Автор: Денис Аветисян
Новое исследование показывает, что оптимизация скорости обучения может быть важнее выбора конкретного метода адаптации параметров при тонкой настройке больших языковых моделей.
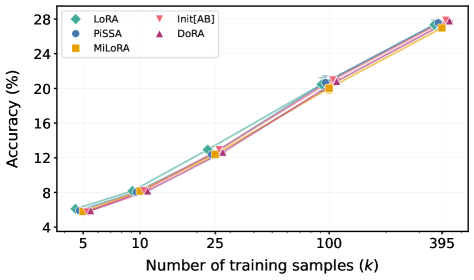
Анализ кривизны показывает, что многие варианты LoRA достигают сопоставимой производительности с базовым LoRA при правильной настройке скорости обучения.
Несмотря на активное развитие альтернативных методов адаптации больших языковых моделей (LLM), вопрос о реальной эффективности этих подходов остается открытым. В работе ‘Learning Rate Matters: Vanilla LoRA May Suffice for LLM Fine-tuning’ проведено систематическое исследование четырех вариантов LoRA в сравнении с базовым методом, показавшее, что оптимальный диапазон скорости обучения существенно различается для разных адаптеров. Ключевой вывод состоит в том, что при корректной настройке скорости обучения все методы достигают сопоставимой производительности, а различия, связанные с рангом адаптеров, оказываются незначительными. Не является ли оптимизация скорости обучения более важным фактором, чем выбор конкретного метода адаптации LLM, и какие теоретические основания, связанные с кривизной пространства параметров, могут объяснить наблюдаемые различия в оптимальных значениях скорости обучения?
Крупные языковые модели: между возможностями и ограничениями
Несмотря на впечатляющие возможности, демонстрируемые крупными языковыми моделями, такими как Qwen3-0.6B, Gemma-3-1B и Llama-2-7B, сложные задачи, требующие логического мышления и анализа, зачастую остаются для них недоступными. Эти модели превосходно справляются с генерацией текста, переводом и ответами на простые вопросы, однако при столкновении с задачами, требующими многоступенчатого рассуждения или понимания контекста, их производительность заметно снижается. Данное ограничение связано с тем, что модели, в основном, обучаются на огромных объемах текстовых данных, где акцент делается на статистических закономерностях, а не на глубоком понимании взаимосвязей и причинно-следственных связей. Поэтому, несмотря на впечатляющий размер и вычислительную мощность, способность к комплексному мышлению остается одной из главных проблем, стоящих перед разработчиками современных языковых моделей.
Увеличение размера языковых моделей, несмотря на кажущуюся логику, не всегда приводит к пропорциональному улучшению их способностей к сложному рассуждению. Исследования показывают, что вычислительные затраты на обучение и использование гигантских моделей растут экспоненциально, в то время как прирост производительности на тестах, требующих логического мышления и анализа, становится всё менее заметным. Это указывает на то, что простое увеличение числа параметров не является панацеей, и для достижения реального прогресса в области искусственного интеллекта необходимы инновационные подходы к архитектуре моделей и методам обучения, которые позволят более эффективно использовать вычислительные ресурсы и повысить способность к абстрактному мышлению.
Современные большие языковые модели, несмотря на впечатляющие возможности, требуют значительных изменений параметров в процессе тонкой настройки для адаптации к конкретным задачам. Этот процесс, известный как fine-tuning, оказывается ресурсоемким, поскольку требует пересчета и обновления миллиардов параметров модели. Необходимость столь масштабных обновлений обусловлена тем, что базовые модели, обученные на огромных объемах данных, не всегда обладают достаточной специфичностью для решения узкоспециализированных задач. В результате, адаптация модели к новой задаче может потребовать значительных вычислительных мощностей и времени, что ограничивает возможности быстрого и экономичного развертывания LLM в различных приложениях. Исследователи активно ищут методы, позволяющие снизить потребность в масштабных обновлениях параметров, например, за счет использования адаптеров или техник transfer learning, чтобы сделать процесс тонкой настройки более эффективным и доступным.
Параметрически-эффективная тонкая настройка: меньше параметров, больше смысла
Методы параметрически-эффективной тонкой настройки (PEFT) представляют собой подход к адаптации предварительно обученных больших языковых моделей к конкретным задачам, при котором обновляется лишь небольшая доля от общего числа параметров модели. Вместо полной перенастройки всех весов, PEFT методы вводят или изменяют лишь ограниченное количество дополнительных параметров, что существенно снижает вычислительные затраты и требования к памяти. Это особенно важно при работе с моделями, насчитывающими миллиарды параметров, где полная перенастройка становится практически невозможной из-за ограничений ресурсов. Сокращение числа обучаемых параметров также снижает риск переобучения на небольших наборах данных, что повышает обобщающую способность модели на новых, ранее не встречавшихся данных.
