшего числа параметров.
NanoQuant: Прорыв в квантовании менее чем в 1 бит
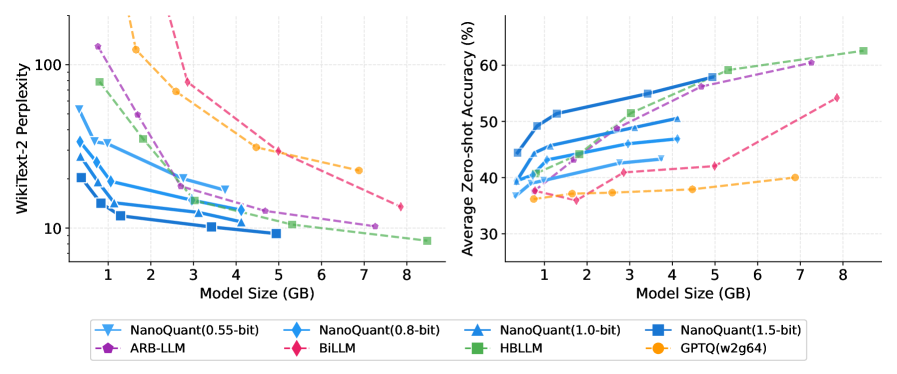
Метод NanoQuant представляет собой эффективный алгоритм пост-обучающей квантизации, предназначенный для сжатия больших языковых моделей (LLM) до уровня ниже 1 бита на параметр. В отличие от традиционных методов квантизации, NanoQuant позволяет добиться значительно более высокой степени сжатия без существенной потери производительности. Это достигается за счет оптимизации процесса квантизации и использования передовых техник, позволяющих минимизировать информационные потери при представлении весов модели в низкобитном формате. В результате, NanoQuant позволяет существенно уменьшить размер модели, снизить требования к вычислительным ресурсам и ускорить процесс инференса.
Метод NanoQuant минимизирует потерю информации при квантовании за счет использования двух ключевых техник: иерархической реконструкции и выравнивания активаций. Иерархическая реконструкция позволяет восстанавливать информацию, утраченную в процессе квантования, путем последовательного приближения к исходным значениям весов модели на разных уровнях детализации. Выравнивание активаций, в свою очередь, нормализует распределение активаций, что улучшает точность представления данных в квантованном формате и снижает влияние ошибок округления. Комбинация этих подходов позволяет добиться значительного сжатия модели при минимальных потерях в производительности и точности.
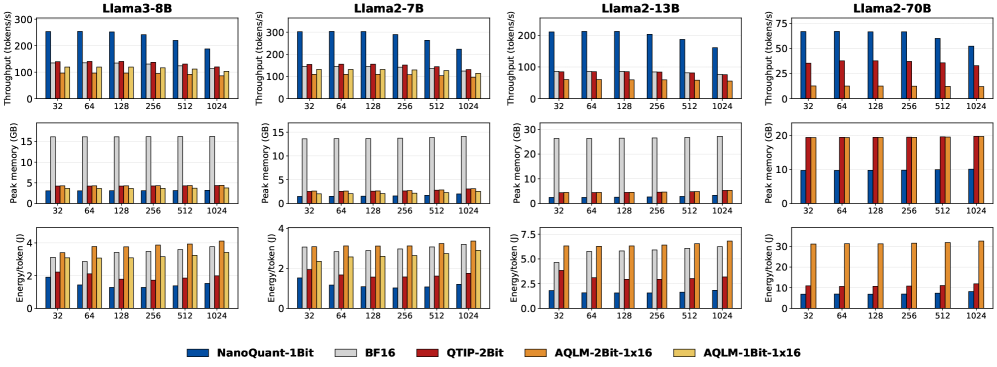
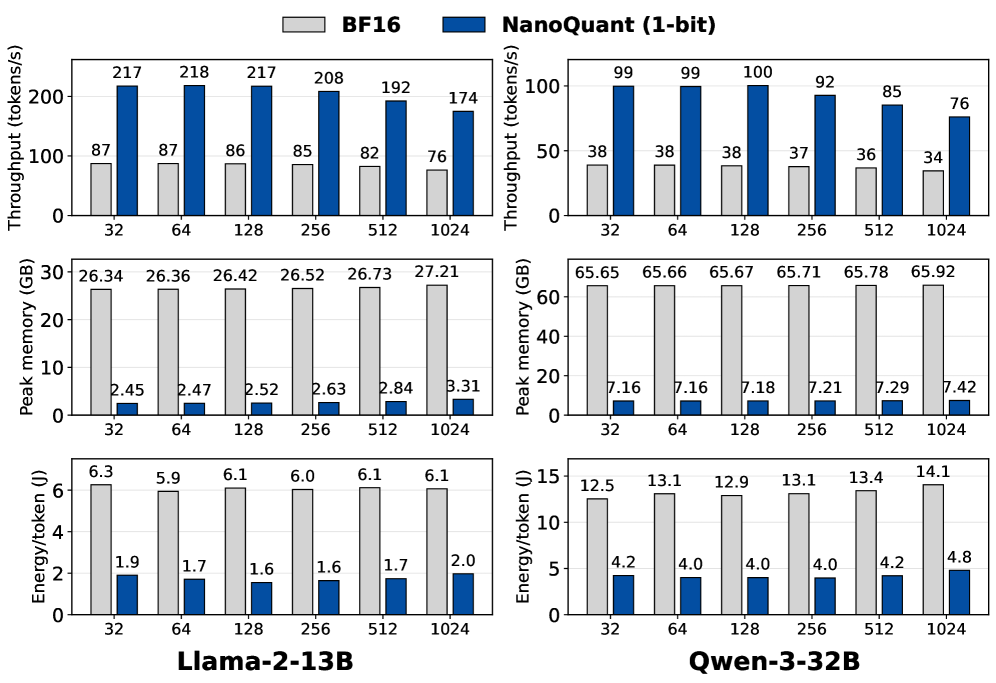
