Автор: Денис Аветисян
Представлен TabReX — фреймворк, позволяющий автоматически оценивать качество сгенерированных таблиц, даже без наличия эталонных данных.
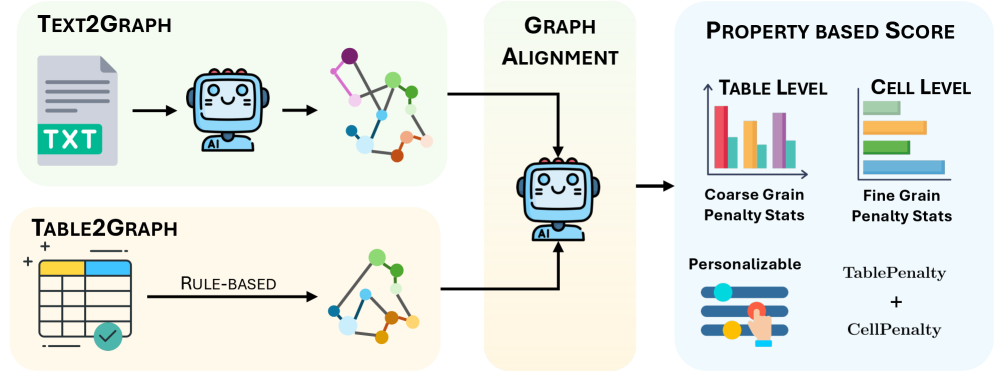
TabReX использует графовое рассуждение и интерпретируемые метрики для надежной и прозрачной оценки табличных данных.
Оценка качества таблиц, генерируемых большими языковыми моделями, представляет собой сложную задачу, поскольку существующие метрики либо упрощают структуру таблиц, игнорируя её, либо зависят от фиксированных эталонных данных, ограничивая обобщение. В данной работе представлена система TabReX : Tabular Referenceless eXplainable Evaluation — новый подход к оценке табличных данных, основанный на графовом рассуждении и не требующий использования эталонных таблиц. TabReX преобразует исходный текст и сгенерированные таблицы в канонические графы знаний, выравнивает их с помощью LLM и вычисляет интерпретируемые оценки, отражающие структурную и фактическую точность. Позволит ли TabReX создать более надежную и прозрачную систему оценки сгенерированных структурированных данных?
Пределы Традиционной Оценки Таблиц
Несмотря на широкое распространение метрик BLEU и ROUGE в оценке сгенерированных текстов, их применение к табличным данным сталкивается с существенными трудностями. Эти метрики, основанные на сопоставлении $n$-грамм с эталонными текстами, зачастую не способны уловить семантическую корректность информации, представленной в табличной форме. В то время как небольшие расхождения в формулировках текста могут быть несущественными, ошибки в числовых данных или логических связях между ячейками таблицы приводят к значительным искажениям смысла, которые BLEU и ROUGE попросту игнорируют. В результате, модели, генерирующие таблицы, могут получать высокие оценки по этим метрикам, несмотря на фактическую неверность или бессмысленность сгенерированного контента, что подчеркивает необходимость разработки специализированных методов оценки, учитывающих специфику табличных данных и их семантическую структуру.
Использование эталонных текстов в метриках оценки, таких как BLEU и ROUGE, создает существенные ограничения и предвзятости при анализе табличных данных. Данный подход, основанный на сравнении с заранее подготовленными образцами, не учитывает синонимию, перефразирование и различные способы представления информации в таблицах. Особенно это проявляется в случае с нюансированным или сложным содержанием, где множество корректных формулировок может не совпадать с эталонным текстом, что приводит к искусственному занижению оценки. Таким образом, полагаясь исключительно на сравнение с эталоном, системы оценки упускают из виду семантическую корректность и информативную ценность сгенерированных таблиц, что затрудняет объективную оценку качества моделей генерации.
