Автор: Денис Аветисян
Исследователи предлагают переосмыслить структуру feed-forward сетей в трансформерах, повышая эффективность и позволяя сосредоточиться на механизме внимания.
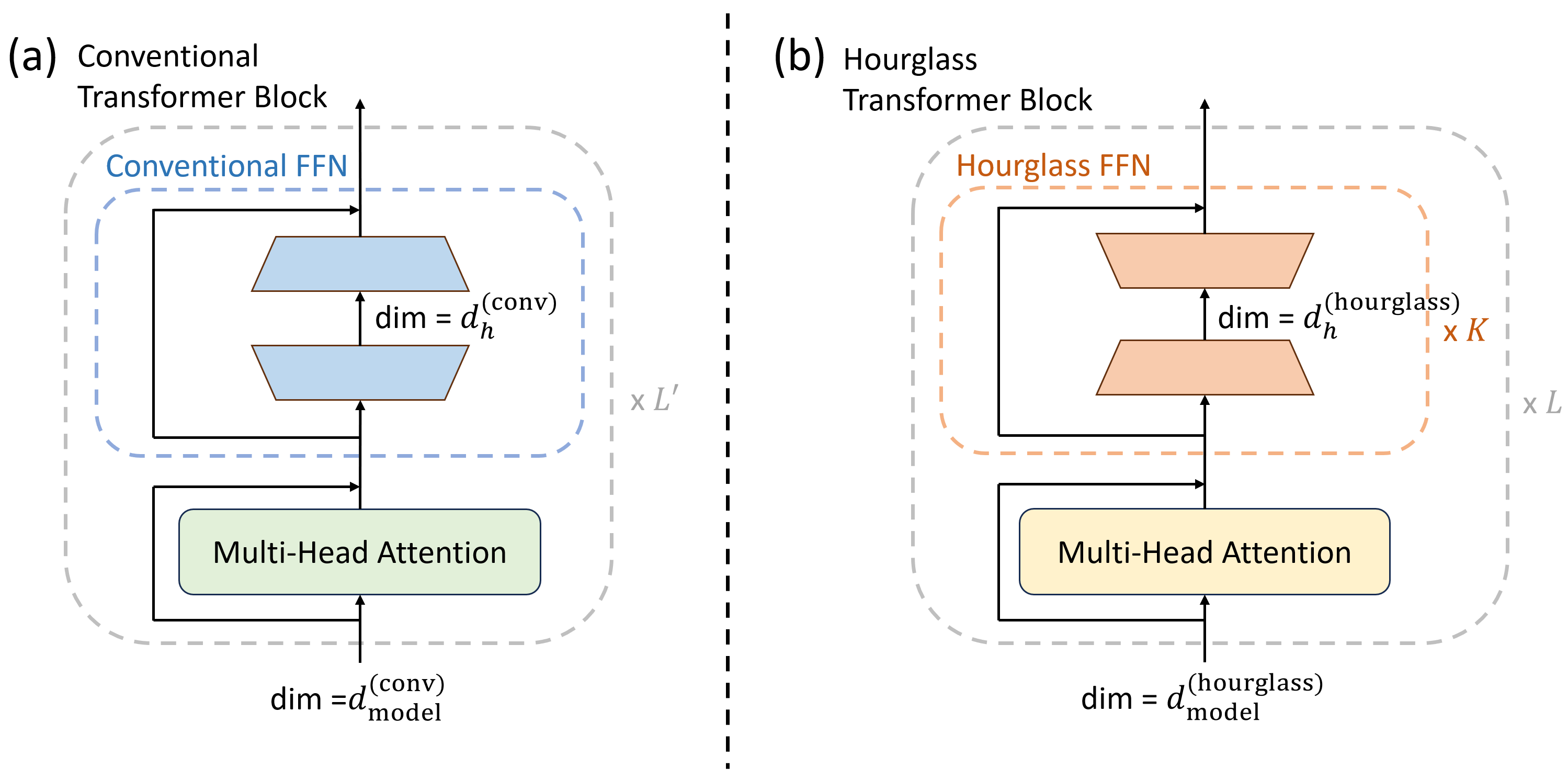
В статье рассматривается замена традиционной узко-широко-узкой сети на более эффективную ‘песочные часы’ для улучшения масштабируемости и снижения вычислительных затрат.
