Автор: Денис Аветисян
Новый подход позволяет табличным моделям машинного обучения эффективно обрабатывать новые признаки на этапе инференса, повышая их гибкость и точность.
Представлен метод TabII, использующий теорию информационного узкого места и контрастивное обучение для адаптации табличных моделей к новым столбцам данных.
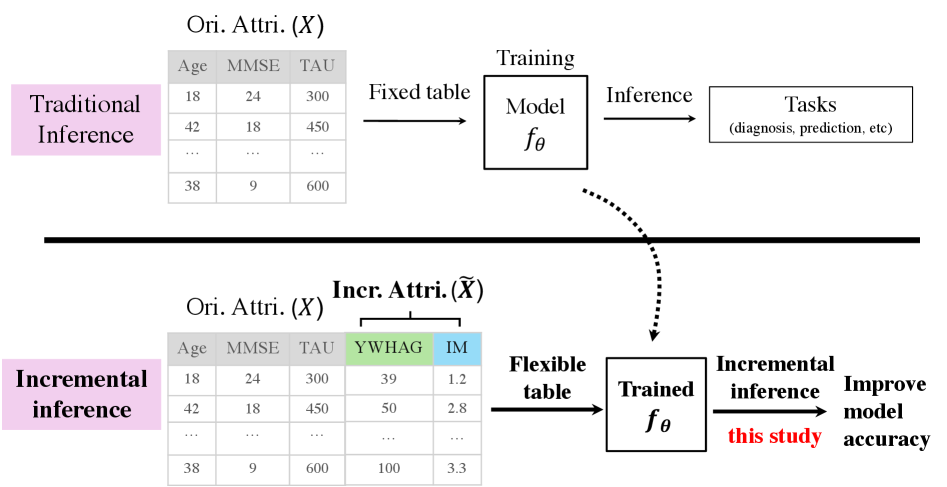
Традиционные подходы к анализу табличных данных не адаптируются к динамически изменяющимся схемам, что ограничивает их применимость в реальных сценариях. В данной работе представлена задача и метод ‘Tabular Incremental Inference’ (TabII), направленные на адаптацию обученных моделей к новым столбцам непосредственно на этапе инференса. TabII, основанный на теории информационного «узкого горлышка» и использующий большие языковые модели и блоки инкрементальной конденсации выборок, позволяет эффективно использовать информацию из новых атрибутов. Способны ли подобные методы открыть новые горизонты в анализе табличных данных и обеспечить более гибкое и адаптивное машинное обучение?
Затянувшаяся агония табличных данных
Традиционные модели машинного обучения, работающие с табличными данными, зачастую испытывают трудности при добавлении новых признаков после завершения обучения, что существенно ограничивает их приспособляемость к изменяющимся условиям. Существующие алгоритмы, как правило, требуют полной переподготовки модели при изменении схемы данных, что является ресурсоемким и непрактичным в динамичных реальных сценариях. Данная неспособность эффективно интегрировать новую информацию без значительной потери ранее полученных знаний, известной как «катастрофическое забывание», делает их менее эффективными в задачах, где структура данных постоянно эволюционирует. В результате, модели, обученные на фиксированном наборе признаков, могут демонстрировать значительное снижение производительности при появлении новых, ранее не встречавшихся параметров, что подчеркивает необходимость разработки более гибких и адаптивных методов обучения.
Неспособность традиционных моделей машинного обучения к адаптации к изменяющимся схемам данных существенно снижает их эффективность в реальных динамических средах. В практических задачах, таких как финансовый анализ, медицинская диагностика или мониторинг сетевой активности, структура данных редко остается неизменной. Появление новых атрибутов, отражающих изменяющиеся условия или доступ к дополнительной информации, требует от моделей способности интегрировать эти изменения без потери ранее приобретенных знаний. В противном случае, модель, обученная на устаревшей схеме данных, может выдавать неточные или нерелевантные прогнозы, что приводит к значительным ошибкам и потерям. Таким образом, гибкость в обработке эволюционирующих табличных данных становится критически важным фактором для успешного применения машинного обучения в постоянно меняющемся мире.
