Автор: Денис Аветисян
Исследователи предлагают эффективный метод улучшения производительности больших языковых моделей после обучения, используя синтетические данные, ориентированные на недостающие внутренние представления.
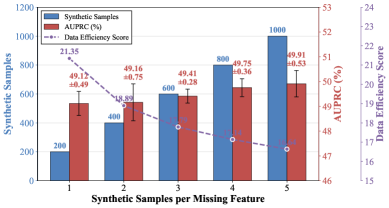
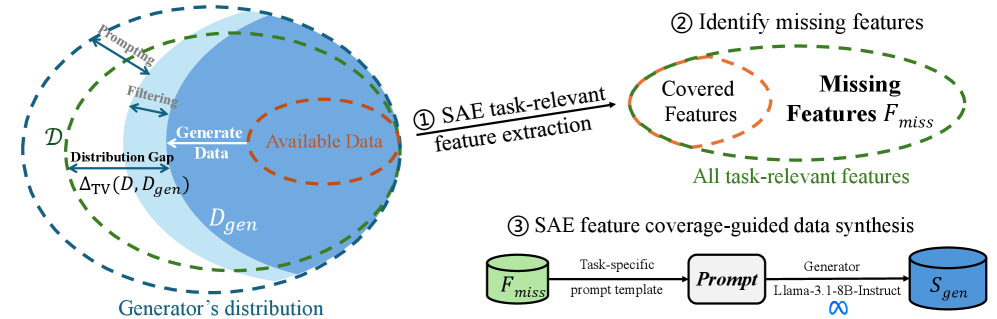
Предложенная методика FAC Synthesis использует разреженные автокодировщики для выявления и восполнения пробелов в покрытии признаков, повышая эффективность обучения и обобщения языковых моделей.
Несмотря на растущую мощность больших языковых моделей (LLM), обеспечение разнообразия данных для их постобучения остается сложной задачей. В работе ‘Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs’ предложен новый подход к оценке и синтезу данных, основанный на измерении покрытия признакового пространства моделей. Авторы демонстрируют, что предложенный метод FAC Synthesis, использующий разреженные автокодировщики для выявления недостающих признаков, позволяет эффективно улучшить как разнообразие данных, так и производительность LLM в различных задачах. Возможно ли, используя этот подход, создать более компактные и эффективные наборы данных для постобучения, снижая вычислительные затраты и повышая обобщающую способность моделей?
Пределы масштаба: вызовы синтеза данных
Крупномасштабные языковые модели демонстрируют впечатляющие результаты при обработке больших объемов данных, однако их способность точно следовать сложным инструкциям и обобщать информацию на незнакомых примерах зачастую ограничена. Несмотря на способность улавливать статистические закономерности в огромных корпусах текстов, модели испытывают трудности с пониманием нюансов языка и контекста, что приводит к ошибкам в ситуациях, требующих критического мышления или творческого подхода. Данное ограничение связано с тем, что модели, обученные на большом количестве данных, могут переобучаться и терять способность к адаптации к новым, непредсказуемым сценариям, что подчеркивает необходимость разработки более эффективных методов обучения и оценки, направленных на повышение обобщающей способности и надежности этих систем.
Традиционные методы синтеза данных, такие как равномерная выборка (Uniform Sampling), зачастую оказываются неэффективными при стремлении к созданию действительно устойчивых моделей. Суть проблемы заключается в неспособности этих методов адекватно охватить так называемый «длинный хвост» возможных входных данных — редкие, но критически важные сценарии, которые могут существенно повлиять на производительность модели в реальных условиях. Равномерная выборка, стремясь к равномерному распределению, игнорирует тот факт, что большинство реальных данных сосредоточено в узком диапазоне, оставляя «длинный хвост» недостаточно представленным. Это приводит к снижению робастности модели, ее склонности к ошибкам при обработке необычных или нетипичных запросов, и, в конечном итоге, к ухудшению общей надежности системы.
Разработанный подход FAC Synthesis демонстрирует значительное повышение эффективности в синтезе данных для обучения больших языковых моделей. В ходе исследований было установлено, что данная методика позволяет достичь сопоставимых результатов с передовым методом MAGPIE, используя при этом в 150 раз меньше синтетических примеров — всего 2000 вместо 300 000. Это существенное снижение потребности в данных открывает новые возможности для обучения моделей в условиях ограниченных ресурсов и позволяет значительно ускорить процесс разработки и адаптации языковых моделей к различным задачам. Полученные результаты подчеркивают потенциал FAC Synthesis как экономичного и эффективного инструмента для улучшения обобщающей способности и надежности больших языковых моделей.
