Автор: Денис Аветисян
Новое исследование демонстрирует, как использование FPGA позволяет значительно ускорить сложные вычисления в тензорных сетях, превосходя возможности традиционных процессоров и графических ускорителей.
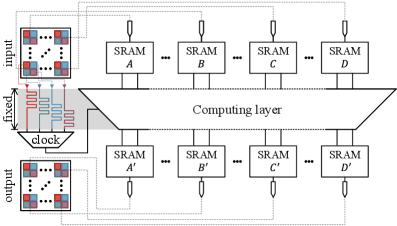
Ускорение алгоритмов iTEBD и HOTRG за счет параллельной реализации на FPGA позволяет эффективно работать с высокой размерностью связей.
Вычислительная сложность квантовых многочастичных расчетов остается серьезным препятствием для моделирования сложных систем. В настоящей работе, посвященной ‘Reducing the Computational Cost Scaling of Tensor Network Algorithms via Field-Programmable Gate Array Parallelism’, предложен новый подход к реализации алгоритмов тензорных сетей, основанный на параллелизме, обеспечиваемом программируемыми вентильными матрицами (FPGA). Разработанная схема, использующая стратегию разделения на квад-тайлы, позволяет существенно снизить вычислительную сложность алгоритмов iTEBD и HOTRG, достигая масштабирования O(D_b) и O(D_b^2) соответственно, в отличие от O(D_b^3) и O(D_b^6) в традиционных CPU-реализациях. Открывает ли это путь к созданию аппаратных платформ для масштабных вычислений с использованием тензорных сетей и преодолению ограничений, связанных с вычислительными ресурсами?
За гранью Монте-Карло: В поисках новых горизонтов
Традиционные методы Монте-Карло, широко применяемые для моделирования квантовых систем с большим числом частиц, сталкиваются с серьезной проблемой — так называемым «проблемой знаков». Данная трудность возникает из-за осциллирующего характера интегралов, необходимых для вычисления свойств системы. По мере увеличения размерности пространства состояний, количество положительных и отрицательных вкладов в интеграл стремится к нулю, что приводит к экспоненциальному снижению точности вычислений. \langle \psi | \hat{O} | \psi \rangle , где \hat{O} — наблюдаемая, становится все сложнее оценить с приемлемой погрешностью. Это существенно ограничивает применимость Монте-Карло к изучению сложных квантовых материалов и явлений, где число взаимодействующих частиц может быть очень большим, и делает поиск альтернативных подходов крайне актуальным.
В отличие от традиционных методов Монте-Карло, испытывающих затруднения при моделировании квантовых систем с большим числом частиц из-за экспоненциального роста вычислительной сложности, тензорные сети предлагают принципиально иной подход. Они используют информацию о квантовой запутанности — корреляциях между частицами — для эффективного представления многочастичных состояний. Вместо того чтобы описывать все возможные конфигурации системы, тензорные сети фокусируются на наиболее значимых, позволяя обходить экспоненциальный рост параметров. Это достигается за счет представления волновой функции как сети связанных тензоров, где каждый тензор описывает локальные корреляции. Такой подход позволяет существенно снизить вычислительные затраты и моделировать системы, недоступные для классических методов, открывая новые возможности для изучения сложных физических явлений и разработки новых материалов. По сути, тензорные сети позволяют «сжать» информацию о запутанном состоянии, сохраняя при этом его ключевые характеристики.
Переход к использованию тензорных сетей имеет решающее значение для моделирования сложных физических систем, которые ранее были недоступны для точного анализа. Традиционные вычислительные методы сталкиваются с экспоненциальным ростом сложности при увеличении числа взаимодействующих частиц, что делает невозможным изучение, например, высокотемпературных сверхпроводников или экзотических магнитных материалов. Тензорные сети, напротив, позволяют эффективно представлять и манипулировать квантовой информацией, используя информацию о структуре запутанности. Это открывает путь к решению задач, которые до недавнего времени казались неразрешимыми, и способствует развитию новых технологий в области материаловедения, химии и фундаментальной физики. Возможность моделировать более сложные системы не только углубляет понимание базовых физических принципов, но и позволяет предсказывать свойства новых материалов и разрабатывать инновационные устройства.