Метод адаптации с низким рангом (LoRA) является эффективной техникой параметро-эффективной тонкой настройки (PEFT), заключающейся во внедрении обучаемых матриц низкого ранга в существующие слои предварительно обученной модели. Вместо обновления всех параметров модели, LoRA замораживает исходные веса и вводит параллельные матрицы низкого ранга ΔW, которые обучаются для адаптации модели к конкретной задаче. Это существенно снижает количество обучаемых параметров, сохраняя при этом способность модели к эффективному обучению и обобщению. Матрицы ΔW имеют значительно меньший размер, чем исходные веса, что приводит к сокращению вычислительных затрат и требований к памяти.
Эффективность LoRA напрямую зависит от инициализации вводимых низкоранговых матриц. Неправильная инициализация может привести к замедлению скорости сходимости алгоритма обучения и, как следствие, к снижению итоговой производительности модели. Оптимальная инициализация, как правило, предполагает использование небольших случайных значений, что способствует более стабильному процессу обучения и предотвращает доминирование низкоранговых адаптеров над исходными весами модели. Экспериментальные данные демонстрируют, что выбор стратегии инициализации оказывает значительное влияние на достижение оптимальных результатов, особенно в задачах, требующих высокой точности и быстрой адаптации к новым данным.
Оптимизация инициализации LoRA: тонкости настройки для лучшего результата
Адаптеры LoRA, в различных реализациях, таких как MiLoRA и PiSSA, используют различные стратегии инициализации для повышения эффективности обучения. MiLoRA инициализирует адаптеры, используя нижние главные компоненты матрицы разложения, что позволяет сконцентрироваться на наиболее значимых направлениях обновления параметров. В свою очередь, PiSSA использует верхние главные компоненты, акцентируя внимание на направлениях, в которых наблюдается наибольшая дисперсия данных. Оба подхода направлены на улучшение адаптации модели к новым задачам за счет оптимального выбора начальных значений весов адаптеров, что позволяет сократить время обучения и повысить итоговую производительность.
Метод DoRA расширяет возможности LoRA путем раздельного обучения обновлений величины и направления весов адаптера. В стандартной LoRA, адаптер изменяет веса модели, комбинируя величину и направление изменения в одном векторе. DoRA, напротив, обучает отдельные векторы для величины и направления, что позволяет более гибко адаптировать модель к новым задачам. Раздельное обучение позволяет модели независимо регулировать, насколько сильно и в каком направлении изменять исходные веса, потенциально улучшая производительность и обобщающую способность, особенно в задачах, требующих тонкой настройки и адаптации к различным условиям.
Экспериментальные исследования подтверждают эффективность LoRA в различных задачах. В области математического рассуждения LoRA демонстрирует хорошие результаты на наборах данных MATH, GSM8K и MetaMathQA, решая задачи разной сложности. В сфере генерации кода LoRA успешно применяется для наборов данных HumanEval, MBPP и CodeFeedback, демонстрируя способность генерировать корректный и функциональный код. Результаты показывают, что LoRA является эффективным методом адаптации больших языковых моделей для специализированных задач, требующих как логических рассуждений, так и навыков программирования.