Для полного раскрытия потенциала больших языковых моделей и достижения лучшего соответствия их поведения намерениям человека, крайне важна разработка более эффективных стратегий аугментации данных. Существующие методы часто оказываются неспособными охватить все разнообразие возможных входных данных, особенно так называемый «длинный хвост» редких, но важных сценариев. Совершенствование подходов к генерации синтетических данных позволит не только повысить устойчивость моделей к новым, ранее не встречавшимся ситуациям, но и улучшить их способность понимать и следовать сложным инструкциям. В конечном итоге, именно качественная и разнообразная тренировочная выборка станет ключевым фактором для создания действительно интеллектуальных и полезных языковых систем, способных решать широкий спектр задач и взаимодействовать с пользователями на качественно новом уровне.
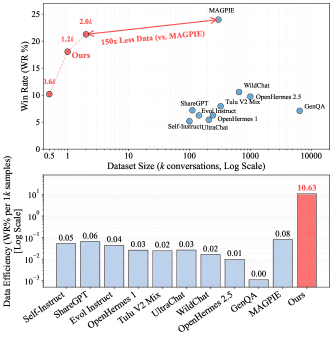
За пределами случайности: синтез данных, управляемый охватом
Синтез на основе FAC (Feature-Attribution Coverage) представляет собой перспективный подход к генерации данных, использующий метрики покрытия для выявления пробелов в обучающей выборке. Метод заключается в создании примеров, которые максимизируют FAC, то есть обеспечивают более полное представление важных для задачи признаков в данных. Это достигается путем анализа влияния различных признаков на предсказания модели и генерации данных, которые активируют ранее недостаточно охваченные комбинации признаков, что способствует повышению надежности и точности модели.
Синтез данных на основе Feature-Attribution Coverage (FAC) направлен на улучшение производительности модели за счет генерации примеров, ориентированных на признаки, наиболее важные для целевой задачи. В отличие от методов, создающих данные случайным образом или на основе общих инструкций, FAC Synthesis идентифицирует пробелы в данных обучения, связанные именно с этими критическими признаками. Это позволяет создавать данные, которые целенаправленно повышают способность модели правильно интерпретировать и использовать информацию, влияющую на конечный результат, тем самым повышая ее точность и надежность в решении поставленной задачи.
В отличие от методов синтеза данных, таких как Evol-Instruct, Magpie, CoT-Self-Instruct, Self-Alignment Optimization, Prismatic Synthesis и SynAlign, подход, основанный на измерении покрытия (Coverage-Guided Synthesis), характеризуется более целенаправленной генерацией примеров. Перечисленные методы не используют метрики покрытия для определения пробелов в обучающих данных и, следовательно, генерируют данные без явной ориентации на повышение производительности модели в отношении конкретных, значимых признаков или аспектов целевой задачи. Это отличает их от FAC Synthesis, где генерация примеров непосредственно связана с максимизацией Feature-Attribution Coverage, обеспечивая более эффективное расширение обучающего набора.
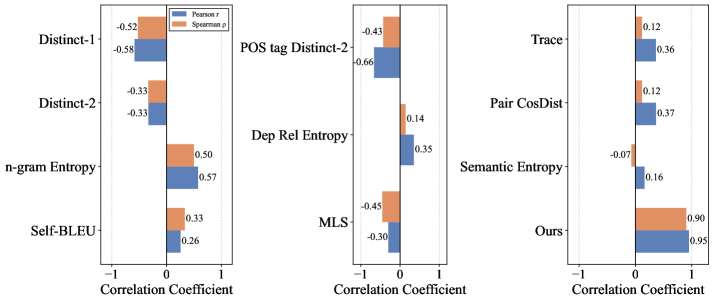
За пределами охвата: измерение разнообразия и надежность обобщения
Для оценки качества и полноты генерируемых данных используется набор метрик разнообразия, включающий в себя семантическую энтропию, косинусное расстояние между эмбеддингами, Distinct-nn и энтропию nn-грамм. Семантическая энтропия измеряет разнообразие семантических представлений сгенерированных данных. Косинусное расстояние между эмбеддингами оценивает расстояние между векторами представлений различных образцов, указывая на степень их отличия. Distinct-nn вычисляет долю уникальных nn-грамм в сгенерированном тексте, отражая лексическое разнообразие. Энтропия nn-грамм, в свою очередь, измеряет статистическую избыточность и разнообразие последовательностей из nn элементов в данных. Комбинированное использование этих метрик позволяет комплексно оценить разнообразие генерируемого контента и его потенциальную полезность для обучения моделей.