Основная сложность адаптации моделей машинного обучения к изменяющимся табличным данным заключается в эффективной интеграции новой информации без возникновения так называемого “катастрофического забывания” или необходимости полной переобучения модели с нуля. Когда схема данных расширяется, добавляются новые признаки, традиционные алгоритмы склонны терять знания, полученные на основе исходных данных, что приводит к резкому снижению производительности. Для решения этой проблемы необходимы методы, позволяющие модели одновременно сохранять ранее полученные знания и эффективно адаптироваться к новым данным, не требуя при этом огромных вычислительных ресурсов или повторного обучения с использованием всего объема данных. Успешное преодоление этой проблемы открывает возможности для создания более гибких и устойчивых моделей, способных функционировать в динамично меняющихся реальных условиях.
Постепенное (инкрементальное) выведение умозаключений для табличных данных представляет собой перспективное решение проблемы адаптации моделей к изменяющимся схемам данных. Однако, эффективность этого подхода напрямую зависит от способности методов к балансировке между сохранением уже полученных знаний и успешной интеграцией новой информации. Необходим тщательный подбор алгоритмов, способных избегать «катастрофического забывания» — потери ранее усвоенных паттернов при обучении на новых данных. Успешная реализация требует разработки механизмов, которые позволят модели эффективно расширять свои знания, не жертвуя при этом точностью и обобщающей способностью, достигнутыми на предыдущих этапах обучения. Именно поэтому, исследования в области инкрементального вывода умозаключений сфокусированы на разработке стратегий, обеспечивающих оптимальное соотношение между удержанием накопленного опыта и способностью к адаптации к меняющимся условиям.
TabII: Внедрение знаний для эволюционирующих таблиц
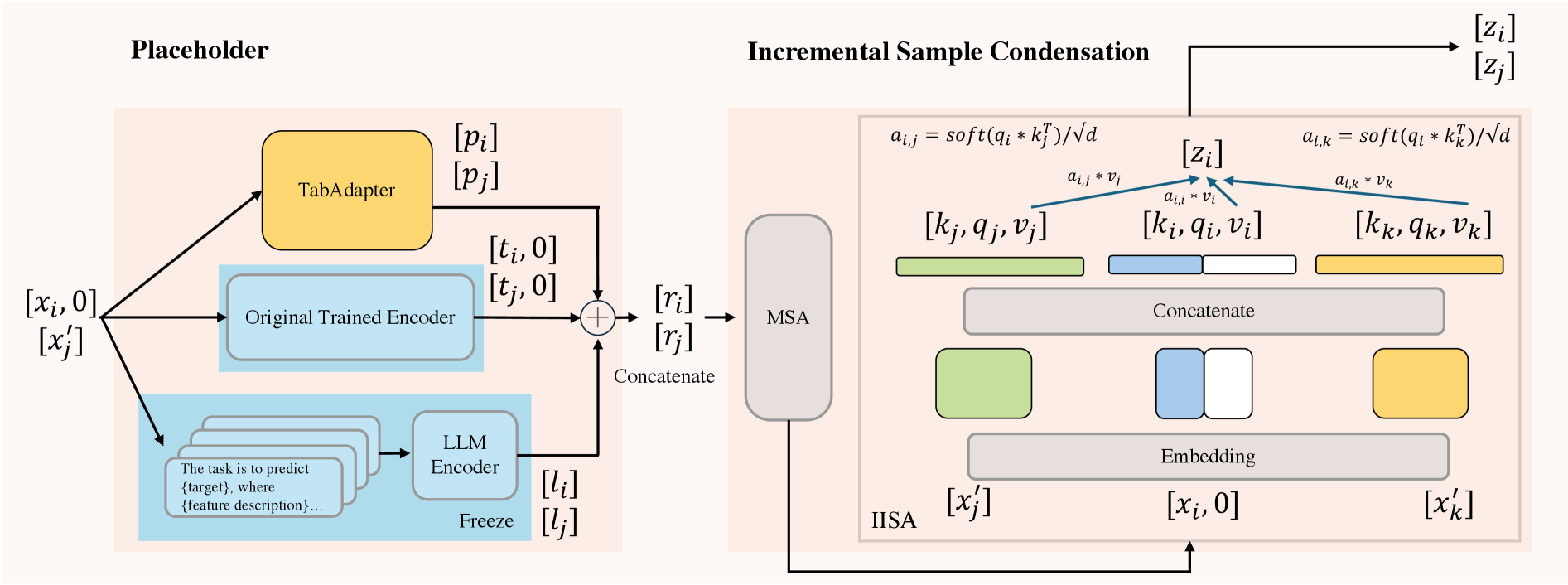
Метод TabII представляет новый подход к инкрементному выводу на табличных данных, основанный на использовании “Плейсхолдеров” для внедрения внешних знаний. Эти плейсхолдеры функционируют как точки входа для информации, полученной из больших языковых моделей (LLM) и табличных фундаментальных моделей (TFM). Внедрение знаний осуществляется путем добавления новых атрибутов или модификации существующих, что позволяет модели адаптироваться к меняющимся данным без необходимости переобучения с нуля. В частности, плейсхолдеры позволяют обогатить данные дополнительным контекстом, который может быть недоступен в исходном наборе данных, повышая тем самым точность и надежность инкрементного вывода.