В архитектурах современных языковых моделей-трансформеров устоялась практика использования многослойных нейронных сетей типа «узкий-широкий-узкий» в качестве feed-forward блоков. В работе ‘Revisiting the Shape Convention of Transformer Language Models’ предпринята попытка переосмыслить эту традиционную структуру, исследуя преимущества «песочных часов» (hourglass) — более глубоких и компактных feed-forward сетей, основанных на остаточных связях. Эксперименты показали, что замена стандартных FFN на предложенную архитектуру позволяет достичь сопоставимой, а в ряде случаев и превосходящей производительности, при этом снижая общее количество параметров и открывая возможности для более эффективного распределения вычислительных ресурсов. Не приведет ли это к пересмотру устоявшихся принципов балансировки между механизмами внимания и feed-forward сетями в будущих поколениях языковых моделей?
Трансформеры: От возможностей к ограничениям
Архитектура Transformer в настоящее время является фундаментальным элементом современных систем обработки естественного языка, демонстрируя передовые результаты в широком спектре задач. От машинного перевода и генерации текста до анализа тональности и ответов на вопросы — модели, основанные на Transformer, последовательно превосходят предыдущие подходы. Ключевым фактором успеха является механизм внимания, позволяющий модели фокусироваться на наиболее релевантных частях входных данных при обработке информации. Эта способность к контекстуализации значительно улучшает понимание и генерацию языка, что делает Transformer краеугольным камнем многих современных приложений в области искусственного интеллекта. Благодаря своей гибкости и масштабируемости, архитектура Transformer продолжает стимулировать инновации и расширять границы возможного в сфере обработки естественного языка.
Несмотря на впечатляющие успехи, увеличение глубины и масштаба архитектуры Transformer сопряжено со значительными вычислительными затратами. Каждое последующее увеличение количества слоев и параметров не всегда приводит к пропорциональному улучшению производительности, а часто демонстрирует эффект убывающей отдачи. Это связано с тем, что сложность вычислений растет квадратично по отношению к длине входной последовательности, что делает обработку длинных текстов крайне ресурсоемкой. Более того, модели с огромным количеством параметров могут страдать от переобучения и требовать колоссальных объемов данных для эффективной тренировки, что делает их применение на практике затруднительным и дорогостоящим. Таким образом, дальнейшее развитие архитектуры Transformer требует поиска инновационных подходов, позволяющих повысить эффективность использования параметров и снизить вычислительную сложность, а не простого увеличения масштаба.
Современные модели, основанные на архитектуре Transformer, часто демонстрируют ограниченную способность эффективно использовать постоянно растущее число параметров. Несмотря на значительные вычислительные ресурсы, направленные на увеличение масштаба, наблюдается тенденция к уменьшению прироста производительности. Это указывает на то, что простое увеличение размера модели не является устойчивым путем к дальнейшему прогрессу в области обработки естественного языка. Вместо этого, исследования все больше фокусируются на разработке инновационных архитектурных решений, которые позволят более рационально использовать существующие параметры и открыть новые возможности для улучшения качества и эффективности моделей. Поиск таких решений включает в себя изучение альтернативных механизмов внимания, оптимизацию структур связей между слоями и разработку новых методов обучения, направленных на повышение способности модели к обобщению и адаптации.
«Песочные часы»: Новая парадигма в дизайне FFN
В отличие от традиционной архитектуры Feed-Forward Network (FFN) с узким-широким-узким строением, мы предлагаем Hourglass FFN, характеризующуюся широким-узким-широким дизайном. Ключевым отличием является использование нескольких под-MLP (Multi-Layer Perceptron), последовательно расположенных в узкой части сети. Такая структура позволяет увеличить выразительность модели за счет более сложной иерархической трансформации признаков, обеспечивая расширение пропускной способности информации по сравнению с классическими FFN слоями. Широкие слои выполняют роль начальной и финальной проекций, а узкий слой с под-MLP обеспечивает более детальную обработку и извлечение признаков.
Конструкция Hourglass FFN направлена на повышение эффективности потока информации и расширение репрезентативной способности за счет стимулирования более тонкой и иерархической трансформации признаков. В отличие от традиционных моделей, где происходит сужение, а затем расширение представления, Hourglass FFN использует расширение, сужение, и снова расширение. Это позволяет модели создавать более сложные и абстрактные представления данных, обрабатывая информацию на различных уровнях детализации и иерархии. Такая структура способствует лучшему извлечению и агрегированию признаков, что в свою очередь улучшает способность модели к обобщению и решению сложных задач.
Архитектура Hourglass FFN использует остаточные соединения (residual connections) и функцию активации SwiGLU для обеспечения стабильного распространения градиентов при обучении глубоких нейронных сетей. Остаточные соединения позволяют градиентам обходить слои, что снижает проблему затухания градиента, особенно в глубоких сетях. SwiGLU, являясь вариантом функции активации GELU, обеспечивает более эффективный поток градиентов и способствует улучшению нелинейных преобразований признаков. Комбинация этих двух элементов позволяет создавать более глубокие и производительные модели, эффективно обучаемые на больших объемах данных.
