Автор: Денис Аветисян
Новое исследование выявляет пробелы в способности современных моделей машинного обучения к экстраполяции и точным вычислениям на табличных данных.
Представлен TabularMath — бенчмарк для оценки вычислительных способностей моделей табличного обучения и их способности к экстраполяции, основанный на синтетических данных и верификации программным кодом.
В то время как стандартные бенчмарки для табличных данных фокусируются на интерполяции, многие реальные задачи, такие как финансовое моделирование, требуют экстраполяции на основе детерминированных вычислений. В работе ‘TabularMath: Evaluating Computational Extrapolation in Tabular Learning via Program-Verified Synthesis’ предложен новый диагностический набор данных TabularMath, состоящий из 114 задач, сгенерированных на основе верифицированных программ, для оценки способности табличных моделей к вычислительному обобщению. Исследование выявило разрыв между метриками регрессии (R^2) и точностью точного совпадения, указывающий на то, что модели хорошо аппроксимируют функции, но испытывают трудности с точным воспроизведением вычислительных результатов. Возможно ли разработать архитектуры, которые бы эффективно объединяли преимущества масштабируемости табличных моделей и точности вычислений, демонстрируемой обучением на нескольких примерах?
Неизбежность Старения Вычислений: Вызов Детерминированной Точности
Несмотря на значительный прогресс в области машинного обучения, достижение надежной обобщающей способности при работе с табличными данными остается сложной задачей, особенно когда речь идет о детерминированных вычислениях. Современные алгоритмы часто демонстрируют высокую точность при обучении, однако их способность к корректному предсказанию на новых, ранее не встречавшихся данных, существенно снижается. Это проявляется в том, что модели успешно интерполируют значения, но не способны воспроизводить точные, известные результаты для заданных входных параметров. Таким образом, существующие подходы демонстрируют скорее способность к запоминанию и экстраполяции, чем к истинному пониманию закономерностей, лежащих в основе детерминированных процессов, что ограничивает их применимость в критически важных областях, где требуется абсолютная точность и надежность.
Традиционные методы машинного обучения, стремясь к высокой корреляции между предсказанными и фактическими значениями, часто достигают показателя R², близкого к 1.0. Однако, несмотря на эту статистическую точность, модели демонстрируют удивительно низкую способность к воспроизведению точных совпадений, особенно при работе с данными, отличающимися от тех, на которых они обучались. Исследования показывают, что точность точных совпадений на таких “незнакомых” данных не превышает 62%. Этот разрыв между высокой корреляцией и низкой точностью указывает на то, что модели, возможно, не столько “понимают” закономерности в данных, сколько просто интерполируют значения, не обладая способностью к систематическому и надежному вычислению.
Несоответствие между высокой статистической точностью и фактической способностью воспроизводить известные результаты подчеркивает потребность в моделях, демонстрирующих систематические вычисления, а не просто интерполяцию данных. Достижение высокой точности, измеряемой, например, коэффициентом детерминации R^2, не гарантирует, что модель действительно “понимает” взаимосвязи и способна надежно генерировать ожидаемые выходные значения для заданных входных данных. Вместо запоминания шаблонов и аппроксимации, необходимы алгоритмы, которые способны логически выводить результаты, подобно тому, как это делает детерминированное вычисление. Это требует от моделей не просто предсказывать, но и обосновывать свои ответы, что особенно важно при работе с табличными данными, где требуется абсолютная точность и воспроизводимость.