Современные методы оценки генерации таблиц зачастую страдают от недостатка прозрачности, что существенно затрудняет отладку и совершенствование соответствующих моделей. Проблема заключается в том, что существующие метрики, выдавая численный результат, не предоставляют информации о конкретных причинах ошибок или слабых местах в сгенерированных данных. Это лишает разработчиков возможности точно определить, какие аспекты модели нуждаются в улучшении — например, корректность логических связей, точность числовых значений или согласованность данных в разных ячейках. В результате, процесс отладки превращается в трудоемкий и малоэффективный эксперимент, где улучшение производительности достигается скорее эмпирическим путем, чем благодаря целенаправленной коррекции проблемных областей. Отсутствие интерпретируемости также усложняет анализ результатов и понимание того, как различные факторы влияют на качество генерации таблиц, что препятствует созданию более надежных и точных моделей.
TabReX: Оценка на Основе Свойств Данных
Традиционные методы оценки таблиц, сгенерированных моделями обработки естественного языка, часто требуют наличия эталонных (reference) таблиц для сравнения, что ограничивает их применимость и масштабируемость. TabReX предлагает альтернативный подход, основанный на оценке таблиц без использования эталонов (reference-less evaluation). Вместо прямого сравнения с эталоном, TabReX фокусируется на проверке соответствия сгенерированной таблицы определенным свойствам, извлеченным из исходного текста. Такой подход позволяет оценивать качество таблицы, не полагаясь на заранее подготовленные данные, и делает оценку более гибкой и адаптивной к различным задачам и доменам. Оценка осуществляется путем определения степени, в которой сгенерированная таблица демонстрирует эти свойства, что обеспечивает более интерпретируемые и обоснованные результаты.
В основе TabReX лежит использование графов знаний для семантического сравнения сгенерированных таблиц и исходного текста. Как таблица, так и текст преобразуются в графы, где узлы представляют сущности, а ребра — отношения между ними. Это позволяет осуществлять сравнение не на уровне поверхностного совпадения слов, а на уровне смысла и взаимосвязей между понятиями. Графы знаний предоставляют структурированное представление информации, что облегчает выявление семантических несоответствий и оценку точности сгенерированной таблицы по отношению к исходному тексту. Такой подход позволяет оценивать не только фактическую корректность данных, но и полноту и логическую согласованность представленной информации.
В основе TabReX лежит преобразование как исходного текста, так и сгенерированной таблицы в графы знаний. Этот процесс осуществляется с помощью специализированных компонентов — Text2Graph для текста и Table2Graph для таблиц. Оба компонента используют большие языковые модели (LLM) для извлечения сущностей, отношений и атрибутов, представляя их в виде триплетов вида (субъект, отношение, объект). LLM обеспечивают семантическое понимание текста и структуры таблицы, позволяя формировать графы, отражающие их содержание и связи между элементами данных. Полученные графы знаний служат основой для дальнейшей оценки соответствия между таблицей и исходным текстом.
Оценка производится путем выравнивания построенных графов знаний, представляющих сгенерированную таблицу и исходный текст, и последующего присвоения баллов на основе интерпретируемых свойств. Выравнивание позволяет сопоставить сущности и отношения в обоих графах, определяя степень соответствия между табличными данными и исходной информацией. Баллы выставляются на основе четко определенных метрик, таких как точность сопоставления сущностей, полнота представленной информации и согласованность отношений, что обеспечивает прозрачность и воспроизводимость оценки. Использование интерпретируемых свойств позволяет выявить конкретные сильные и слабые стороны сгенерированной таблицы.
