Автор: Денис Аветисян
В новой статье рассматриваются возможности и ограничения использования вычислений со смешанной точностью в задачах линейной алгебры и матричных вычислений.
Анализ ошибок и методы итерационного уточнения для повышения производительности и сохранения точности в вычислениях с переменной точностью.
Несмотря на растущую вычислительную мощность, достижение оптимальной производительности и точности в матричных вычислениях остается сложной задачей. В работе, посвященной ‘Balancing Inexactness in Mixed Precision Matrix Computations’, исследуется возможность использования вычислений со смешанной точностью для повышения эффективности, особенно в условиях, когда уже присутствуют другие источники погрешности, такие как ошибки дискретизации или аппроксимации. Предлагается подход, заключающийся в балансировке различных источников неточности для минимизации влияния на общую точность вычислений. Каким образом анализ взаимодействия этих погрешностей может привести к разработке более эффективных и надежных алгоритмов численной линейной алгебры?
Основы численных ошибок в науке
Многие научные приложения, от моделирования климата до проектирования самолетов и анализа медицинских изображений, опираются на методы численной линейной алгебры для получения приближенных решений непрерывных задач. Невозможность точного аналитического решения, вызванная сложностью уравнений или отсутствием закрытой формы, вынуждает исследователей обращаться к численным методам. Эти методы, такие как решение систем линейных уравнений Ax = b, собственные значения и собственные векторы матриц, и разложение матриц на составляющие, позволяют получать практические, хоть и не абсолютно точные, результаты. В результате, численная линейная алгебра является краеугольным камнем современной науки и техники, предоставляя инструменты для решения задач, которые в противном случае оставались бы неразрешимыми.
Любые численные методы, используемые в научных вычислениях, неизбежно вносят погрешности. Эти погрешности возникают на различных этапах решения задачи. Изначальная математическая модель, как упрощение реального явления, сама по себе является источником приближений. Далее, процесс дискретизации — переход от непрерывной задачи к дискретной, решаемой на компьютере — вносит дополнительную погрешность, связанную с выбором шага сетки или других параметров. Наконец, конкретный численный алгоритм, используемый для решения дискретной задачи, также вносит свои погрешности, зависящие от его свойств и реализации. Таким образом, понимание источников этих ошибок, таких как O(h) для погрешности дискретизации, и методов их оценки и минимизации, является фундаментальным для получения достоверных и надежных научных результатов.
Обеспечение надёжности и достоверности научных результатов напрямую зависит от понимания и контроля погрешностей, неизбежно возникающих в процессе численного моделирования. Несмотря на мощь современных вычислительных инструментов, любое приближённое решение, полученное с помощью численных методов, содержит ошибки, обусловленные как упрощениями в исходной модели, так и особенностями используемых алгоритмов. Пренебрежение этими погрешностями может привести к искажению выводов, неверной интерпретации данных и, в конечном итоге, к ошибочным научным заключениям. Поэтому, тщательный анализ источников ошибок, разработка методов их оценки и минимизации, а также верификация полученных результатов являются неотъемлемой частью любого научного исследования, использующего численные методы. В частности, важно учитывать, что даже небольшие погрешности на начальных этапах вычислений могут экспоненциально возрастать, приводя к существенным отклонениям в финальных результатах, особенно в задачах, чувствительных к начальным условиям.
Конечная точность и реальность ошибок округления
Компьютеры представляют числа, используя арифметику конечной точности, в частности, стандарт IEEE 754 для чисел с плавающей точкой. Этот стандарт определяет форматы представления чисел с ограниченным количеством битов для мантиссы и экспоненты. Вследствие этого, не все вещественные числа могут быть представлены абсолютно точно; любое число, которое не может быть представлено точно, округляется до ближайшего представимого числа. Это округление и является причиной возникновения погрешности округления. Например, представление числа π в формате double precision (64 бита) дает приближенное значение, отличное от его истинного значения. Данная погрешность округления является неотъемлемой частью вычислений на компьютерах и должна учитываться при анализе результатов.
При использовании вычислений с плавающей точкой, погрешность округления, обусловленная конечной точностью представления чисел (примерно 10^{-{16}} для чисел двойной точности), не является единичной ошибкой, а накапливается с каждой арифметической операцией. Это означает, что даже при выполнении большого количества операций, кажущихся простыми, итоговый результат может существенно отличаться от теоретически верного значения. Накопление погрешности особенно заметно в задачах, требующих высокой точности, таких как решение систем уравнений или долгосрочное моделирование, где даже небольшие ошибки на каждой итерации могут привести к значительным отклонениям в конечном итоге. Поэтому, при разработке численных алгоритмов необходимо учитывать и минимизировать влияние накапливающейся погрешности округления.