В TabII, для обогащения информации об атрибутах используются “Плейсхолдеры”, которые объединяют возможности больших языковых моделей (LLM) и табличных фундаментальных моделей (TFM). LLM применяются для извлечения семантических знаний из текстовых описаний атрибутов, что позволяет учитывать контекст и взаимосвязи. Параллельно, TFM используются для анализа статистических характеристик атрибутов и выявления закономерностей в табличных данных. Комбинирование этих подходов обеспечивает более полное и точное представление информации об атрибутах, что улучшает качество инференса в условиях инкрементального обучения.
Основным компонентом TabII является блок ‘Incremental Sample Condensation’ (ISC), реализующий механизм сжатия выборочных данных. ISC использует многоголовое самовнимание (multi-head self-attention) для объединения представлений признаков. Этот процесс позволяет модели эффективно учитывать взаимосвязи между признаками и создавать компактные, информативные представления, что критически важно для инкрементального обучения. Многоголовое самовнимание позволяет параллельно анализировать данные с разных точек зрения, повышая способность модели к обобщению и адаптации к новым данным без потери производительности на существующих данных. В ISC, выходные данные каждого блока самовнимания объединяются для формирования окончательного представления, которое затем используется для дальнейшей обработки.
Архитектура TabII обеспечивает эффективное обучение на основе добавляемых атрибутов, не ухудшая при этом производительность на существующих данных. Это достигается за счет использования механизма ‘Incremental Sample Condensation’ (ISC), который применяет многоголовое самовнимание для слияния представлений новых и ранее существующих данных. В отличие от традиционных подходов, требующих переобучения модели при добавлении новых атрибутов, TabII адаптируется к изменениям инкрементально, минимизируя риск «катастрофического забывания» и поддерживая высокую точность предсказаний на всем наборе данных. Данная особенность позволяет использовать TabII в динамических средах, где структура данных постоянно меняется.
Подтверждение эффективности: Бенчмарки и сравнения
Для оценки обобщающей способности модели TabII проводилось тестирование на восьми общедоступных наборах данных, включая широко используемые ‘Diabetes Dataset’ и ‘Adult Dataset’. Использование разнообразных датасетов позволило подтвердить устойчивость модели к различным типам данных и задачам, демонстрируя её способность эффективно работать с незнакомыми данными без существенной потери производительности. Результаты тестирования на этих наборах данных являются важным подтверждением эффективности архитектуры TabII и её потенциала для применения в широком спектре практических задач.
Сравнительный анализ производительности TabII с существующими методами, включая FT-Trans, SCARF и TabPFN v2, демонстрирует его превосходство на ряде бенчмарков. В ходе экспериментов TabII последовательно превосходит эти альтернативные подходы по ключевым метрикам точности и эффективности, что подтверждается результатами, полученными на различных наборах данных. Данные сравнения показывают, что TabII обеспечивает более высокую производительность при решении задач табличных данных, чем рассматриваемые методы, что указывает на его преимущества в контексте обработки и анализа структурированной информации.