TabReX-Bench: Тщательная Валидация
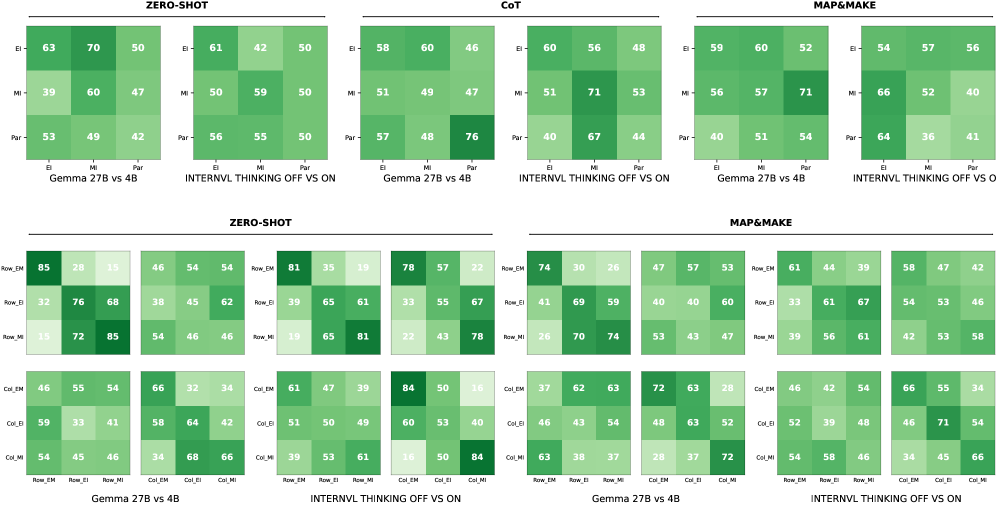
Для всесторонней оценки TabReX был разработан TabReX-Bench — масштабный бенчмарк для метрик, применяемых к табличным данным. Этот бенчмарк включает в себя обширный набор таблиц и метрик, позволяющий оценить производительность различных алгоритмов в различных сценариях. TabReX-Bench предназначен для обеспечения надежной и воспроизводимой оценки, что критически важно для сравнения и улучшения алгоритмов анализа табличных данных. В бенчмарке реализована поддержка различных типов табличных данных и метрик, что обеспечивает его гибкость и применимость к широкому спектру задач.
Для всесторонней оценки устойчивости и чувствительности метрик, TabReX-Bench использует как сохраняющие данные, так и изменяющие данные возмущения. Сохраняющие данные возмущения включают незначительные изменения, не влияющие на базовую информацию в таблице, например, перестановку столбцов или небольшое округление числовых значений. Изменяющие данные возмущения, напротив, намеренно вносят изменения, такие как добавление шума, пропуски значений или замена данных, чтобы оценить, насколько метрика реагирует на искажения в исходных данных и сохраняет ли она свою согласованность. Комбинация этих двух типов возмущений позволяет комплексно оценить поведение метрики в различных сценариях и выявить ее слабые места.
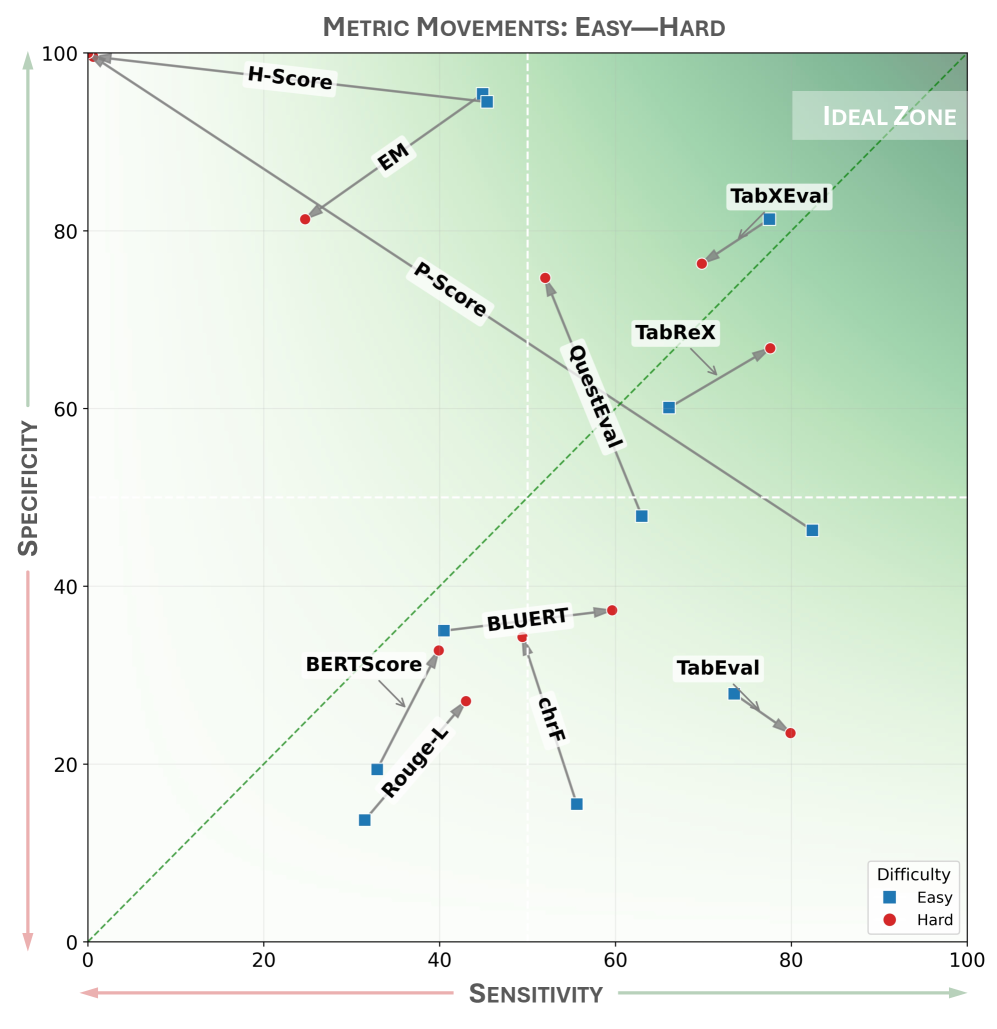
Валидация производительности TabReX проведена посредством вычисления коэффициента корреляции Спирмена, который достиг значения 0.75 при сравнении с оценками, данными людьми. Данный показатель демонстрирует высокую степень согласованности между автоматической оценкой метрик и субъективным человеческим восприятием качества, подтверждая надежность и адекватность предложенного фреймворка в задачах оценки табличных данных. Высокое значение корреляции указывает на то, что TabReX способен эффективно выявлять и оценивать характеристики табличных данных, аналогично тому, как это делают эксперты-люди.
При валидации TabReX были получены значения коэффициента корреляции Кендалла $Tau = 0.64$ и рангового коэффициента корреляции (RBO) равного $0.41$ при сравнении с оценками, данными людьми. Эти результаты демонстрируют высокую степень согласованности TabReX с человеческим суждением и подтверждают надежность и устойчивость системы при использовании различных метрик корреляции для оценки качества табличных данных.