Успех NanoQuant в достижении экстремальной компрессии обусловлен применением передовых алгоритмов оптимизации и инициализации. В частности, используется алгоритм ADMM (Alternating Direction Method of Multipliers) для эффективного решения задач оптимизации, возникающих при квантовании. Для минимизации потерь информации при переходе к низкобитным представлениям применяется стратегия инициализации Hessian-Aware Initialization, учитывающая кривизну функции потерь. В результате, 70-миллиардный параметр модели удалось сжать до 5.35 ГБ, что является значительным уменьшением по сравнению с исходным размером в 138.04 ГБ.
Метод NanoQuant позволяет достичь сжатия больших языковых моделей (LLM) до менее чем 1 бита на параметр (BPW), что значительно превосходит возможности традиционных методов квантизации. На потребительском оборудовании с 8 ГБ видеопамяти, NanoQuant обеспечивает впечатляющую скорость декодирования — до 20.11 токенов в секунду. Данная производительность достигается за счет экстремального сжатия модели без существенной потери качества, что позволяет развертывать LLM на устройствах с ограниченными ресурсами.
К интеллекту на периферии: Будущее сжатых моделей
Возможность эффективного запуска больших языковых моделей непосредственно на периферийных устройствах — так называемый On-Device Inference — открывает принципиально новые перспективы для персонализированного и конфиденциального искусственного интеллекта. Вместо отправки данных на удаленные серверы для обработки, вся логика теперь может быть реализована локально, на смартфоне, носимом устройстве или встроенной системе. Это не только значительно снижает задержку и энергопотребление, но и обеспечивает повышенную защиту персональных данных, поскольку информация не покидает пределы устройства. Такой подход позволяет создавать интеллектуальные системы, адаптирующиеся к индивидуальным потребностям пользователя в реальном времени, без риска компрометации конфиденциальности, что особенно важно в чувствительных областях, таких как здравоохранение или финансы.