Для полной реализации потенциала тензорных сетей необходимы эффективные аппаратные решения. Хотя алгоритмы тензорных сетей демонстрируют многообещающие результаты в моделировании сложных квантовых систем, их вычислительная интенсивность требует специализированного оборудования для преодоления ограничений традиционных архитектур. Разработка и оптимизация таких аппаратных средств, включая специализированные процессоры и ускорители, представляет собой ключевую задачу, поскольку она напрямую влияет на масштабируемость и применимость этих методов к реальным физическим проблемам. Без эффективной аппаратной поддержки, возможности тензорных сетей по моделированию высокоразмерных систем останутся ограниченными, препятствуя прогрессу в материаловедении, химии и фундаментальной физике. Таким образом, инвестиции в аппаратные инновации являются необходимым условием для раскрытия полного потенциала этого перспективного подхода к квантовым вычислениям.
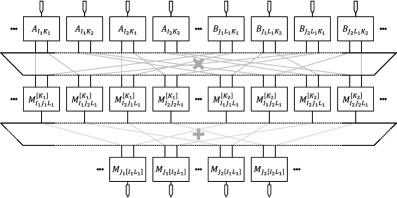
FPGA: Архитектура параллелизма для тензорных вычислений
Программируемые пользователем вентильные матрицы (FPGA) представляют собой перспективную платформу для ускорения алгоритмов тензорных сетей благодаря сочетанию переконфигурируемости и мелкозернистого параллелизма. В отличие от фиксированной архитектуры центральных и графических процессоров, FPGA позволяют адаптировать аппаратную структуру под конкретные вычислительные задачи, что особенно важно для тензорных операций. Возможность реализации параллельных вычислений на уровне логических элементов обеспечивает значительное повышение производительности за счет одновременной обработки данных, что делает FPGA эффективным решением для ресурсоемких задач машинного обучения и научных вычислений.
Эффективная реализация алгоритмов на FPGA напрямую зависит от оптимального использования ключевых ресурсов устройства. Блочная RAM (BRAM) обеспечивает высокоскоростную локальную память для хранения больших объемов данных, необходимых для вычислений. Слайсы цифровой обработки сигналов DSP48E оптимизированы для выполнения операций умножения и сложения, критически важных для тензорных вычислений. Look-Up Tables (LUT) реализуют логические функции и обеспечивают гибкость в реализации произвольных операций. Комбинация этих ресурсов позволяет эффективно развернуть сложные алгоритмы, минимизируя задержки и максимизируя пропускную способность, что особенно важно для ресурсоемких задач, таких как тензорные сети.
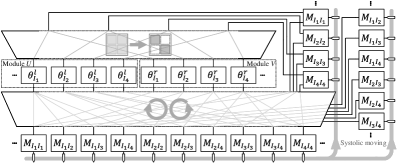
Стратегия параллелизма на основе Quad-Tile предполагает декомпозицию тензорных сверток и сингулярного разложения (SVD) на управляемые блоки. Этот подход заключается в разделении исходных тензоров на меньшие, независимые фрагменты — «тайлы». Вычисления, такие как умножение тензоров и SVD, выполняются параллельно над этими тайлами, что значительно снижает общее время вычислений. Размер тайлов оптимизируется для эффективного использования ресурсов FPGA, включая Block RAM (BRAM) и DSP48E slices. Использование Quad-Tile позволяет добиться высокой степени параллелизма и, как следствие, существенного ускорения по сравнению с последовательными вычислениями на CPU или GPU.
Применение метода Quad-Tile Parallelism позволяет добиться значительного ускорения вычислений в алгоритмах тензорных сетей. Экспериментальные данные демонстрируют, что данный подход обеспечивает ускорение до 24.7x по сравнению с центральными процессорами (CPU) и превосходит производительность графических процессоров (GPU) в задачах, связанных с тензорными операциями и разложением по сингулярным числам (SVD). Ускорение достигается за счет распараллеливания операций над блоками данных, что позволяет эффективно использовать ресурсы FPGA для одновременного выполнения множества вычислений.