В основе TabReX лежит методология оценки, основанная на анализе свойств данных (Property-Driven Scoring), что обеспечивает интерпретируемость и надёжность результатов. Вместо прямой оптимизации под конкретные метрики, TabReX оценивает, насколько хорошо метрика соответствует заранее определённым свойствам, таким как монотонность и согласованность с базовыми принципами анализа данных. Это позволяет не только количественно оценить качество метрики, но и предоставить объяснение её поведения, что критически важно для понимания и доверия к результатам. Такой подход позволяет выявлять метрики, которые дают корректные результаты не случайно, а благодаря соответствию фундаментальным свойствам данных, что повышает общую надёжность системы оценки.
Влияние и Перспективы Развития
Разработанный инструмент TabReX представляет собой более надежный и понятный метод оценки моделей генерации таблиц, что способствует улучшению их разработки и отладке. В отличие от существующих метрик, часто предоставляющих лишь общую оценку, TabReX обеспечивает детальный анализ семантической корректности сгенерированных таблиц. Такой подход позволяет разработчикам не только выявлять общие недостатки моделей, но и точно определять конкретные области, требующие улучшения, например, корректность связей между данными или соответствие табличной структуры заданным требованиям. Благодаря этому, TabReX выступает в качестве ценного ресурса для исследователей, стремящихся к созданию более точных и надежных систем генерации таблиц, способных эффективно обрабатывать и представлять структурированную информацию.
Подход, основанный на использовании графов знаний, позволяет значительно углубить понимание семантической корректности табличных данных. Вместо простого сопоставления текста, система анализирует взаимосвязи между сущностями, представленными в таблице, и проверяет их соответствие общепринятым знаниям и логическим правилам. Это означает, что TabReX способен выявлять не только синтаксические ошибки, но и смысловые несоответствия, которые остаются незамеченными при использовании традиционных метрик. Например, система может определить, что утверждение «Париж — столица Германии» является неверным, опираясь на знания, хранящиеся в графе знаний, даже если само предложение грамматически корректно. Такой анализ открывает новые возможности для оценки и улучшения моделей генерации таблиц, обеспечивая более высокую степень достоверности и информативности генерируемых данных.