Для подтверждения эффективности внедрения знаний посредством Placeholders, проводилась оценка важности атрибутов с использованием алгоритма XGBoost. Анализ показал, что атрибуты, связанные с Placeholders, демонстрируют высокую значимость в процессе прогнозирования, что свидетельствует о том, что внедренные знания успешно используются моделью для улучшения её производительности. Высокая важность этих атрибутов подтверждает, что Placeholders не являются просто шумом, а предоставляют ценную информацию, способствующую более точному моделированию данных и повышению общей эффективности модели TabII.
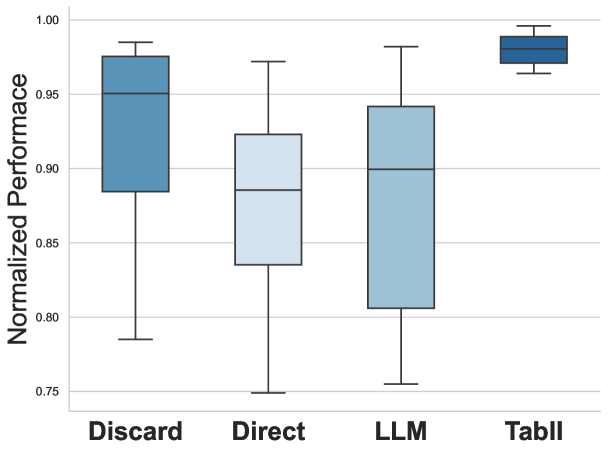
В ходе тестирования было установлено, что TabII демонстрирует производительность, составляющую 97% от показателей модели, обученной на полностью размеченных данных с добавлением инкрементальных атрибутов. Данный результат подтверждает, что TabII достигает передовых показателей в задачах табличного обучения, эффективно используя информацию из частично размеченных данных и приближаясь по эффективности к моделям, обученным на полном объеме размеченных данных. Это свидетельствует о высокой эффективности подхода, используемого в TabII, для извлечения полезной информации из неполных данных и адаптации к новым признакам.
В условиях неконтролируемого обучения, TabII демонстрирует производительность, достигающую 95.8% от уровня, достигаемого при использовании полностью контролируемого обучения на трех стандартных наборах данных. Это подтверждает высокую адаптивность модели и её способность эффективно извлекать информацию и делать точные прогнозы, используя только немаркированные данные для тестирования, что свидетельствует о её потенциале в сценариях с ограниченными или отсутствующими маркированными данными.
Способность TabII эффективно работать в сценариях “обучения без учителя” (Zero-Shot Learning) демонстрирует высокую адаптивность модели и минимальную потребность в переобучении. В данных сценариях TabII успешно применяет полученные знания к новым, ранее не встречавшимся данным, не требуя дополнительной настройки или модификации. Это достигается благодаря архитектуре модели, позволяющей ей обобщать информацию и экстраполировать её на новые задачи без необходимости в примерах, размеченных для конкретной целевой задачи. Данная особенность делает TabII особенно ценным инструментом в ситуациях, когда получение размеченных данных затруднено или невозможно.
Теоретические основы и перспективы развития
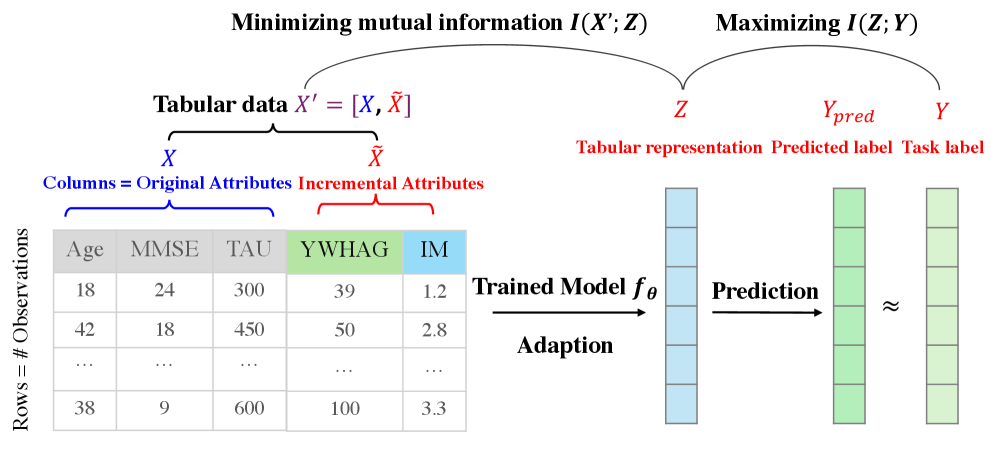
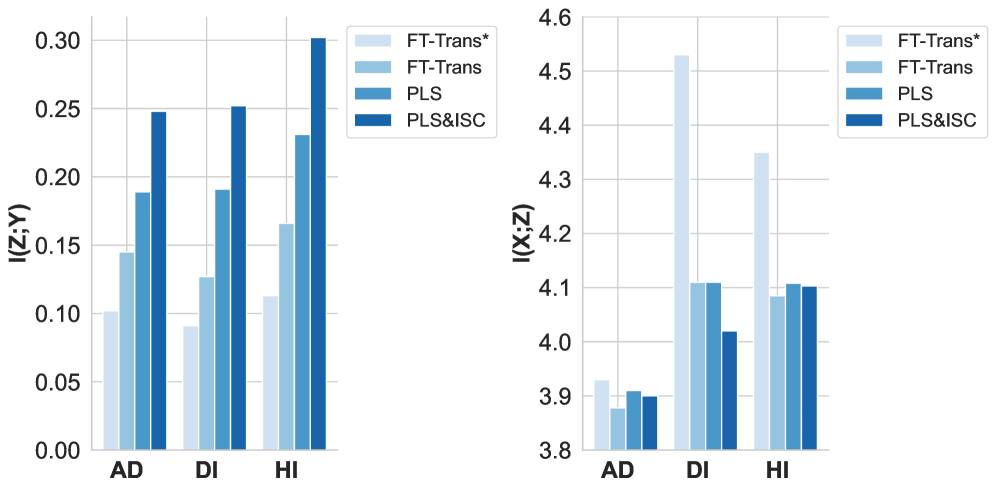