Модель Гейзенберга: Эталонная проверка и валидация
Одномерная антиферромагнитная модель Гейзенберга (H = \sum_{i} \vec{S}_i \cdot \vec{S}_{i+1}) широко используется в качестве эталонной платформы для оценки эффективности алгоритмов тензорных сетей и их аппаратных реализаций на FPGA. Выбор обусловлен относительной простотой модели, позволяющей протестировать основные принципы работы алгоритмов, и одновременно достаточной сложностью для демонстрации преимуществ аппаратного ускорения. Модель позволяет валидировать точность и производительность различных методов, таких как Infinite Time-Evolving Block Decimation (ITEBD) и Higher-Order Tensor Renormalization Group (HOTRG), в задачах поиска основного состояния, а также сравнивать их с традиционными вычислительными платформами, такими как CPU и GPU.
Для определения волновой функции основного состояния в модели одномерного антиферромагнитного Гейзенберга используются алгоритмы Infinite Time-Evolving Block Decimation (iTEBD) и Higher-Order Tensor Renormalization Group (HOTRG). iTEBD представляет собой метод временной эволюции блочного типа, позволяющий эффективно аппроксимировать основное состояние путем последовательного расширения блочной структуры. HOTRG, в свою очередь, является методом группы ренормализации, использующим тензорные преобразования более высокого порядка для достижения более точной аппроксимации и уменьшения вычислительной сложности по сравнению с традиционными методами. Оба алгоритма активно применяются для анализа корреляционных функций и других свойств основного состояния в данной модели.
Экспериментальные результаты демонстрируют значительное увеличение производительности при использовании FPGA для реализации алгоритмов ITEBD и HOTRG в сравнении с традиционными вычислительными платформами. В частности, зафиксировано ускорение в 19.2 раза по сравнению с графическими процессорами (GPU) и в 24.7 раза по сравнению с центральными процессорами (CPU). Данное ускорение достигается благодаря аппаратной реализации алгоритмов на FPGA, что позволяет эффективно использовать параллелизм и оптимизировать операции для решения задач квантовой физики.
Успешная реализация демонстрирует возможность аппаратного ускорения на FPGA для решения сложных квантовых задач. В частности, алгоритм iTEBD (Infinite Time-Evolving Block Decimation) имеет вычислительную сложность, масштабирующуюся как O(Db), где D — размер локального гильбертова пространства, а b — число блоков в цепи. Алгоритм HOTRG (Higher-Order Tensor Renormalization Group) характеризуется более высокой сложностью, равной O(Db2). Такая зависимость от параметров D и b позволяет существенно сократить время вычислений по сравнению с традиционными CPU и GPU решениями при решении задач, связанных с одномерной антиферромагнитной моделью Гейзенберга, и подтверждает перспективность использования FPGA для моделирования квантовых систем.
![Сравнение времени вычислений на различных платформах (FPGA с конвейерной и без нее, GPU, CPU) для одномерной AF Heisenberg модели показывает, что время вычислений масштабируется как <span class="katex-eq" data-katex-display="false">Db^x</span>, где значения <span class="katex-eq" data-katex-display="false">x</span> составляют 1.11, 1.09, 1.14 и 2.94 для FPGA (конвейерный), FPGA (без конвейера), GPU и CPU соответственно, что подтверждается логарифмическим масштабом на вставках и сопоставимо с результатами предыдущей работы (Db^[2.88]D\_{b}^{2.88}).](https://arxiv.org/html/2602.05900v1/x4.png)
Взгляд в будущее: Новые горизонты и перспективы
Разработанные методы аппаратного ускорения на основе FPGA оказались применимы не только в задачах квантовой физики, но и в областях машинного обучения и анализа больших данных. Высокая производительность и энергоэффективность, достигнутые при моделировании квантовых систем, делают эти технологии востребованными для решения сложных вычислительных задач, возникающих при обучении нейронных сетей или обработке огромных массивов информации. Возможность параллельной обработки данных, присущая FPGA, позволяет значительно сократить время вычислений и повысить пропускную способность систем, что особенно важно для приложений, требующих оперативной обработки данных в режиме реального времени. Таким образом, данное исследование открывает новые перспективы для создания более эффективных и быстрых вычислительных систем, способных решать широкий спектр задач в различных областях науки и техники.
