Автор: Денис Аветисян
Новое исследование выявляет и устраняет ключевую причину нестабильности в процессе обучения с подкреплением, позволяя создавать более надёжные и предсказуемые языковые модели.
Метод STAPO снижает влияние редких, неинформативных токенов, которые приводят к взрыву градиентов и дестабилизируют обучение с подкреплением для больших языковых моделей.
Несмотря на значительные успехи обучения с подкреплением в улучшении логических способностей больших языковых моделей, существующие методы часто страдают от нестабильности и деградации качества на поздних стадиях обучения. В работе ‘STAPO: Stabilizing Reinforcement Learning for LLMs by Silencing Rare Spurious Tokens’ показано, что источником этой нестабильности являются редкие, незначимые токены — порядка 0.01% от общего числа — которые, тем не менее, непропорционально усиливают градиенты и дестабилизируют процесс обучения. Предложенный метод STAPO выборочно маскирует обновления, связанные с такими токенами, и нормализует потери, обеспечивая стабильность и улучшение результатов на математических задачах на 7.13% по сравнению с существующими подходами. Не приведет ли более эффективное подавление этих «ложных» сигналов к созданию еще более надежных и эффективных языковых моделей?
Неустойчивость Обучения с Подкреплением: Когда Теория Встречает Реальность
Тонкая настройка больших языковых моделей (LLM) с использованием обучения с подкреплением (RL) становится ключевым элементом в решении сложных задач, особенно в области математического рассуждения. В то время как LLM демонстрируют впечатляющие возможности в генерации текста, их способность к логическому выводу и решению задач, требующих последовательных шагов, часто ограничена. Обучение с подкреплением позволяет модели не просто генерировать ответы, но и учиться на своих ошибках, получая вознаграждение за правильные шаги в решении задачи. Этот процесс особенно важен для математики, где последовательность и точность вычислений критически важны. Применение RL позволяет LLM осваивать сложные стратегии решения задач, такие как разбиение сложной задачи на более мелкие подзадачи и выбор оптимального пути к решению, что значительно повышает их эффективность и надежность в математическом контексте.
Стандартные методы обучения с подкреплением зачастую демонстрируют нестабильность при взаимодействии с большими языковыми моделями, что приводит к расхождению процесса обучения и, как следствие, к неудовлетворительным результатам. Особенно остро эта проблема проявляется в задачах, где пространство возможных действий (действий модели) имеет высокую размерность. Это связано с тем, что даже незначительные изменения в параметрах модели или в данных могут вызвать каскад эффектов, приводящих к непредсказуемому поведению и отклонению от оптимальной стратегии. В результате, модель может начать генерировать нелогичные или некорректные ответы, а процесс обучения перестает сходиться к стабильному решению, требуя значительных усилий по настройке и стабилизации.
Нестабильность обучения с подкреплением больших языковых моделей (LLM) часто обусловлена высокой чувствительностью процесса оптимизации к ложным корреляциям, присутствующим как в обучающих данных, так и в самой стратегии поведения модели. Иными словами, алгоритм может начать усиливать действия, которые случайно приводят к желаемому результату в конкретном наборе данных, вместо того чтобы изучать истинные закономерности, необходимые для обобщения на новые, неизвестные ранее примеры. Эта проблема особенно актуальна в задачах с многомерными пространствами действий, где случайные корреляции могут легко замаскировать реальные связи между действиями и наградами, приводя к расхождению алгоритма и ухудшению производительности. По сути, модель может “заучить” не решение задачи, а лишь специфические особенности обучающей выборки, что делает её неспособной к эффективной работе в реальных условиях.