Архитектура TabII разработана в соответствии с принципами теории «информационного узкого места», стремясь к оптимальному балансу между сжатием данных и сохранением релевантной информации. Данный подход позволяет модели эффективно уменьшать размер входных данных, выделяя наиболее значимые признаки, необходимые для точного прогнозирования. В основе лежит идея о том, что идеальное представление данных должно быть как можно более компактным, но при этом достаточно информативным для решения поставленной задачи. В результате, TabII демонстрирует способность к эффективному обобщению, даже при работе с ограниченными объемами данных, благодаря акценту на извлечение ключевых закономерностей и отбрасыванию избыточной информации. I(Z;Y) — показатель взаимной информации между сжатым представлением Z и целевой переменной Y, максимизируется, а I(X;Z) — между исходными данными X и представлением Z — минимизируется, что свидетельствует об эффективном сжатии и сохранении значимой информации.
Принцип упругой консолидации весов играет ключевую роль в обеспечении стабильности модели TabII при инкрементальном обучении. Данный подход позволяет избежать катастрофического забывания, характерного для нейронных сетей, когда освоение новых данных приводит к потере знаний, полученных ранее. Метод заключается в определении важности каждого веса в сети и применении регуляризации, препятствующей значительному изменению наиболее значимых весов при обучении на новых данных. Таким образом, модель способна адаптироваться к новым задачам, сохраняя при этом знания, полученные на предыдущих этапах, что критически важно для непрерывного обучения и эффективной работы с динамически меняющимися данными.
Интеграция внешних знаний посредством плейсхолдеров представляет собой эффективный подход к преодолению проблемы нехватки данных и повышению устойчивости модели. Данная методика позволяет TabII использовать предварительно заданную информацию, компенсируя недостаток обучающих примеров и обогащая представление о данных. Плейсхолдеры выступают в роли своеобразных “якорей”, направляющих процесс обучения и позволяющих модели обобщать знания даже при ограниченном объеме данных. Такой подход особенно важен при работе с табличными данными, где зачастую сложно получить достаточное количество размеченных примеров для каждой комбинации признаков. В результате, использование плейсхолдеров способствует не только повышению точности модели, но и её способности адаптироваться к новым, ранее не встречавшимся данным, что делает TabII более надежным и универсальным решением.