Дальнейшие исследования направлены на изучение альтернативных аппаратных архитектур, в частности, тензорных процессоров (TPU) и специализированных интегральных схем (ASIC). Эти платформы предлагают потенциал для значительного повышения производительности и энергоэффективности по сравнению с традиционными центральными и графическими процессорами. TPU, разработанные Google, оптимизированы для операций матричного умножения, ключевых для задач машинного обучения и моделирования. ASIC, в свою очередь, позволяют создавать специализированные схемы, идеально подходящие для конкретных вычислительных задач, что обеспечивает максимальную производительность при минимальном энергопотреблении. Изучение возможностей этих архитектур позволит расширить границы применимости разработанных методов ускорения и открыть новые перспективы в решении сложных научных и технологических задач.
Сравнение производительности и энергоэффективности различных вычислительных платформ, таких как FPGA, Tensor Processing Units (TPU) и специализированные интегральные схемы (ASIC), становится ключевым фактором в оптимизации решения конкретных задач. Эффективность каждой платформы существенно различается в зависимости от характера вычислений: FPGA демонстрируют гибкость, TPU — высокую скорость в задачах машинного обучения, а ASIC — максимальную энергоэффективность для специализированных алгоритмов. Тщательный анализ этих параметров позволит определить оптимальное решение, обеспечивающее наилучшее соотношение между скоростью, потреблением энергии и стоимостью, что критически важно для широкого спектра приложений, от моделирования сложных систем до обработки больших объемов данных и разработки передовых алгоритмов искусственного интеллекта.
Представленная работа вносит значительный вклад в разработку вычислительных систем нового поколения, отличающихся повышенной мощностью и энергоэффективностью. Это позволяет решать сложнейшие задачи современной науки и техники, ранее недоступные из-за ограничений вычислительных ресурсов. Оптимизация аппаратного обеспечения для моделирования квантовых систем, продемонстрированная в исследовании, имеет потенциал для ускорения прогресса в таких областях, как разработка новых материалов, создание лекарственных препаратов и анализ больших данных. В перспективе, подобные разработки могут стать основой для построения высокопроизводительных вычислительных кластеров, способных решать глобальные проблемы, стоящие перед человечеством, и открывать новые горизонты в познании окружающего мира.

Исследование демонстрирует, что даже самые сложные вычисления, такие как те, что используются в тензорных сетях, могут быть ускорены при использовании специализированного оборудования, вроде FPGA. Это напоминает о хрупкости любой теоретической конструкции. Словно горизонт событий, ограничения аппаратного обеспечения рано или поздно поглощают любые амбиции по бесконечному масштабированию вычислений. Как однажды заметил Стивен Хокинг: «Чем больше мы узнаем о Вселенной, тем больше понимаем, как мало мы знаем». В данном случае, преодоление ограничений вычислительной мощности — это не покорение пространства, а лишь наблюдение за тем, как оно покоряет нас, заставляя искать новые подходы к решению задач, даже если эти подходы кажутся временными.
Куда же дальше?
Представленные результаты, несомненно, демонстрируют ускорение вычислений тензорных сетей посредством аппаратного параллелизма на FPGA. Однако, ускорение — это всего лишь свет, который ещё не успел исчезнуть за горизонтом событий вычислительной сложности. Увеличение масштаба вычислений, неизбежное в стремлении к более реалистичным моделям, вновь и вновь обнажит фундаментальные ограничения. Не стоит обольщаться, что железо решит все проблемы.
Очевидно, что вопрос не только в скорости, но и в архитектуре. Тензорные сети, несмотря на свою элегантность, остаются лишь одним из способов представления многочастичных систем. Следует помнить, что любая модель — это лишь приближение, неизбежно искажающее реальность. Поиск более эффективных алгоритмов, способных ужимать информацию без потери существенной точности, представляется задачей куда более фундаментальной, чем простое наращивание вычислительных мощностей.
В конечном итоге, прогресс в этой области будет определяться не столько скоростью вычислений, сколько способностью исследователей признать хрупкость любой теории. Возможно, ключ к решению лежит не в совершенствовании существующих методов, а в смелом пересмотре основополагающих принципов представления данных. Иначе, все эти усилия окажутся лишь тщетной попыткой удержать свет, который уже необратимо поглощён тьмой.
Оригинал статьи: https://arxiv.org/pdf/2602.05900.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Bibby AI: Новый помощник для исследователей в LaTeX
- Графы и действия: новый подход к планированию для роботов
- Визуальное мышление машин: проверка на прочность
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Наука определений: Автоматическое извлечение знаний из научных текстов
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Искусственный интеллект, который знает, когда ему нужна подсказка
2026-02-06 14:58