Оценка За Пределами Регрессии: Фокус на Точность
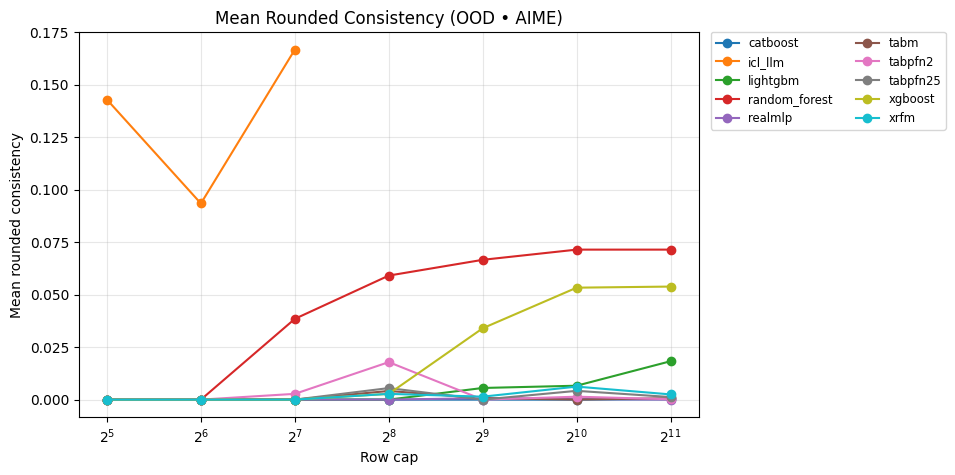
Критически важной метрикой оценки детерминированных вычислений является «Округленная Согласованность» (Rounded Consistency) — способность модели выдавать корректные целочисленные результаты после округления предсказанных значений. Данная метрика оценивает, насколько точно модель воспроизводит дискретные, целочисленные ответы, необходимые во многих задачах, требующих точного соответствия, а не только приблизительного регрессионного соответствия. Высокая округленная согласованность подразумевает, что даже при незначительных погрешностях предсказания, округление до ближайшего целого числа приводит к верному ответу, что особенно важно для задач, где целочисленные значения имеют принципиальное значение.
Модель TabPFN v2.5 демонстрирует высокую производительность в задачах регрессии, достигая значения R^2 \approx 1.0. Однако, на датасете GSM8K-Random при обработке 2048 строк, наблюдается значительный разрыв между показателем R^2 и метрикой “Округленная Согласованность” (Rounded Consistency), которая составляет всего 62%. Это указывает на то, что модель, несмотря на способность точно предсказывать непрерывные значения, не способна уловить детерминированные зависимости, необходимые для получения корректных целочисленных результатов после округления.
Наблюдаемое расхождение между высокой производительностью моделей в задачах регрессии (например, R^2 \approx 1.0) и низкой точностью точного совпадения (exact-match accuracy) стимулирует разработку новых методов, сочетающих в себе сильные регрессионные возможности и способность к выдаче корректных целочисленных результатов после округления. Такие методы необходимы для задач, где важна не только общая близость предсказаний, но и их абсолютная точность, особенно в контексте детерминированных вычислений. Акцент делается на создание моделей, способных воспроизводить правильные ответы без необходимости сложной постобработки или корректировки предсказаний.
Обобщение и Производительность на Неизвестных Данных
Оценка моделей на данных, отличных от обучающей выборки (out-of-distribution, OOD), является критически важной для определения их реальной способности к обобщению. Традиционная оценка на тестовых данных, полученных из того же распределения, что и обучающие, может давать завышенные результаты и не отражать производительность в реальных условиях, где входные данные могут существенно отличаться. Использование OOD-данных позволяет выявить слабые места модели и оценить её устойчивость к изменениям в данных, что необходимо для обеспечения надежной работы в различных сценариях и на новых, ранее не встречавшихся данных. Отсутствие оценки на OOD-данных может привести к ошибочному выводу о высокой производительности модели, что чревато ошибками при ее развертывании в реальных приложениях.
Методы обучения с использованием контекста (In-Context Learning, ICL) представляют собой перспективную альтернативу традиционным методам обучения, демонстрируя повышенную устойчивость к изменениям в данных и высокую эффективность при использовании ограниченного количества примеров. В отличие от традиционного обучения, требующего обновления весов модели на основе большого набора данных, ICL позволяет модели выполнять задачи, опираясь на предоставленный контекст в виде нескольких примеров, без изменения ее параметров. Это обеспечивает возможность быстрого адаптации к новым задачам и данным, а также снижает потребность в вычислительных ресурсах, необходимых для переобучения модели. Эффективность ICL обусловлена способностью модели использовать предоставленный контекст для выявления закономерностей и обобщения знаний, что позволяет достигать конкурентоспособных результатов даже при ограниченном количестве обучающих данных.
Несмотря на эффективность метода обучения с подсказками (In-Context Learning, ICL), его точность, измеряемая метрикой Rounded Consistency, составляет приблизительно 40% при оценке на данных, отличных от обучающей выборки (out-of-distribution). Это указывает на необходимость проведения тщательного тестирования моделей на разнообразных наборах данных, таких как GSM8K и AIME, и одновременного использования метрики Rounded Consistency для обеспечения надежной производительности и выявления потенциальных проблем с обобщающей способностью модели в реальных условиях.