Для сообщества исследователей, занимающихся генерацией таблиц, создан ценный ресурс — эталонный набор данных TabReX-Bench. Он предоставляет стандартизированную платформу для объективного сравнения различных метрик оценки качества сгенерированных таблиц. TabReX-Bench позволяет исследователям не просто сравнивать общую производительность моделей, но и выявлять сильные и слабые стороны каждой метрики в различных сценариях. Это способствует более глубокому пониманию ограничений существующих методов оценки и стимулирует разработку более надежных и интерпретируемых метрик, что, в свою очередь, ускоряет прогресс в области генерации табличных данных. Предоставляя единую точку отсчета, TabReX-Bench способствует повышению прозрачности и воспроизводимости исследований в данной области, позволяя более эффективно накапливать и распространять знания.
Исследование демонстрирует, что метрика TabReX обладает значительно более высокой способностью к различению между моделями генерации таблиц, о чем свидетельствует показатель TabReX Tie Ratio ($\pi_t$) в 13.6%. Этот параметр указывает на то, что в значительно большем количестве случаев TabReX способна выявить различия в качестве сгенерированных таблиц, в то время как другие метрики часто демонстрируют одинаковую оценку для моделей с разным уровнем производительности. Кроме того, показатель Rank Dispersion ($\zeta_F$), равный 27.0, подтверждает стабильность метрики TabReX, то есть она последовательно оценивает модели, минимизируя влияние случайных факторов и обеспечивая надежные результаты сравнения.
Дальнейшие исследования TabReX направлены на расширение его возможностей для анализа табличных данных со сложной структурой, включая вложенные таблицы и ячейки с разнородным содержимым. Особое внимание будет уделено интеграции предметно-ориентированных знаний — например, информации из баз знаний или онтологий — для более точной оценки семантической корректности таблиц. Это позволит не просто выявлять синтаксические ошибки, но и оценивать, насколько сгенерированные данные соответствуют реальным фактам и логическим связям в конкретной области. Планируется разработка механизмов, учитывающих контекст и специфику данных, что приведет к созданию более надежной и интерпретируемой системы оценки генерации таблиц и откроет новые возможности для автоматической проверки и улучшения качества данных.
Представленная работа демонстрирует стремление к упрощению оценки табличных данных, избегая необходимости в эталонных значениях. Такой подход, как и философия, изложенная Эдсгером Дейкстрой: «Простота — это высшая степень изысканности», позволяет сосредоточиться на внутренней логике и структуре генерируемых таблиц. TabReX, используя графовое рассуждение, стремится к ‘компрессии без потерь’ — выделению наиболее значимых аспектов качества таблицы, удаляя избыточную сложность. Это соответствует идее, что совершенство достигается не добавлением, а удалением лишнего, что особенно важно при оценке структурированных данных, где ясность и интерпретируемость играют ключевую роль.
Что дальше?
Представленный подход, хоть и демонстрирует перспективность оценки табличных данных без необходимости в эталонных примерах, не освобождает от необходимости дальнейшей работы над фундаментальными вопросами. Сложность табличных структур и многообразие возможных интерпретаций требуют более глубокого понимания того, что именно делает таблицу «хорошей». Текущие метрики, основанные на графовом рассуждении, лишь приближают к этой цели, но не являются окончательным ответом. Иллюзия совершенства, создаваемая кажущейся точностью численных показателей, должна быть рассеяна.
Наиболее важным направлением представляется не столько разработка новых метрик, сколько создание инструментов, позволяющих пользователю самостоятельно оценивать качество сгенерированных таблиц, опираясь на контекст задачи и собственные знания. Искусственный интеллект должен быть не заменой человеческого разума, а его усилением. Добавление всё новых и новых слоёв абстракции лишь отдаляет от сути, тогда как истинное понимание достигается через упрощение и очищение.
В конечном итоге, ценность TabReX и подобных ему фреймворков заключается не в абсолютной оценке, а в предоставлении пользователю информации, необходимой для принятия обоснованных решений. Вместо стремления к идеальной метрике следует сосредоточиться на создании инструментов, способных выявлять ошибки и несоответствия, позволяя человеку самостоятельно оценивать и корректировать результаты. Ведь, как известно, совершенство не в количестве добавленного, а в количестве убранного.
Оригинал статьи: https://arxiv.org/pdf/2512.15907.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-19 10:37