Эмпирическое подтверждение: Прирост производительности и эффективности
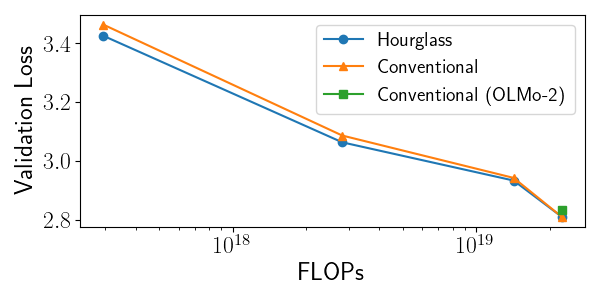
Экспериментальные данные демонстрируют стабильное превосходство Hourglass FFN над традиционной архитектурой узкий-широкий-узкий FFN в различных моделях и на различных наборах данных. В частности, модель с 1 миллиардом параметров (1B) достигла показателя валидационной перплексии в 20.082, что сопоставимо с результатами сильных базовых моделей. Данный результат указывает на повышенную эффективность Hourglass FFN в задачах языкового моделирования и позволяет достигать сопоставимой производительности с меньшим количеством вычислительных ресурсов.
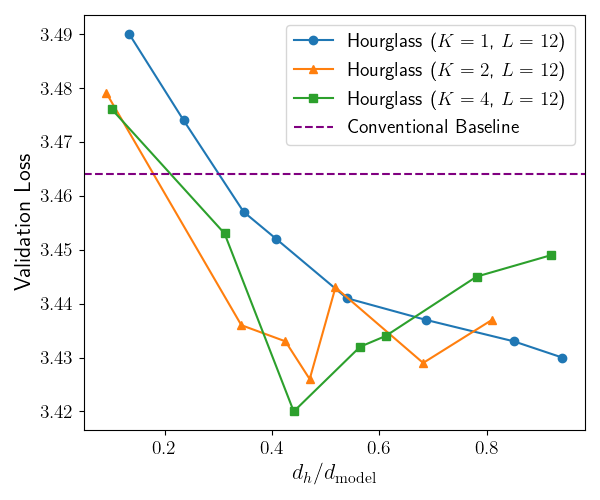
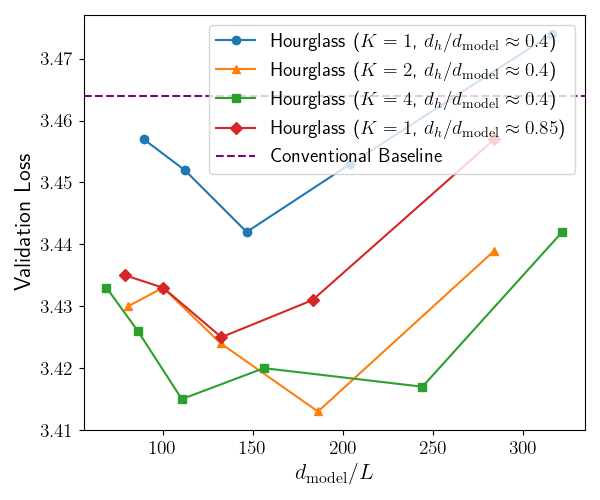
Экспериментальные данные показали U-образную зависимость между шириной и глубиной модели. Анализ продемонстрировал, что существует оптимальный баланс между этими параметрами, позволяющий максимизировать производительность. Отклонение от этого оптимального соотношения, как в сторону увеличения ширины при фиксированной глубине, так и наоборот, приводит к ухудшению результатов. Наблюдаемая зависимость указывает на необходимость тщательной настройки архитектуры модели для достижения наилучшей эффективности и снижения вычислительных затрат.
При использовании модели с 113 миллионами параметров, Hourglass FFN достигла показателя валидационной перплексии 32.788. Эксперименты показали распределение параметров, при котором на механизмы внимания выделялось 649 миллионов параметров, а на FFN — 425 миллионов. Такое распределение демонстрирует более эффективное использование параметров по сравнению с традиционными подходами, позволяя достичь сопоставимых или лучших результатов при меньшем общем количестве параметров модели.
Эксперименты показали, что архитектура Hourglass FFN обеспечивает более эффективное распределение параметров, достигая сопоставимых или превосходящих результатов с меньшим количеством параметров по сравнению с традиционными моделями. В частности, на модели с 906 миллионами параметров зафиксировано приблизительное снижение потерь при валидации на 5% относительно базовой модели, что свидетельствует о повышенной эффективности использования параметров и потенциале для создания более компактных и производительных языковых моделей.