Исследования показали, что модель TabII демонстрирует наивысшее значение взаимной информации I(Z;Y) на всех протестированных наборах данных. Это свидетельствует об эффективном использовании дополнительных столбцов для повышения способности модели улавливать и сохранять релевантную информацию. Взаимная информация, по сути, измеряет, насколько хорошо сжатое представление данных Z предсказывает целевую переменную Y. Более высокое значение I(Z;Y) указывает на то, что TabII успешно извлекает наиболее важные признаки из данных, обеспечивая высокую точность прогнозирования даже при работе с неполными или зашумленными данными. Таким образом, данная особенность подчеркивает способность модели эффективно конденсировать информацию и представлять ее в компактной и полезной форме.
Исследования показали, что модель TabII демонстрирует превосходство в фильтрации нерелевантной информации по сравнению с FT-Trans, что подтверждается более низким значением взаимной информации I(X;Z). Данный показатель свидетельствует о способности TabII эффективно конденсировать данные, отбрасывая несущественные признаки и фокусируясь на наиболее значимых для решения поставленной задачи. В отличие от FT-Trans, которая сохраняет больше исходной информации, TabII создает более компактное и информативное представление, что способствует повышению устойчивости и обобщающей способности модели, особенно при работе с зашумленными или неполными данными. Такая способность к конденсации данных является ключевым фактором, определяющим эффективность TabII в задачах инкрементального обучения и анализа табличных данных.
Дальнейшие исследования TabII сосредоточены на разработке инновационных стратегий внедрения знаний, направленных на повышение эффективности модели в условиях ограниченных данных и сложных взаимосвязей в табличных наборах. Планируется изучение различных подходов к интеграции внешних знаний, выходящих за рамки текущих Placeholders, с целью оптимизации процесса обучения и улучшения обобщающей способности. Особое внимание будет уделено расширению возможностей TabII для работы с более сложными табличными данными, характеризующимися большим количеством столбцов, нелинейными зависимостями и разнородными типами признаков. Исследователи стремятся к созданию системы, способной эффективно извлекать и использовать релевантную информацию из внешних источников, обеспечивая устойчивость и надежность модели в различных сценариях применения.
В очередной раз наблюдается стремление к оптимизации, к сжатию информации, чтобы уместить новые данные в старые модели. Авторы предлагают TabII, основанный на теории информационного горлышка, что, в принципе, логично — всегда нужно найти самое узкое место, чтобы все пропустить. Но, как показывает опыт, любое “улучшение” рано или поздно превращается в технический долг. Вот и здесь: добавление новых колонок во время инференса — это, конечно, удобно, но кто-нибудь подумал о документации? И о тех багах, которые обязательно вылезут, когда это всё попадет в продакшен? Как остроумно заметила Ада Лавлейс: «То, что мы сейчас называем искусственным интеллектом, является лишь отражением нашего собственного интеллекта». Иными словами, все эти алгоритмы — лишь зеркало наших проблем, которые мы потом и будем решать.
Что дальше?
Представленный подход, безусловно, элегантен. Сжать информацию, сохранить главное — звучит как мечта любого разработчика, столкнувшегося с вечным ростом размерности данных. Однако, стоит помнить: каждая «оптимизация» — это лишь отложенный технический долг. Вполне вероятно, что новые столбцы, добавленные «на лету», в конечном итоге обнаружатся источником скрытых смещений, которые проявятся в самый неподходящий момент. Тесты, конечно, покажут отсутствие проблем… до первого понедельника.
Настоящим вызовом, вероятно, станет масштабирование. Теория информации прекрасна в уравнениях, но практика подсказывает, что вычисление взаимной информации для действительно больших таблиц — задача нетривиальная. Автоматизация, возможно, и поможет, но уже виден сценарий, в котором скрипт, оптимизирующий сжатие, случайно удаляет все данные.
Будущие исследования, скорее всего, будут направлены на повышение устойчивости к «шуму» в новых столбцах, а также на разработку методов оценки «ценности» информации, чтобы не тратить ресурсы на сжатие очевидно бесполезных данных. В конце концов, идеальное решение — это не то, которое максимально сжимает информацию, а то, которое достаточно надёжно работает, даже когда что-то пойдёт не так.
Оригинал статьи: https://arxiv.org/pdf/2601.15751.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-25 04:39