Метрики, такие как Total Variation Distance (TVD) и Divergence Кулбака-Лейблера (KL Divergence), позволяют оценить распределение синтезированных данных и их потенциальное влияние на обобщающую способность моделей. TVD измеряет максимальную разницу между двумя вероятностными распределениями, представляя собой максимальное абсолютное отклонение вероятностей для любого события. KL Divergence оценивает информацию, теряемую при аппроксимации одного вероятностного распределения другим, выступая в качестве меры различия между ними. Высокие значения этих метрик указывают на значительные расхождения в распределениях, что может свидетельствовать о недостаточном разнообразии синтезированных данных и, как следствие, о снижении способности модели к обобщению на новые, ранее не встречавшиеся данные.
Наблюдается сильная линейная зависимость между метрикой Functional Adequacy Coverage (FAC) и Area Under the Precision-Recall Curve (AUPRC), подтвержденная коэффициентом корреляции Пирсона r = 0.95. Этот результат указывает на то, что FAC может служить надежным предиктором производительности модели в задачах, оцениваемых по AUPRC. Высокие значения FAC, отражающие более полное покрытие функционального пространства генерируемых данных, статистически значимо связаны с более высокими показателями AUPRC, что позволяет использовать FAC в качестве эффективного инструмента для оценки и сравнения качества синтетических данных.
Коэффициент корреляции Спирмена (ρ) в размере 0.90 подтверждает выраженную положительную связь между охватом данных и производительностью модели. В отличие от коэффициента корреляции Пирсона, Спирмен измеряет монотонную связь, что делает его более устойчивым к выбросам и нелинейным зависимостям в данных. Высокое значение ρ указывает на то, что увеличение охвата синтезированных данных стабильно связано с улучшением показателей производительности модели, что подтверждает важность генерации разнообразного набора данных для повышения обобщающей способности.
Градиентные методы представляют собой дополнительный подход к оценке разнообразия генерируемых данных, позволяя количественно оценить это разнообразие непосредственно в пространстве градиентов. В отличие от метрик, основанных на анализе самих сгенерированных образцов, эти методы анализируют изменения в параметрах модели, вызванные генерацией. Теория PAC-Bayes (Probably Approximately Correct Bayes) предоставляет теоретическую базу для оценки ошибки обобщения, позволяя установить верхние границы на эту ошибку с заданной вероятностью. Это достигается за счет анализа априорного распределения на параметрах модели и использования байесовского подхода к оценке вероятности данных. Комбинирование градиентных методов с теорией PAC-Bayes позволяет получить более полное представление о качестве и способности к обобщению сгенерированных данных.
За пределами охвата: согласование LLM с человеческими ценностями
Эффективный синтез данных для больших языковых моделей требует первостепенного внимания к соответствию человеческим ценностям и намерениям. Недостаточно просто обеспечить техническую работоспособность; необходимо активно формировать поведение модели, чтобы исключить генерацию вредоносного или предвзятого контента. Этот процесс подразумевает не только фильтрацию существующих данных, но и целенаправленное создание новых, отражающих принципы ответственности и этичности. В противном случае, даже самые мощные языковые модели могут непреднамеренно распространять дезинформацию, усиливать стереотипы или причинять вред, подчеркивая важность интеграции этических соображений на каждом этапе синтеза данных и обучения модели.
Для формирования синтезированных данных и направления языковой модели к желаемому поведению ключевую роль играют такие задачи, как построение моделей вознаграждения, управление поведением и обнаружение токсичности. Модели вознаграждения обучаются оценивать качество генерируемого текста с точки зрения соответствия человеческим ценностям, позволяя модели отдавать предпочтение безопасному и полезному контенту. Управление поведением, в свою очередь, предполагает активное воздействие на процесс генерации, направленное на избежание нежелательных ответов и поощрение желаемых. Не менее важна и функция обнаружения токсичности, которая позволяет идентифицировать и фильтровать потенциально вредоносный или оскорбительный контент, обеспечивая тем самым безопасность и этичность работы языковой модели. В совокупности эти методы позволяют создать более надежные и контролируемые системы искусственного интеллекта.
Интеграция принципов соответствия человеческим ценностям непосредственно в процесс синтеза данных позволяет создавать большие языковые модели (LLM), которые не просто демонстрируют впечатляющую производительность, но и отличаются безопасностью и полезностью для общества. Вместо того чтобы полагаться на постобработку или фильтрацию сгенерированного контента, подобный подход направлен на формирование поведения модели уже на этапе обучения, минимизируя риски генерации вредоносного или предвзятого материала. Это достигается за счет включения в процесс обучения сигналов, отражающих предпочтения человека в отношении этичности, справедливости и отсутствия предрассудков, что позволяет LLM не только эффективно решать задачи, но и действовать в соответствии с общепринятыми нормами и принципами.