Чувствительность вычислений к ошибке округления часто оценивается с помощью числа обусловленности (condition number). Это число характеризует, насколько сильно относительная ошибка в исходных данных влияет на относительную ошибку в результате вычислений. Высокое число обусловленности указывает на то, что даже небольшие ошибки округления могут привести к значительным отклонениям в конечном результате. Формально, число обусловленности cond(f) определяется как предел отношения \frac{\|\delta x\|}{\|\delta y\|} , где \delta x — небольшое изменение входных данных, а \delta y — соответствующее изменение результата вычислений. Низкое число обусловленности указывает на устойчивость вычислений, в то время как высокое число обусловленности указывает на их неустойчивость к ошибкам округления.
Ускорение решений: Итеративное уточнение и предварительная обработка
Итеративное уточнение (Iterative Refinement) представляет собой эффективный метод повышения точности решения систем линейных уравнений. Данный подход заключается в последовательном улучшении приближенного решения путем вычисления невязки — разницы между правым и левым членом уравнения после подстановки текущего приближения. Затем, используя решение возмущенной системы, полученной с использованием этой невязки, выполняется коррекция приближенного решения. Повторение этой процедуры позволяет итеративно приближаться к точному решению системы Ax = b, даже в случаях, когда прямые методы могут быть неэффективными или численно нестабильными. Метод особенно полезен при решении больших и разреженных систем, возникающих в различных областях науки и техники.
Методы, такие как разреженные приближенные обратные предварители (Sparse Approximate Inverse Preconditioners, SPAI) и рандомизированное приближение Нюстрёма (Randomized Nyström Approximation), существенно ускоряют сходимость итерационного уточнения. SPAI, создавая приближенную обратную матрицу, снижает число итераций, необходимых для достижения заданной точности решения системы линейных уравнений. Рандомизированное приближение Нюстрёма, в свою очередь, эффективно уменьшает размерность задачи, что также приводит к ускорению сходимости и снижению вычислительных затрат, особенно для больших разреженных систем. Оба подхода позволяют значительно повысить производительность итерационного уточнения по сравнению с его применением без предварительной обработки.
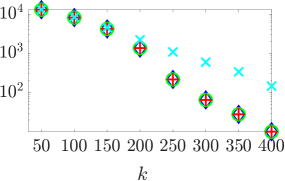
Итеративное уточнение на основе GMRES (Generalized Minimal Residual Method) демонстрирует высокую эффективность при решении сложных линейных систем уравнений. В частности, применение предварительного обусловливания с использованием Sparse Approximate Inverse (SPAI) значительно ускоряет сходимость алгоритма. Результаты, представленные на Рисунке 1, наглядно показывают прирост производительности, достигаемый при использовании SPAI предварительного обусловливания, что позволяет сократить количество итераций и общее время вычислений для достижения заданной точности решения Ax = b.
Смешанная точность для производительности и точности
Вычислительная техника со смешанной точностью представляет собой подход, позволяющий оптимизировать баланс между скоростью вычислений и их точностью. Вместо использования единого формата чисел с плавающей точкой, система динамически адаптирует точность в зависимости от требований конкретной задачи. Это достигается за счет использования форматов пониженной точности, таких как одинарная точность (float32) или полуточность (float16), для операций, где незначительная потеря точности допустима, и сохранением высокой точности (double precision) для критически важных вычислений. Такой подход позволяет значительно ускорить вычисления, поскольку операции с числами пониженной точности требуют меньше вычислительных ресурсов и памяти, одновременно минимизируя влияние на конечный результат благодаря адаптивному выбору точности.
Использование вычислений со смешанной точностью позволяет добиться существенного прироста производительности за счет применения форматов пониженной точности, когда это допустимо. В частности, при решении задач на бенчмарке HPL-MxP, удалось достичь скорости в 16.7 экзафлопс, что более чем в девять раз превышает показатель в 1.8 экзафлопс, полученный при использовании стандартного бенчмарка HPL. Такое увеличение производительности обусловлено снижением требований к памяти и ускорением арифметических операций, что особенно важно для решения масштабных вычислительных задач в различных областях науки и техники. Оптимизация точности вычислений позволяет находить баланс между скоростью и надежностью результатов, открывая новые возможности для эффективного использования вычислительных ресурсов.
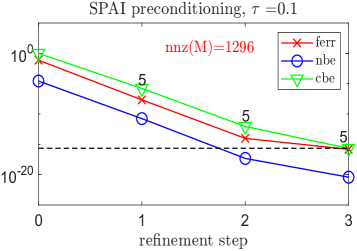
Для оценки производительности решателей, использующих смешанную точность, разработан эталонный тест HPL-MxP. Он позволяет стандартизировать измерения и сравнивать эффективность различных подходов. Важно отметить, что оптимизация хранения данных, например, с помощью иерархических матричных приближений, может значительно снизить потребность в памяти. График, представленный на Рисунке 4, демонстрирует, что величина экономии памяти напрямую зависит от выбранного значения ε (эпсилон), определяющего допустимую погрешность приближения. Более высокие значения ε приводят к большей экономии памяти, однако и к потенциальному снижению точности вычислений, что требует тщательного баланса между скоростью, объемом памяти и требуемой точностью результата.