Влияние и перспективы для эффективной обработки естественного языка
Архитектура Hourglass FFN представляет собой отход от доминирующей тенденции в области обработки естественного языка — простого увеличения размеров моделей. Вместо этого, она предлагает альтернативный путь к повышению эффективности и устойчивости, акцентируя внимание на более рациональном использовании существующих параметров. Вместо слепого наращивания масштаба, Hourglass FFN перераспределяет вычислительные ресурсы, оптимизируя взаимодействие между слоями нейронной сети. Такой подход позволяет достичь сравнимых, а в некоторых случаях и превосходящих результатов, при значительно меньших затратах на обучение и развертывание, открывая перспективы для создания более доступных и экологичных моделей, способных решать сложные задачи в области лингвистики и искусственного интеллекта.
Исследования показали, что перераспределение параметров в архитектуре нейронных сетей, а именно сокращение числа параметров в слое Feed-Forward Network (FFN) и увеличение их числа в механизме внимания, может значительно повысить эффективность обработки естественного языка. Такой подход позволяет модели более эффективно концентрироваться на релевантной информации, улучшая ее способность к пониманию и генерации текста. Полученные результаты указывают на то, что не всегда увеличение общего числа параметров является оптимальным решением; стратегическое их перераспределение между различными компонентами модели может привести к более высокой производительности при сохранении или даже снижении вычислительных затрат. Это открывает новые перспективы для разработки более эффективных и устойчивых моделей обработки естественного языка, особенно в условиях ограниченных ресурсов.
Исследования продемонстрировали, что разработанная архитектура Hourglass FFN превосходит широко используемую модель с открытым исходным кодом OLMo-2 по ряду ключевых метрик. Этот результат указывает на значительный потенциал Hourglass FFN как жизнеспособной и эффективной альтернативы для дальнейших исследований в области обработки естественного языка. Преимущество в производительности, достигнутое при сравнимом количестве параметров, позволяет предположить, что данная архитектура может стать основой для создания более устойчивых и экономичных языковых моделей, пригодных для развертывания в различных приложениях, где важны как точность, так и эффективность использования ресурсов.
Исследование демонстрирует, что архитектура сети определяет её поведение, и предложенная «песочные часы» форма feed-forward сети является ярким примером этого принципа. Авторы подчеркивают, что эффективное масштабирование достигается не за счет увеличения серверной мощности, а благодаря ясности идей, лежащих в основе структуры модели. Тим Бернерс-Ли однажды заметил: «Веб — это не просто набор страниц, соединенных гиперссылками, а способ думать.» Эта мысль перекликается с текущей работой, показывая, что продуманная архитектура, подобно четко структурированному веб-пространству, позволяет системе функционировать более эффективно и раскрывать свой потенциал. Уделяя больше внимания механизму внимания, а не просто увеличению числа параметров, авторы создают систему, которая может более эффективно обрабатывать информацию, подобно тому, как хорошо организованный веб-сайт позволяет пользователям быстро находить нужные ресурсы.
Куда Далее?
Предложенная модификация архитектуры сети, замена традиционной “узко-широко-узкой” структуры на более элегантную “песочные часы”, не является, конечно, панацеей. Скорее, это приглашение к переосмыслению фундаментальных принципов масштабирования языковых моделей. Упор на эффективность параметров в слоях Feed-Forward Network, освобождающий ресурсы для механизма внимания, поднимает вопрос: что мы на самом деле оптимизируем? Простое увеличение числа параметров или же улучшение способности модели к обобщению и пониманию?
Очевидным направлением для дальнейших исследований представляется изучение влияния формы Feed-Forward Network на различные аспекты обучения, такие как скорость сходимости, устойчивость к переобучению и способность к трансферному обучению. Важно понимать, что простота — это не минимализм, а четкое разграничение необходимого и случайного. Необходимо выяснить, существуют ли другие, возможно, более изящные, способы оптимизации архитектуры Transformer, которые позволят добиться еще большей эффективности.
Наконец, следует признать, что предложенная архитектура — это лишь один шаг на пути к созданию действительно интеллектуальных систем. Углубленное понимание взаимосвязи между структурой сети и ее функциональными возможностями, а также поиск новых способов интеграции различных механизмов внимания, представляются ключевыми задачами для будущего исследований в этой области.
Оригинал статьи: https://arxiv.org/pdf/2602.06471.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Переворот: От Теории к Реальности
- Искусственный интеллект на службе редких болезней
- Шум Теплового Релакса: Точное Моделирование для Квантовой Защиты
- Язык тела под присмотром ИИ: архитектура и гарантии
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Квантовые Забавы: От Алгоритмов к Чипам
- Самообучающиеся агенты: новый подход к автономным системам
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Наука, управляемая интеллектом: новая эра открытий
2026-02-09 18:15