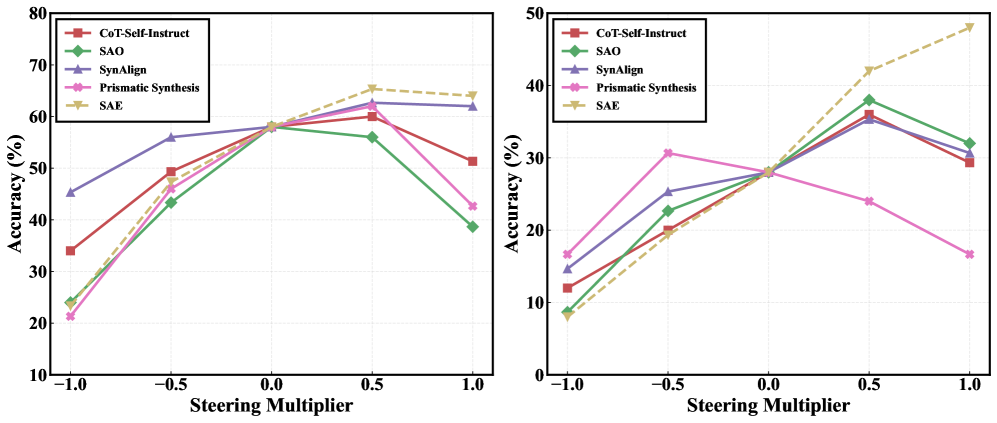
Исследование демонстрирует, что понимание внутренней структуры больших языковых моделей позволяет не просто использовать их возможности, но и целенаправленно расширять их. Авторы предлагают метод FAC Synthesis, который, по сути, является своего рода реверс-инжинирингом недостающих знаний в модели. Этот подход напоминает поиск уязвимостей в системе, чтобы затем её укрепить. Тим Бернерс-Ли однажды сказал: «Интернет — это для всех». Подобно этому, FAC Synthesis стремится сделать возможности языковых моделей более полными и доступными, заполняя пробелы в их понимании мира и обеспечивая более качественное выполнение задач. Использование разреженных автоэнкодеров для выявления недостающих признаков — это элегантный способ ‘взломать’ ограничения модели, расширив её потенциал.
Куда дальше?
Представленная работа, по сути, лишь констатация очевидного: даже самые мощные языковые модели — это не зеркало реальности, а её приблизительная, фрагментарная проекция. Метод FAC Synthesis, выявляя пробелы в покрытии признаков, скорее диагностирует болезнь, чем предлагает окончательное лекарство. Вопрос в том, насколько принципиально возможно полностью «заполнить» внутреннее пространство признаков, не столкнувшись с экспоненциальным ростом сложности и не потеряв обобщающую способность. Каждый эксплойт начинается с вопроса, а не с намерения.
Перспективным направлением представляется исследование динамической природы этих признаков. Вместо статического «заполнения» пробелов, возможно, более эффективно будет научиться управлять существующими признаками, переконфигурировать их в зависимости от задачи, создавать «виртуальные» признаки на лету. Это потребует отказа от представления о признаках как о жёстко заданных сущностях и перехода к более гибкой, процедурной модели.
В конечном счёте, успех этого направления зависит не от совершенствования алгоритмов синтеза данных, а от глубокого понимания того, как информация кодируется и представляется внутри нейронных сетей. Реверс-инжиниринг «чёрного ящика» — задача нетривиальная, но именно она определяет горизонт возможностей. Попытки «взломать» систему, пусть даже в исследовательских целях, неизбежно приводят к её лучшему пониманию.
Оригинал статьи: https://arxiv.org/pdf/2602.10388.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Конфиденциальный анализ больших данных: новый подход к быстрым ответам
- Звук в коде: новая эра токенизации аудио
- Стратегия подцелей: Как научить ИИ долгосрочному планированию
- Преображение лиц: от тепла к реализму с помощью ИИ
- Грань между Творчеством и Риском: Искусственный Интеллект и Эротический Контент
- Пространственная Архитектура для Эффективного Ускорения Нейросетей
- Понимание сложных систем: новый взгляд на агентные модели
- Юридический интеллект на турецком: Новые модели для понимания права
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Квантовые схемы и ИИ: Новые горизонты программирования
2026-02-17 03:07