Контроль ошибок и валидация: обеспечение надёжных результатов
Прямой и обратный анализ ошибок предоставляют строгие математические методы для установления границ и характеристики погрешностей в численных вычислениях. Вместо того чтобы просто полагаться на эмпирические наблюдения, эти подходы позволяют оценить, как ошибки округления и другие неточности распространяются на протяжении всего процесса вычисления. Прямой анализ ошибок фокусируется на оценке влияния ошибок ввода на конечный результат, в то время как обратный анализ рассматривает, насколько сильно должны быть изменены входные данные, чтобы привести к наблюдаемой ошибке в результате. Такой подход позволяет определить устойчивость алгоритма — его способность выдавать разумные результаты даже при наличии небольших погрешностей во входных данных. Использование этих методов критически важно в таких областях, как моделирование климата, инженерный анализ и финансовое моделирование, где точность и надежность результатов имеют первостепенное значение, и даже незначительные ошибки могут привести к серьезным последствиям. ε — часто используемое обозначение для машинной точности, играющей ключевую роль в этих расчетах.
Тщательный анализ распространения ошибок позволяет создавать алгоритмы, демонстрирующие высокую устойчивость и надежность. В процессе разработки, учет того, как погрешности накапливаются и трансформируются при выполнении операций, является ключевым фактором. Такой подход позволяет минимизировать влияние случайных или систематических ошибок на конечный результат вычислений, особенно в сложных моделях и симуляциях. Использование методов, учитывающих чувствительность алгоритма к погрешностям входных данных и промежуточных вычислений, способствует созданию более точных и предсказуемых результатов, что критически важно для научных исследований и инженерных приложений. ε — небольшое отклонение на входе может привести к значительному изменению результата, поэтому методы контроля ошибок необходимы для обеспечения достоверности полученных данных.
По мере того, как научные задачи становятся все более сложными и требуют обработки огромных объемов данных, дальнейшие исследования в области эффективных матричных представлений и методов контроля ошибок приобретают жизненно важное значение. Разработка новых алгоритмов и форматов хранения, позволяющих минимизировать вычислительные затраты и повысить точность результатов, является ключевой задачей современной вычислительной науки. Особое внимание уделяется созданию устойчивых к ошибкам методов, способных корректно обрабатывать неточности, возникающие из-за ограниченной точности машинных вычислений или неполноты исходных данных. A \cdot x = b Решение систем линейных уравнений, являющееся основой многих научных расчетов, требует постоянного совершенствования алгоритмов и техник, позволяющих получать надежные и достоверные результаты даже при работе с плохо обусловленными матрицами или зашумленными данными. Успех в этой области позволит решать задачи, которые ранее были недоступны из-за вычислительных ограничений, открывая новые горизонты в различных областях науки и техники.
Исследование, представленное в данной работе, акцентирует внимание на необходимости взвешенного подхода к вычислениям со смешанной точностью. В контексте итеративного уточнения и работы с иерархическими матрицами, неизбежно возникают погрешности, обусловленные как аппаратными ограничениями, так и особенностями алгоритмов. В этой связи, замечание Петра Капицы: «В конечном счете, все системы стареют — вопрос лишь в том, делают ли они это достойно» представляется удивительно проницательным. Подобно стареющей системе, вычислительный процесс подвержен накоплению ошибок, и задача исследователя — обеспечить его «достойное» завершение, сохранив приемлемый уровень точности при повышении производительности. Баланс между скоростью и точностью — ключевой аспект, определяющий долговечность и надежность численных методов.
Куда же дальше?
Представленная работа, подобно любому коммиту в летописи вычислений, фиксирует состояние дел на определенный момент. Однако, в отличие от безупречного кода, математические системы неизбежно несут в себе погрешности. Стремление к балансу между точностью и скородействием в вычислениях с использованием смешанной точности — это не победа над неточностью, а скорее её осознанное использование. Каждая версия алгоритма — это глава в истории приближений, а задержка с исправлением ошибок — своего рода налог на амбиции, на желание охватить большее.
Остается открытым вопрос о систематической оценке влияния различных источников ошибок, особенно в контексте иерархических матриц и итеративного уточнения. Необходимо разработать более строгие метрики, учитывающие не только абсолютную, но и относительную погрешность, а также её распространение в сложных вычислительных схемах. Важным направлением представляется исследование адаптивных стратегий смешанной точности, способных динамически подстраиваться под характеристики конкретной задачи.
В конечном счете, задача состоит не в создании идеального численного алгоритма — это утопия. Задача — в разработке систем, которые стареют достойно, сохраняя свою функциональность и адекватность в меняющейся среде вычислительных ресурсов. Время — не метрика для оптимизации, а среда, в которой эти системы существуют и эволюционируют.
Оригинал статьи: https://arxiv.org/pdf/2602.04348.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Внимание на максимум: обучение моделей видеть и понимать
- Квантовые маршруты и гравитационные сенсоры: немного иронии от физика
- Квантовые состояния под давлением: сжатие данных для новых алгоритмов
- Искусственный интеллект на производстве: иллюзии автономии
- Квантовый Шум: Не Враг, а Возможность?
- Искусственный интеллект под контролем: новый подход к правовому регулированию
2026-02-05 22:02