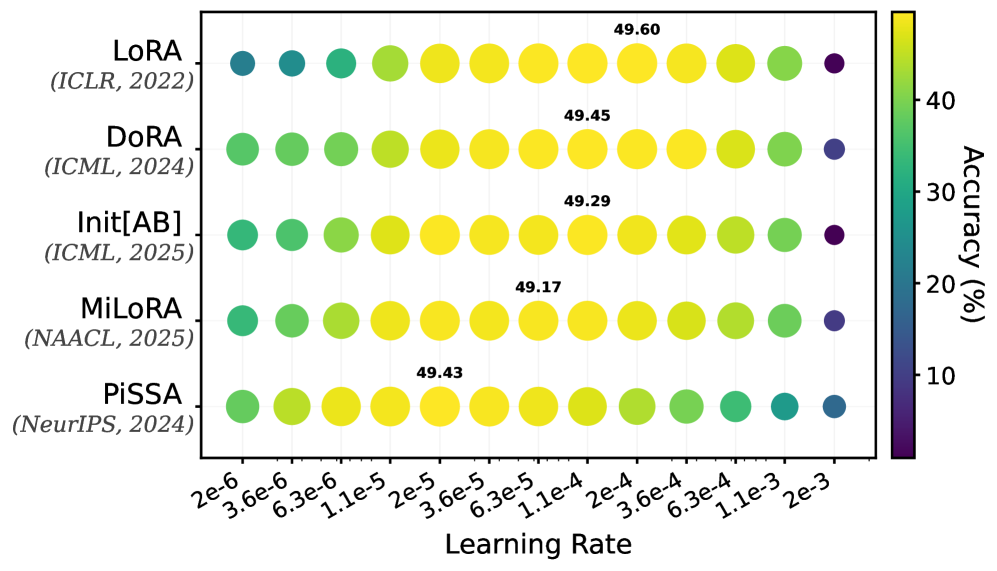
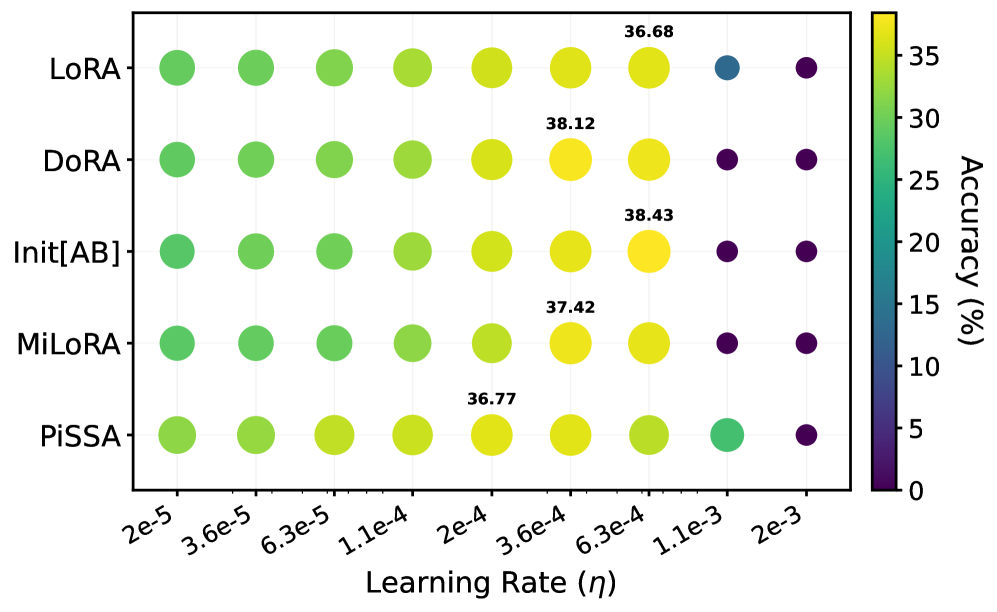
Несмотря на появление новых вариантов LoRA, таких как MiLoRA, PiSSA и DoRA, разница в производительности между ними оказалась незначительной. Эксперименты на моделях Gemma и Llama показали, что средняя разница в точности при решении задач математического рассуждения составляет всего 0.52%, а при генерации кода — 1.75%. Данные результаты свидетельствуют о том, что при правильной настройке скорости обучения, все рассмотренные методы адаптации LoRA способны достигать сопоставимых уровней производительности.
Экспериментальные данные показывают, что максимальная разница в производительности между различными методами адаптации LoRA (включая MiLoRA, PiSSA, DoRA и стандартный LoRA) на модели Llama составляет всего 2.15% при оценке на различных задачах и при различных рангах адаптеров. Это указывает на то, что при корректной настройке скорости обучения (learning rate), все рассмотренные методы способны демонстрировать сопоставимые результаты. Таким образом, выбор конкретного метода инициализации LoRA не является критичным фактором, определяющим конечную производительность, при условии оптимизации гиперпараметров обучения.