Ложные Токены: Скрытые Дефекты Обучения
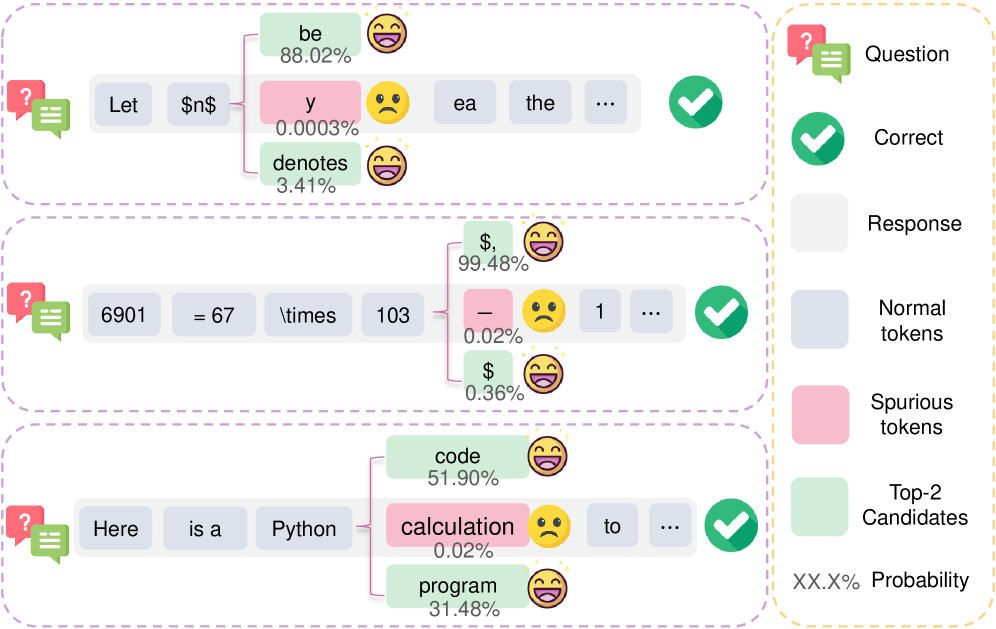
Критическим источником нестабильности в процессе обучения с подкреплением является наличие так называемых “ложных токенов” (Spurious Tokens) — редких токенов, демонстрирующих неожиданно высокий показатель преимущества (advantage). Этот высокий показатель, возникающий при обработке редких состояний или действий, искажает сигнал обучения, заставляя алгоритм переоценивать их значимость. В результате, политика может фокусироваться на нерелевантных признаках, что приводит к снижению общей производительности и затрудняет сходимость обучения. Высокое преимущество ложных токенов, не отражающее реальную ценность действия, вносит шум в градиент, усложняя оптимизацию и потенциально приводя к расхождению.
Токены, характеризующиеся низкой энтропией и высокой вероятностью (Token Probability), могут приводить к фокусировке политики на нерелевантных признаках. Низкая энтропия указывает на предсказуемость токена, а высокая вероятность — на его частое появление в процессе обучения. Вместе эти факторы приводят к тому, что алгоритм может необоснованно усиливать влияние этих токенов, ошибочно принимая их за значимые признаки, что в конечном итоге приводит к ухудшению общей производительности и снижению способности агента к обобщению.
Влияние ложных токенов (Spurious Tokens) проявляется в непредсказуемых значениях нормы градиента (Gradient Norm), что указывает на нестабильный ландшафт оптимизации и потенциальную расходимость процесса обучения с подкреплением. Высокие значения нормы градиента, вызванные этими токенами, свидетельствуют о резких изменениях в параметрах модели, что затрудняет ее сходимость к оптимальному решению. Анализ нормы градиента позволяет выявить периоды нестабильности, связанные с влиянием ложных токенов, и оценить степень их воздействия на процесс обучения. Нестабильность, проявляющаяся в колебаниях нормы градиента, может приводить к неэффективному использованию вычислительных ресурсов и замедлять сходимость алгоритма.
Метод STAPO решает проблему неустойчивости обучения, вызванную ложными токенами, путем маскировки примерно 0.01% наиболее проблемных из них. Эта процедура заключается в исключении из рассмотрения небольшого процента токенов, характеризующихся высокой величиной преимущества и низкой энтропией. Маскировка позволяет снизить влияние этих токенов на градиент и, как следствие, стабилизировать процесс оптимизации, предотвращая расхождение и улучшая общую производительность алгоритма обучения с подкреплением.
Отрицательные или положительные значения преимущества (advantage) используются в алгоритмах обучения с подкреплением для оценки выгодности конкретного действия в определенном состоянии. Однако, в случае «ложных токенов» (spurious tokens), значение преимущества часто оказывается положительным, даже если действие, связанное с этим токеном, на самом деле не способствует достижению оптимальной стратегии. Это происходит из-за статистических аномалий, приводящих к завышенной оценке выгоды от случайных или нерелевантных действий. Положительный сигнал преимущества вводит алгоритм в заблуждение, заставляя его усиливать нежелательное поведение и снижая общую производительность модели. Такая ситуация особенно опасна на начальных этапах обучения, когда алгоритм наиболее чувствителен к ложным сигналам.
От DAPO к STAPO: Эволюция Стабилизации Обучения
Первоначальные методы стабилизации обучения с подкреплением для больших языковых моделей (LLM), такие как DAPO, ввели нормализацию на уровне токенов для решения проблемы нестабильности. Эта техника заключалась в применении нормализации к вероятностям, генерируемым моделью для каждого токена, что позволяло предотвратить доминирование отдельных токенов и более равномерно распределять вероятность по всему словарю. Фактически, нормализация на уровне токенов служила механизмом регуляризации, снижающим риск переобучения и повышающим устойчивость процесса обучения, особенно в контексте задач, где LLM используется в качестве агента обучения с подкреплением.
