Автор: Денис Аветисян
Исследователи представили UM-Text — модель, объединяющую возможности понимания изображений и обработки текста для точного и гибкого редактирования визуального контента по текстовым запросам.
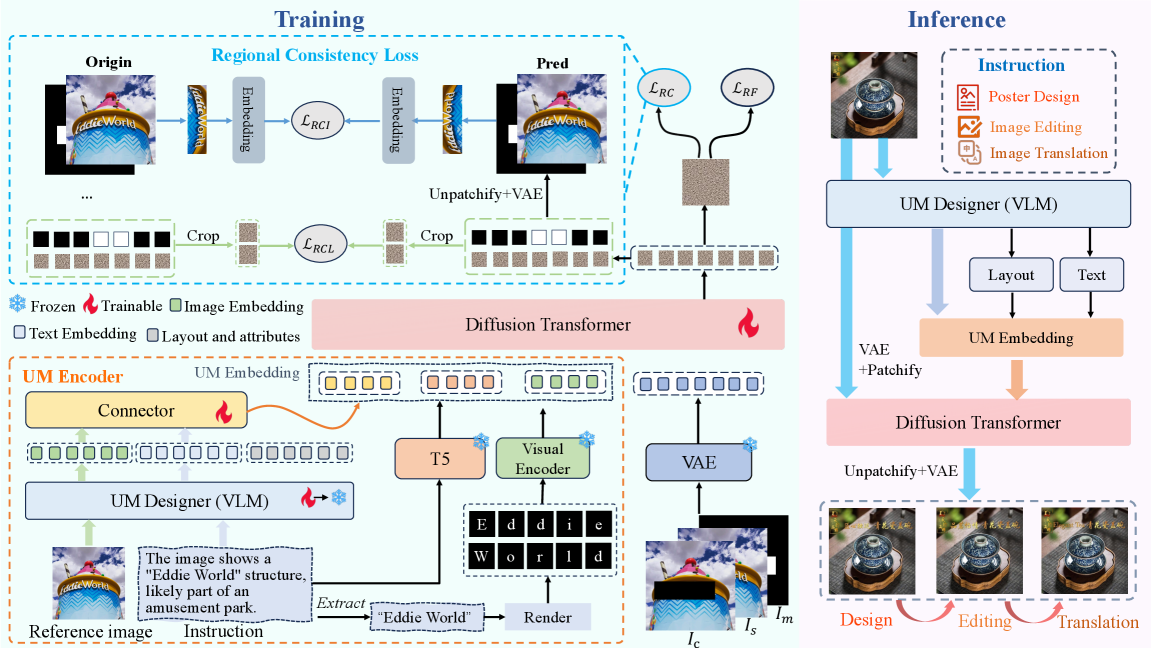
Представлена унифицированная мультимодальная модель UM-Text, использующая диффузионные модели и региональные потери согласованности для улучшения задач генерации и редактирования изображений по текстовым описаниям.
Несмотря на значительный прогресс в области генерации изображений, редактирование текста на изображениях с использованием естественного языка остается сложной задачей, требующей глубокого понимания контекста и стилистической согласованности. В данной работе представлена модель UM-Text: A Unified Multimodal Model for Image Understanding, предлагающая унифицированный мультимодальный подход к пониманию контекста и визуальному редактированию текста по текстовым инструкциям. Ключевой особенностью является интеграция Visual Language Model (VLM) и нового энкодера UM-Encoder, позволяющих точно интерпретировать инструкции и создавать гармоничный визуальный текст, а также разработанный набор данных UM-DATA-200K для обучения модели. Сможет ли предложенный подход существенно расширить возможности автоматизированного редактирования и генерации визуального контента?
Визуальный текст: Между иллюзией и смыслом
Существующие методы визуального редактирования текста зачастую сталкиваются с серьезными проблемами в поддержании семантической согласованности и эстетического качества. Это проявляется в искажениях смысла при замене или изменении текста на изображениях, а также в заметных визуальных артефактах, таких как несовпадение шрифтов, размеров или стилей. Вследствие этих ограничений, практическое применение подобных технологий в реальных сценариях, например, в автоматической коррекции рекламных баннеров или создании персонализированного контента, остается затруднительным. Неспособность сохранить как смысл, так и визуальную привлекательность существенно снижает полезность существующих систем, подчеркивая необходимость разработки принципиально новых подходов к визуальному редактированию текста.