Чувствительность к гиперпараметрам и перспективы развития
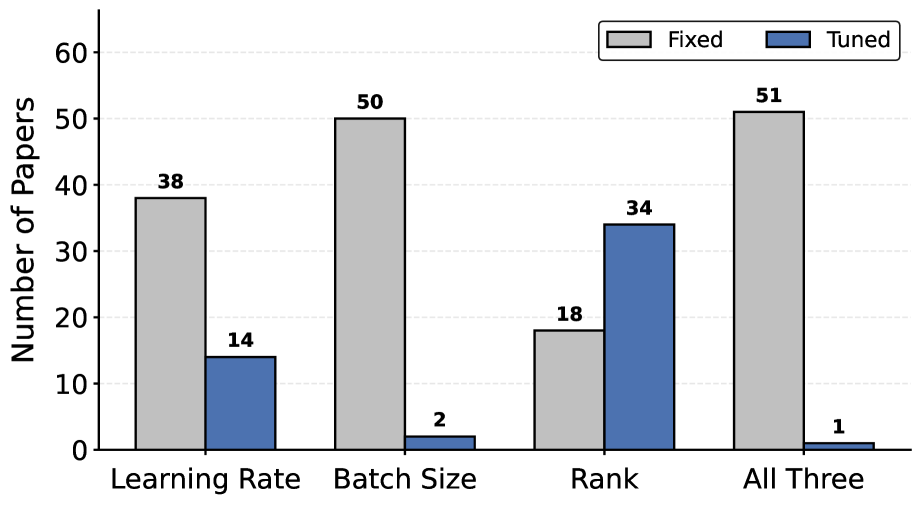
Эффективность метода LoRA, как показывает практика, напрямую зависит от тщательно подобранных гиперпараметров, в частности, ранга (Rank), скорости обучения (Learning Rate) и размера пакета (Batch Size). Некорректный выбор этих параметров может существенно снизить качество адаптации модели, даже при наличии большого объема обучающих данных. Например, слишком высокий ранг может привести к переобучению и увеличению вычислительных затрат, в то время как недостаточный ранг ограничивает способность модели к изучению сложных зависимостей. Скорость обучения, в свою очередь, требует тонкой настройки: слишком высокая скорость может привести к нестабильности процесса обучения, а слишком низкая — к замедлению сходимости и застреванию в локальных минимумах функции потерь. Размер пакета влияет на градиентные оценки и может влиять на скорость и стабильность обучения, требуя компромисса между точностью и вычислительной эффективностью. Таким образом, оптимизация гиперпараметров является критически важным этапом при использовании LoRA для достижения максимальной производительности.
Понимание взаимодействия между гиперпараметрами, такими как ранг, скорость обучения и размер пакета, и кривизной ландшафта функции потерь, определяемой гессианом, имеет решающее значение для достижения оптимальной адаптации модели. Гессиан, представляющий собой матрицу вторых производных, позволяет оценить локальную кривизну и, следовательно, скорость и стабильность сходимости алгоритма. В областях с высокой кривизной, характеризующихся большими собственными значениями гессиана, необходимо использовать меньшие скорости обучения для предотвращения расходимости. И наоборот, в плоских областях более высокие скорости обучения могут ускорить сходимость. Эффективная настройка гиперпараметров требует учета этой взаимосвязи и адаптации параметров обучения к конкретным характеристикам ландшафта потерь, что позволяет максимизировать производительность модели и обеспечить стабильное обучение. Анализ гессиана предоставляет ценную информацию для разработки более эффективных стратегий оптимизации и улучшения общей эффективности адаптации моделей.
Исследования показывают, что алгоритм PiSSA демонстрирует значительно большее максимальное собственное значение гессиана по сравнению с другими методами оптимизации. Это ключевое отличие объясняет, почему PiSSA способен эффективно обучаться даже при использовании более низких скоростей обучения. Гессиан, представляющий собой матрицу вторых производных функции потерь, отражает кривизну ландшафта потерь. Более высокое максимальное собственное значение указывает на более выраженную кривизну в определенном направлении, что позволяет PiSSA быстрее и точнее находить минимум функции потерь, избегая колебаний и перерегулирования, характерных для методов, требующих более высоких скоростей обучения для преодоления плоских участков ландшафта потерь. Таким образом, способность PiSSA эффективно использовать низкие скорости обучения является прямым следствием его уникальных свойств, связанных со структурой гессиана.
Перспективные исследования в области адаптации больших языковых моделей должны быть сосредоточены на автоматизированной настройке гиперпараметров и адаптивных стратегиях инициализации. Вместо ручного подбора параметров, алгоритмы автоматической оптимизации позволят эффективно находить оптимальные значения для различных задач и наборов данных. Особый интерес представляют методы, способные динамически адаптировать процесс инициализации модели, учитывая специфику решаемой задачи и характеристики данных. Такой подход позволит значительно повысить эффективность обучения и обобщающую способность моделей, снизив потребность в ручной настройке и обеспечивая более устойчивые результаты в различных сценариях применения.