Современные модели искусственного интеллекта, особенно большие языковые модели, предъявляют значительные требования к объему памяти и энергопотреблению. Технологии сжатия моделей, такие как NanoQuant, позволяют преодолеть эти ограничения, значительно уменьшая размер и сложность моделей без существенной потери точности. Это достигается за счет использования квантования и других методов оптимизации, позволяющих эффективно представлять параметры модели с меньшей разрядностью. В результате, становится возможным развертывание сложных алгоритмов машинного обучения непосредственно на мобильных устройствах, встроенных системах и других периферийных устройствах, где ресурсы ограничены. Такой подход открывает новые возможности для реализации интеллектуальных приложений, работающих в режиме реального времени и не требующих подключения к облачным серверам, что повышает конфиденциальность данных и снижает задержки.
Переход к более компактным и эффективным моделям искусственного интеллекта, способным функционировать непосредственно на устройствах, таких как смартфоны и встроенные системы, знаменует собой новую эру повсеместного внедрения ИИ. Этот сдвиг парадигмы позволит значительно расширить сферу применения технологий искусственного интеллекта, от персональных помощников и интеллектуальных гаджетов до автоматизированных систем управления и мониторинга в промышленности и медицине. Возможность обработки данных непосредственно на устройстве, без необходимости передачи в облако, не только повышает скорость и отзывчивость приложений, но и обеспечивает повышенную конфиденциальность и безопасность данных пользователя, открывая путь к созданию более интеллектуального и взаимосвязанного мира, где технологии искусственного интеллекта органично интегрированы в повседневную жизнь.
Исследование демонстрирует, что сжатие больших языковых моделей до суб-1-битной точности возможно без существенной потери производительности. Этот подход, реализованный в NanoQuant, подобен взлому системы, когда, понимая её структуру, можно найти способы оптимизации и сжатия, сохраняя при этом функциональность. Андрей Колмогоров однажды сказал: «Математика — это искусство находить закономерности в хаосе». Данная работа, применяя методы низкоранховой факторизации и квантизации, подтверждает эту мысль, находя закономерности в параметрах моделей, что позволяет значительно сократить их размер и сложность, открывая возможности для развертывания на устройствах с ограниченными ресурсами. По сути, NanoQuant — это реверс-инжиниринг модели для достижения максимальной эффективности.
Куда дальше?
Представленная работа, демонстрируя сжатие больших языковых моделей до суб-1-битного представления, ставит интересный вопрос: насколько далеко можно зайти в редукции, прежде чем потеряется не просто производительность, а сама суть “интеллекта”? Каждый эксплойт начинается с вопроса, а не с намерения. NanoQuant, безусловно, открывает двери для развертывания моделей на крайне ограниченных ресурсах, но истинный вызов — не в миниатюризации, а в сохранении способности к обобщению и адаптации. Очевидно, что существующие методы оценки качества моделей не всегда отражают их реальную способность к решению нетривиальных задач в условиях экстремальной компрессии.
Будущие исследования, вероятно, сосредоточатся на разработке новых метрик, учитывающих не только точность, но и устойчивость к шуму, а также способность к обучению «на лету» с минимальным объемом данных. Интересным направлением представляется поиск компромисса между степенью квантования и архитектурой сети — возможно, существуют принципиально новые структуры, более устойчивые к экстремальной компрессии. Нельзя исключать и появление методов, использующих принципы нечёткой логики или других неклассических подходов к представлению информации.
В конечном счете, NanoQuant — это не просто техническое решение, а приглашение к переосмыслению фундаментальных принципов машинного обучения. Реализация подобного сжатия накладывает ограничения, которые вынуждают искать элегантные, эффективные алгоритмы, и, возможно, даже пересмотреть само понятие «интеллект» в контексте искусственных систем.
Оригинал статьи: https://arxiv.org/pdf/2602.06694.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Язык тела под присмотром ИИ: архитектура и гарантии
- Генерация без рисков: как избежать нарушения авторских прав при работе с языковыми моделями
- Искусственный интеллект на службе редких болезней
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Генетическая приоритизация: новый взгляд на отбор генов
- Квантовый Переворот: От Теории к Реальности
- Плоские зоны: от теории к новым материалам
- Творческий процесс под микроскопом: от логов к искусственному интеллекту
2026-02-09 21:52