Растущая потребность в высококачественном визуальном редактировании текста обуславливает необходимость разработки новой платформы, способной не только распознавать текст на изображениях, но и понимать его семантический контекст. Существующие методы часто не справляются с задачей сохранения эстетической целостности и смысловой связности при изменении текста в визуальном контенте. Поэтому, для достижения реалистичных и правдоподобных результатов, требуется принципиально новый подход, сочетающий в себе передовые алгоритмы компьютерного зрения и обработки естественного языка. Такая платформа должна уметь генерировать текст, органично вписывающийся в существующее изображение, учитывая его стиль, шрифт и общее визуальное восприятие, открывая широкие возможности для редактирования и улучшения визуального контента.
UM-Text: Унифицированный мультимодальный подход
В основе UM-Text лежит новый UM-Encoder, предназначенный для эффективного представления как визуальной, так и текстовой информации. Данный энкодер объединяет эти два типа данных в единое условие для последующей генерации контента. Он позволяет модели одновременно учитывать визуальный контекст и семантику текста, что обеспечивает более когерентное и релевантное создание мультимодальных документов. В отличие от традиционных подходов, требующих отдельных путей обработки для визуальных и текстовых данных, UM-Encoder обеспечивает их совместное кодирование, создавая унифицированное представление, используемое для управления процессом генерации.
В основе системы UM-Text лежит компонент UM-Designer, осуществляющий планировку и высококачественную отрисовку текста. Данный компонент функционирует на базе больших языковых моделей (LLM) и диффузионных моделей. LLM отвечают за планирование структуры и компоновки текста, определяя расположение элементов и их взаимосвязь. Диффузионные модели, в свою очередь, обеспечивают реалистичную и детализированную отрисовку текста, повышая его визуальное качество и удобочитаемость. Совместное использование этих технологий позволяет генерировать текстовые документы с согласованной структурой и высоким уровнем визуальной точности.
Для обеспечения структурной связности генерируемого текста в UM-Text используется функция потерь региональной согласованности (Regional Consistency Loss). Данный механизм способствует сохранению логической структуры и взаимосвязи между различными областями текста, что подтверждается экспериментальными данными. В ходе оценки производительности было зафиксировано улучшение на 4.8% и 4.2% на соответствующих наборах данных, что свидетельствует о повышении качества и когерентности генерируемого текста по сравнению с альтернативными подходами.

UM-DATA-200K: Основа для понимания визуального текста
Представляем UM-DATA-200K — масштабный набор данных, состоящий из пар «изображение-текст», разработанный специально для предварительного обучения наших визуальных языковых моделей (VLM). Набор данных содержит 200 тысяч пар и предназначен для улучшения способности моделей понимать и обрабатывать визуальную информацию, сопоставляя её с соответствующим текстовым описанием. Объем и структура UM-DATA-200K позволяют проводить эффективное обучение моделей, повышая их производительность в задачах визуального понимания и генерации текста.
Для обеспечения высокого качества набора данных UM-DATA-200K использовался комплекс автоматизированных инструментов. Обнаружение текста в изображениях осуществлялось с помощью PPOCRv4, что позволило точно идентифицировать и извлечь текстовую информацию. Сегментация объектов выполнялась с использованием SAM2, обеспечивая точное выделение и определение границ объектов на изображениях. Оценка эстетических характеристик изображений проводилась с помощью Aesthetic Predictor V2.5, что позволило отфильтровать изображения с низким качеством или нежелательными характеристиками и обеспечить визуальную согласованность набора данных.
Для обучения модели использовался FLUX-Fill — инструмент для генерации чистых изображений. Он позволяет снизить уровень шума и артефактов в обучающей выборке, что достигается путем автоматической коррекции и улучшения качества исходных изображений. Применение FLUX-Fill способствует повышению стабильности и эффективности процесса обучения, позволяя модели лучше обобщать данные и достигать более высоких показателей точности.