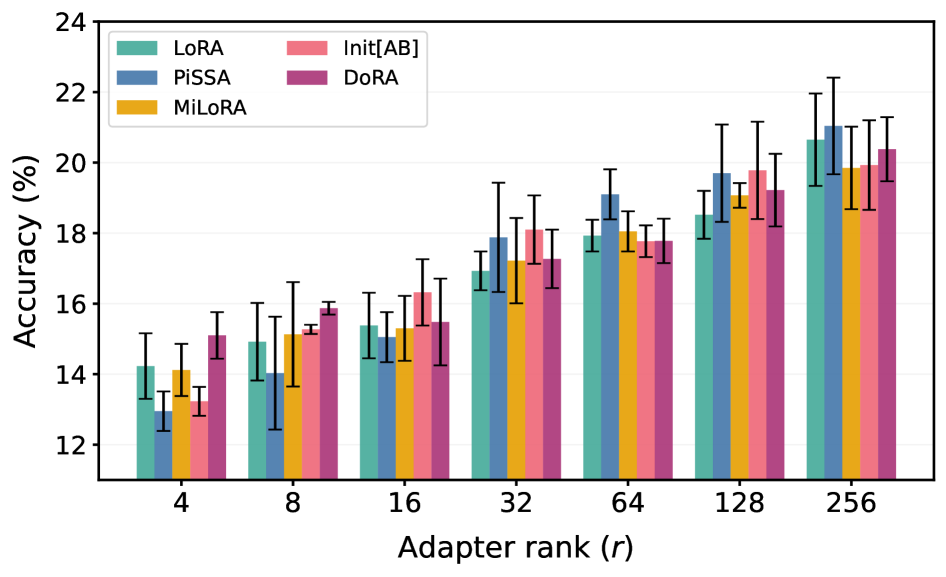
Исследование показывает, что в погоне за новыми методами адаптации больших языковых моделей, часто упускается из виду банальная оптимизация скорости обучения. Авторы работы убедительно демонстрируют, что правильно настроенный «ванильный» LoRA может достигать сопоставимых результатов с более сложными вариантами. Это подтверждает старую истину: элегантная теория бессильна перед суровой реальностью продакшена. Как однажды заметил Андрей Колмогоров: «Математика — это искусство делать из ничего, что-то». Здесь же, из простого алгоритма, при правильной настройке, можно получить результат не хуже, чем от более изощренных методов. Важно помнить, что снижение вычислительных издержек и упрощение архитектуры часто оказываются важнее, чем бесконечное усложнение.
Куда же мы катимся?
Статья, как водится, показала, что многие из этих модных «LoRA-вариаций» — всего лишь способ потратить больше вычислительных ресурсов, добиваясь той же самой производительности, что и от обычной LoRA, если, конечно, уделить внимание настройке скорости обучения. Не то, чтобы это было неожиданностью. Если система стабильно падает, значит, она хотя бы последовательна. И, честно говоря, в погоне за «state-of-the-art» часто забывают о банальном, но важном — о правильной настройке параметров. Всё это напоминает попытки улучшить телегу, прикручивая к ней реактивный двигатель — вроде бы технологично, но не факт, что быстрее.
Не решены, как и прежде, вопросы обобщения. Каждый новый датасет — это новая головная боль. Адаптеры, как и любые другие методы, склонны к переобучению, и, вероятно, будущее за ещё более сложными механизмами регуляризации, или, что более вероятно, за просто огромными датасетами, которые поглотят все проблемы. Ведь, в конце концов, мы не пишем код — мы просто оставляем комментарии будущим археологам, надеясь, что они поймут, зачем мы это сделали.
Вместо того, чтобы изобретать новые способы «эффективной адаптации», возможно, стоит задуматься о фундаментальных ограничениях этих моделей. Неужели действительно существует «универсальный» адаптер? Или мы просто обречены на вечное переобучение и бесконечную настройку скорости обучения? И, главное, кто-нибудь вспомнит об этом через год, когда появится новая «революционная» архитектура?
Оригинал статьи: https://arxiv.org/pdf/2602.04998.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Bibby AI: Новый помощник для исследователей в LaTeX
- Графы и действия: новый подход к планированию для роботов
- Квантовые хроники: Последние новости в области квантовых исследований и разработки.
- Стиль сквозь века: математика искусства
- Самообучающийся Автопилот: Новый Подход к Безопасности и Адаптации
- Управление Формой: Новый Метод Контроля 3D-Генерации
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
2026-02-07 00:43