Ландшафт Табличных Моделей: Разнообразие Подходов
В настоящее время для анализа табличных данных активно исследуется широкий спектр методов, включающий в себя такие алгоритмы, как XGBoost, CatBoost, LightGBM, Random Forest, а также более новые подходы — TabM, RealMLP-TD-S и xRFM. Данное разнообразие обусловлено стремлением к повышению точности и эффективности моделей в различных сценариях. Каждый из этих алгоритмов обладает уникальными характеристиками и особенностями, что позволяет подобрать оптимальное решение для конкретной задачи, учитывая специфику данных и требуемый уровень производительности. Исследователи стремятся выявить преимущества и недостатки каждого метода, чтобы предоставить специалистам инструменты для построения наиболее эффективных моделей машинного обучения для табличных данных.
Для всесторонней и объективной оценки производительности различных моделей машинного обучения на табличных данных, был разработан специализированный бенчмарк — TabularMath. Данный бенчмарк ориентирован на задачи, имеющие детерминированное решение, что позволяет исключить влияние случайных факторов и точно измерить способность модели к обобщению и решению поставленной задачи. В рамках TabularMath, такие алгоритмы как XGBoost, CatBoost, LightGBM и другие, подвергаются строгому тестированию на различных наборах данных, что позволяет исследователям и практикам выявлять сильные и слабые стороны каждого подхода и выбирать наиболее подходящий инструмент для конкретной задачи. Результаты, полученные в рамках этого бенчмарка, служат надежной основой для сравнения моделей и определения перспективных направлений в развитии алгоритмов машинного обучения для табличных данных.
Понимание сильных и слабых сторон каждого метода машинного обучения, предназначенного для работы с табличными данными, имеет решающее значение для выбора оптимального подхода в конкретной задаче. Различные алгоритмы, такие как XGBoost, CatBoost и LightGBM, демонстрируют различную производительность в зависимости от характеристик набора данных — объема, количества признаков, наличия пропущенных значений и типов взаимосвязей. Например, некоторые модели лучше справляются с категориальными признаками, в то время как другие превосходно обрабатывают числовые данные. Тщательный анализ преимуществ и недостатков каждого алгоритма, в контексте конкретной задачи и доступных данных, позволяет значительно повысить точность и эффективность моделирования, избежав неоптимальных решений и максимизируя потенциал извлечения полезной информации из табличных данных.
Исследование, представленное в данной работе, акцентирует внимание на проблеме экстраполяции в табличном обучении, выявляя разрыв между способностью моделей к простому подбору кривой и выполнению точных вычислений. Это особенно заметно при работе с данными, требующими логических выводов и арифметических операций. Как однажды заметил Брайан Керниган: «Простота — это высшая степень совершенства». Эта фраза отражает стремление авторов к созданию бенчмарка TabularMath, который позволяет оценить не только способность модели к запоминанию, но и к пониманию лежащих в основе данных закономерностей. По сути, TabularMath представляет собой попытку измерить, насколько “достойно стареет” система в условиях недостатка данных и необходимости экстраполяции, выявляя её истинный потенциал к адаптации и решению новых задач.
Что Дальше?
Представленный анализ, выявляющий разрыв между регрессионной аппроксимацией и точным вычислением в табличных данных, лишь подтверждает старую истину: каждая абстракция несет груз прошлого. Стремление к обобщению, к созданию модели, работающей “из коробки”, неизбежно приводит к потере информации о конкретном механизме генерации данных. TabularMath, как инструмент выявления этой потери, ценен сам по себе, но лишь сигнализирует о необходимости пересмотра фундаментальных подходов.
Вопрос не в улучшении существующих алгоритмов, а в признании их временности. Попытки “выжать” больше точности из существующих моделей — это лишь отсрочка неизбежного. Гораздо перспективнее кажутся исследования, направленные на создание систем, способных адаптироваться к новым данным, учитывать контекст, и, возможно, даже “забывать” устаревшую информацию. Медленные изменения — вот что обеспечивает устойчивость, а не гонка за максимальной точностью на фиксированном наборе данных.
Будущие работы, вероятно, сосредоточатся на разработке гибридных подходов, сочетающих в себе преимущества глубокого обучения и символьных вычислений. Но даже в этом случае, необходимо помнить: время — это не метрика, а среда, в которой существуют системы. И любая система, даже самая совершенная, неизбежно стареет. Вопрос лишь в том, делает ли она это достойно.
Оригинал статьи: https://arxiv.org/pdf/2602.02523.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Многокритериальная оптимизация: взгляд на народные методы
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Искусственный интеллект в медицине: новый уровень самостоятельности
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Диффузия против Квантов: Новый Взгляд на Факторизацию
2026-02-04 13:55