Превосходная производительность и широкая применимость
Экспериментальные исследования показали, что UM-Text превосходит существующие методы в задачах генерации и редактирования текста, достигая передовых результатов на эталонных наборах данных, включая AnyText. Эффективность модели оценивалась с использованием метрик, таких как Frechet Inception Distance (FID), демонстрирующая улучшенное качество генерируемого текста, а также Sentence Accuracy (Sen.ACC) и Normalized Edit Distance (NED), подтверждающие высокую точность и соответствие исходному смыслу при внесении изменений. Полученные результаты указывают на значительный прогресс в области автоматической обработки естественного языка и открывают новые возможности для создания более качественных и эффективных текстовых редакторов и генераторов.
Разработанная система демонстрирует выдающуюся устойчивость в широком спектре задач по редактированию текста. Исследования показали, что она эффективно справляется не только с простой заменой фрагментов текста, но и со сложными преобразованиями, такими как изменение стиля изложения и модификация содержания. Данная гибкость достигается благодаря архитектуре, позволяющей адаптироваться к различным требованиям к редактированию, обеспечивая сохранение как семантической точности, так и стилистической согласованности исходного текста. Способность системы к комплексному редактированию открывает широкие возможности для автоматизации задач, связанных с улучшением качества, адаптацией и персонализацией текстового контента.
Исследования показали, что применение Learned Perceptual Image Patch Similarity (LPIPS) демонстрирует более низкие значения в сравнении с DreamText, что свидетельствует о значительно улучшенной согласованности стиля генерируемых текстов. Этот показатель, наряду с достижением передовых результатов в Sequence Accuracy (SeqAcc), подтверждает способность разработанного фреймворка не только создавать визуально правдоподобные тексты, но и сохранять их семантическую точность и соответствие исходному контексту. Полученные данные указывают на превосходство системы в поддержании стилистической целостности и генерации последовательностей, которые более точно отражают заданный смысл.

В очередной раз наблюдается стремление к универсальности, к единой модели, способной охватить сразу несколько модальностей. UM-Text, как и многие другие разработки, пытается совместить текстовое описание и визуальное представление. Однако, как известно, каждая «революционная» технология завтра станет техдолгом. Разработчики утверждают о достижении региональной согласованности, но стоит помнить, что даже самая изящная архитектура рано или поздно встретится с реальностью продакшена, где баги возникают там, где их меньше всего ожидаешь. Как метко заметил Янн Лекун: «Если баг воспроизводится — значит, у нас стабильная система». И это не ирония, а констатация факта. В конечном итоге, главная задача — не создать идеальную модель, а научиться быстро и эффективно её чинить.
Что дальше?
Представленная работа, безусловно, добавляет ещё один уровень сложности в и без того перегруженную область мультимодального обучения. Однако, не стоит забывать старую истину: каждое «революционное» улучшение — это лишь отложенный технический долг. Возможность редактирования изображений по текстовому запросу — это красиво, но вопрос стабильности и предсказуемости генерации в реальных условиях остаётся открытым. Скорее всего, продюсеры найдут способ сломать даже самую элегантную архитектуру, заставив модель генерировать нечто невообразимое при вполне разумном запросе.
Новый набор данных и функция потерь, направленная на региональную согласованность, — это шаг в правильном направлении, но не панацея. Важно помнить, что идеальный код — это признак того, что его ещё никто не запустил в продакшн. Будущие исследования, вероятно, будут сосредоточены на повышении робастности модели к зашумленным или неоднозначным запросам, а также на снижении вычислительных затрат, ведь каждое усложнение всегда имеет свою цену.
Вместо погони за очередным SOTA, стоит задуматься о фундаментальных вопросах: действительно ли пользователю нужно редактировать изображение, или достаточно просто сгенерировать новое? Возможно, самое интересное развитие области — это не усложнение моделей, а их упрощение и адаптация к реальным потребностям, а не к академическим бенчмаркам. Ведь в конечном итоге, главное — чтобы модель работала, а не выглядела красиво в презентации.
Оригинал статьи: https://arxiv.org/pdf/2601.08321.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-14 22:40