Алгоритм STAPO (Spurious-Token-Aware Policy Optimization) является усовершенствованием существующих методов стабилизации обучения с подкреплением для больших языковых моделей. В отличие от предыдущих подходов, STAPO ориентирован на выявление и подавление так называемых “ложных токенов” — артефактов, возникающих в процессе обучения и приводящих к нестабильности. Этот алгоритм позволяет избежать концентрации вероятности на этих токенах путем их маскировки и перенормировки функции потерь, что способствует более надежной и стабильной тренировке модели.
Алгоритм STAPO (Spurious-Token-Aware Policy Optimization) решает проблему нестабильности обучения моделей, маскируя проблемные «ложные» токены, возникающие в процессе генерации. Этот подход предотвращает эксплуатацию моделью артефактов, связанных с этими токенами, путем исключения их из процесса оптимизации. Дополнительно, STAPO выполняет перенормировку функции потерь, что позволяет более эффективно корректировать веса модели и стабилизировать процесс обучения, избегая чрезмерной концентрации вероятности на нежелательных токенах.
Алгоритм STAPO обеспечивает стабильность обучения за счет управления вероятностью коллизий (Collision Probability). В процессе обучения языковых моделей с подкреплением, модель может концентрировать вероятность на небольшом количестве токенов, что приводит к нестабильности и неоптимальным результатам. STAPO решает эту проблему, отслеживая и управляя распределением вероятностей, предотвращая чрезмерную концентрацию на отдельных токенах. Это достигается за счет маскировки «ложных» токенов и ренормализации функции потерь, что способствует более равномерному распределению вероятности и, как следствие, более надежному и стабильному процессу обучения.
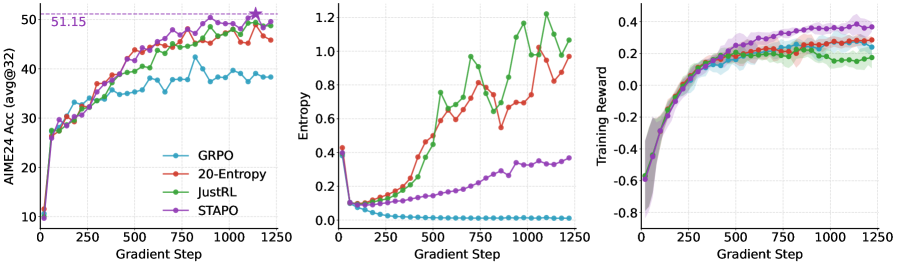
Алгоритм STAPO демонстрирует значительное улучшение производительности на бенчмарке AIME24. При использовании модели Qwen3-1.7B, STAPO обеспечивает относительное увеличение показателя на 13.5%, а с моделью Qwen3-14B — на 5.94%. Эти результаты подтверждают эффективность подхода STAPO в стабилизации обучения с подкреплением и повышении надежности моделей больших языковых моделей.
Динамика Энтропии и Надежное Обучение Стратегии
Анализ динамики энтропии в процессе обучения демонстрирует, что алгоритм STAPO последовательно поддерживает более здоровый уровень энтропии по сравнению со стандартными методами обучения с подкреплением. Данный показатель отражает степень исследуемости алгоритмом пространства действий; стабильно высокая энтропия указывает на эффективный поиск оптимальных решений, избегая преждевременной сходимости к субоптимальным стратегиям. В отличие от традиционных подходов, где энтропия часто стремительно падает, STAPO обеспечивает ее устойчивость, что способствует более надежному и эффективному обучению, позволяя модели избегать локальных оптимумов и находить более обобщенные решения.
Стабильность энтропии в процессе обучения модели указывает на её способность эффективно исследовать пространство действий, что является ключевым фактором для достижения оптимальных решений. Недостаточная энтропия может привести к преждевременной сходимости к субоптимальным стратегиям, когда модель перестает искать более выгодные варианты. В отличие от этого, поддерживая постоянный уровень энтропии, модель продолжает активно исследовать различные возможности, избегая «застревания» в локальных оптимумах. Такой подход позволяет ей находить более надежные и эффективные решения, что подтверждается результатами, демонстрирующими превосходство данной методики над традиционными алгоритмами обучения с подкреплением.
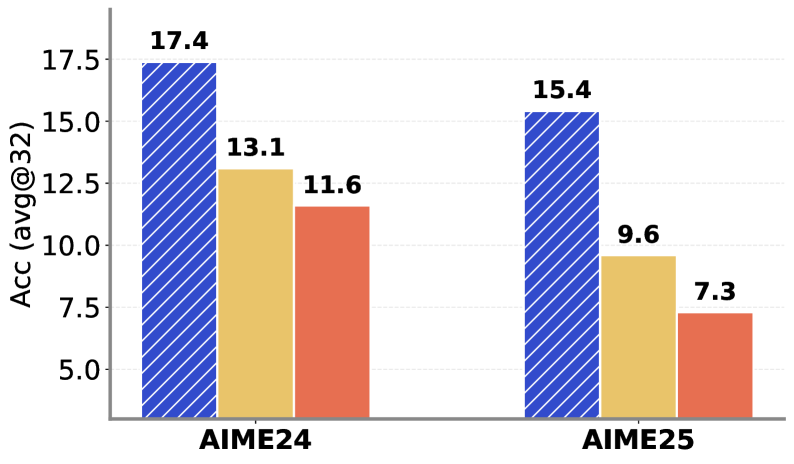
В результате применения алгоритма STAPO достигнута точность в 17,4% на платформе AIME24 и 15,4% на AIME25, что значительно превосходит показатели, демонстрируемые традиционными методами обучения с подкреплением. Полученные результаты свидетельствуют о превосходстве STAPO в задачах, требующих эффективного исследования пространства действий и устойчивой оптимизации стратегии. Преимущество в точности, проявленное на обеих платформах, подтверждает надежность и универсальность предложенного подхода к обучению, позволяя достигать более высоких показателей эффективности в сложных вычислительных задачах.
Стабильность процесса обучения, достигаемая благодаря STAPO, оказывает существенное влияние не только на итоговую производительность модели, но и на эффективность использования вычислительных ресурсов. В отличие от стандартных методов обучения с подкреплением, которые часто демонстрируют колебания энтропии и склонность к преждевременной сходимости, STAPO поддерживает более устойчивый уровень энтропии на протяжении всего обучения. Это позволяет модели более эффективно исследовать пространство действий, избегая застревания в локальных оптимумах и требуя меньшего количества итераций для достижения оптимального решения. В результате, алгоритм STAPO демонстрирует превосходные результаты на задачах AIME24 и AIME25, при этом снижая потребность в вычислительной мощности и времени, что делает его привлекательным решением для задач, требующих высокой эффективности и масштабируемости.
Исследование показывает, что даже незначительные артефакты в выходных данных больших языковых моделей могут привести к нестабильности обучения с подкреплением. Авторы выявили, что небольшая доля «ложных токенов» способна непропорционально усиливать градиенты, нарушая процесс оптимизации. Этот феномен хорошо согласуется с мыслью Кena Thompson: «Вся сложность — это просто больше ошибок». В данном случае, «ошибки» проявляются в виде редких, неинформативных токенов, которые, тем не менее, оказывают существенное влияние на обучение. Стремление к идеальной масштабируемости часто игнорирует фундаментальную хрупкость систем, и STAPO — лишь одна из попыток залатать дыры в кажущейся элегантности современных моделей.
Что Дальше?
Работа, безусловно, выявила очередную «тонкую» проблему обучения больших языковых моделей с подкреплением. Как всегда, элегантная теория оптимизации натыкается на реальность: горстка случайных, бессмысленных токенов способна обрушить всю систему. Похоже, когда-то это был простой bash-скрипт, а теперь… Теперь это «AI», и нужно искать инвесторов. Впрочем, маскировка этих «спорных» токенов — лишь временное решение. Начинаешь подозревать, что проблема кроется глубже — в самой архитектуре моделей и их склонности генерировать статистический шум, который потом пытаются «причесать» все более сложными методами.
Следующим шагом, вероятно, станет попытка найти более фундаментальный способ стабилизации обучения, возможно, через изменение функции потерь или архитектуры самой модели. Но давайте будем честны: каждый новый «прорыв» порождает новый технический долг. Документация снова соврет, а проблема, как всегда, окажется в другом месте.
В конечном итоге, вся эта гонка за производительностью напоминает попытку построить карточный домик во время землетрясения. Вероятно, рано или поздно придётся признать, что «обучение с подкреплением» для больших языковых моделей — это, в лучшем случае, сложная эвристика, а не надёжный алгоритм. И тогда все эти красивые графики сходимости покажутся особенно ироничными.
Оригинал статьи: https://arxiv.org/pdf/2602.15620.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Взрыв скорости: Оптимизация внимания для современных GPU
- Знаем, чего не знаем: Моделирование вероятностных рассуждений на основе множественных доказательств
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Языковые модели и границы возможного: что делает язык человеческим?
- Учимся с интересом: как создать AI-репетитора, вдохновлённого лучшими учителями
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Искусственный интеллект и квантовая физика: кто кого?
- Искусственный интеллект, который мыслит быстрее: MiMo-V2-Flash
- Любовь и данные: конфиденциальность в отношениях с искусственным интеллектом
2026-02-18 16:14